PythonによるS-Learnerの実装
はじめに
S-Learnerについて、Pythonによる実装を交えてまとめました。内容について誤り等ございましたら、コメントにてご指摘いただけますと幸いです。
機械学習を用いた因果推論
機械学習を用いた因果推論手法は大きく分けて下記の2通りが存在します。
- Meta-Learner系
- Causal-Tree系
今回はMeta-Learner系の手法の1つであるS-Learnerについて紹介します。
Meta-Leanrerとは
Meta-Learnerとは、機械学習と因果推論の考え方を掛け合わせて条件付き平均処置効果(CATE: Conditional Average Treatment Effect)を推定する手法の総称です。
条件付き平均処置効果(CATE)とは、平均処置効果(ATE: Average Treatment Effect)をある条件(
ここで、
そのため、機械学習を使って取得できないデータの予測値を算出し、推定に利用しようとするのがMeta-Learnerの考え方です。その中でも今回はS-Learnerについて紹介します。
S-Learnerとは
S-Learnerの"S"は"Single"の頭文字を表しており、S-Learnerとは、その名の通り1つの機械学習モデルを構築し条件付き平均処置効果(CATE)を推定しようとする手法です。
ダイエット商品の広告を回した際に
- iさんの共変量:
X_i - iさんが広告を見たかどうか(処置):
T_i T_i=1 T_i=0 - iさんの売上:
Y_i
というデータから広告の効果を推定するという例をもとにS-Learnerの手順を説明します。
- 全てのデータ、すなわち、対照群(広告を見ていないグループ)と処置群(広告を見たグループ)のデータから、共変量
X=x, T=t Y \mu(x, t) = E[Y|X=x, T=t] - 全てのデータに対し、処置を受けていない(広告を見ていない)場合のデータ(
X=x, T=0 X=x, T=1 - 2.で作成した各々のデータに対して
Y \hat{\mu}(x, t) \: \hat{\mu}_1(x, 1), \hat{\mu}_0(x, 0) \:
\hat{\tau}(x) = \hat{\mu}_1(x, 1) - \hat{\mu}_0(x, 0)
Pythonによる実装
ダイエット商品の広告効果を例に、Pythonでデータを作成し、S-Learnerを用いて効果を算出してみます。
設定
とある健康食品会社では、ECにてダイエット商品を販売しています。ダイエット商品の販促のため広告を回した結果から広告効果を推定することになりました。
手元には下記のデータがあります。
- iさんのダイエットへの意識の高さを表す指標
x_i - 一様分布(-1, 1)に従う
- iさんが広告を見たかどうかを表すダミー変数
T_i - 下記のモデルによって決定されるとする
T_i = \left\{\begin{array}{ll} 1 & (x_i + noise_i > 0): 広告を見た \\ \\ 0 & (x_i + noise_i \leq 0): 広告を見てない \end{array}\right. -
noise_i
- 下記のモデルによって決定されるとする
- iさんの購入金額
Y_i -
x_i T_i Y_i = 1000(\: [\: 3 + \tau_i T_i + 3x_i + noise_i \:] \: ) - ただし
[x] n \leq x < n+1 - また、効果
\tau_i x_i \tau_i = \left\{\begin{array}{ll} 1 & (x_i \leq 0) \\ \\ 2 & (0 < x_i \leq 0.5) \\ \\ 3 & (0.5 < x_i \leq 1) \end{array}\right. -
noise_i
-
データの作成
Pythonで上記の設定を満たすデータを作成します。
# 必要なライブラリをインポート
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# グラフをJupyter上に描画
%matplotlib inline
# データ数
size = 1000
# シードの設定
np.random.seed(0)
# ダイエットへの意識の高さ
x = np.random.uniform(-1, 1, size)
noise = np.random.randn(size)
# 広告ダミー
_T = x + noise
T = np.where(_T>0, 1, 0)
# ダイエットへの意識の高さによって広告効果が異なる
t = np.zeros(size)
for i in range(size):
if x[i] < 0:
t[i] = 1
elif x[i] < 0.5:
t[i] = 2
else:
t[i] = 3
# 売上
noise = np.random.uniform(0, 1, size)
Y = np.clip(t*T + 3*x + 3 + noise, 0, 10).astype("int") * 1000
# 売上のヒストグラムを描画
plt.hist(Y)
plt.xlabel("ダイエット商品の売上(単位:円)")
plt.show()
(出力結果)

S-Learnerによる効果検証
今回は売上
# 必要なライブラリをインポート
from sklearn.ensemble import RandomForestRegressor
# 手順1: モデルを学習
reg = RandomForestRegressor(max_depth=3, random_state=0)
X = df.loc[:, ["x", "T"]]
reg.fit(X, df["Y"])
# 手順2: 広告を見ていない(T=0)データと広告を見た(T=1)データを作成
X_0 = X.copy()
X_0["T"] = 0
X_1 = X.copy()
X_1["T"] = 1
# 手順3: 効果の推定
mu_0 = reg.predict(X_0)
mu_1 = reg.predict(X_1)
tau = mu_1 - mu_0
# 推定された効果の描画
plt.scatter(df[["x"]], tau, alpha=0.3)
plt.hlines(1000, -1, 0, linestyles='--', color="red")
plt.hlines(1000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.hlines(2000, 0, 0.5, linestyles='--', color="red")
plt.hlines(2000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.hlines(3000, 0.5, 1.0, linestyles='--', color="red")
plt.hlines(3000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.xlabel("ダイエットへの意識の高さ")
plt.ylabel("広告効果")
plt.ylim(0, 4000)
plt.show()
(出力結果)
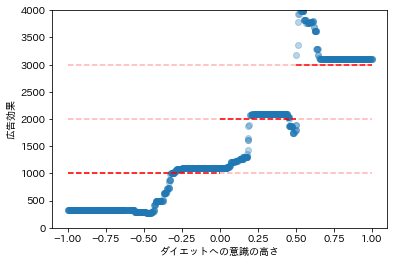
ダイエットへの意識が低いデータでは推定の精度は悪いですが、効果の異質性(非線形の効果)を捉えた推定はできているようです。
EconMLの紹介
EconMLとは、観察可能なデータから機械学習を用いて条件付き平均処置効果(CATE)を推定するPythonパッケージです。Microsoft社が開発しているもので、さまざまなMeta-Learner系やCausal-Tree系の因果推論手法が実装されています。
EconMLの公式ドキュメントはこちらです。
EconMLによるS-Learnerの実装
S-Learnerは推定に利用する機械学習モデルを選択するだけで実装できます。
今回はランダムフォレスト回帰をモデルに選択します。
# 必要なライブラリのインポート
from sklearn.ensemble import RandomForestRegressor
from econml.metalearners import SLearner
# モデルの構築
models = RandomForestRegressor(max_depth=3, random_state=0)
S_learner = SLearner(models=models)
S_learner.fit(Y, T, X=x.reshape(-1, 1))
# 効果の推定
tau = S_learner.effect(x.reshape(-1, 1))
# 推定された効果の可視化
plt.scatter(df[["x"]], tau, alpha=0.3)
plt.hlines(1000, -1, 0, linestyles='--', color="red")
plt.hlines(1000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.hlines(2000, 0, 0.5, linestyles='--', color="red")
plt.hlines(2000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.hlines(3000, 0.5, 1.0, linestyles='--', color="red")
plt.hlines(3000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.xlabel("ダイエットへの意識の高さ")
plt.ylabel("広告効果")
plt.ylim(0, 4000)
plt.show()
(出力結果)
先ほどと同様の結果が得られました。
補足
先ほども少し触れましたが、現実社会においては広告効果を推定したい場合、広告を見た人もそうでない人もその多くが商品を購入しないというシーンがほとんどです。
先ほどの例で売上
# 必要なライブラリをインポート
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# グラフをJupyter上に描画
%matplotlib inline
# データ数
size = 1000
# シードの設定
np.random.seed(0)
# ダイエットへの意識の高さ
x = np.random.uniform(-1, 1, size)
noise = np.random.randn(size)
# 広告ダミー
_T = x + noise
T = np.where(_T>0, 1, 0)
# ダイエットへの意識の高さによって広告効果が異なる
t = np.zeros(size)
for i in range(size):
if x[i] < 0:
t[i] = 1
elif x[i] < 0.5:
t[i] = 2
else:
t[i] = 3
# 売上
noise = np.random.uniform(0, 1, size)
Y = np.clip(t*T + 3*x + noise, 0, 10).astype("int") * 1000
# Y = np.clip(t*T + 3*x + 3 + noise, 0, 10).astype("int") * 1000
# 売上のヒストグラムを描画
plt.hist(Y)
plt.xlabel("ダイエット商品の売上(単位:円)")
plt.show()
(出力結果)

このデータにおいて、S-Learnerを実装してみます。
# 必要なライブラリのインポート
from sklearn.ensemble import RandomForestRegressor
from econml.metalearners import SLearner
# モデルの構築
models = RandomForestRegressor(max_depth=3, random_state=0)
S_learner = SLearner(models=models)
S_learner.fit(Y, T, X=x.reshape(-1, 1))
# 効果の推定
tau = S_learner.effect(x.reshape(-1, 1))
# 推定された効果の描画
plt.scatter(df[["x"]], tau, alpha=0.3)
plt.hlines(1000, -1, 0, linestyles='--', color="red")
plt.hlines(1000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.hlines(2000, 0, 0.5, linestyles='--', color="red")
plt.hlines(2000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.hlines(3000, 0.5, 1.0, linestyles='--', color="red")
plt.hlines(3000, -1, 1, linestyles='--', color="red", alpha=0.3)
plt.xlabel("ダイエットへの意識の高さ")
plt.ylabel("広告効果")
plt.ylim(0, 4000)
plt.show()
(出力結果)

特にダイエットへの意識が低いグループの広告効果において、推定の精度がかなり悪いようです。
参考文献
- EconML公式ドキュメント
- CausalML公式ドキュメント
- Causal Inference for The Brave and True
- Sören R. Künzel, Jasjeet S. Sekhon, Peter J. Bickel, Bin Yu 「Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning」(2017)
おわりに
最後まで読んでいただきありがとうございました。他にも「Python×データ分析」をメインテーマに記事を執筆しているので、参考にしていただけたら幸いです。内容の誤り等がございましたら、コメントにてご指摘くださいませ。
他にも下記のような記事を書いています。ご一読いただけますと幸いです。
- 相関関係と因果関係と疑似相関
- 反実仮想と因果効果
- 介入とランダム化比較試験
- 回帰分析を用いた効果検証
- 層別解析を用いた効果検証
- 傾向スコアを用いた効果検証
- 操作変数を用いた効果検証
- 回帰不連続デザインを用いた効果検証
- 差分の差分法を用いた効果検証
- 機械学習を用いた効果検証
また、過去にLTや勉強会で発表した資料は下記リンクにまとめてあります。ぜひ、ご一読くださいませ。
Discussion