本記事では、よく聞く「Self-RAG」についてざっくり理解します。軽めの記事です。
はじめまして。ナレッジセンスの門脇です。生成AIやRAGシステムを活用したサービスを開発しています。
この記事は何
この記事は、RAGの新手法として昨年発表された「Self-RAG」の論文[1]について、日本語で簡単にまとめたものです。
この論文は「CRAG」[2]など、最近出ている別のRAGアーキテクチャにも影響を与えているので、理解する価値がありそうです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
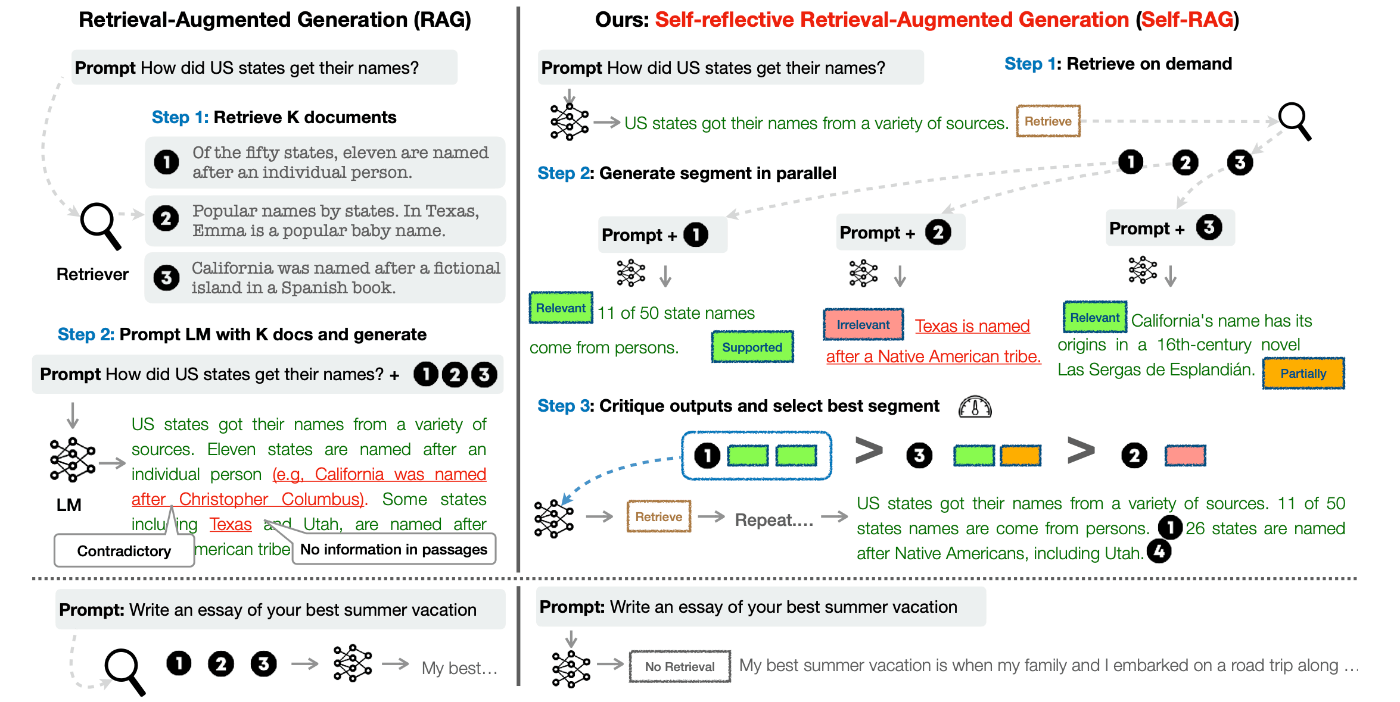
RAGの性能を高めるための新しい手法です。ワシントン大学などの研究者によって2023年10月に提案されました。Self-RAGという手法を使うメリットは、回答品質を上げられること、ハルシネーション(幻覚)を減らせることです。Self-RAGが従来のRAGよりも優れている理由は、「そもそも文書検索が必要か」どうか、チェックする機能が組み込まれていたり、取得してきた文書からの生成品質を自分自身でチェックする機能を取り入れてたりしているからです。チェックの結果、誤っているor無意味と判断された内容は回答には、利用されない仕組みです。
問題意識
大規模言語モデル(LLM)は便利ですが、たまに事実に基づかない不正確な応答を生成してしまう(ハルシネーション・幻覚)という問題があります。
この問題に対し、外部の知識を参照してから生成する手法としてRetrieval-Augmented Generation (RAG)が注目されています。しかし通常のRAGでは、検索が必要ないのにドキュメントを参照してしまったり、参照した文書の質が低かったりすると、かえって性能が低くなります。例えば人間なら、「こんにちは」と言われた時に、わざわざ辞書で調べてから回答を考えるようなことはしませんが、通常のRAGの場合だと、「こんにちは」に関連する文書を検索して回答する仕組みになってしまいます。
手法
画像の引用元[3]
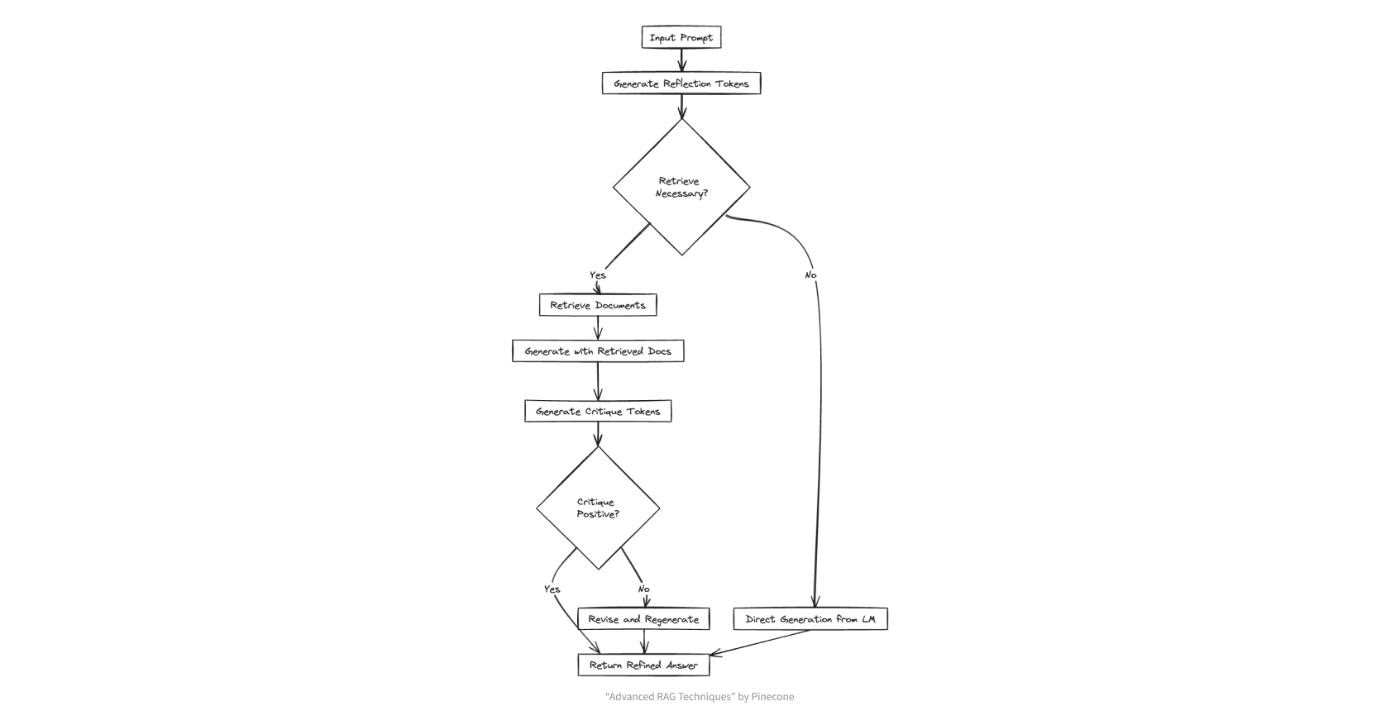
本論文では、①RAGするかどうかをまず判断し②取得ドキュメントを批判的に選別するという手法「Self-RAG」を提案しています。Self-RAGの主なポイントは以下の4点です。
【事前にやっておくこと】
-
LLMをファインチューニングし文章の生成の途中でreflection tokenを混ぜ込めるようにする
Self-RAGでは、独自にファインチューニングしたモデルを生成に利用します。[4]
【ユーザーが質問を入力して来たとき】
-
ユーザーの質問に対し、まず検索の要否を自己判断
不要と判断した場合は文書検索はせず、独自の知識だけで回答を生成します。以下、検索した場合を説明します -
検索で取得した複数の文書を基に、それぞれ回答生成
それぞれのドキュメント1つずつ+元の質問をもとに、LLMが複数の回答を生成します。 -
回答を評価、最も良い応答を選択
生成された複数の回答について、質問にして関係あるか、証拠になるか、有用かどうかを判断し、最もスコアの高い回答を採用します。
アルゴリズムの詳細
エッセンスの理解が目的なので、上では簡単のためにざっくり書きました。具体的なアルゴリズムは以下です。

※「まとめ」でも触れますが、この「1」にあたる事前準備のファインチューニングが面倒なこともあり、最近ではFTしない実用的な手法も提案されています。
成果

SELF-RAGの評価実験は、大きく3種類のタスクで行われました。
- オープンドメインQA (PopQA, TriviaQA)
- 選択式の推論タスク (ARC-Challenge, PubHealth)
- 長文生成 (Biography, ASQA)
比較対象は、パラメータ数の多いLLM、LLM+RAG、ChatGPT[5]やLlama2-chatなどのモデルです。
結果として、SELF-RAGは全てのタスクにおいてベースラインを大きく上回りました。
- ARC-ChallengeやPubHealthでは70%以上の正解率
- PopQAやTriviaQAでは50%以上の正解率でChatGPTを凌駕
- 長文生成ではChatGPTと同等以上
パラメータ数が少ないSELF-RAG 7Bが、ChatGPTやLlama2-chat 13Bを上回るケースもあり、提案手法の優位性が示されました。
まとめ
Self-RAGは、一般的なRAGよりも回答性能を高めるために提案された手法です。この研究を参考にして
「CRAG」のような新しい手法が生まれたり、Self-RAGのエッセンスは抑えつつ、(独自のモデルは微調整せずに)OpenAIのモデルだけで実現するような、より実用的なフレームワークも登場したりしています(例えば[3:1][6])。個人的にも、Self-RAGそのものよりもこのエッセンスが重要だと考えています。みなさまが業務でRAGシステムを構築する際も、ハルシネーションを防ぐ仕組みとして参考にしていただければ幸いです。今後も、類似研究の「RAG Fusion」などについて、機会があれば記事にする予定です。
-
"Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection", Akari Asai et al. ↩︎
-
"Corrective Retrieval Augmented Generation", Shi-Qi Yan et al. ↩︎
-
例えば、質問
次のうち、異質なものは? Twitter、Instagram、WhatsApp
回答
Twitter, Instagram, and WhatsApp are all social media platforms. [No Retrieval]WhatsApp is the odd one out because it is a messaging app, while Twitter and # Instagram are primarily used for sharing photos and videos.[Utility:5]</s> Model prediction: Sure![Retrieval]<paragraph><paragraph>
のように回答できます。この[No Retrieval]などがreflection tokenです。 ↩︎ -
特に言及されていないため、GPT-3.5(+もしかしたらChatGPTの標準プロンプト?)での評価だと思われます ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion