はじめまして。株式会社ナレッジセンスの門脇です。普段はエンジニア兼PMとして、「社内データに基づいて回答してくれる」チャットボットをエンタープライズ企業向けに提供しています(一応、200社以上に導入実績あり)。ここで開発しているチャットボットは、ChatGPTを始めとしたLLM(Large Language Models)を活用したサービスであり、その中でもRAG(Retrieval Augmented Generative)という仕組みをガッツリ利用しています。本記事では、RAG精度向上のための知見を共有していきます。
はじめに
この記事は何
この記事は、LlamaIndexのAndrei氏による『A Cheat Sheet and Some Recipes For Building Advanced RAG』[1]という記事で紹介されている「RAGに関するチートシート」について、Andrei氏の許可を得て翻訳し、解説したものです。(※なお、このAndrei氏のチートシート自体、Y Gao et al.によるサーベイ論文[2]に多大な影響を受けています)
このチートシートを見たとき、「自分が実務でやっていることそのものだ」と感銘を受けたのを覚えています。とても有益なシートです。
元記事で紹介されているチートシートは非常に膨大だったため、何度かに分割して紹介できればと思います。
本記事は「基礎編」です。いわゆるAdvancedなテクニックは未だ出てきません。まずはエンジニアが、周辺のステークホルダーを説得するためのチートシートという感じに位置づけられそうです。
対象読者
- 生成AIに取り組むエンジニア。
- 生成AIに関わるビジネスサイドの方。
特にこの「基礎編」のチートシートは「エンジニアがビジネスサイドに説明するため」に有効活用できる内容だと思います。ご自身が理解するためにはもちろん、社内やクライアントにRAGについて説明するとき、必ず役に立つと思います。この基礎編のチートシートは、「RAGを全く知らない人に説明するときに伝えるべき全て」が必要十分に記載されているという印象です。
本題
RAGテクニック集(チートシート)
以下はチートシートです。元記事全体のチートシートのうち、「基礎編」に該当する部分だけ切り出しています。以下、更に細かく分けてこのシートを補足していきます。
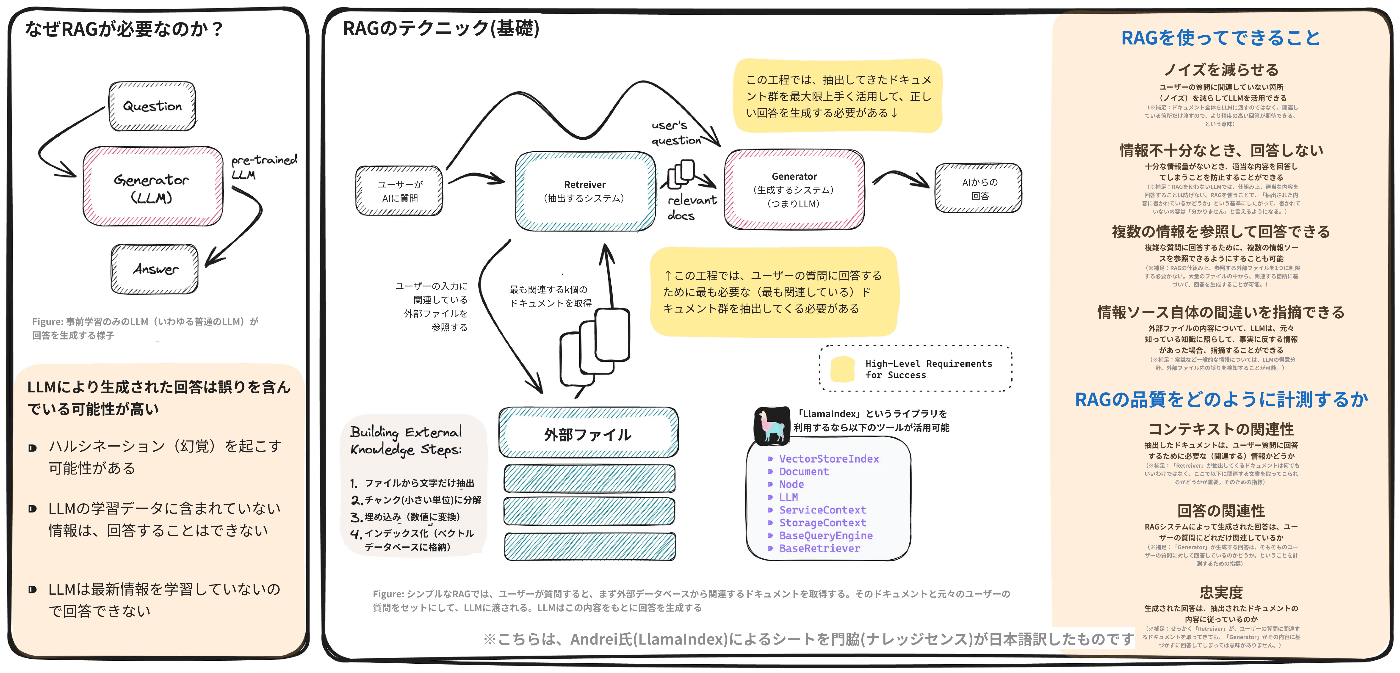
RAGとは。なぜ必要なのか?
RAGとは、大雑把に言うと、ファイルを参照して回答できるLLM(例えばChatGPT)を作成するための方法です。RAGがなぜ必要なのかというと、通常のLLMでは、回答の正確性を向上させるのに限界があるからです。通常のLLMでは、事実と違う内容を勝手に捏造してしまったり(ハルシネーション)、そもそも学習データに含まれていない情報(例えば公開されていない社内の文書)については、回答することはできなかったりという限界があります。

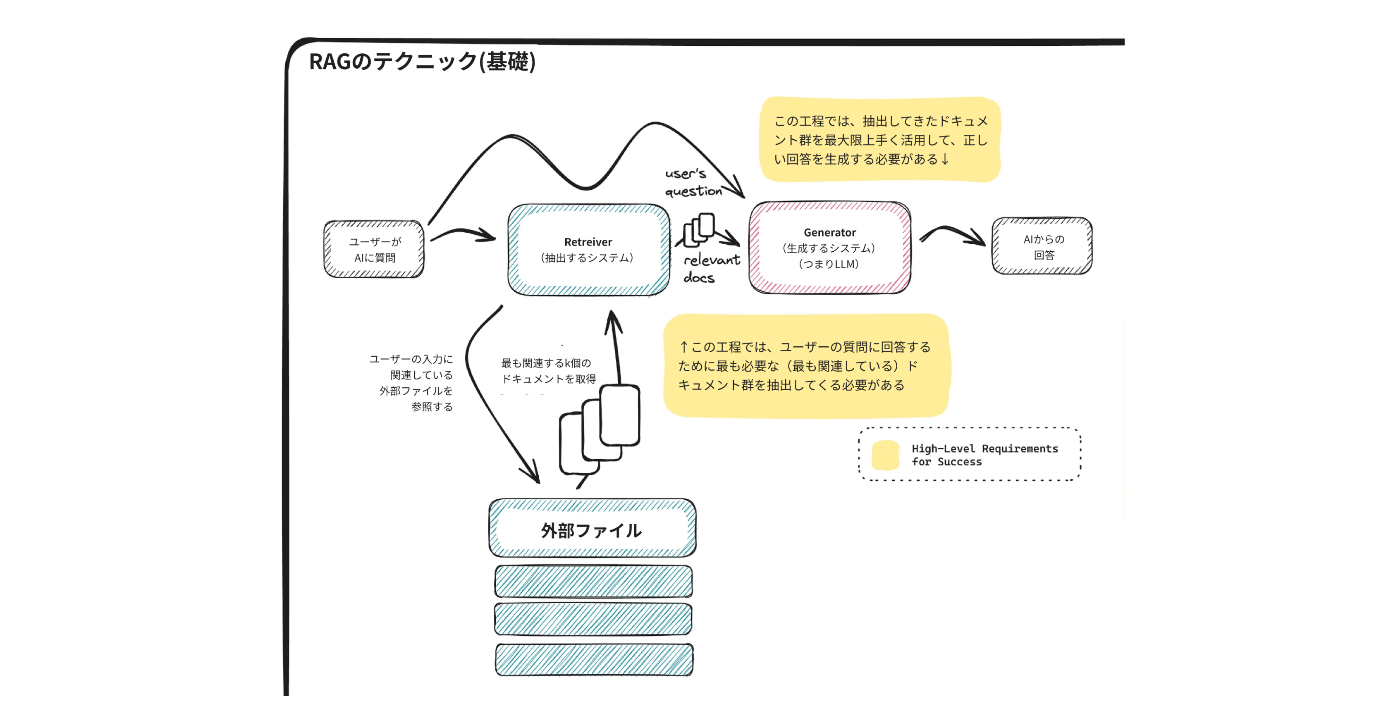
RAGの仕組み
この記事をご覧のエンジニアの方であれば、既にご存知の内容かと思います。以下、チートシートの引用です。
「RAGでは、ユーザーが質問すると、まず外部データベースから関連するドキュメントを取得する。そのドキュメントと元々のユーザーの質問がセットされ、LLMに渡される。LLMは、この内容をもとに回答を生成する」
非常にシンプルな内容なので、この図と一緒に説明すれば、ビジネスサイドの方でも理解してもらえます。私個人的にも、似たような図を使って顧客や社内ビジネスサイドに説明していて、必ず理解してもらえる印象です。
RAGの良さはこのシンプルさ、始めやすさなのですが、始めのうちは、なかなか思い通りの回答が得られません。この回答精度を上げようとすると、かなりの苦難が待っています...
RAGの精度向上のために必要なこと
RAGの精度向上を試みる際に重要な要素は、以下の2点に分解できます。
- ユーザーの質問に回答するために最も必要な(最も関連している)ドキュメント群を抽出すること
- 抽出してきたドキュメント群を最大限上手く活用して、正しい回答を生成すること
この2点は、上の「RAGの仕組み」で登場した画像の中の黄色い枠で囲まれている部分に該当します。
※具体的な手法は、今後の記事で紹介していきます
RAGを使ってできること

個人的には、実務でRAGを使っていて嬉しいポイントは
- 情報不十分なとき、回答しないことができる
- 独自のドキュメントに基づいて回答できる(上の画像には含まれていませんが)
ことです。画像中で4つ目に列挙されている「情報ソース自体の間違いを指摘できる」というのは使い所が分かりづらいですが、コード中のバグを探す、というようなユースケースが想定されてそうです。
また、画像中の1つ目にある「ノイズを減らせる」という点については、「LLMは、人間の質問が長いほど回答の精度が落ちる」(注[3])という点を前提にしています。大量の文章をLLMに解釈させるのではなく、関係あるだけ読んでもらって回答精度を向上させようよ、ということが可能になります。また、これはすなわち「金銭的なコストを節約できる」というメリットにも繋がります。大抵のLLMは、AIへの入力とAIからの出力の文字数で課金されるからです。
RAGの品質計測

「改善は計測から」なので、どのように評価するかは改善前に決めておく必要があります。
補足として、こちらの評価指標については、RAG評価ツールの「RAGAS」から、もう少し多くの指標が提案されています。[4]
まとめ
RAGのテクニックを紹介すると言いながら、この「基礎編」ではいわゆるAdvancedなテクニックは紹介できなかったのが心残りです。(今後の続編にて掲載するためお許しください🙏)
ただ個人的には、エンジニア向けのチートシートの中にガッツリ、この内容が含まれていることに意味があると思っていて、それは、「ステークホルダーを説得することも、エンジニアが身につけるべきテクニックである」ということだと思うからです。なので、このチートシートを早速社内で展開しています。
直近で続編を出す予定で、そこでは「チャンキング」や「ナレッジグラフ」などの手法に触れる予定です。(待てない方は、私の過去の投稿を御覧ください。割と内容か被りそうです...)
-
『A Cheat Sheet and Some Recipes For Building Advanced RAG』 ↩︎
-
Retrieval-Augmented Generation for Large Language Models: A Survey ↩︎
-
最近では、Gemini 1.5など、大量の文章を投下しても精度が落ちづらいモデルも登場してくる流れになっています。(リンク) ↩︎
-
https://docs.ragas.io/en/stable/concepts/metrics/index.html ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion