はじめまして。株式会社ナレッジセンスの門脇です。普段はエンジニア兼PMとして、「社内データに基づいて回答してくれる」チャットボットをエンタープライズ企業向けに提供しています(一応、200社以上に導入実績あり)。ここで開発しているチャットボットは、ChatGPTを始めとしたLLM(Large Language Models)を活用したサービスであり、その中でもRAG(Retrieval Augmented Generative)という仕組みをガッツリ利用しています。本記事では、RAG精度向上のための知見を共有していきます。
はじめに
この記事は何
この記事は、LlamaIndexのAndrei氏による『A Cheat Sheet and Some Recipes For Building Advanced RAG』[1]という記事で紹介されている「RAGに関するチートシート」について、Andrei氏の許可を得て翻訳し、解説したものです。(※なお、このAndrei氏のチートシート自体、Y Gao et al.によるサーベイ論文[2]に多大な影響を受けています)
このチートシートを見たとき、「自分が実務でやっていることそのものだ」と感銘を受けたのを覚えています。とても有益なシートです。
元記事で紹介されているチートシートは非常に膨大だったため、3回に分割して紹介しています。
本記事は最終回である「応用編-B」です。RAGの性能を高めるためによく知られている手法・テクニックを確認する位置づけです。
前回出した「応用編A」はこちら。
対象読者
- 生成AIに取り組むエンジニア
- (生成AIに関わるビジネスサイドの方)
特にこの「応用編-B」のチートシートは「エンジニアがRAGを改善するための定石を確認する」際に有効活用できる内容だと思います。
- 先日出した「基礎編」よりは、エンジニア向けです。
- 先日出した「応用編A」とは、難易度的な違いはありません。
本記事「応用編B」のチートシートは、一つ一つが独立したテクニックになっているため、効果が出そうなものから順に、スモールに改善を試していただければと思います!
本題
RAGテクニック集(チートシート)
以下はチートシートです。元記事全体のチートシートのうち、「応用編-B」に該当する部分だけ切り出しています。以下、更に細かく分けてこのシートを補足していきます。
基礎編の振り返り
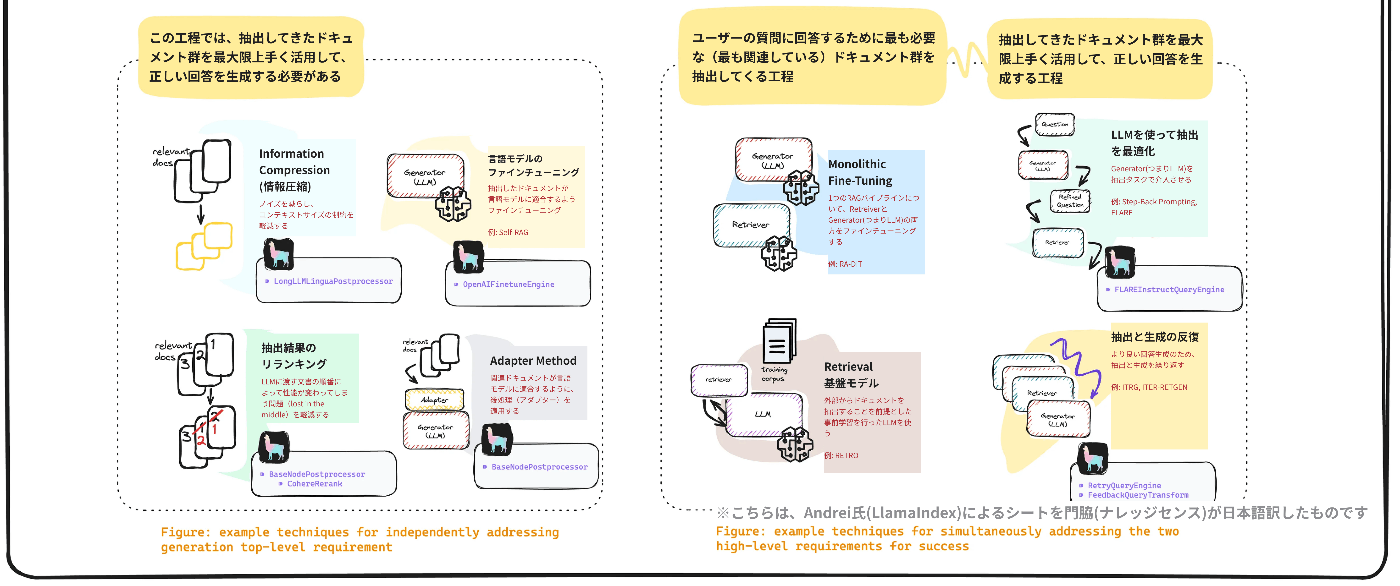
RAGの精度向上を試みる際に重要な要素は、以下の2点に分解できます。
- ユーザーの質問に回答するために最も必要な(最も関連している)ドキュメント群を抽出すること
- 抽出してきたドキュメント群を最大限上手く活用して、正しい回答を生成すること
「応用編-B」では、特に2つ目の「抽出してきたドキュメント群から適切な回答を生成する」ための具体的なテクニックについて見ていきます。
ドキュメントから適切な回答を生成するテクニック
抽出してきたドキュメント群を最大限上手く活用して、正しい回答を生成するためのテクニックは、以下のとおりです。
1. 抽出ドキュメントのリランキング
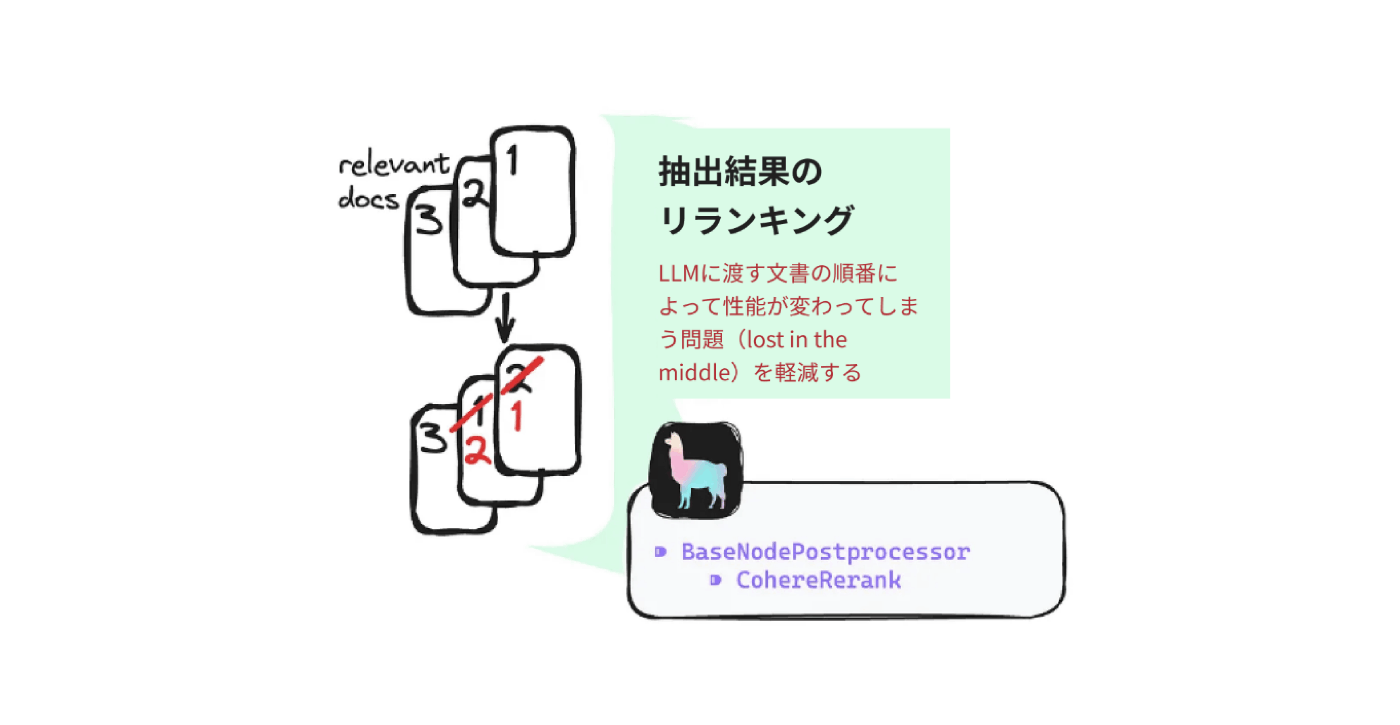
本記事で対応必須のテクニックが1つあるとしたら、こちらになると思います。
リランキングが必要な理由について、チートシートの中では「LLMに渡す文書の順番によって性能が変わってしまう問題(lost in the middle)を軽減する」ためとされていますが、実践的なRAGにおいて、リランキングの価値はそれだけではありません。リランキングは、ベクトル検索(埋め込みモデル)の弱みを補う意味でも重要です。
まず、リランキングとは、ベクトル検索で抽出したドキュメント群について「何らかの方法で並べ替えてからLLMに渡す」という手法です。並び替える方法は何でも良いのですが、大抵の場合、リランキング用の機械学習モデルを利用して、並び替えを行います。
ベクトル検索をした後にわざわざリランキング処理を行う理由は、ベクトル検索は、ざっくり言うと「早い変わりに精度がイマイチ」だからです(詳しい理由はこちら)。
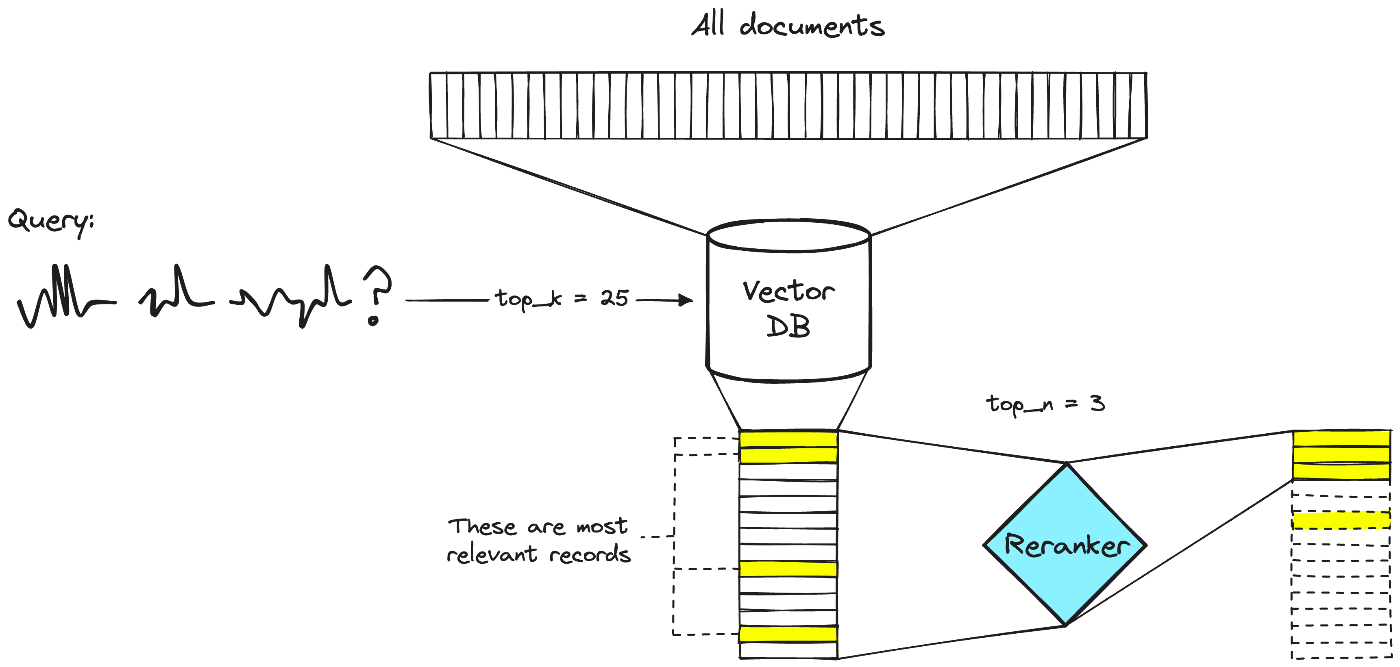
画像はPineconeの記事より引用
リランキングの例はこんな形です。まずベクトル検索で、関連するドキュメントをざっくり15件取得した後、リランキングモデルで更に精度高く、関連性の高い順に並べ直し、その上位3件をLLMに渡す。そうすることで、LLMが、より適切な回答を生成してくれる可能性を高めます。
実際、マイクロソフトによる研究[3]によると、「リランキング」によって、RAGの性能が大きく変わることが報告されています。

こちらの研究では、検索結果の上位1~5位で、関連するドキュメントを取得できたクエリの割合は、上の図のように報告されています。「Hybrid検索+リランキング」の手法を用いたときが、最もパフォーマンスが高いことがわかります。
リランキングに関するその他参考記事:
- Rerankers and Two-Stage Retrieval
-
メルカリにおける機械学習による検索のリランキングへの道のり
(→そのままRAGの記事ではないですが、LLM時代以前の、従来の検索技術は今日でも重要です)
2. 抽出ドキュメントを圧縮
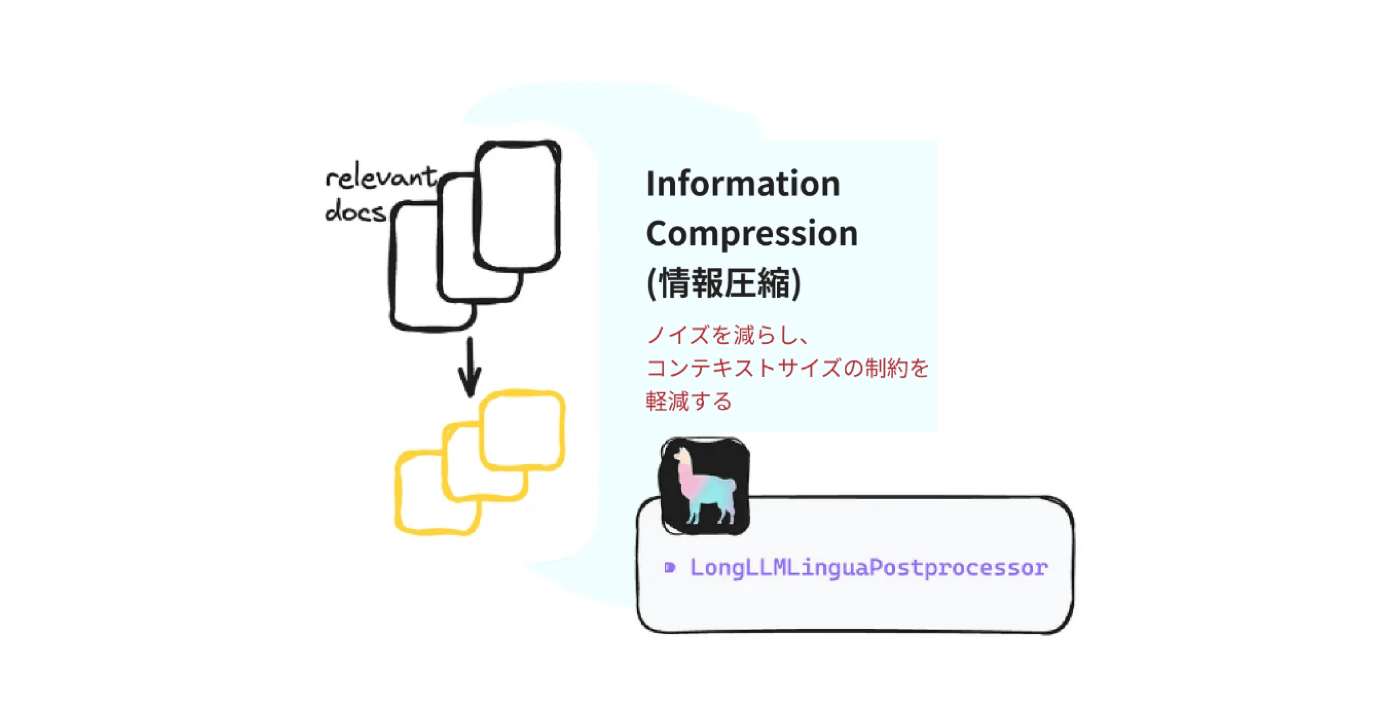
RAGでは、どうしてもプロンプトに入れる文字数が多くなりがちです。プロンプト文字数が多いと、回答精度、時間、金銭的なコストなどあらゆる点で問題が出てきやすくなります。そこで、抽出したドキュメントを、LongLLMLingua [4] のようなモデルを使って要約してからLLMに渡そう、というのが今回のテクニックです。注意点として、LongLLMLingua は、日本語ではあまりうまく行かないことが知られています。[5]
抽出ドキュメントを圧縮に関するその他参考記事:
3. Adapter Method

ここで紹介されている「Adapter Method」は、急に粒度が大きい話です。要は、抽出してきたドキュメントをLLMに渡す前に「色々処理しましょうね」というテクニックが紹介されています。先に登場した「リランキング」もここに含まれると思いますし、キーワードやメタデータでフィルタリングを効かせるのもここでやることです。
「Adapter」というキーワードがあったので、最初、効率的なファインチューニングを行うための「LoRA」[6]のような手法を、RAGに適用するという話なのかと思いましたが、違うようです。
※以下、かなり上級テクニックな印象で、多くの場合は、この手法に取り組む前に「もっと別のことが改善出来ないか」確認する方が良いと考えます。(例えば、「応用編-A」にあるテクニックなど)
4. 言語モデルのファインチューニング

通常のRAGでは、ユーザーの質問に関わらず、ドキュメントを検索し、その内容を元に回答を生成します。例えば「こんにちは」のような、RAGを必要としない質問に対しても、ドキュメントの検索を行ってから回答をしてしまいます。このような問題にはFunction calling[7]で対処をするのが一般的かと思いますが、Self-RAG[8]のようにモデルをファインチューニングして対応することもできます。
言語モデルのファインチューニングに関するその他参考記事:
5. その他のテクニック

■ Monolithic Fine-Tuning
一つのRAGパイプラインの中で、フィードバックを効かせながら両方改善していく
-
RA-DIT
→「抽出」が最適かどうかをLLMに判断させ、その結果をフィードバックして「抽出」を最適化。同様に、LLMが関連ドキュメントを本に最適な生成ができるようになるよう、ファインチューニング。
■ LLMを使って抽出を最適化
- Step-Back Prompting
-
Flare
→LLMによる出力をリアルタイムで監視し、信頼性が低いと判断された場合、その場で再度データベースから「抽出」し直す。ここで抽出し直すときのクエリとして、先ほど信頼性が低いとされた文章そのものを利用する。以下、Jiang, Z. et al.[9]より解説図を引用

■ Retrieval 基盤モデル
-
RETRO
→LLMに対し、外部からドキュメントを抽出することを前提とした事前学習を行う
■ 抽出と生成の反復
-
Self Correcting Query Engines - Evaluation & Retry
→回答として十分かどうかをLLMに判断させ、NGであればドキュメントの抽出からやり直す - 近い発想で、複数のLLMで生成させた内容をまとめるアンサンブル(Ensemble)手法(例:Silicon Crowd[10])でも、LLMの回答精度が向上することが報告されています。
まとめ
本記事は、これまで3回に渡って解説してきた「RAGでの回答精度向上のためのテクニック」の最終回です。この中では紹介しきれなかったテクニックもあるので、今後の記事でまとめようと思います。例えば「プロンプトエンジニアリング」は有名なテクニックですがかなり強力です。実際、OpenAI公式によるRAG解説動画[11]でも、かなり重要視されています。
最後になりますが、ソフトウェアエンジニアを募集しています。手前味噌ですが、弊社でエンジニアをやるのは本当に楽しいです。「最新の研究を、すぐに現場に適用して成果を実感できること」はシンプルに楽しいですし、何より、解こうとしている課題(大企業の社内データ検索・知的活動の最速化)が巨大なのでワクワクします。顧客の普段の業務に直結するサービスなので、アップデートの度に喜んでもらえるのも、シンプルに嬉しいです。業務委託も募集中。詳細はこちら。
今後も、現場で生成AIを運用した知見を共有していきます。
私の過去の投稿も、RAGの改善における参考になれば幸いです。
-
『A Cheat Sheet and Some Recipes For Building Advanced RAG』 ↩︎
-
Retrieval-Augmented Generation for Large Language Models: A Survey ↩︎
-
Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities ↩︎
-
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression ↩︎
-
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection ↩︎
-
Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion