導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
RAGのシステムでは一般的に、断片化されたテキストをEmbeddingによってベクトル化し、関連する情報を検索、そして質問に回答するという形式が採用されるかと思います。
しかし本来、RAGのデータソースは断片化されたテキストに限定はされていません。その一つとして、Knowledge Graph(知識グラフ)というものが存在します。
本記事では、そんなKnowledge Graphを利用した新しいRAGのシステム、GNN-RAGについて紹介します。
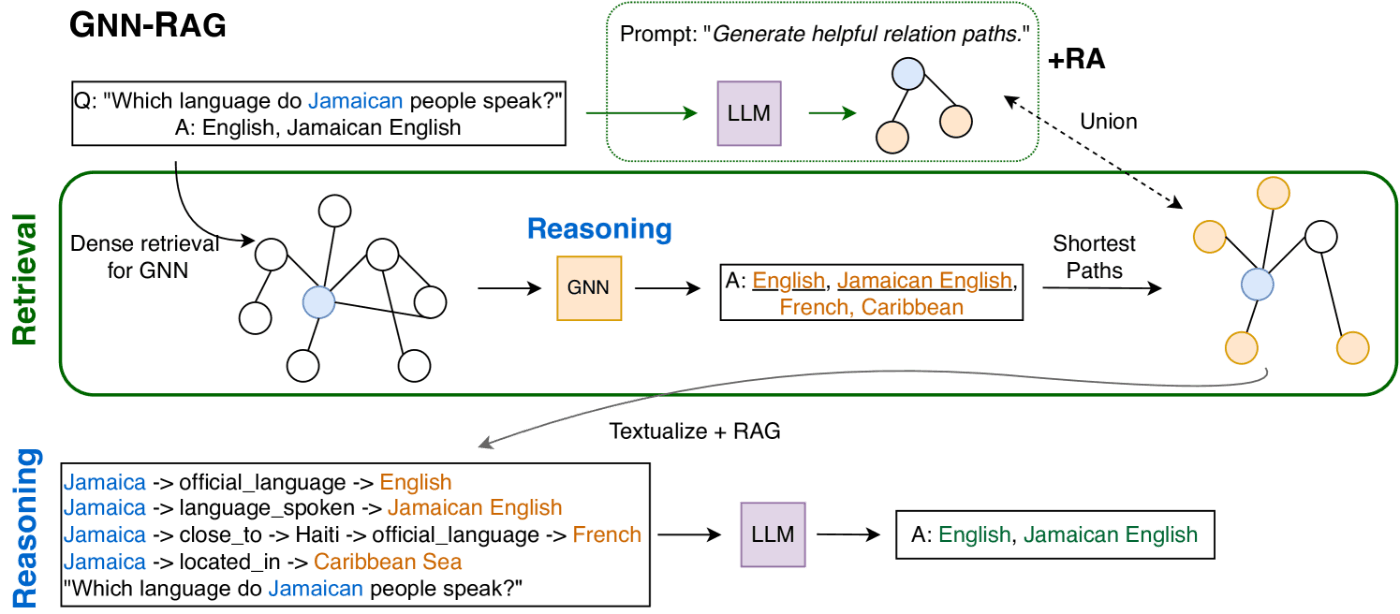
サマリー
GNN-RAGは、Knowledge Graphから関連するデータの取得にGNNを使用します。この手法を利用することで、既存のKnowledge Graphを利用したQAと比較して以下のような成果を上げています。
- 従来のKnowledge Graphを使用したQAの手法と比べて8.9~15.5%性能を改善
- 7BレベルのLLMでもGPT-4と同等の性能
精度の面だけでなく、小規模なLLMでもQAの精度を担保できるという点で優れているようです。
この記事について
この記事では、RAGのデータソースの一つであるKnowledge Graphを効率良く扱うための手法である、GNN-RAGについて紹介します。これまで紹介したことのない点も多いため、そのあたりを含めて簡潔に解説していこうと思います。
解説
GNN-RAGの解説の前に、まずKnowledge GraphやGNNに関する簡単な解説を行います。詳細な解説をすると長くなってしまうので、GNN-RAGと関わる部分に絞って説明します。
Knowledge Graph(知識グラフ)とは
Knowledge Graphは、2つの要素の関連性を言葉で表現しそれをグラフ上にまとめた構造を表しています。画像内の言葉を引用すれば、「Cows -> eat -> Herbs」などのように表現されます。グラフで言うところの頂点は「Cows」、「Herbs」が該当し、「eat」が辺に該当しています。
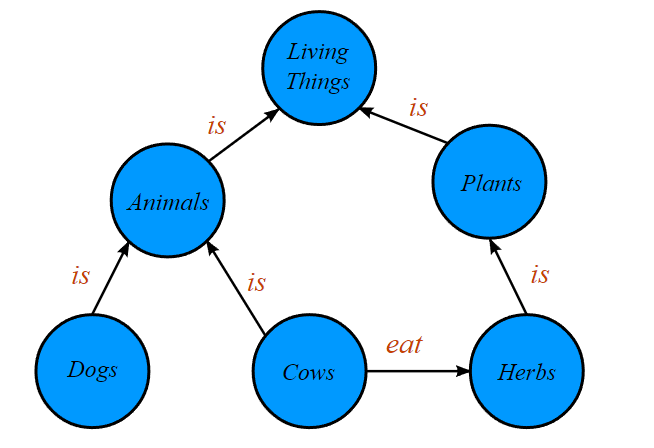
By Jayarathina - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=37135596
論文に記載されているわけではないですが、断片化されたドキュメントデータと比較すると、
- データの関係性にフォーカスしているため情報を集約しやすい
- 前後関係に縛られにくい分、コンテキストを失いがち
- 保管できるデータの内容に偏りが生じやすい
といった特徴を上げることができるかと思います。
GNNとは
GNNとは、Graph Neural Networksの略称でグラフを利用したニューラルネットワーク全般を指しています。SNSの関係性を学習したり、交通情報を学習したりと幅広い分野で使用されています。
なぜGNNを使用するのか
論文ではGNNを利用するメリットとして、質問に対する複数の関係性や関係性の遠い情報の取得に優れている点に触れています。
比較結果として以下のような表を掲載しています。

この表は、隣り合う情報を取得するタスクでは既存の手法のほうが優れた成果を上げていることを示しています。対照的に、2つ以上離れている情報を必要とする質問に対してはGNNを使用した手法がより優れていることを示しています。
手法
GNN-RAGは、GNNを使用する関係上事前に学習が必要となります。しかし、既存の手法を使用することになるので、それぞれの手法の説明は行いません。詳細な学習方法や計算式等は元の論文を参照してください。
また、コードがGithubで公開されているので、実装が気になる方は以下を参照してください。
検索方法
検索のゴールは、Knowledge Graph内の回答Entityとそこにいたる関係性の抽出です。また、論文内では別々の手法で取得したグラフ情報を組み合わせることでさらに精度を上げる試みを行っているので、その点を含めて説明します。
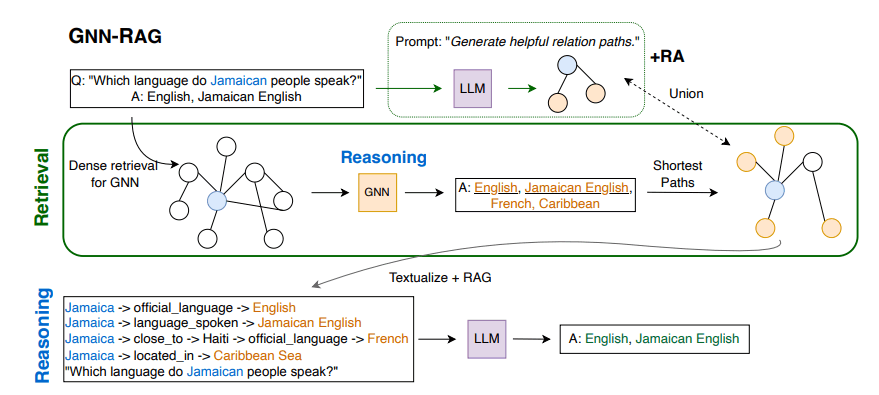
1-1a. 関連するサブグラフの抽出
別の論文になってしまうので詳細は割愛しますが、以下の論文の手法を使用して質問に関連するサブグラフの抽出を行います。
この論文内の手法を利用することで、関連性の高い情報に限定したEntityで構成されたサブグラフを取得する事ができます。
1-1b. GNNを用いた関連Entityの抽出
取得されたサブグラフから、回答を抽出する手法にはReaRevという手法を使用しています。
この手法は質問に対して、関連性の高いEntityを取得する機能を提供しています。ただし、どういう辺をたどって関係しているかまでは出力されません。なので辺の抽出には、質問Entityと回答Entityとを結ぶ最短経路を機械的に選択し、それらを組み合わせてサブグラフとして抽出します。
1-2. LLMを使用したサブグラフの取得(オプション)
LLMを使用したグラフ抽出の利点を享受するために、オプション的にRAという呼び名でサブグラフ抽出を別途行なう手法も提案されています。
論文内ではRoGという手法を採用しています。
この手法はLLMに、Entityからどういった関係性をたどっていけば、質問に回答するために必要な情報にアクセスできるかを予測させます。そしてそれを実際のKnowkledge Graphに当てはめることで、回答データにたどり着く手法となっています。
2. LLMを使用し回答を生成
1で取得したグラフを元に、質問から回答までの理由付けを文字列に変換しそれを質問文と合わせて送信します。グラフデータは、質問Entityから回答Entityまでの過程を矢印でつなぎ合わせ、それらをさらに回答ごとに改行してつなぎ合わせます。
論文内の例では以下のようになっています。
Jamaica -> official_language -> English
Jamaica -> language_spoken -> Jamaican English
Jamaica -> close_to -> Haiti -> official_language -> French
Jamaica -> located_in -> Caribbean Sea
"Which language do Jamaican people speak?"
結果
まずは、回答の精度を様々な手法と比較した結果を掲載します。
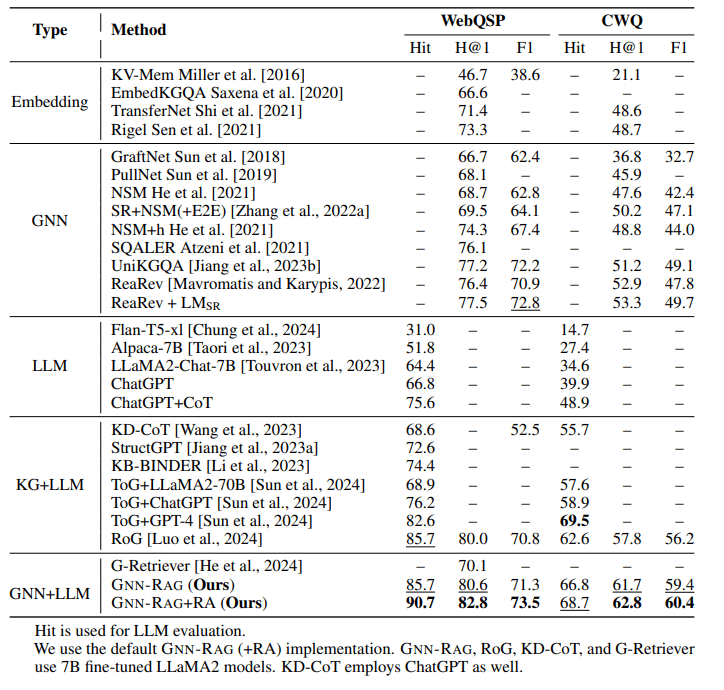
この表から、GNN-RAG+RAの手法が一つ頭が抜けた成果をあげ、次にRNN-RAG、RoGという順番で成果を上げているように見えます。
ToG+GPT-4については、マルチホップなデータセットを多く含むCWQで高い成果を上げていることから、課題によってこのあたりの評価は変わってきそうです。
次は、マルチホップ、マルチエンティティの質問に対する精度です。
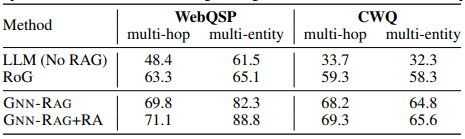
この表から、より複雑なタスクにおけるGNN-RAGの性能はわかりやすく向上していそうです。
最後に、使用するLLMと性能の変化です。
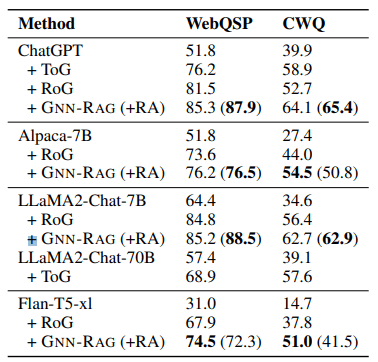
すべての場合でGNN-RAGが高い性能を出しています。また、LLMの性能が下がるほどRAを使用しないほうが精度が上がっているようです。
考察
まず、GNN-RAGという手法についてですが、複雑なタスクにおける精度が既存のLLMを使用した方法と比べて高いことがわかりました。これは、グラフの構造についてあらかじめ学習しておき回答に利用することの有用性を表しているかと思います。
次に、LLMの性能と回答の精度の関係性ですが、これは当然の結果と言えそうです。というのも、GNN-RAGは回答のときにのみLLMを使用しているのに対して、ToGやRoGは検索の段階からLLMを使用しているため、LLMの性能に大きく左右されると言えそうです。しかし、これは裏を返すとLLMの性能が今後さらに上がっていくと、評価が逆転される可能性を示唆していると言えそうです。
その観点で、RAという形でLLMベースの手法も取り入れるのは良いアイディアかなと思います。
RAについて、先程も少し触れましたが、別角度からデータを取得するという観点で選択肢の幅が広がりLLMの回答精度が向上するという点で良い方法かなと思います。ただ、組み合わせは何もGNN-RAGだけのものでは無いので、例えばToGとRoGを組み合わせた場合の精度も気になります。
最後に、ここまでの観点といくつか追加でGNN-RAGを評価してみます。
メリット
- 性能の低いLLMとの相性がよい
- データ取得にLLMを使用しない(RA使用しなければ)ので高速に結果を取得できる
- 既存手法と比べて複雑な質問に対する回答の精度が高い
デメリット
- 比較的簡単なタスクでは既存手法のほうが精度が出ている
- 使用には学習が必要なためデータ更新がしづらい
- LLMの性能向上の恩恵をあまり受けられない
- QA以外のタスクに応用が難しそう
まとめ
Knowledge Graphから関係するデータを抽出する手法として、GNN-RAGを紹介しました。Knowledge Graphはその特性上利用できるタスクに制約がそれなりにありそうですが、その分特定のタスクに対してはかなり高い精度を出してくれるのではという印象を受けました。
GNN-RAGについては、LLMの登場によってLLMを使用したグラフの検索の手法とは一見逆行しているようにも映ります。しかし、データ取得においてLLMとやり取りが必要なかったり、LLMの性能が低くても回答を引き出すことができるという観点で良い手法に感じました。
業務を利用するうえでと考えると、そもそもKnowledge Graphに適したユースケースがまだちゃんとは見つかっていないので、すぐに活用するのは難しそうです。将来みなさまがKnowledge Graphを利用する上で、少しでも参考になれば幸いです
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion