導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、LLMの画像の読み込みにLaTeX形式の文字起こしを組み合わせることで、回答精度を引き上げる手法について紹介します。

サマリー
LLMは文字だけではなく画像もそのまま読み込めるため、比較的テキストの抽出の難しいPDFで画像として読み込むことで情報を引き出すことができます。しかし、整理された文章を渡す場合と比較して画像を渡してのLLMの利用は精度が引き出せないことがあります。
この問題に対応するために、今回紹介する論文ではLaTeX形式で画像を文字起こしした結果と画像をLLMに入力する手法を提唱しています。特に一度の画像の読み取りで高い精度を実現する必要がある場面で効果を発揮する手法となっていて、画像単体での入力と比較して10%程度読み取りの精度が向上します。
LLMのメディアデータの読み込み性能の課題
LLMの性能により、画像や音声ファイル、動画などをLLMは認識できるようになりました。これにより、人が認識するようにLLMもデータを認識できるようになり、利便性が大きく向上しました。一方で、メディアデータの読み込みは完全にテキスト化された情報と比べると精度が低くなることがあります。これは、メディアデータから文章を読み取る際にLLMとしての性能を利用してしまい、文章が直接入力された場合と比較して、回答の精度が下がってしまうためです。
手法
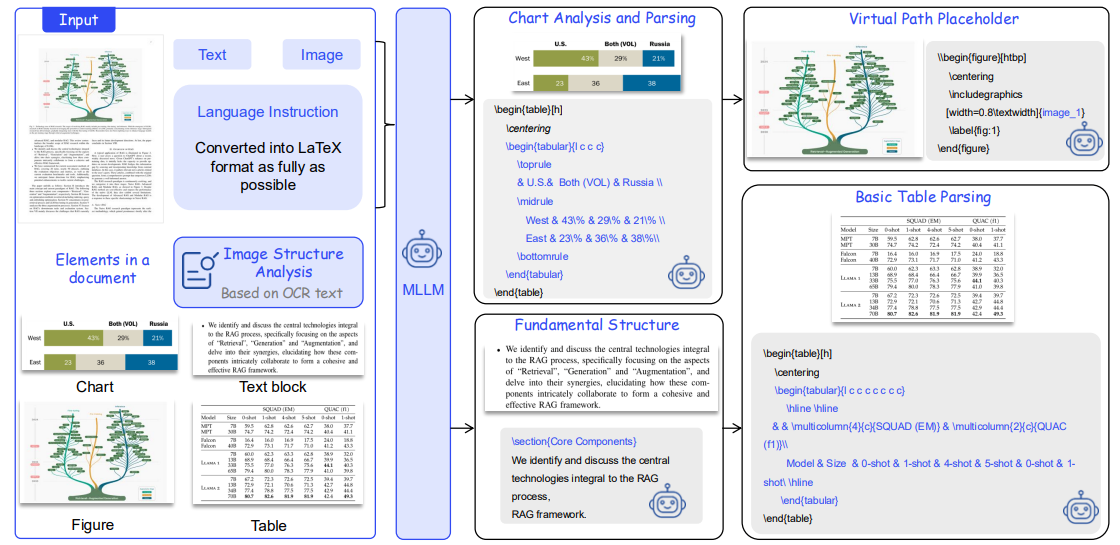
読み込ませるための手法は至ってシンプルで以下の2段階のステップを経て、画像を読み込みます。
- LLMに画像を入力して、その構造や含まれる文章、図表などをLaTeX形式で出力する
- 元の画像と1で生成したLaTeX形式の文章、ユーザーの質問を一緒に入力してLLMに回答させる
文章に書き起こしにくい画像などの情報は、図の位置が伝わるようなパスを利用します。
\\begin{figure}[htbp]
\centering
\includegraphics
[width=0.8\textwidth]{image_1}
\label{fig:1}
\end{figure}
成果

上の図は、画像と質問だけをLLMに渡した場合(左側)と、LaTeXと画像、質問をLLMに渡した場合(右側)とのLLMの画像に対するAttentionの違いを可視化したものです。LaTeXを渡した場合のほうが、画像内の文章への注意がより集中しています。これにより画像内の内容をより的確に捉えられるようになっています。

続いて、各種モデルの画像読み込みを、画像単体、画像+OCR読み込み、画像+LaTeXの三種類で比較した結果です。ほとんどのモデルでLaTeXによる文字起こしの性能が一番高くなっており、画像のみの場合と比較すると最低でも5%、最大で190%の性能の向上が確認できます。
まとめ
LLMの画像の読み取りの性能を向上させる方法について紹介しました。この手法は特に人の手を介さない自動化プロセスにおいて、可能な限り精度を上げたい場合に有用な手段と考えています。また、この方法に限った話ではないですが、LLMの性能をできるだけ引き出すには明確なタスクを小分けに実行していくことが大事です。今回の例でいうと、画像の読み込み+意味の理解+質問への回答という3つのLLMのタスクを、画像の読み込み+意味の理解と意味の理解+質問への回答とを分けることで、回答の精度を上げていると言えます。実際、LLMのプロダクトの開発の現場でも、特に精度を出したい部分ではできるだけ細かい明確なタスクを任せるようにしています。LLMを使って画像読み込みを自動化したいけど、精度があまり上がらない。という場面で是非、ご活用いただければと思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion