本記事では、LLMの「画像読み取り性能」を高める手法について、ざっくり紹介します。
株式会社ナレッジセンスは、「エンタープライズ企業の膨大なデータを掘り起こし、活用可能にする」プロダクトを開発しているスタートアップです。
この記事は何
この記事は、画像に「横線」を引くだけでLLMの画像読み取りの性能を向上させる手法を提案した論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は、こちらの記事もご参考下さい。
※ちなみにこの手法は直接的にはRAGではありません。しかし、2025年は「マルチモーダルRAG」が流行する年です。例えば、社内データの「ごちゃごちゃしたポンチ絵」などを正確に読み取れると、マルチモーダルRAGの精度は向上します。
本題
ざっくりサマリー

画像に3本の横線を追加し、「この線に沿って順番に見てね」と指示するだけで、LLMの画像認識精度が劇的に向上する、というシンプルなものです。Sharif University of Technologyの研究者らによって2025年6月に提案されました。
これまでのLLM(※正確には画像読み取り可能な「VLM」ですが。)は、画像内の複数の物体を同時に認識しようとするため、それぞれの特徴(色、形、位置など)を混同してしまう問題を抱えていました 。(バインディング問題)
そこで、この手法では、①画像に横線を引いて領域を分割し、②ステップ・バイ・ステップな処理を促すことで、この問題を解決します。
問題意識
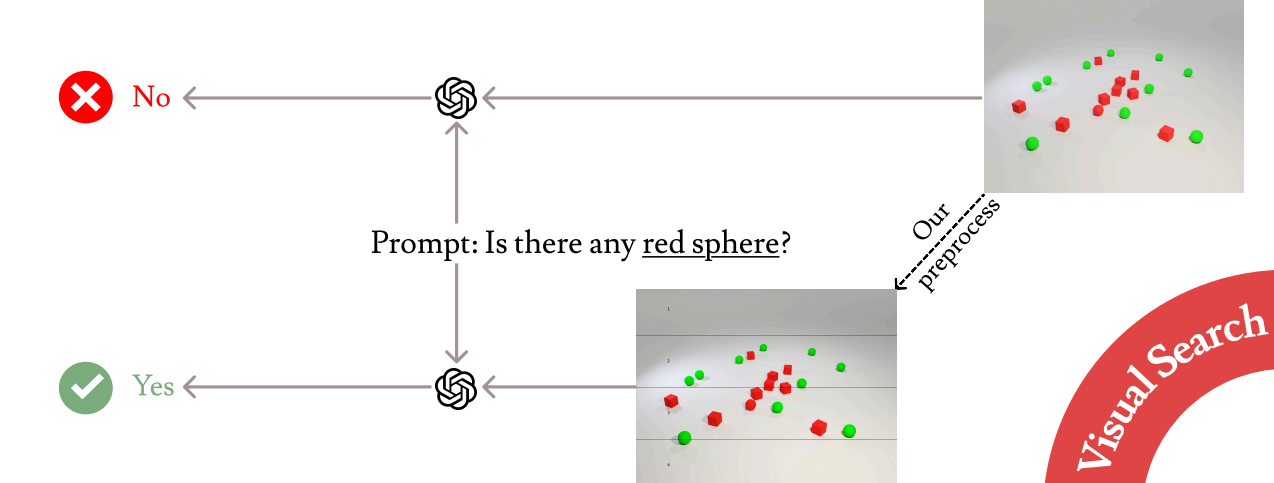
例えば、↑上の画像(の上段)のように、「LLMは、画像をざっくりとしか理解してくれない」 という問題があります。この画像、よく見ると「赤い球」が含まれているのですが、通常、LLMは認識出来ないようです。
これは、RAGの精度にも関わる重要な問題です。
なぜかと言うと、マルチモーダルRAGでは、PDFなどの社内データに含まれる「画像・図表」をLLMに読み込ませることで、RAGの回答精度を上げているからです。
LLMの画像読み取り性能が低いまま利用してしまうと、複雑な図表・ポンチ絵を読み込ませた時、ハルシネーションを起こしがちです。
手法
超シンプルです。

LLMに画像を読み込ませるときに
- 画像を前処理する(3本の横線を引く)
- プロンプトに、「
画像に引かれた横線に基づいて、順番にスキャンしてください」 (Scan the image sequentially based on horizontal lines exist in the image)という一文を追加
以上。超シンプルです。
この手法のキモは、人間が文章を読むのと同じように「上から順番に逐次処理」するよう、LLMに教えていることです。また、ファインチューニングが不要な手法なので、非常に低コストで実装できるのも嬉しいポイントです。
成果

- GPT-4oなどのモデルで、物体カウントの精度が26.83%、視覚探索の精度が25.00%向上
- 単なる言語的指示だけ(Chain-of-Thoughtなど)では精度改善せず、視覚的に補助線を引く今回のアプローチが重要だと示した
まとめ
弊社では普段、エンタープライズ企業向けにRAGサービスを提供しています。大企業は、「社員数」も「事業規模」も大きいので、業務で使っている社内データも、複雑な図表ばっかりです。
今回の手法は、画像に「横線」を引くだけで、こうした文書のRAG精度を上げることができます。しかも、前回紹介したLaTeXの手法と同様、実装に取り入れやすいです。
結局、以前紹介した「HtmlRAG」でもそうでしたが、人間にとっては当たり前にできる「構造や順序の理解」を、いかにAIに分かりやすく伝えてあげられるか、という点が、RAGの精度改善では重要な考え方です。
ぜひ、みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion