はじめまして。株式会社ナレッジセンスの門脇です。普段はエンジニア兼PMとして、「社内データに基づいて回答してくれる」チャットボットをエンタープライズ企業向けに提供しています(一応、200社以上に導入実績あり)。ここで開発しているチャットボットは、ChatGPTを始めとしたLLM(Large Language Models)を活用したサービスであり、その中でもRAG(Retrieval Augmented Generative)という仕組みをガッツリ利用しています。本記事では、RAG精度向上のための知見を共有していきます。
はじめに
この記事は何
この記事は、LlamaIndexのAndrei氏による『A Cheat Sheet and Some Recipes For Building Advanced RAG』[1]という記事で紹介されている「RAGに関するチートシート」について、Andrei氏の許可を得て翻訳し、解説したものです。(※なお、このAndrei氏のチートシート自体、Y Gao et al.によるサーベイ論文[2]に多大な影響を受けています)
このチートシートを見たとき、「自分が実務でやっていることそのものだ」と感銘を受けたのを覚えています。とても有益なシートです。
元記事で紹介されているチートシートは非常に膨大だったため、何回かに分割して紹介しています。
本記事は「応用編A」です。RAGの性能を高めるためによく知られている手法・テクニックを確認するような位置づけです。先日出した「基礎編」は以下のリンクから読めます。
対象読者
- 生成AIに取り組むエンジニア
- (生成AIに関わるビジネスサイドの方)
特にこの「応用編A」のチートシートは「エンジニアがRAGを改善するための定石を確認する」際に有効活用できる内容だと思います。先日出した「基礎編」よりは、エンジニア向け・実装者向けのテクニック集になっています。この応用編のチートシートは、一つ一つが独立したテクニックになっているため、効果が出そうなものから順に、スモールに改善を試していけるものになっている印象です。
本題
RAGテクニック集(チートシート)
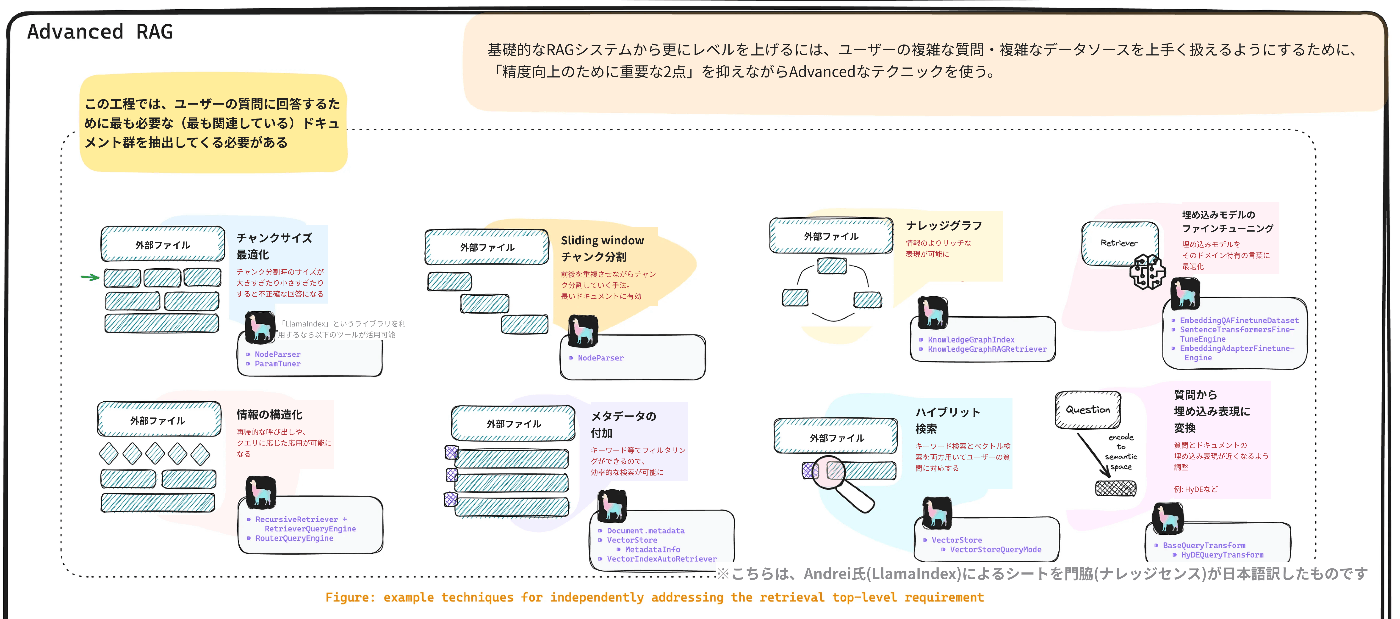
以下はチートシートです。元記事全体のチートシートのうち、「応用編A」に該当する部分だけ切り出しています。以下、更に細かく分けてこのシートを補足していきます。
基礎編の振り返り
RAGの精度向上を試みる際に重要な要素は、以下の2点に分解できます。
- ユーザーの質問に回答するために最も必要な(最も関連している)ドキュメント群を抽出すること
- 抽出してきたドキュメント群を最大限上手く活用して、正しい回答を生成すること
「応用編-A」では、特に1つ目の「ユーザーの質問に回答するために最も必要な(最も関連している)ドキュメント群を抽出する」ための具体的なテクニックについて見ていきます。
適切なドキュメントを抽出するテクニック
ユーザーの質問に回答するために最も必要な(最も関連している)ドキュメント群を抽出するためのテクニックは以下のとおりです。
1. チャンク分割を最適化する

基礎編でも見た通り、RAGでは「ドキュメントの中から、関連している箇所のみ言語モデルに渡す」という仕組みです。そのため、元のドキュメントを細切れ(チャンク)にして、データベースに保管します。
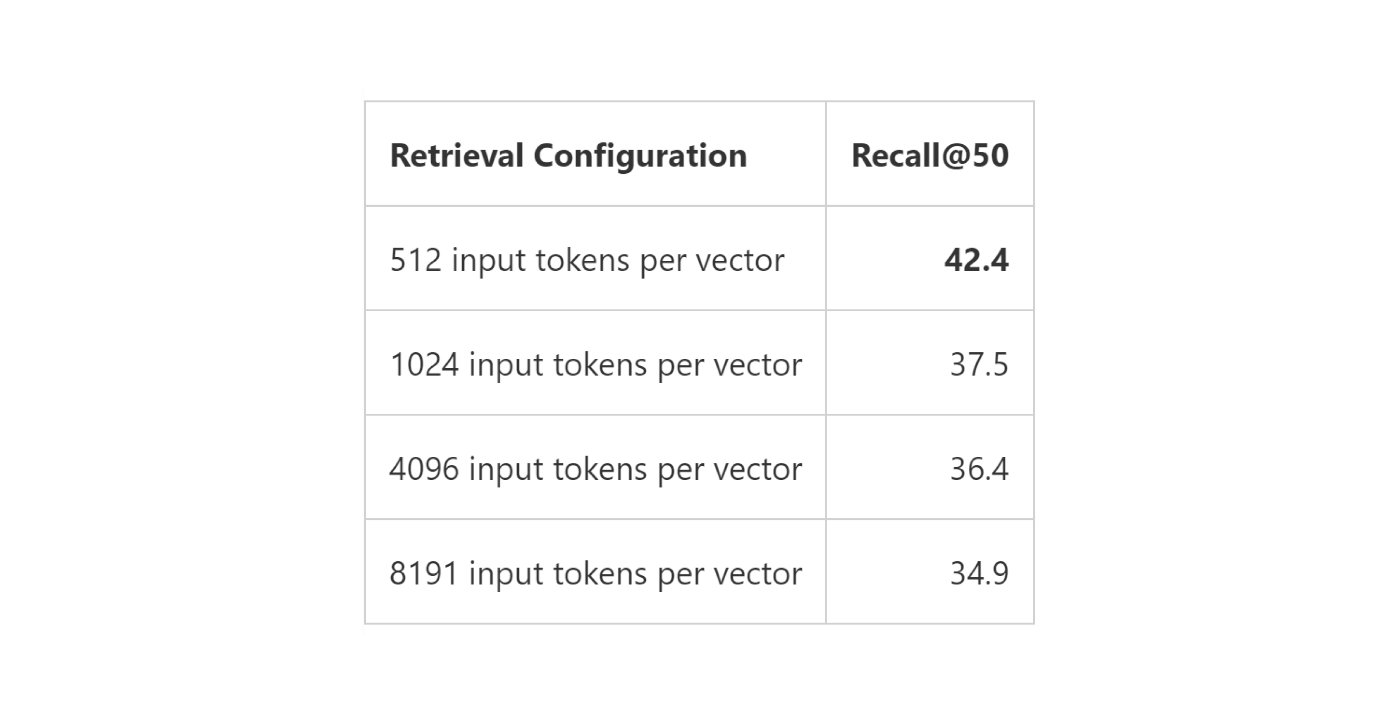
このチャンクを何文字単位で区切ってDBに格納するか(チャンクサイズ)、どの程度、前後のチャンクと内容を重複させるか、というのが重要なテクニックとなっています。チャンクサイズや重複は、ドキュメントの種類や想定利用方法によって、最適化の余地があります。
実際、マイクロソフトによる研究[3]によると、チャンクサイズによって、RAGの性能が大きく変わることが報告されています。
チャンク分割に関するその他参考記事:
2. ハイブリット検索

RAGでは、関連するドキュメント取得し、LLMに渡す必要があります。では膨大なドキュメント群の中から、どのように「今回のユーザーの質問に関連する」箇所を見つけ出せばいいのでしょうか。よく使われるのは、以下の2つの手法です。
- キーワード検索
- セマンティック(意味)検索
この点、書こうと思えば紙面が足りないので簡単に。
キーワード検索は、読んでそのままですが、ユーザーの質問の中で重要なキーワードを抽出し、そのキーワードが入っているチャンクを取ってくる手法。セマンティック検索は、ユーザーの質問と意味的に近いドキュメントを取得するため、ベクトル検索を活用する手法(ベクトル化しコサイン類似度が大きいものを取得する)です。
これらの手法が一長一短なので、両方を上手くブレンドして使うことで両方の良さを引き出しましょう、というのがハイブリット検索という手法です。例えばキーワード検索を50%、セマンティック検索を50%の割合で検索に活用する、ということも可能です。
実際、この2つの検索手法をどの程度の割合でブレンドするのが良いのか、日々研究されています(LlamaIndex[4]など)。一般的な最適なブレンド割合というものは当然ながら存在せず、どのような質問が想定されるかによって、最適な値は異なるという結論です。
3. 質問から埋め込み表現に変換(HyDE[5]など)

先程、セマンティック検索では、ユーザーの「質問」と、意味的に近いドキュメントを取得すると書きましたが、本来的にはユーザーの質問に対する「答えがありそうな」ドキュメントを取ってきたいです。そのため、HyDEという手法では、ユーザーから質問が来たら、一度それに対するダミー回答を(LLMで)生成し、そのダミー回答を使ってセマンティック検索をする(回答と意味的に近いドキュメントを取得する)、ということが行われます。この手法、当然ながらダミー回答の質によって検索の精度が左右されてしまいますので、得意/不得意なタスクがはっきりしている印象ですが、一度は試してみる価値があります。
4. 情報の構造化

複数のチャンクを(LLMで)要約した「親ノード」を作成しておき、この木構造を利用して検索する手法。
情報の構造に関するその他関連記事
- https://twitter.com/jerryjliu0/status/1636390216247431174
- Different types of indexes in LlamaIndex to improve your RAG system.
5. メタデータの付加
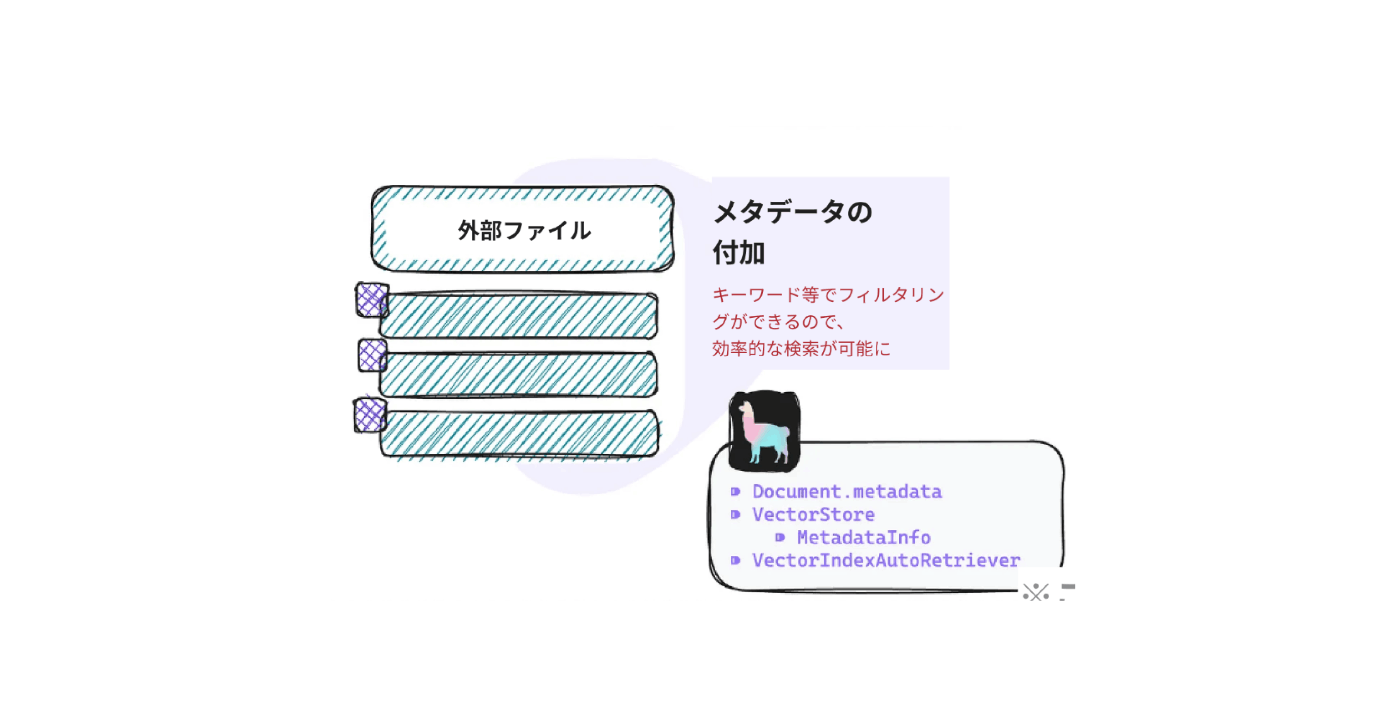
チャンクと一緒にメタデータ(ページ数やファイル名、作者など)を持っておくことにより、フィルタリングに利用したり、そのチャンクが全体におけるどういう位置づけなのか、LLMが解釈するために役立ちます。
メタデータに関するその他関連記事
以下2つは、かなり上級テクニックな印象で、多くの場合は、この手法に取り組む前に「もっと別のことが改善出来ないか」確認する方が良いと考えます。
6. ナレッジグラフ

グラフデータベースに情報を保管する手法。取り出すときはこれまでと同様、キーワード検索か意味検索、またはハイブリット検索を利用。質問内容に対する網羅的な知識の獲得を目指します。
ナレッジグラフに関するその他関連記事
- https://twitter.com/jerryjliu0/status/1625531410508562432
- https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/C9-2.pdf
7. 埋め込みモデルのファインチューニング

意味検索をするためには、文字→ベクトル化するための埋め込みモデルが必要です。埋め込みモデルはオープンソースで公開されているものや、OpenAIによるEmbeddings APIを利用することが一般的です。しかしながら、公開されているモデルでは、専門的な単語や社内用語などについては上手にベクトル化することができません。この課題を克服するために、埋め込みモデル自体をファインチューニングするという手法が考えられます。
埋め込みモデルのファインチューニングの関連記事
まとめ
RAGのテクニックの中でも「適切なドキュメントを抽出する」という観点で、重要なものを解説しました。中には応用的すぎるものもありましたので、成果が出そうなものから取り組むのが良いと思います。(弊社でも試したことがないものも、紹介してしまいました🙏)
次回は最終回になる予定で、「抽出したドキュメントから適切な回答を生成するテクニック」を紹介します。直近で出す予定で、そこでは「リランキング」や「LongLLMLingua」などの手法に触れる予定です。(待てない方は、私の過去の投稿を御覧ください。)
-
『A Cheat Sheet and Some Recipes For Building Advanced RAG』 ↩︎
-
Retrieval-Augmented Generation for Large Language Models: A Survey ↩︎
-
Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities ↩︎
-
LlamaIndex: Enhancing Retrieval Performance with Alpha Tuning in Hybrid Search in RAG ↩︎
-
Precise Zero-Shot Dense Retrieval without Relevance Labels ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion