この記事は何
ナレッジセンスでは、エンタープライズ向けにRAGサービスを提供しています。その中で「RAGは簡単に作れるけど、精度を上げるのは難しい」という課題に日々向き合っています。本記事は、2024~2025年に公開された研究や事例をもとに、RAGの回答精度を高める代表的なアプローチを ざっくりまとめたものです。
ざっくりサマリー
この記事では、企業の社内データを利用したRAG、特に大企業で「エンタープライズRAG」での実装手法についてざっくり理解します。まず、エンタープライズRAGでのよくある課題をお伝えします。その上で、2025年現在の最新動向を踏まえ、評価手法のような基本戦略から、ちょっと高度なテクニックまで、RAGの精度を向上手法を概観します。
(エンタープライズRAGとは、社内の膨大なデータをLLMが活用可能にするためのソリューションのことです。)
RAG、実装は簡単。しかし、精度向上は「茨の道」

*Langchainによる『RAG From Scratch』から引用。一部改変
RAGとは何か?
まず、RAGについて。RAGとは、LLMがファイルを参照して回答できる仕組みです。これにより、LLMが元々持っていない知識を補い、回答の正確性・信頼性を高めることができます。[1]
とりあえず作ってみるのが良さそう
この1-2年で、「基本的なRAG」の実装コストは下がりました。
例えば、OpenAIのRetrieval APIを使えば、ファイル検索(ベクトル検索)機能を活用して、驚くほど少ないコードでRAGを実装できます。
これからRAGを試す方であれば、こういうほぼほぼフルマネージドなRAGサービスを利用してみるところから始めるのが良いと思います。
ただ、この場合、実装が手軽な分、精度は実用レベルにはならないのが現状です。デモレベルのRAGには十分ですが、企業の現場で本当に役立つ、高精度なシステムを構築するのは全く別の話です。
というのも、RAGを実装するというのは、本質的に「高性能な検索エンジン」を作る行為だからです。(長い機械学習の歴史でも、「検索」って、もう、超巨大な研究分野ですからね。一朝一夕では行きません。)
エンタープライズRAGでよくある課題
RAGの精度向上テクニックを学ぶ前に、まずはエンタープライズRAGで直面する、「あるある」な課題を紹介します。
課題① 昔の情報、結構残ってる
大企業では、「過去に蓄積されたドキュメントが、もう最新ではない」ことがよくあります。古い情報が残ったままになっている、ということです[2]。新しい情報が追加されているものの、古い情報を消し忘れているパターンです。消し忘れというか、記録のために、昔のバージョンもあえて残している、という企業もよくあります。
通常のRAGだと、検索してきた情報の鮮度を検証する仕組みがありません。なので、古い情報や条件に合わない情報に基づいて、自信満々に間違った回答を生成してしまうリスクがあります。
課題② チャンキングで文脈が消える
RAGでは、元のドキュメントが長い場合、それを細切れ(チャンク)にして、データベースに保管します[3]。しかし、この機械的な分割は、重要な文脈を断ち切ってしまうことがよくあります。
重要な情報が前後のチャンクに分断されてしまったり、文書内の離れた場所にある情報(「飛び地にある重要情報」)を見落としたりすることがあります。かといって、「関連しそうなチャンクを大量にLLMに渡せば解決するか?」というと、そう単純ではありません。逆に関係のない情報が増えすぎると、LLMが幻覚(ハルシネーション)を起こす可能性が高まります[4]。

課題③ ベクトル検索の限界(専門用語弱い・文脈考慮できない)

RAGでは、通常、ベクトル検索を利用して文書検索をするのが王道です。ただ、弱点もあります。
例えば、専門用語が多いドキュメントでは、「単語の雰囲気は似ていても、意味は全然違う情報」を誤って取得してしまうことがあります[5]。
また、文書内の複雑な関係性を捉えるのが苦手なため、例えば組織図やシステム構成のような、要素間の繋がりが重要な情報を正確に扱うことができません[6]。
課題④ 複雑な図表・画像の読み取りミス
前提として、通常のRAGでは、PDFファイルに含まれる画像や図表に対して回答することはできません。また、工夫して、画像を読み取り可能にしたとしても、LLMの画像読み取り性能には限界があります。LLMは、画像をざっくりとしか理解しません[7]。
LLMが苦手な画像の例(参考)↓

しかし、現実のエンタープライズ企業の社内データには、画像やグラフ、複雑な構成図(いわゆる「ごちゃごちゃしたポンチ絵」)が豊富に含まれています。
これは、実用的なRAGを実現する上で、結構大きいハードルです。
課題⑤ 普通のRAGだと柔軟性がない
RAGは、基本的には、「一度検索し、その結果を基に生成する」という固定的な仕組みです。

ただ、これだけでは柔軟性がありません。これだけだと、ユーザーの質問が曖昧な場合に「逆質問」したり、複雑な問いに対して複数回の検索を組み合わせて答えを導き出したり、という柔軟な行動ができず、精度が落ちます。[8]
RAGの精度を向上するための手法
手法① RAG改善の基礎
まずは、かなり基礎的な内容です↓。が、もし、試していない場合は、まずは以下の改善が必要です。
1. LLMと埋め込みモデルの選定
RAGの最終的な出力品質は、生成を担当するLLMの性能に大きく依存します。多くの場合、まず効果的な精度向上の手法は、より高性能なLLMを選択することです[9]。現在であれば、まずは GPT-5 や Gemini 2.5 Pro モデルを利用するところが出発点です。
また、RAGで利用する 「埋め込みモデル」も、結構重要です[10]。OpenAIのtext-embedding-3-largeもいいですが、SB Intさんなども、日本語特化の埋め込みモデルを出してくれています[11]。
2. RAGの精度評価
「測定できないものは、改善できない」[12]
です。精度向上を目指すなら、まずは、Ragasのような評価フレームワークの導入をおすすめします[13]。Ragasは、ユーザーの質問、RAGの回答、参照されたコンテキスト、そして正解データ(Ground Truth)を入力として、以下のような指標を定量的に評価してくれます。
- Faithfulness: 生成された回答が、提供されたコンテキストにどれだけ忠実か
- Answer Relevancy: 生成された回答が、元の質問にどれだけ関連しているか
- Context Precision/Recall: 検索されたコンテキストが、回答生成にどれだけ適切かつ十分であったか
このような評価パイプラインを最初に構築することで、後述する様々な改善手法の効果を客観的に測定し、体系的な精度向上を実現できます。
手法② 検索を強化
RAGの精度向上において、「検索」の改善は、キモになる部分です。
1. ハイブリッド検索とリランキング
ベクトル検索は意味の類似性に基づく検索に強い一方で、キーワードや専門用語のような特定の文字列との一致(完全一致)には弱いという弱点があります。このような、ベクトル検索の弱点を補うのが、ハイブリッド検索です。
これは、ベクトル検索と、キーワードベースの検索を組み合わせる手法です。両方の検索結果を統合することで、意味的な広がりとキーワードの正確性の両方を担保し、検索の網羅性を高めることができます[14]。
さらに、検索結果の精度を高めるためにリランキングという手法も有効です[15]。これは、ハイブリッド検索で得られた上位候補(例:50件)を、より高性能だが計算コストの高いモデル(Re-ranker)を使って再度順位付けし、最も関連性の高い文書をトップに持ってくる二段階のプロセスです。

2. ベクトル検索に頼らない「PageIndex」
RAGなのにベクトル検索を使わないという、最新手法も登場しています。「PageIndex」という手法では、、LLM自身に文書の内容を要約させ、キーワードとそれが含まれる箇所をマッピングした「索引(Index)」を作成させるアプローチです。

PageIndexという手法では、文書を階層的なツリー構造に変換(「目次」のようなイメージ)し、LLMがその構造を辿って検索します。これにより、人間が文書を読むときのように、文脈を理解して必要な情報を探し出すことが可能になります。
3. ナレッジグラフを組み合わせたRAG
企業のドキュメントでは、専門性の高い、似たようが単語が多いです。なので、その単語がどういう意味で利用されているかという、前後情報「関係性」が重要です。GraphRAGは、このような要件を、ナレッジグラフを利用して解決します[16][17]。

手法③ 「RAG x AIエージェント」の手法
2025年のRAGでは、「AIエージェント」が重要です。すなわち「Agentic RAG」です。これは、RAGのプロセスを「人間みたいに柔軟に」動くようにしよう、というアプローチです。
1. Agentic RAGとは何か
AIエージェントとは、単に指示を実行するだけでなく、
①自己内省、②計画、③ツール利用
といった自律的な思考・行動ができるLLMのことです。
固定化されたパイプラインの代わりに、LLMが司令塔となり、「この質問には検索が必要か?」「検索クエリを改善すべきか?」「得られた情報で回答するのに十分か?」といった意思決定を動的に行います。詳細は以下の記事でまとめています。
2. 自己評価・修正するRAG
実は、「AIエージェント」が流行する前から、AgenticなRAGは出てきていました。特に重要なのが、自身のプロセスを評価し、間違いを修正する能力です。この系統の代表的なフレームワークが「Self-RAG」「CRAG」「Adaptive RAG」です。
Self-RAG
→モデル自身が「リフレクショントークン」と呼ばれる特殊なトークンを生成し、各ステップで自己評価を行います。「この文書は質問と関連しているか?」「この生成文は文書に裏付けられているか?」といった内省を繰り返すことで、回答の事実性を劇的に向上させます。ハルシネーションを徹底的に抑制したい場合に非常に有効な手法です[18]。

Corrective RAG (CRAG)
→取得した文書が不十分、または無関係だと判断した場合、エージェントがWeb検索のような別のツールを使って情報を補正・補強。これにより、社内のナレッジベースが不完全であっても、外部の最新情報で回答の頑健性を高めることができます[19]。
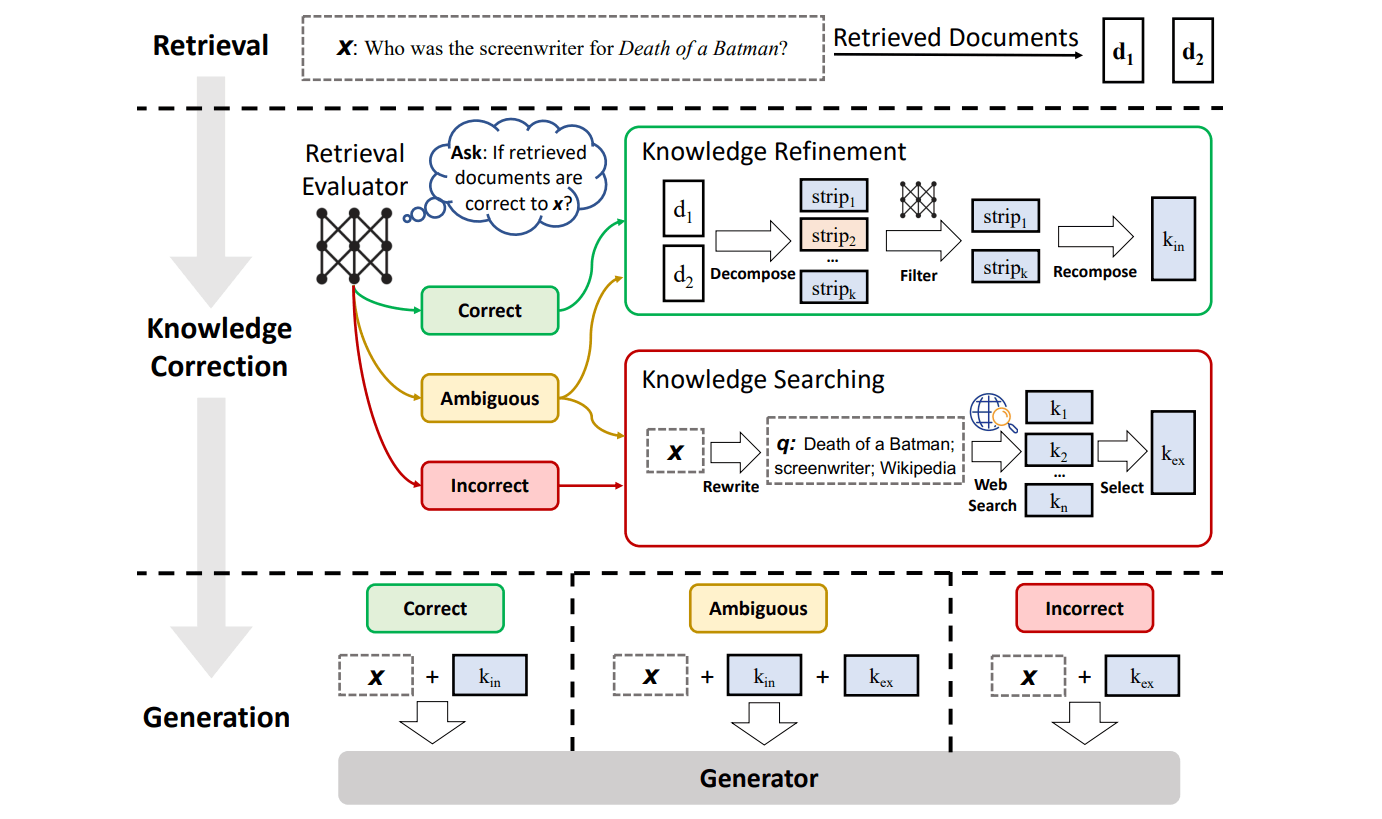
Adaptive RAG
→プロセスの最初に「ルーター」を置き、ユーザーの質問の複雑度を分析・分類します[20]。
- 単純な質問(例:「フランスの首都は?」)→ LLMが内部知識で回答(検索不要)
- 中程度の質問(例:「弊社の最新の経費精算規定は?」)→ 単純なRAGで検索
- 複雑な質問(例:「競合A社とB社の直近の戦略を比較して」)→ 後述するDeep Researchのような反復的な検索プロセスを実行
このように、Agentic RAG では、質問に応じて柔軟な回答ができるようにします。そうすることで、回答の質・コスト・速度のバランスをとります。
手法④ 他にも色々
- コンテキストエンジニアリング[21]
- 深い調査を実現する「Deep Research」[22]
- マルチモーダルRAG
- AIに「分からない」と言わせる[23]
- LLMの「思考プロセス」を蓄積して活用[24]
まとめ
弊社では、普段から、エンタープライズ企業向けに、RAGシステムを提供しています。
今回の記事では、エンタープライズRAGでよくある課題と、典型的な解決策を整理しました。普通のRAGを「ざっくり作る」ためのコストは下がっていますが、現場のRAGで本当に求められるクオリティは、逆に、どんどん高まっていると感じます。
みなさまが業務でRAGシステムを構築する際、この記事が参考になれば幸いですし、こういう「泥臭い仕事で、デカい顧客価値を生み出せる」タイプの領域に、興味を持つ人材が増えれば嬉しいです。
今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
-
https://zenn.dev/knowledgesense/articles/47de9ead8029ba#ragとは。なぜ必要なのか? ↩︎
-
https://zenn.dev/knowledgesense/articles/1ecd331dc6b589#:~:text=過去に蓄積されたドキュメントが、もう最新ではない ↩︎
-
https://zenn.dev/knowledgesense/articles/1ecd331dc6b589#:~:text=過去に蓄積されたドキュメントが、もう最新ではない ↩︎
-
https://zenn.dev/knowledgesense/articles/e0ade68c265200#問題意識 ↩︎
-
https://zenn.dev/knowledgesense/articles/2895f9adc8d802#問題意識 ↩︎
-
https://zenn.dev/knowledgesense/articles/077ad1ab0f9ff6#問題意識 ↩︎
-
https://zenn.dev/knowledgesense/articles/41db334e173e2a#問題意識 ↩︎
-
https://zenn.dev/knowledgesense/articles/64975fb9377f82#問題意識:~:text=問題意識-,従来のRAGでは、柔軟性がありません,-でした。例えば ↩︎
-
https://zenn.dev/knowledgesense/articles/cec1cd43244524#7.-埋め込みモデルのファインチューニング ↩︎
-
https://www.sbintuitions.co.jp/blog/entry/2025/08/20/160139 ↩︎
-
https://zenn.dev/knowledgesense/articles/cec1cd43244524#2.-ハイブリット検索 ↩︎
-
https://zenn.dev/knowledgesense/articles/9303b94ea2c4eb#1.-抽出ドキュメントのリランキング ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion