導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、推論過程をキャッシュし利用することで、思考リソースを大幅に減らす手法RoTについて紹介します。

サマリー
LLMはReasoningという、反復思考によって性能を引き上げることに成功しました。その反面、使用するトークン数が大幅に増加し、結果の出力まで時間がかかるようになってしまいました。
今回紹介するRoTはReasoningの過程を「キャッシュ」することで、コストを最大60%削減し、出力完了までの時間を最大70%削減しています。
課題意識
反復思考の時間とコスト
Reasoningは非常に強力な手法である一方で、完了までの時間がものすごく遅くなったり、トークンの利用量が増えすぎてしまう問題があります。この問題を緩和するため、gpt-5などのReasoningを含むモデルでは、トークンの順序が完全に一致している場合に、過去の計算結果を再利用することでコストを抑えていますが、そもそもの出力が非常に大きいため効果は限定的です。
手法
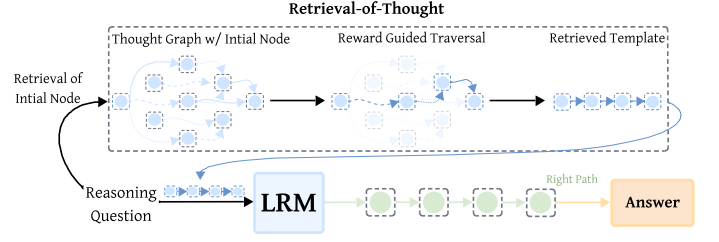
推論過程をナレッジグラフで保管します。
このとき以下のステップでナレッジグラフの情報を更新します。
- 問題解決のプロセスを思考のステップごとにノードを作成し、連続したステップをエッジで連結します。
- ノード同士の類似度を計算し、一定以上類似しているもの同士をエッジで連結します。
つづいて、思考ステップの取得方法です。細かい説明は省略しますが、以下のルールで連続したステップを取得しLLMに渡します。
- 関連度の高いノードをベクトルの類似度から取得
- 関連度が低くなるまでノードを順にたどっていき、最後にLLMにそこまでに取得したノードを渡す
以上の手順で、思考の一部を省略して、性能を保ちつつコストを大幅に抑えています。
評価

まずは金額面での評価です。すべてのベースモデルで、RoTを導入することでコスト効率が改善しており、最大60%ほどコスト削減に成功しています。またコスト低下の幅は、軽量なモデルほど大きいようです。

続いて出力までにかかる時間の評価です。こちらもすべてのベースモデルで、応答時間が改善しており、最大で70%ほどの性能の工場が見られます。こちらも、元のモデルが軽量なほど効果が大きいようです。

最後に、通常のCoTと比較した、思考の反復回数の変化です。最大で80%ほど試行回数が減少しており、こちらもやはり、元のモデルが軽量なほど効果が大きいようです。
まとめ
Reasoningモデルが登場してから、LLMの性能はまた劇的に改善した一方で、どうしてもコスト面、時間の面で利用のしづらさが発生してしまっていました。今回紹介した、RoTの特筆すべきポイントは、思考過程で行っていことを計算コストの高いLLMではなく、計算コストの低い外部のモジュールで行っている点にあるかなと思います。
また軽量モデルでの性能の改善が大きいという点からも、モバイル端末で動かすSLMの性能向上に対しても果たす役割は大きいのでは、と感じています。
もし、LLMの思考時間の長さ、費用がボトルネックになってしまっているのであれば、かなり効果の期待できる手法かと思うので活用してみてください。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion