本記事では、「Adaptive-RAG」についてざっくり理解します。軽めの記事です。
株式会社ナレッジセンスでは普段の業務で、生成AIやRAGシステムを活用したサービスを開発しています。
この記事は何
この記事は、Adaptive系で現在、最も「コスパ」が良いとされる「Adaptive-RAG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
RAGの回答精度を高めるための手法です。韓国科学技術院(KAIST)の研究者らによって2024年3月に提案されました。「Adaptive-RAG」という手法を使うメリットは、ユーザーからの入力としてシンプルな質問・複雑な質問、どちらも想定される場合に、「そこまで遅くなりすぎずに、ある程度の回答精度がでる」という点です。
Adaptive-RAGでは、ユーザーから質問が来たときに、「そもそもRAGすべきか、RAGするなら複数回のドキュメント検索をすべきか?」について分類して、適切な手法を利用することで回答を生成します。わざわざRAGしなくていい回答についてはRAGしないので、LLMの回答が早くて正確になりますし、逆に複数回RAGが必要なものについてはじっくり時間を取って、精度の高い回答を生成します。
既存手法の「Self-RAG」にかなり似ていますが、論文内ではちゃんと速度・精度比較がなされています。(Self-RAGについては私も先日、こちらで紹介しています)
問題意識
Retrieval-Augmented Generation (RAG) を使うことで、多くの場面でLLMの回答性能を上げることができます。しかし、わざわざRAGしなくても良い質問が来た時にもRAGをしてしまうと、回答がムダに遅くなったり、回答精度が落ちたりします。なので、LLM単体で回答できる場合と、RAGしないと回答できない場合で、回答生成の戦略を分ける必要があります。
手法
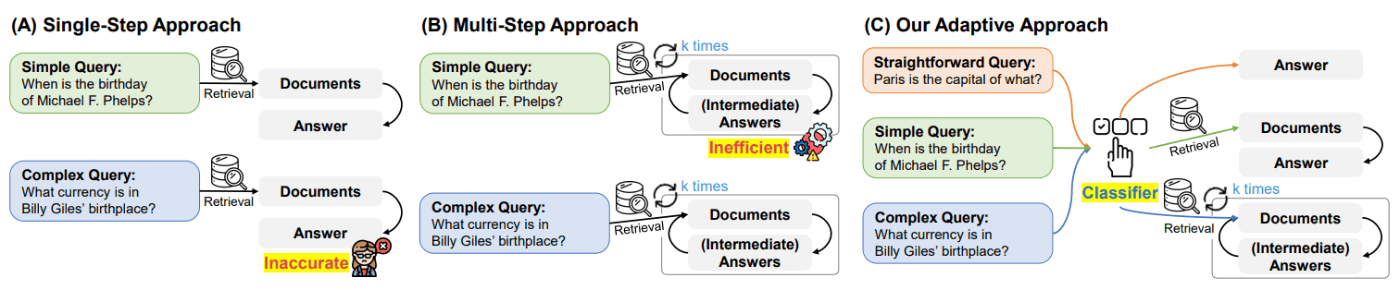
本論文では、質問の複雑さに基づいて最適な戦略を動的に選択できる「Adaptive-RAG」を提案しています。以下の図で言うところの、一番右が、今回の提案手法です。
Adaptive-RAGの主なポイントは以下の3つです。
ユーザーからの質問について、簡単、中程度、複雑の3つに分類し、それぞれの場合で最適な回答手法を適用します。
- 簡単な質問 → 検索なしでLLMのみで回答
- 中程度の質問 → LLMと1回の検索を組み合わせて回答
- 複雑な質問 → LLMと複数回の検索を繰り返し、推論を重ねて回答
この手法のキモは、質問の難易度を自動で判定するClassifier(分類器)です。この分類器は、T5という言語モデル[2]をファインチューニングすることで構築されています。
成果
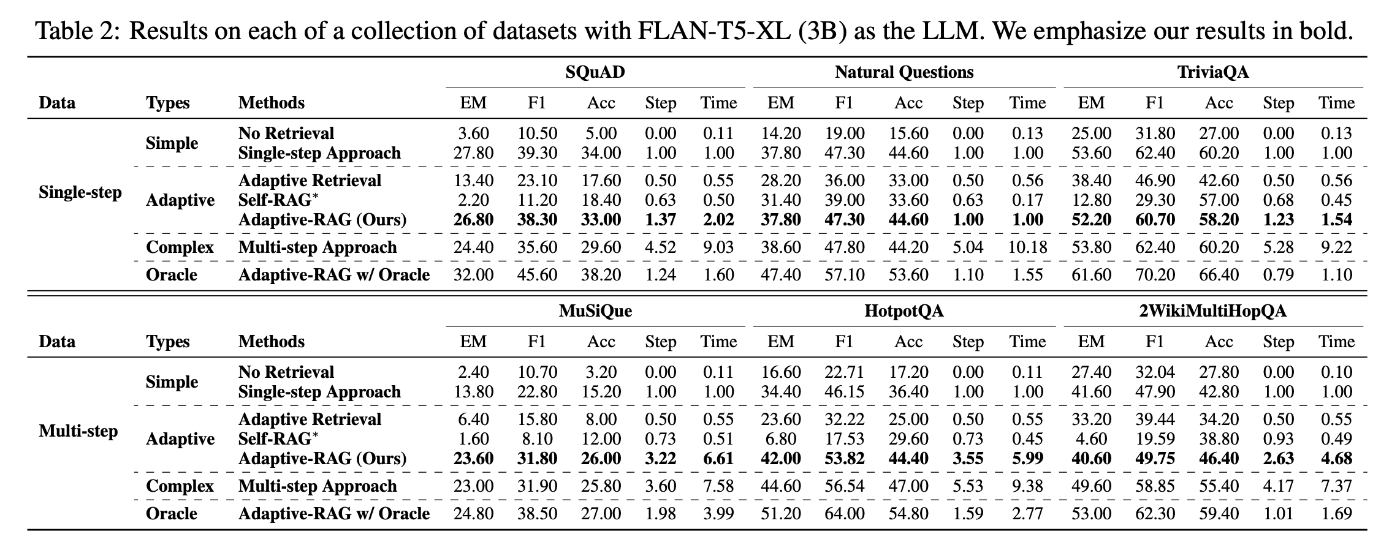
複数のオープンドメインQAデータセットを用いてモデルを評価し、その結果、従来のアプローチ(Self-RAGなど)と比較して、提案モデルが全体的な効率と精度を向上させることができたと報告されています。テストケースがSingle-stepの場合とMulti-stepの場合とを見てみると、Adaptive-RAGは複雑な質問(Multi-step)の場合には回答生成時間をがっつり取っている代わりに、回答精度を保っていることが特徴的です。
まとめ
私自身、普段から大企業にRAGシステムを提供していますが、実際、「複数回の検索をしないと回答できない」ような質問が入力されることはよくあります。一方で、毎度、複数回検索するようなRAGシステムにしていると、回答速度がかなり遅くなってしまうというジレンマがあります。Adaptive-RAGでは質問を分類することで、回答生成の戦略を変更するというエッセンスを提案しているので、この点は実務でも利用価値があるなと感じています。(とはいえ、まさにこの「分類器」がキモであり、正確な分類をさせるのが結構難しいのですが...)
みなさまが業務でRAGシステムを構築する際も、回答精度を上げる工夫として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion