株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ向けに開発提供しているスタートアップです。本記事では、RAGの性能を高めるための「MoGG」という手法について、ざっくり理解します。
この記事は何
この記事は、社内用語が多く含まれるドキュメントでもRAGの性能を高くするための手法「MoGG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
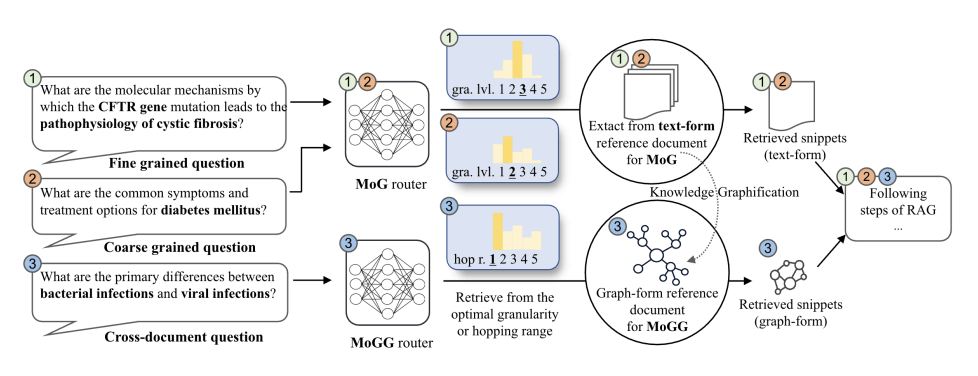
MoGG(Mix-of-Granularity-Graph)は、RAGの精度を上げるための、新しいチャンク分割の手法です。MoGGでは、チャンクとグラフ構造を上手く組み合わせることで、専門用語・社内用語が多いドキュメントでも回答精度を向上させることができます。上海人工知能研究所と北京航空航天大学の研究者らによって2024年6月に提案されました。
通常のRAGでは、文書を「固定のチャンクサイズ」で分割します。例えば、文書を「上から順に200文字ずつ」のチャンクに小分けにします。こうしてしまうと、チャンクの外にある情報が削ぎ落ちてしまいます。特に、この場合、「脚注」みたいな形で離れたところに用語説明があるような文書で、かなりRAGの回答精度が落ちます。
そこで、MoGGでは、①複数のチャンクサイズを動的に使い分ける、②チャンクをグラフ構造で表現するという新しいチャンク分割の手法を提案しています。こうすることで、「脚注」のように離れた場所にある情報も、全て含めた情報抽出をすることができるようになります。
問題意識
従来のRAGの課題として、用語の説明が離れた場所に書かれていると、精度が上がらないという点がありました。
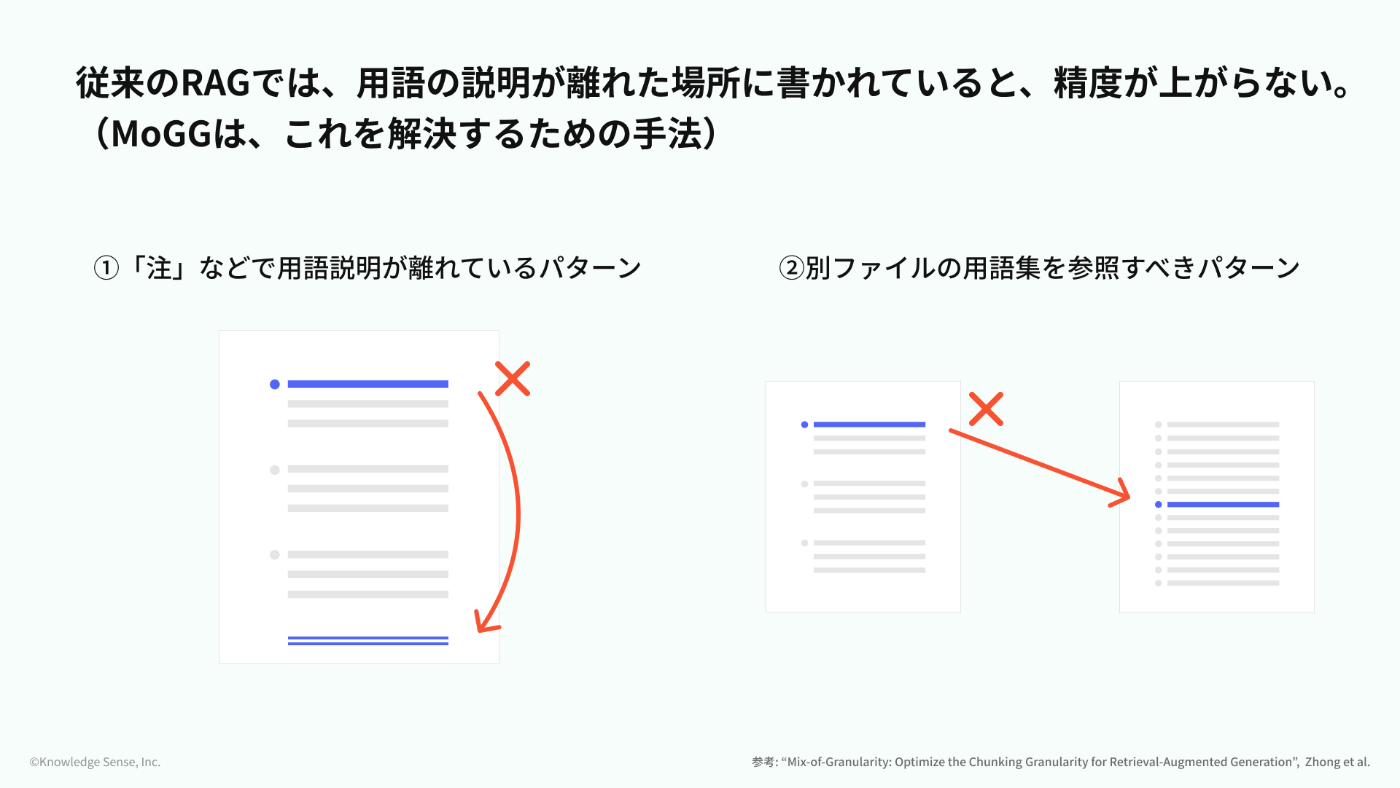
例えば、以下のような文書です。
- 1つの文書の遠く離れた場所に、「脚注」のような形で用語の定義が記載されているパターン
- 「XXについてはYY.pdfを参照」というように「用語集」を参照しなければいけないパターン
実際、多くの大企業のRAG支援をしてきた弊社の経験から言っても、こういう文書はかなり多いです。。。
手法
MoGGは、文書を1-2文のチャンクに分けた後、それぞれのチャンクの意味的な類似度に応じてグラフ構造を作成する手法です。
ちなみにMoGGは、「MoG」という手法の拡張版。MoGとは、複数のチャンクサイズを用意しておき、ユーザーの入力に基づいて動的に取得サイズを変える手法です。
MoGGは、以下の2つの要素の組み合わせです。
-
Mix-of-Granularity (MoG):
- 複数のチャンクサイズを用意し、ユーザーの入力クエリに基づいて最適なチャンクサイズを動的に選択する手法。
- この選択を行うために「ルーター」を自前で実装。(←今回はあまり深く触れません🙏)
-
グラフ構造:
- ドキュメントをグラフ形式で前処理。
- ユーザーの入力に合わせて「グラフを何ホップしたところまで情報抽出するか」を動的に選択
具体的な手順は以下の通りです。
【事前準備】
- 文書を1〜2文に分割し、各片をグラフのノードとする。
- 意味の近いノード間にエッジを設定してグラフ構造を構築。
【ユーザーが質問を入力して来たとき】
-
ユーザーの質問に応じて「グラフを何ホップ」するべきか決定
(→「MoG」の「ルーター」を利用するのですが、詳細は割愛) - 1で決定した「ホップ数」の分、グラフを探索しチャンク情報を収集
- 2で収集したチャンクを、参考文書としてLLMに渡す(ここは通常のRAGと同じ)
MoGGという手法のキモは、細切れにしたチャンク同士に結びつきを与えている部分です。これにより、これまでのRAGでは実現できなかった、「チャンクAが必要なら、チャンクBの情報も併せてLLMに渡した方がいいよね」という、理想的な結びつきを実現することが出来ます。
成果
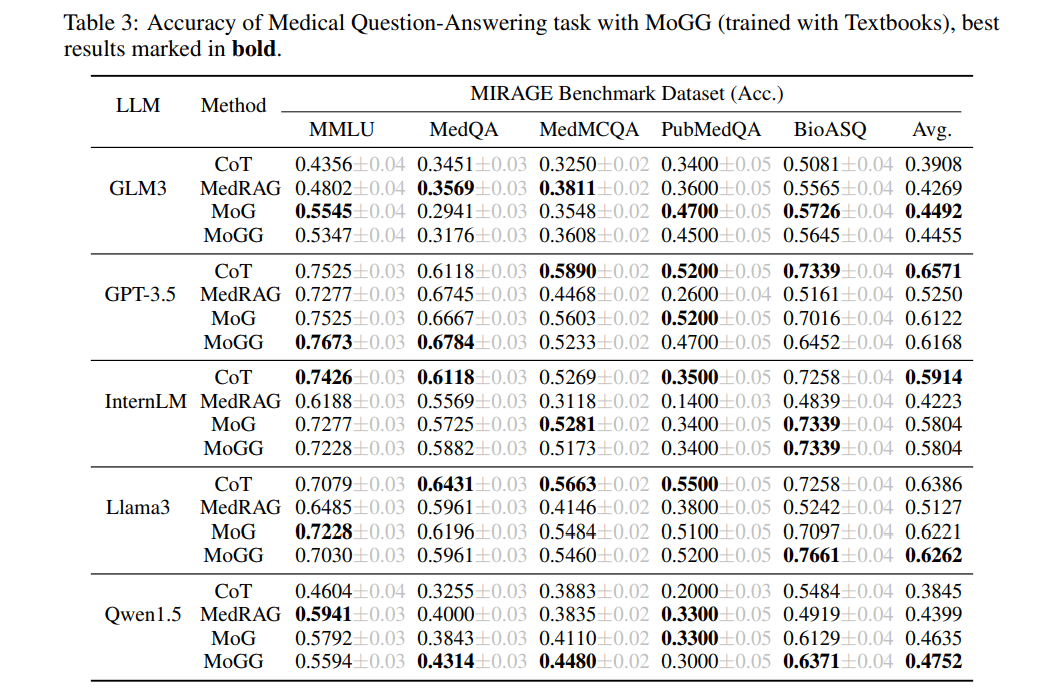
- 特に医療分野の質問応答タスクにおいて、RAGシステムの精度が向上
→「MedRAG」と比べて、平均では全てMoGGが勝っている - 特に情報が分散している場合に、さらなる性能向上
- 小規模なLLM(ChatGLMやQwen)ほど、MoGとMoGGによる性能向上が顕著。
画像右端にある「Avg.」というところを見ると、一応、全てのモデルで従来のRAGである「MedRAG」よりも「MoGG」が優れているのが分かります。
まとめ
弊社では普段、法人向けにRAGシステムを提供しています。その中で一部の企業では「社内用語を含む文書だと、RAGの回答精度が低い」という問題がたびたび起きます。そういう問題についてはMoGGという手法が活躍します。
逆に正直な話、MoGGという手法は、いわゆる「万能」なチャンク分割手法ではないです。しかし、社内文書に規定が多かったり、「注」が多かったり、「用語集」が多かったりするような企業では、かなり使えるRAG手法です。
ちなみに、「RAGが専門領域に弱い」という問題を解決する手法は、他にもありますのでご参考ください。[2][3]
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion