本記事では、RAGの性能を高めるための「PageIndex」という手法について、ざっくり理解します。
株式会社ナレッジセンスは、「エンタープライズ企業の膨大なデータを掘り起こし、活用可能にする」プロダクトを開発しているスタートアップです。
この記事は何
この記事は、RAGで「ベクトルDB」を使わずに回答精度を上げる手法「PageIndex」[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます(参考)。
本題
ざっくりサマリー

PageIndexは、RAGの精度を上げるための新しい手法です。Vectify AIによって開発されました。
通常のRAGでは、文章をベクトル化して、類似度が高いものを検索して参照します。しかし、これだと「意味は似ているが、文脈は違う」情報を取ってきてしまい、回答精度が落ちます。
そこで、PageIndexは、ベクトルデータベースを使わないRAGを提案しています。
具体的には、PageIndexという手法では、文書を階層的なツリー構造に変換(「目次」のようなイメージ)し、LLMがその構造を辿って検索します。これにより、人間が文書を読むときのように、文脈を理解して必要な情報を探し出すことが可能になります。
使い所が大事
問題意識

従来のRAGの課題として、文書を細切れの「チャンク」に分けるため、文脈が失われるという問題がありました。
例えば、契約書や金融関連のドキュメントでは、文書内のあらゆる箇所で「似た雰囲気の専門用語」が使われます。従来の「ベクトル検索型」のRAGでは、こうした「雰囲気が似ている」文書の検索が苦手です。ユーザーの質問とは関係のない情報を、文脈を無視して、引っ張ってきてしまうことがあります。
手法
そこで、PageIndexという手法では、ベクトル検索を使わず、「目次のようなもの」を使って情報探索するRAG手法 を提案しています。

具体的な手順は以下の3ステップです。
【事前にやっておくこと】
-
ドキュメントの構造化
- PDFを、OCRを使って読み込む
- このとき、階層構造に注意してMarkdownに変換
-
階層ツリーを構築
- 1を使い、「目次」のような木構造(JSON形式)を構築
【ユーザーが質問を入力して来たとき】
-
ツリー検索の実行
- ユーザーの質問を受け取ると、LLMが「2」のツリー構造を辿って探索
PageIndexという手法のキモは、LLMに文書の全体像を捉える能力を与えている点です。これまでの「ベクトル検索型」のRAGの手法だと、LLMに渡すのは「ごく一部」の検索結果だけなので、文脈が消えていました。しかし、PageIndexでは、全体像(目次)を捉えながら、目的の記述を探しに行くという「人間らしい文書探索」ができるようになりました。
成果
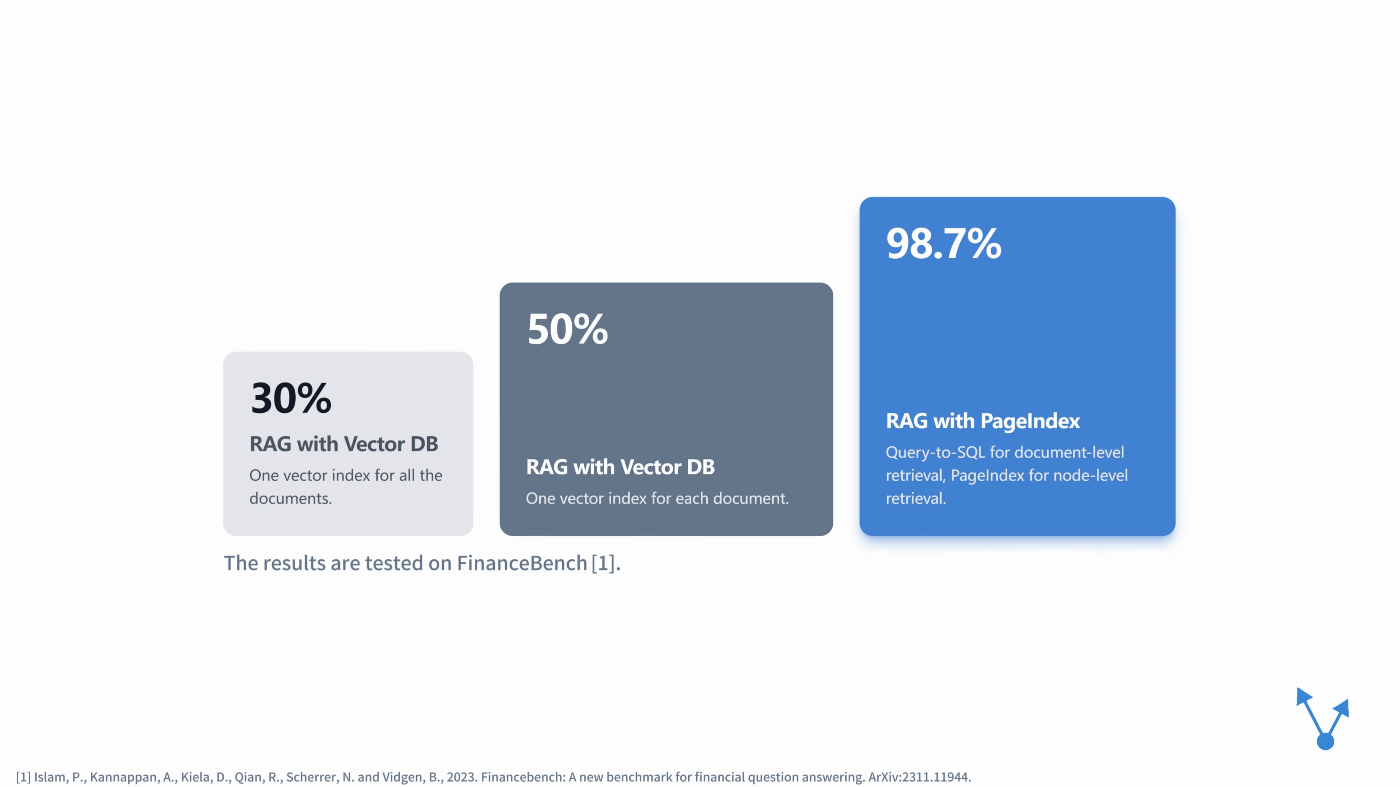
- 金融レポートの分析に関する質問応答ベンチマーク「FinanceBench」において、98.7%の正解率を達成
- 検索プロセスが透明で、どのような経路で情報が取得されたかが明確に
限界もあります↓
- 複数の文書に対応できない(複数の文書をまたがった「目次」って難しい)
- ユーザーの質問が来てから、回答までに時間がかかる
- そもそもの文書がある程度きれいな構造でないと、きれいな目次が作れない
まとめ
弊社では普段から、エンタープライズ向けに生成AIサービスを開発しています。エンタープライズRAGの対象として特に難しいのは法務系・財務系のドキュメントです。普通にRAGをすると苦手なこうした文書だからこそ、人間が「目次を辿る」行動を真似したような「PageIndex」というRAG手法は、成果が出やすいです。
PageIndexにも、上で挙げたような色々な限界があります。限界がある上でもPageIndexという手法のユースケースとして適しているのは、1つの文書について問い合わせをしたい ようなタスクです。例えば、「膨大なページ数のPDF1件を読み込ませて、AIに質問したい」というニーズはかなり大きいです。
普通、RAGというと、膨大な文書を読み込ませるイメージがありますが、以外と、単体の文書を読み込ませて質疑応答させたいという需要も大きいです。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion
ベクトルデータベースで雑に100文書ほどとり、あとは同じ用語が使用されているかで検索をかけるではいけないのでしょうか?