株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ向けに開発提供しているスタートアップです。本記事では、RAGの性能を高めるための「Golden-Retriever」という手法について、ざっくり理解します。
この記事は何
この記事は、RAGシステムを専門用語に強くするための手法「Golden-Retriever」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
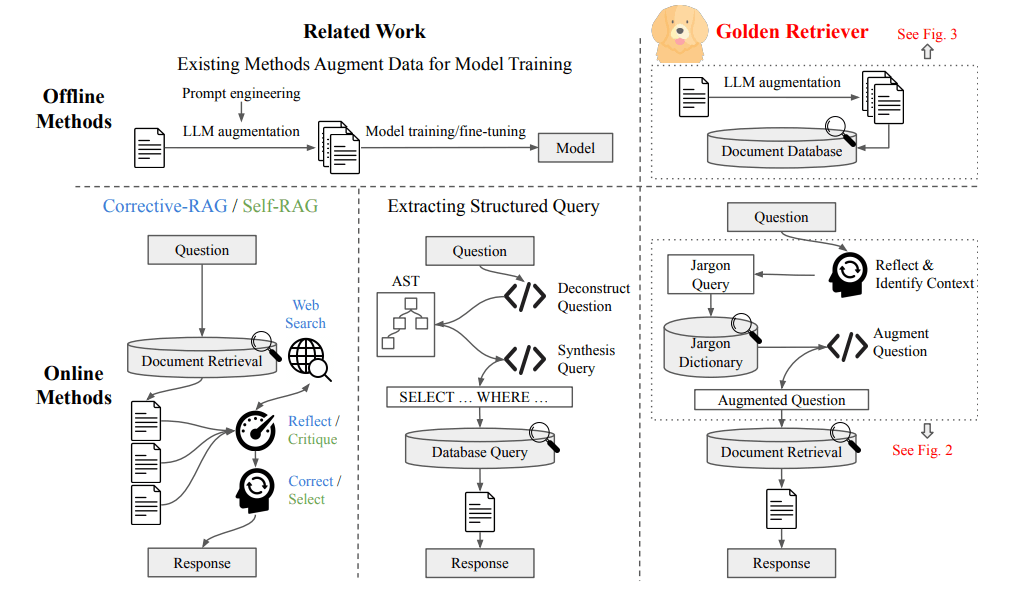
Golden-Retrieverは、RAG(Retrieval Augmented Generation)を、業界特有の用語・社内用語を含むような質問に強くするための手法です。カリフォルニア大学の研究者らによって2024年8月に提案されました。
従来のRAGシステムは、専門用語を含む質問に弱いです。最近登場したRAGの工夫(例えばCRAGやSelf-RAG)を使うことで、RAGの回答精度が上がることが知られています。しかし、これらの工夫を用いても、依然として専門用語には弱いです。
Golden-Retrieverは、質問に含まれる専門用語の意味を明確にしてからドキュメントの検索を行うことで、精度の高い回答生成を実現します。
問題意識
Retrieval-Augmented Generation (RAG) は便利ですが、専門用語は得意ではありません。例えば「MVP」という言葉。「最も活躍した人」という意味もありますが、IT業界では「最小限の機能を持った製品」(Minimum Viable Product)という意味です。
このように、特に大きい企業ほど、社内の人しか理解できない専門用語や業界用語(いわゆる「ジャーゴン」)があるのではないでしょうか。LLMや埋め込みモデルは、公開データで学習していています。そのため、このような用語をうまく解釈できず、RAGの性能が落ちます。
手法
Golden-Retrieverは、ユーザーから質問が来た際、まず「専門用語が含まれているか」を確認し、含まれていたら専門用語データベースで意味を検索。意味を明確にしてからRAGする手法です。
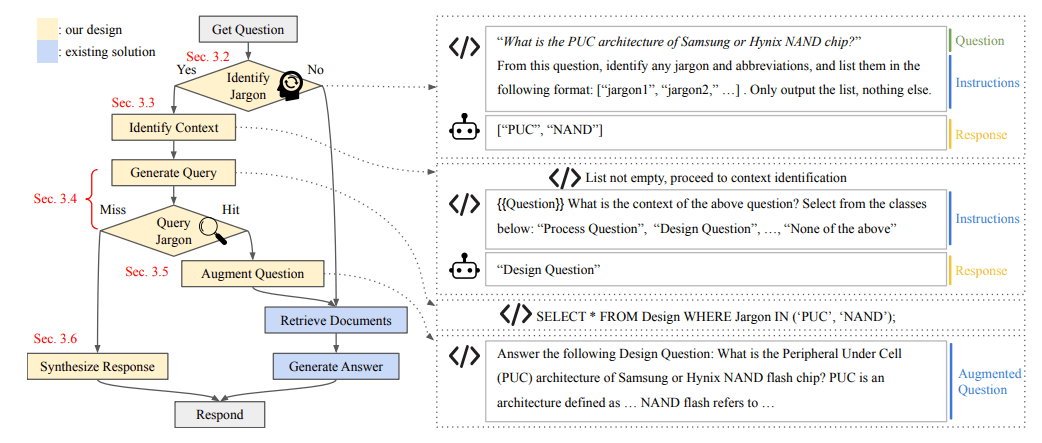
【事前にやっておくこと】
- RAGに使いたいデータについて、OCR(光学文字認識)でテキスト抽出
- 抽出されたテキストを、チャンクに分割。要約チャンクも作成して保管
【ユーザーが質問を入力して来たとき】
- ユーザーの質問に含まれる専門用語を抽出
- 1について、用語集DBを検索して意味を明確化
- ユーザーの質問が、どういう文脈の用語なのかLLMに分類させる
- 2,3の内容をもとに、文書検索を行う(以下、通常のRAG)
Golden-Retrieverという手法のキモは、①専門用語を抽出→②意味の明確化を行っている部分です。専門用語の意味が載っているデータベースを検索するためのSQLを自動生成することで、自動的に意味を明確化します。専門用語のデータベースは最初から存在している前提ですが(笑)、多くの企業では、何らかの形で「用語集」があるのではないでしょうか。
成果
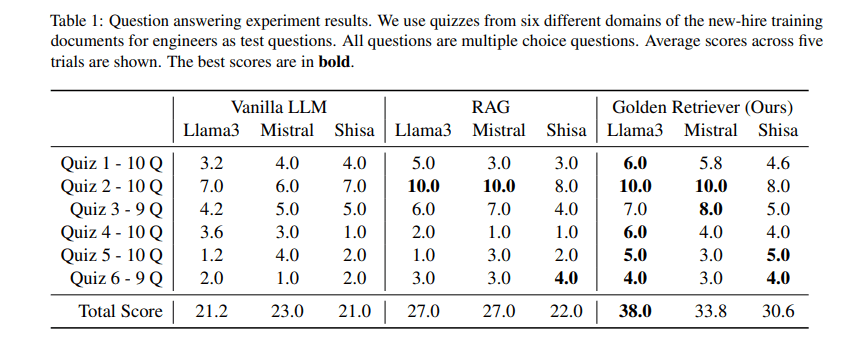
- Meta-Llama-3-70Bのスコアを通常のLLMに比べて79.2%、RAGに比べて40.7%向上させた
- 3つのLLM全体での平均改善率は、通常のLLMに対して57.3%、RAGに対して35.0%
生成速度についての言及はありませんが、おそらく通常のRAGより生成速度が遅くなる点は、この手法のデメリットとなりそうです。
まとめ
弊社では、まさに「企業向けのRAGシステム」を提供しているので、「RAGを専門用語に強くして欲しい」というご要望を、本当に多くいただきます。弊社では、今回紹介した手法に限らず、あらゆる手を尽くして、専門用語にも強くなるよう努力していますが、まだ完璧ではありません。今後もこの分野の研究は増えるのではないかと考えます。
RAGの開発者としては、「LLMやエンべディングモデルは公開データで学習しているので、社内用語をうまく解釈できない」とう大前提に立って開発することが今後も重要そうです。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion