株式会社ナレッジセンスは、エンタープライズ企業向けにRAGを提供しているスタートアップです。本記事では、RAGの性能を高めるための「LongRAG」という手法について、ざっくり理解します。
この記事は何
この記事は、RAGの文脈消える問題を克服する新手法「LongRAG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
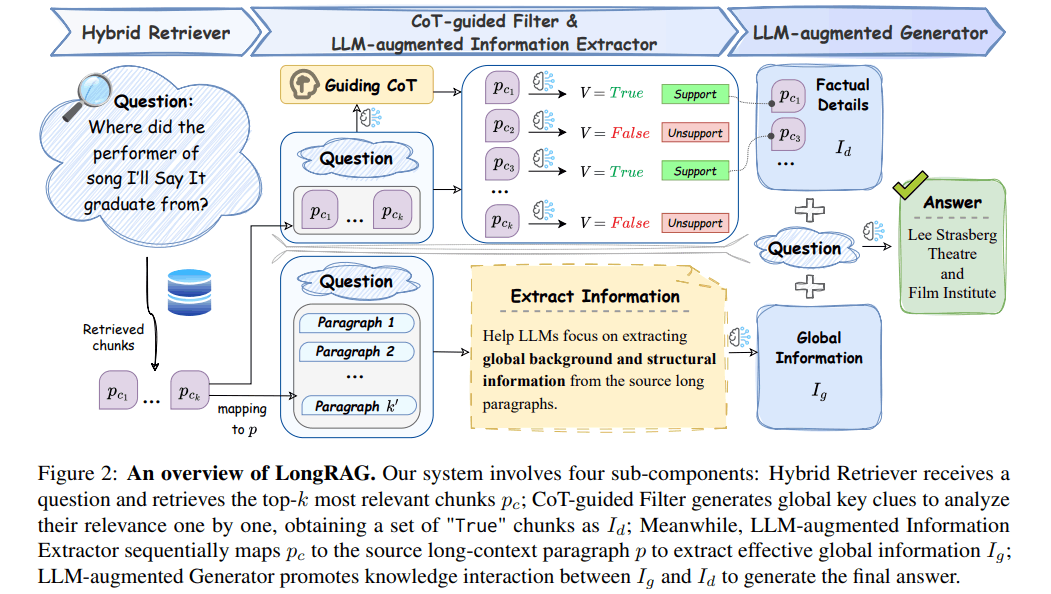
LongRAGは、「文書全体を読まないと正答できない」ようなタイプの質問に対しても、RAGの精度を上げるための新しい手法です。中国科学院・清華大学の研究者らによって2024年10月に提案されました。
ざっくり言うと、LongRAGとは、「階層化」+「フィルタリング」です。 2つとも、よく知られたRAGの手法ですが、これらを組み合わせることで、RAGの課題を克服します。
もう少し詳しく説明します。通常のRAGの問題点は、前後の文脈が失われたり[2]、重要な情報を見落としたり[3]することです。これが起きる理由は、RAGが、長文をチャンク(断片)に分割して処理するためです。
そこで、LongRAGは、チャンク単体だけでなく、①チャンクの前後文脈の活用、②関係ないチャンクの排除という2つの手段を使って、この課題を解決します。
問題意識
大規模言語モデル(LLM)は便利ですが、欠点もあります。(例えば全てのLLMには、入力上限があります。)RAGは、そうした欠点を補えますが、それでも従来のRAGだと、限界があります。
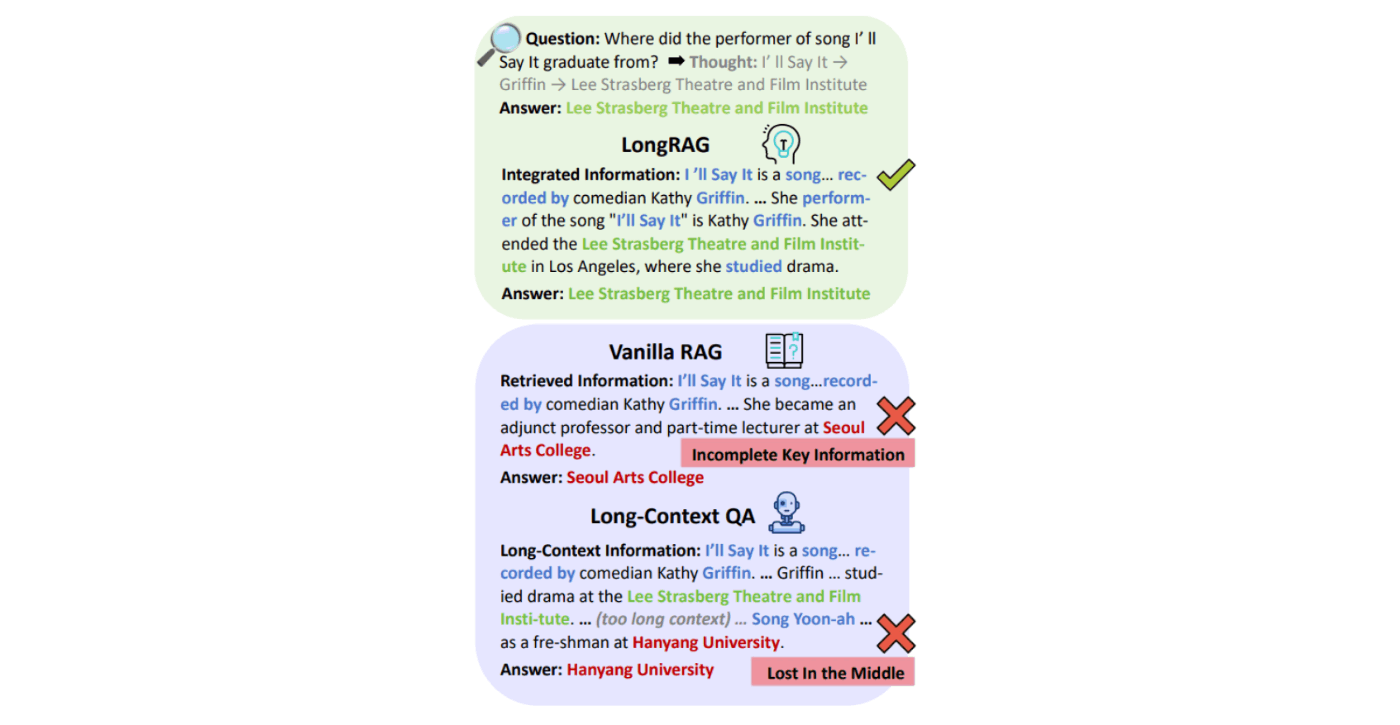
従来のRAGの限界として、以下があります。
- チャンキング(文書の分割)によって前後の文脈が失われる
- 飛び地にある重要情報をとってこられない
- では、関連ファイルを大量にLLMに渡せばいいか?と言うと、そうではなく。関係ない情報を多くLLMに渡すと、幻覚を起こす可能性がある
手法
LongRAGは複数の手法の組み合わせなので、少し複雑です。
【ユーザーが質問を入力して来たとき】
-
ベクトル検索+リランキング
- 普通のベクトル検索で、数チャンク取得
- cross-encoderモデルを使って、その数チャンクをリランキング[4]
-
チャンクが書かれていた段落を特定 (画像の中央下段)
- 1のチャンクそれぞれが所属していた段落を、元文書から取得
- その段落とユーザーの質問を、小さいLLMに渡し、関連情報を抽出させる
-
CoTで必要情報を洗い出し、フィルタリング (画像の中央上段)
- 小さいLLMに、Chain-of-Thoughtさせ、ユーザーの質問の解決に必要なステップを作成
- 小さいLLMに、全チャンクを渡す。各チャンクの重要性を判定
- 必要なチャンクのみ次のステップに進む
-
最終回答の生成
- 2,3の情報を合わせて、最終的な回答を生成
- 大きいLLM(GPT-3.5など)を使う
LongRAGのキモは、検索後の後処理です。RAGの手法は色々ありますが、検索時の処理を頑張る手法と、検索されたものを頑張って処理する手法、大きく2つに分けられます。検索前を頑張る手法は、これまでも多く紹介しました。今回の手法は、「検索されたものを以下に料理するか」というところに力点があります。これの重要なポイントは、「検索時に頑張る手法」と組み合わせると、さらに精度改善の可能性があるという点です。
ただしこの手法、回答生成にかかる時間が、かなり遅いです。。。
成果
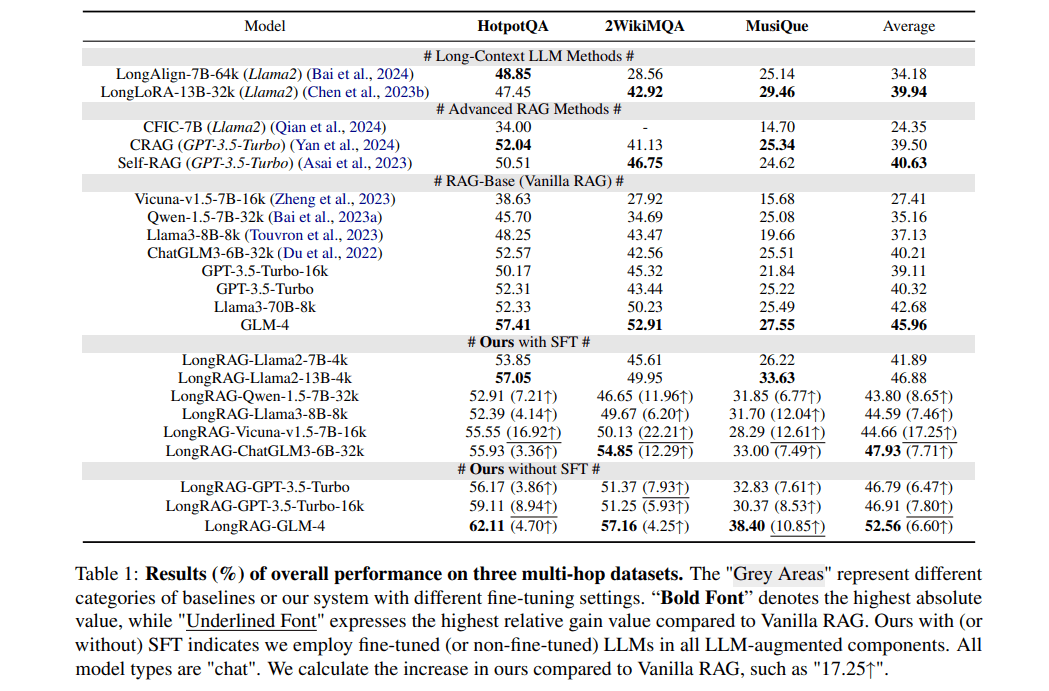
- 普通のLLMを使った場合と比較して6.94%の性能向上
- Advanced RAG(Self-RAG[5]やCRAG[6]など)を使った場合と比較して6.16%の性能向上
- 通常のRAG (Vanilla RAG)と比較して17.25%の性能向上
- 小規模なローカルLLMでも、GPT-3.5-Turboに匹敵する性能を実現
まとめ
RAGのよくある課題をまるっと解決する、素晴らしい手法だと感じました。「よくある問題」を、個別に解決しようとする手法はありましたが、こうして最小限のパートだけ組み合わせて、調和させることで精度向上しています。回答が遅いという問題は残りますが。。。
実際、普段エンタープライズ向けにRAGを提供していると、「遅くてもいいからより正確な回答が欲しい」というシチュエーションは結構あります。まだまだRAGは完璧ではないので、だからこそ、精度・速度・その他のニーズのようなトレードオフを、いかにバランスさせるかが重要です。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion