どんな人向けの記事?
- これからRAGを作ってみたい
- DifyやLangChainにこだわらず、自分で開発をハンドリングしたい
- ベクトルDBや埋め込みモデルの選定の勘所をサッと知りたい
ここではRAGとは何かのような話題は扱いません。
RAGが、ほぼAI活用の現実的な最適解になりつつある
LLMは高度な知的タスクを実行可能である。
そんな理解が世界に広まっていく中で、企業は自らが蓄えたデータをLLMに組み合わせてどう活用するか躍起になっています。これからはビッグデータだ!という時代を経ているため、情報インフラに投資した企業も多く、AIでデータを活用する流れはもはや確定路線と言えます。
この問題を解決する手法として一番最初に思いつくのは、モデル自体を改変するファインチューニングです。しかし、ファインチューニングにはいくつかの実用上の問題があります。ファインチューニング自体に専門知識が必要であることや、データセットの変化に応じて柔軟にモデルを毎回教育しなおすコストをすべて受け入れることは難しいです。
一方、RAGであれば、いままで蓄えたデータを活かすことができます。また、データの取り出し方を調整するだけで、新たな知識の導入や、いらない知識の除外も容易です。
また、ファインチューニングのようにモデルに対する知識要求量は少なく、上記のような改変に対する時間的コストも軽微です。
したがって、既存資源を使った現実的なAI活用の最適解は、ほぼRAGになると言って良いでしょう。
DifyやLangChainだと概念実証(PoC)もちょっと厳しいかも
RAGをはじめAIワークフローを作ろうと考えたときに、 Dify のようなフルマネジメントなSaaSを使うのが最も簡単ですが、Difyのベクトルデータベースの許容量はとても少ないです。
例えば、DifyのPROFESSIONALプランは $59/month ですが、ここで許容される VectorStorageの上限はたったの 200MB です。
埋め込みモデルの選定にもよりますが、これを実際に利用すると、ちょっとしたドキュメントを1点~数点読み込ませただけでストアがいっぱいになってしまいます。これでは使い物になりません。
また、LangChainは便利なツールですが、LLMアプリケーションを作るとなると結構キツい部分があります。詳しくは上記の記事に詳しいのですが、LangChainは過度に抽象化されているため、実装を見ながら細かいチューニングをするのは逆に難しい気がします。
最低限の構成でRAGを作る場合、必要なのは適切なLLMモデルにcontextやmessageを設定して、completionしてもらうだけです。各種ベクトルDBもRESTなendpointを持っていることがほとんどなので、別にLangChainは必要ありません。
埋め込みにローカルモデルを使うか、APIを使うかでも異なりますが、LangChainにこだわらなければ、そもそもPython実装である必要性もありません
この点をどう調整するかは、エンジニアリングリソースをマネジメントする観点でも非常に重要です。
したがって、今回はDifyやLangChainを使わず、できるだけ自分でハンドルを握ったままシンプルなRAGを構成するときに考えることをまとめてみます。
開発フリーで概念実証(PoC)に使いたいならフルマネジメントサービスで
- 社内 or クライアントが使う資料の多様性が高い
- まずは、早くPoCをやりたい
- 開発リソースをなるべく節約したい
これらの要件がそろっている場合は、「Vertex AI Search」が最適解となるでしょう。
次の画像を見てください。実に多様なデータソースにアクセスできます。
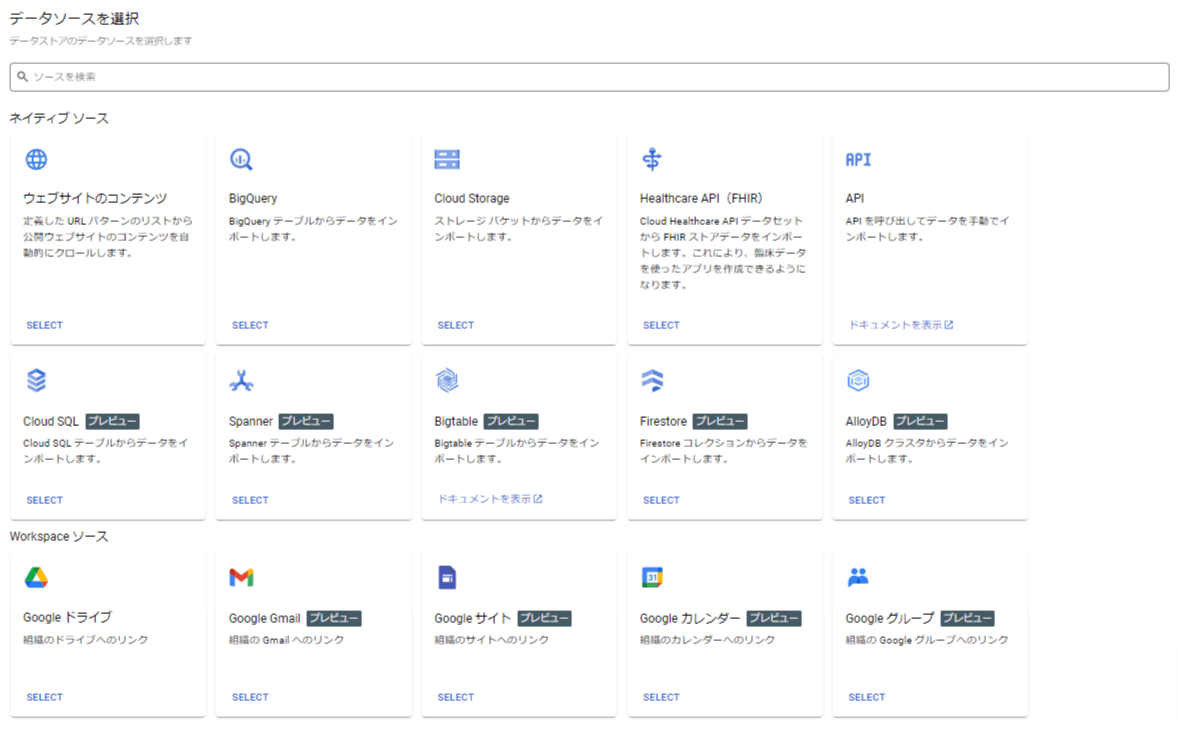
Cloud Storageを経由すればPDFなどの資料のベクトル化も自動でやってくれるほか、ビジネス上のコミュニティハブになりがちなGoogle系リソースのほとんどにアクセスできます。
したがって、「〇〇のRAGを作ってみよう」という話がある程度固まった時点で、Vertex AI SearchでサクッとRAGを作ってしまうのがとにかく早く、ビジネス的なメリットがあります。
さらに、もっと小さなデータセット単位で試したいという話であれば、NotebookLMも非常に良い選択肢です。いくつかの限られたドキュメントや、WebサイトからRAGを作るという点では、NotebookLMが最速です
レスポンスの質も高いので、小さなものを作るということにフォーカスするならまず試すべき選択肢になります。データが多いとすぐリミットになってしまうのでそこには注意が必要です。
気を付けておきたいことは、Vertex AI Serchでデータソースを利用可能になるまでには結構時間がかかること。また、細かいチューニングや自社サービスへのインテグレートを考えると、自分で実装するのが一番良い選択になるはずです。したがって、このステップで重要なのは大雑把なイメージをつかむところまでかなと考えています。
社内向けのデータを使うなら、まずはベクトルDBを選定しよう
上記のようなPoCである程度の満足度が得られそうなことが分かったら、次はベクトルDBを選択することをお勧めします。その理由は、最もコスト面でのネックおよび、できる範囲を制限するクリティカルポイントになりうる可能性が高いからです。
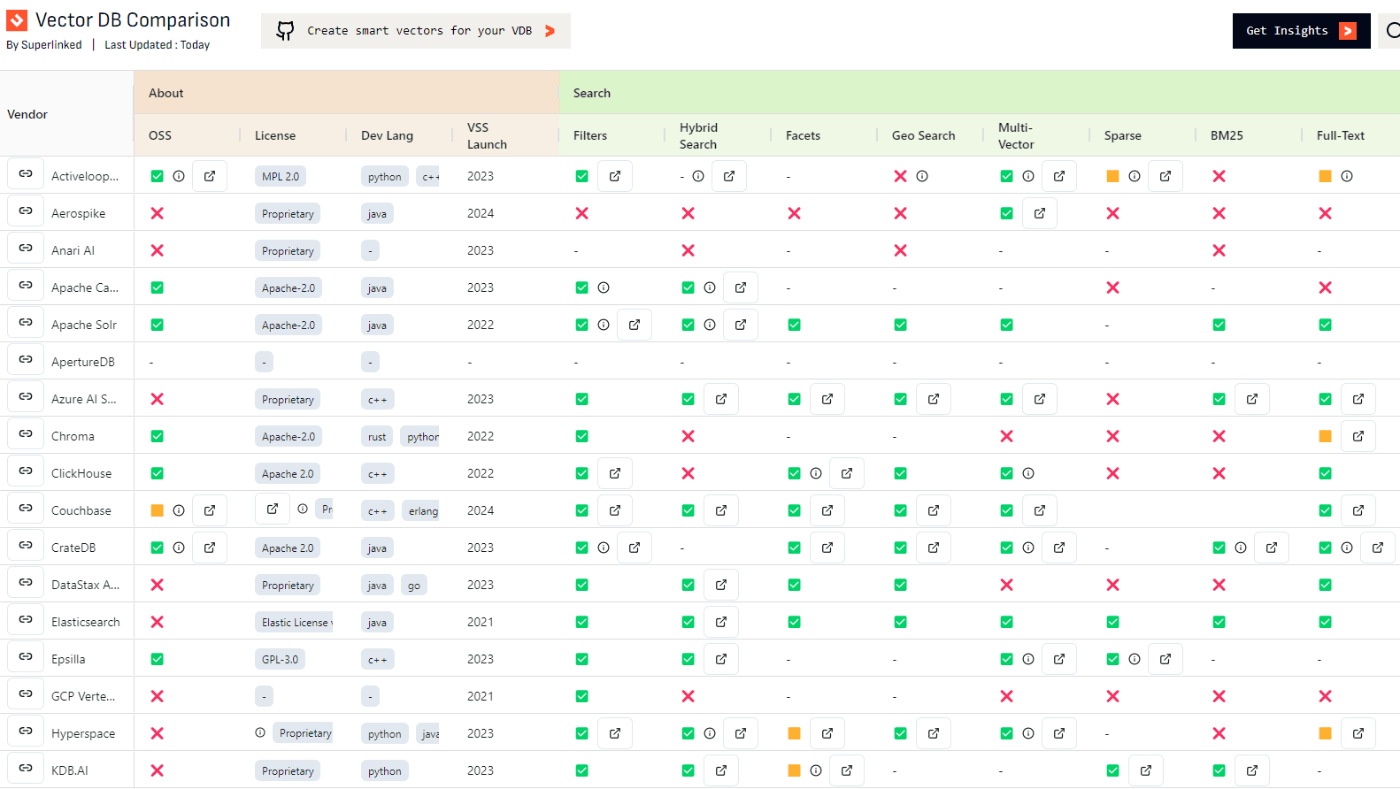
vector-db-comparison をみるとわかる通り、ベクトルDBはまさに戦国時代。
価格感もかなり違うことが見て取れます。また、AWS, GCPそれぞれでのホスティングの容易さも既存プロダクトとのインテグレーションを考えたとき非常に重要です。
さらに、有名で高速とされているPineconeなどはセルフホスティングできないという特徴を持っているため注意が必要です。私は群雄割拠のベクトルDB界隈で突然サービスが終了する可能性は決して低くないと考えています。
ベクトル化したデータはただのfloat配列なので、それ以外のメタデータでの検索インターフェースが使いやすいかどうかも非常に重要です。ここは実際のAPI Reference を見てみるしかないので、GitHub Starsが高いものから並び替えて使ってみるのが良いでしょう。
dockerで簡単に立ち上げられる、検索インターフェースが使いやすい、Goでgrpc経由で簡単に叩けるなどの理由から、私はQdrantを好んで使っています。
Elasticsearchなどはすでに使っている方も多いと思いますし、PostgreSQLにはpgvectorという拡張があり、これを利用することでベクトルDBとして使うことも可能なので、これらについて経験豊富な方は選択肢として有用でしょう。
LangChainのVector Storeとして紹介されているのはChroma, Pinecone, FAISS, Lanceです。ほかにもChromaはいろんなところで使われているような印象もあるので、生き残りやすそうということでこれらを選択するのもありかと思います。
このように、ベクトルDBの選択は今まで使ってきた技術スタックや、これから何をやりたいか、インターフェースが自分好みかなど様々な要因に支配され、全ての面でベストな選択肢になるプロダクトが存在しません。
ぜひ一番最初に検討することをオススメします。
外向きのデータを使いたいならクローラーなど他のツールとの統合を考慮する
Webのデータを入れたいというユースケースも考えられます。
この場合、定型のサイトのクローリングでは自分でクローラーを書いてしまうのが最も精度が高くなるでしょう。
一方、ユーザーの検索クエリに応じてクローリングを行いたいようなユースケースでは、API経由のアクセスができると便利です。これについてもいくつか選択肢があるため考慮しておくべき事項になります。
FirecrawlはLLMベースでWebページを構造化された状態で取ってくるのが便利ですが、その構造化に問題があるかないかというと微妙なところがあるので、ユースケースで使うことが想定されるサイトについてのレスポンスを実際に目で確認しておくことが非常に重要と言えるでしょう。
日本語埋め込み(Embedding)モデルを選ぶ
埋め込みで最も使われているのはOpenAIの text-embedding-ada-002 かと思います。
最近は text-embedding-3-large などより精度の高いモデルも出てきており、コスト面で許容されるならこれを使うのが良いでしょう。
他方、ローカルの埋め込みモデルもかなりの精度が出るものが出てきているので、コスト面と実行スピードの面から比較してみる価値があります。
上記のスライドに非常に詳しいので、一度目を通しておくことをお勧めします。
特に私が気に入っているのは pkshatech/GLuCoSE-base-ja や intfloat/multilingual-e5-large です。
これらのモデルは個人的には自分のプロジェクトにおける精度がそこそこ高く、部分的な実用に耐えうるという所感を持っています。
model = AutoModel.from_pretrained('intfloat/multilingual-e5-large')
モデルの切り替えも非常に簡単なので、いろいろなモデルを検討することが大事でしょう。
実際に使ってみるとわかるのですが、カタログスペックと実際の環境での印象はだいぶ異なります。
例えば、E5系はGluCoSeに比べて倍程度の推論時間が必要であることを言及している情報源は少なく、手元で動かすかだけで得られる情報はかなり多いと考えています。
また、Sentence-Transformersが要求するメモリ量は必ずしも多くないため、埋め込みモデルのファインチューニングはLLMほどコストが高くありません
埋め込みモデルのファインチューニングは積極的な選択肢になりうるので、頭に入れておくと良いでしょう。
最後に、これらのモデルはGPUフリーなCloudRunで走らせることも可能であることを付け加えておきます。言うまでもなくこのような手法を使うことで、GPUを接続したインスタンスを常時立てておくよりも格安に運用可能です。
RAGを初回構築する場合、大量のベクトル作成を必要とするケースがほとんどかと思うので、ローカルモデルを検討する重要性はなおさら高いと言えるでしょう。
最後に、現段階ではGoogleのEmbeddingモデルは 1500RPM/min まで無料で使えることにも触れておきます。今後値段が付いてくる可能性は高いことと、Googleのサービスの継続性について疑問を覚える方もいると思いますが、実証レベルでとりあえずAPI経由でEmbeddingしたいというときは良い選択肢になるでしょう。
LLMモデルの選択
最初に試すべきはやはり Claude 3.5 Sonnet でしょう。
日本語のアウトプットとして良い精度を出すという点では、依然 Claude3.5 sonnetが最強であると思います。
さらに、RAGでは Input tokenが大きくなりがちなので GPT4o が $5 /1M token に対して Claude3.5 Sonnetは $3/1M tokenと安いことも理由となります。
もっとコストを落としたい場合は、 gpt-4o-mini にするだけで 速度もコストも下がります。
ここで、速度をさらに上げたい場合、groq を使うと体感でのレスポンスもさらに向上する可能性があるので触れておきます。
ただし、個人的にはRAGのアウトプットの質を上げるには、最終的に出力を構築するLLMの性能を上げることがほとんどの場合でワークするため、コスト面での要件が厳しくない限り、Claude 3.5 Sonnet で良いのではと考えています。
Optionとしてナレッジグラフやリランキングのような手法を利用するか考える
GraphRAGのようにナレッジグラフを利用すると、回答の質はかなり高くなります。
また、よくRAGの性能を上げる方法として挙げられるリランキングなどの手法も存在します。
私の試したタスクにおいては、リランキングは出力の構造化が多少うまくなる程度のメリットしかありませんでしたが、これもタスクによって改善度が異なるのでしょう。
ナレッジグラフ、リランキングともに、計算コストは高いと言えます。ただし、かかるコストの種類がちょっと違うので理解しておく必要があります。
ナレッジグラフは、検索コストはそこまで高くないものの、グラフ構造を作成する際の計算コストが跳ね上がります。例えば、 MicrosoftのGraphRAGを実際に動かしたとき、Wikiのページを1ページぶん処理するだけで5分程度の時間がかかってしまいました。
リランキングは、リランキング用のモデルをメモリに載せておく必要があったり、その推論時間分が最終的な出力までの時間にプラスされてしまうことを考慮しておく必要があります。チャットボットのようなものにRAGを搭載した場合、これらの推論時間がそのままユーザーの待機時間になってしまうことを頭に入れておかなければなりません。
これらの手法が自分のデータセットにおいて必要か、十分な効果があるのか。
小さいデータセットを作ってPoCレベルで確認しておくことが重要です。
評価手法を考えておく
LLMモデルのベンチマークと、体感の性能が全然違うと思ったことはありませんか?
もはやモデルのベンチマークですごい性能だ!と言ってる人の方が少数派ではないでしょうか。
一方で、RAGを作って納品したり整備したりしていく必要がある場合に、「性能を評価しない」ということは許されないでしょう。実際、toBビジネスでクライアントに対してこれを伝えるのは厳しいのではと思います。
このような状況下で納得感のあるベンチマークをとるなら、Ragasというフレームワークがオススメです。
Ragasは、Metrics-Driven Development (MDD) というコンセプトを採用し、いくつかのメトリクスを提供しています。
Ragasに与えるべき情報は以下のような情報です。
- ユーザーの質問
- RAGの回答内容
- RAGが回答の参考にした情報
- ドメイン知識
これらの情報を提供すると、
- 生成内容と参考情報の忠実性
- 生成内容と質問の適切性
- 参考情報が回答内容へ反映されているか
- 参考情報に、ドメイン知識が反映されているか
などのメトリクスを数値で判定することができます。
RAGの性質によって、評価すべきメトリクスが変わったり、重みづけすべき内容が変わってくるかと思いますが、実際のプロダクトに必要なドメイン知識を使って評価できるRagasはよいスタートポイントと言えると思います。
実際にユーザーがどのようなクエリを投げて、RAGによってどんな情報を取得し、どんなレスポンスを得ているかが非常に重要な判断材料となるため、事前に監視するインフラを作成することも重要なポイントとなるでしょう。それらの情報は、先述した埋め込みモデルのファインチューニングや、その他RAGの性能改善手法を試すときにすぐ動けるかどうかに直結するでしょう。
ここは納品する商品の性能に直結する部分になると考えています。これらのインフラを整えない場合、LLMや埋め込みモデルの性能が上がるのを待つという受動的なアクションしかとれなくなってしまうリスクがあります。
Bizサイドとの連携の観点からは、クライアント側とよく相談したうえで、品質向上のためにこの部分が重要であることを説明しきって意思決定を促すこともRAGアプリケーションを納品するために重要な論点になるでしょう。
まとめ
ざっくりとした内容でしたが、とりあえずRAGを始めるという視点で、必要な技術選定を行うときの勘所をまとめてみたつもりです。
AI活用の流れは最低でも今後数年にわたって続くと思われるビッグウェーブです。
最新のモデルや改善手法が毎日のように報告されるのにも関わらず、実務上それが使えるのか、使えないかという情報は非常に限られています。
マインディアでは毎日AI活用のナレッジをBizサイド、Devサイドで相互にシェアして知見を深めています。EngeneerはAI関連アプリケーションを開発する専用の時間を設けていることで、非常にスピード感を持った開発を進めることができます。
もし興味のある方は、カジュアル面談等お待ちしておりますので、ぜひXのDM等からお気軽にご連絡をお願いします!
あとお友達になってくれる人も強く募集しているのでXよろしくです!

Discussion