こんにちは。PharmaXの上野です。
今回はLLMアプリケーションを評価する上で知っておくべき評価の基本をきちんと整理したいと思います。
これまで何度かLLMアプリケーションの評価について語ってきました。
運用についても記事や発表の形でシェアを行ってきました。
ですが、まだまだ「評価とはなにか?」という基本的なところで躓いてしまっている方も多い印象なので、今回は前提から丁寧に評価の全体像をまとめていきたいと思います。
LLMアプリケーションを運用している方の参考になれば嬉しいです!
なぜLLMアプリケーションを評価する必要があるのか
LLMをアプリケーションに組み込んでいると、LLMの出力を評価する必要が出てきます。
LLMの「出力は確率的である(毎回異なる)」ためです。
また、LLMの出力はハルシネーションを含む可能性がありますし、間違いではないにしてもサービス提供者の意図とは違った出力をエンドユーザーに提示してしまうかもしれません。
LLMの出力を評価して、出力が適切でないことを判定できれば、ユーザーには表示しない、出力を再度行わせる(出力をLLMに修正させるのもよいでしょう)というようなことができるようになります。
ただ、LLMアプリケーションの評価として、出力結果だけを評価すれば本当に満足なのでしょうか。
本来、LLMを組み込んだ機能やアプリケーションを作った目的はビジネス上の成果を達成することのはずです。
そのため、特定の課題を解決する満たすために作られたLLM機能は、その機能によって実際にどの程度”役立ったのか”やどの程度”ビジネス上の数値を向上させたのか”を評価する必要があります。
LLMアプリケーション(だけに限らず機械学習全般)の評価の議論がややこしいのは、このように"評価"という言葉が指す意味が文脈によって異なるからです。
また、評価の対象も文脈によって異なります。
XなどのSNS上で新しいモデルが出るたびに取り沙汰されるのは、モデルそのものに対する評価です。
GPTシリーズや、Claudeシリーズに新しいモデルが登場したときによく騒がれている、〇〇の性能で新しいモデルがトップに立ったと話題になるアレです。
リーダーボードとしては下記のようなものもあります。
しかし、LLMアプリケーションの開発者にとって本当に重要なのは、自社のアプリケーションにおける性能です。
リーダーボード上での評価が高いモデルが登場したからと言って、かならずしも自社のLLMアプリケーションの性能を向上させてくれるとは限りません。
(実際私もリーダーボードの評価は参考程度にしか見ていません。)
実際、プロンプトの与え方と解かせる課題のセットによっては、リーダーボードの結果とは異なる性能の優劣を示すことが多々あります。
このようにLLMアプリケーションにおける評価の議論には気をつけるべきポイントが複数存在します。
この記事では、まずは
- 評価対象
- オフライン評価とオンライン評価
- 評価指標の設定の仕方
という基本を整理したいと思います。
その上で、
- LLMアプリケーションの出力に対するの評価指標の設定の仕方
という個別の観点を押さえ、
- Pharmaxでの評価の運用
についても簡単にシェアしたいと思います。
評価対象
評価対象には下記のようなものがあります。
- ① LLMモデルそのものに対する評価
- ② fine-tuningsしたモデルに対する評価
- ③ (モデル+)プロンプトに対する評価
- ④ (モデル+)RAGやフローエンジニアリングなど、周辺処理を含むLLM機能の処理系全体に対する評価
①では、様々な分野で正しく答えられるか?というような一般的な知能・言語能力を評価します。
医学的な問いに正しく答えれるか?というように特定のドメインの能力や、日本語能力のような特定の言語の能力を扱うこともあります。
モデル間の性能を比較するいわゆるリーダーボードなどで扱われているのがこの評価です。
②と③は、特定のユースケースに対してどの程度想定した挙動になるのかを評価します。
fine-tuningしたり、プロンプティングしているということは、解きたい特定の課題があるはずなので、その課題に対して正しく出力できているかを評価しましょうということです。
④は、LLM機能・アプリケーションに対する評価です。
RAGであれば、検索+生成の全体が最も評価したい対象ですが、パーツとして、
- 検索の精度
- 検索した情報を与えた後の生成の精度
もそれぞれ評価することができるでしょう。
次に、フローエンジニアリングの簡単な例として、社内のバックオフィス系の質問に答えるチャットボットを作成することを考えましょう。
下記のようにa) 質問内容を分類して、b) その分類結果に応じて質問回答をする処理をするとします。
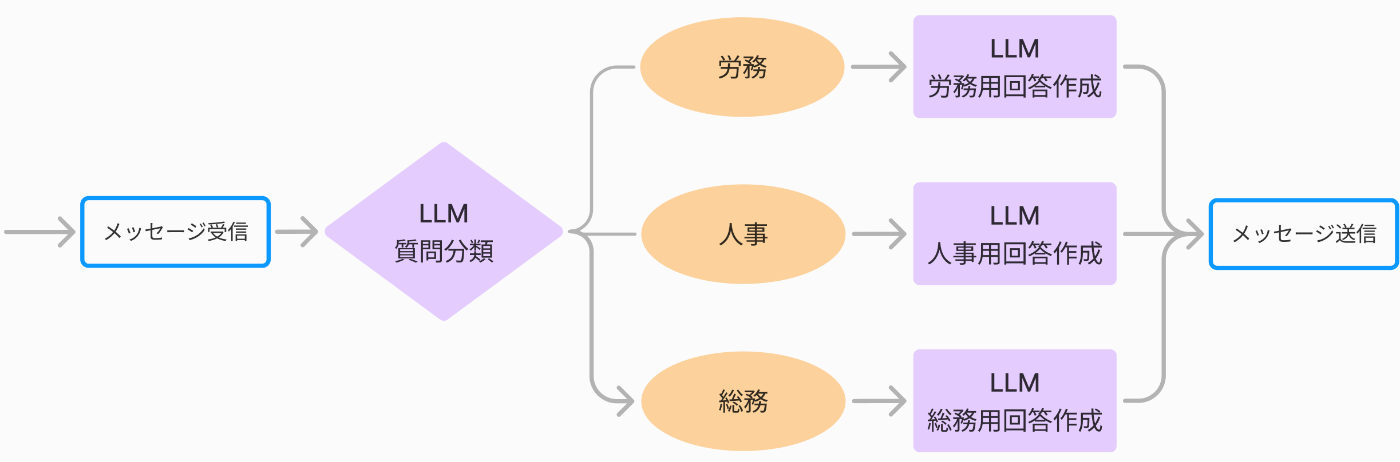
(フローエンジニアリングについては、私の『LLMマルチエージェントのフローエンジニアリングの勘所』をご覧ください)
このような機能の評価対象は、a) 質問内容を分類して、b) その分類結果に応じて質問回答をした結果、どの程度いい回答が得られたかという処理系全体です。
その中のパーツとして、
- a)質問内容を分類するモデル(+プロンプトやfine-tuning)
- b) 各分類の質問への回答作成モデル(+プロンプトやfine-tuning)
をそれぞれ評価することもできます。
というよりも、この場合には、a)やb)もパーツとして評価しなければ、処理系全体の精度の改善は見込めません。
このように処理系全体から見れば、fine-tuningやプロンプティングもパーツとして評価の対象なので、④は②や③を含むと考えることもできます。
これ以降は、基本的には④のLLM機能・アプリケーションを評価することを考えていきたいと思います。
オフライン評価とオンライン評価
次に大前提として、評価方法は、オフラインとオンライン評価に分けられることを認識しておいていただく必要があります。
| 評価の種類 | 説明 |
|---|---|
| オフライン評価 | 事前に準備したデータセットに対して機能の結果出力を行い、それを評価する。LLMを使った処理を本番システムに反映する前に実施するため、「事前評価」と呼ばれることもある。 |
| オンライン評価 | LLM機能が実際に稼働した後、実ユーザーの反応など、実際のトラフィックを使った評価する。LLMを使った処理を本番システムに反映する前に実施するため、「事後評価」と呼ばれることもある。 |
PharmaXでも、オフライン評価とオンライン評価の両方を行って、LLMアプリケーションを評価しています。
機械学習やLLMアプリケーションの文脈で評価と言えば、オフライン評価のことを指す場合が多い印象です。
しかし、後述するようにオフライン評価で評価できる指標には限りがあります
また、事前に準備したデータセットが本番データと同じ傾向であることを担保するのは実はかなり難しいことです。
当初は、本番データの傾向を上手く反映したデータセットを準備できたとしても、時間の経過とともに本番データの傾向が変化することもあります。
そのため、オンライン評価も組み合わせて、総合的に評価していく必要があります。
評価指標の設定の仕方
評価の3レイヤー
評価指標にはレイヤーの概念があることも念頭においておく必要があるでしょう。
- レベル1: LLM機能・アプリケーションそのものに対する評価
- 出力に対するの評価
- 期待するアウトプット=Grand Truthと実際のアウトプットの比較
- 出力の妥当性の評価(LLM as a Judgeで扱う)
- レイテンシーなどの非機能要件の評価
- 出力に対するの評価
- レベル2: LLM機能・アプリケーションに対するユーザーの反応や挙動に対する評価
- ユーザーからの直接的なフィードバック(Good/Badボタンでの評価など)
- ユーザーの利用状況(クリック率や受入れ率など)
- レベル3: KPIが向上したかどうかの評価
レベル1、2、3と進むほど、ゴール=目的に近くなっていきます。
逆を返すと、レベル1、2、3と進むほど、LLM機能の良し悪しだけでは成果は決まらなくなっていきます。
レベル1: LLM機能・アプリケーションそのものに対する評価
レベル1は、LLM機能・アプリケーションそのものに対する評価です。
当たり前ですが、まずは出力そのものに対する評価をしたくなります。
これには大きく分けて2つの評価方法があって、
- 期待するアウトプット(Grand Truth)と実際のアウトプットを比較してスコアリングする
- 定義した評価基準に基づいて、システムの出力の妥当性をスコアリング(合格/不合格を判定)する
というものがあります。
出力の評価方法の1つ目はいわゆる"精度"と呼ばれるものです。
2つ目は、アプリケーションにとって満たすべき出力の要件をクリアしているか(=妥当性)を評価します。
要件を満たしているかを人の手ですべて評価していたのでは、到底手が回らないので、LLM-as-a-Judgeと呼ばれるLLM出力を評価させる手法が注目されています。
これら出力に対する評価については、また後ほど詳しくご紹介いたします。
また、レベル1では、アプリケーションはレイテンシーなどの非機能要件も含んで評価する必要もあります。
わざわざ言うほどのことでもありませんが、どれだけ素晴らしい出力をしていても、レスポンスが遅すぎれば使い物になりません。
ユーザーが出力を待っているような、文字通りのリアルタイム性を求められるようなサービスなら、1秒から数秒以内にレスポンスを返さなければ、誰も使わない機能になってしまうでしょう。
レベル2: LLM機能・アプリケーションに対するユーザーの反応や挙動に対する評価
レベル2は、そのLLM機能に対して、どのようにユーザーが反応したかの評価です。
すぐ思いつく方法として、ユーザーに直接フィードバックしてもらうという方法もあります。
しかし、ユーザーからフィードバックを集めるのはなかなか難しいので、クリック率などの行動データを収集して評価することになります。
ゴールであるKPIの先行指標となるような指標が望ましいでしょう。
例えば、Netflixのようなサブスクサービスを考えてみましょう。
LLMによって向上させたいKPIが継続率だとします。
その場合の先行指標として評価すべきは、LLM機能によって見られる動画の件数が増えたのか?などになるでしょう。
ただし、レベル2の評価はLLM機能の性能だけでは決まらないことに注意が必要です。
KPIはLLMとは関係ないUXにも影響を受けます。
上記のNetflixの例で言えば、LLM機能がイケていたとしても、動画の選択するまでのUXに問題を抱えていれば、見られる動画の件数は増えないということもあり得ます。
レベル3: KPIが向上したかどうかの評価
最後にレベル3は、そのLLM機能が実際にKPIを向上させたかどうかの評価です。
KPIはビジネスによって変わりますが、例えば、購入率や入会率の向上や、生産性の向上などです。
サブスクであれば、継続率なども代表的なKPIにあたるでしょう。
ただし、レベル3の結果が出るまでは、レベル2以上にLLM機能以外の影響も受けます。
Netflixの例で言えば、LLM機能がイケていたとしても、最終的なKPIである継続率は上がらない理由はいくらでも考えつきます。
極端な例では、toBビジネスでは、LLM機能がどれだけ素晴らしくても、営業プロセスが上手くいっていなければ、プロダクトが売れないということもあり得るのです。
このように評価について議論している時は、このような三階層を意識して議論することが重要です。
評価指標を設定するでの観点
当然、LLM機能を作る目的は、ビジネス上のKPIを上げることです。
ですから、本来的には、そのLLM機能がビジネス上のKPIを向上させたかどうかを評価する必要があります。
つまり、レベル3の評価が最も重要な評価です。
一方で、KPIとなるビジネス指標への影響は、様々な要因が混ざり合う上に、評価できるまでの時間軸も長くなります。
そこで、その手前のレベル1やレベル2の評価指標でも評価することができれば、LLMアプリケーション開発のPDCAを素早く回すことができます。
例えば、サブスクサービスの継続率を向上させるためにLLM機能を導入したとして、継続率が上がるほどの影響があったのかが分かるまでにはある程度の時間がかかります。
また、他にも同時並行で機能改善が進んでいたりするでしょうから、そのLLM機能のみの影響で継続率が上がったことは証明できないことの方が多いのです。
そのため、理想は、レベル1やレベル2の評価指標の評価値が向上すれば、しばらくしてレベル3のKPIが上がるような先行指標となる評価指標を設定することです。
そのため、レベル1やレベル2の指標をKPIに対する先行指標や代理指標(先行変数や先行変数)と呼んだりします。
しかし、実際にサービスを開発したことがある方は分かるように、そうは問屋が卸さないのが世の中です。
現実的には、KPIにきれいに相関するようなレベル1やレベル2の先行指標を見つけることは至難の業と言っても過言ではありません。
もちろん、(LLMの例ではないですが、)画像認識による不良部品の除去のように、モデルの精度が上がれば、ビジネス上のKPIが直接的に向上する(この場合は、作業員の工数の削減や見逃し率の低下)ような場合もあります。
しかし、例えば、その人が興味のある商品や動画を精度高くレコメンデーションした(レベル1)からといって、クリック率は上がる(レベル2)かもしれませんが、購入率や成約率が上がる(レベル3)とは限らないのです。
これが評価指標の設定に関する本質的な難しさです。
特に、オフライン評価で評価できるのはあくまでレベル1の評価指標だけです。
オフライン評価でいい評価結果を出したからといって、KPIが上がるとは限らないと言われるのは、そもそもレベル1の評価結果が上がった結果、レベル3のKPIも上がるという素直な関係にある評価指標を設定できていないケースが多いのです。
また、オフライン評価の場合は、オンライン評価とオフライン評価 でも述べたように、評価用のデータも本番とは異なるケースも多いため、
より一層オンライン評価でいい評価を出すことが、KPIが上がるという結果をもたらすとは限らないということになってしまうというわけです。
KPIの先行指標となる評価指標を決めることの難しさについては、この10年ほどの機械学習のビジネス利用に普及に伴い様々な意見が出されています。
有名なのものとして、Booking.comとNetfilxの
- 『150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com』
- 『The Netflix Recommender System: Algorithms, Business Value, and Innovation』
などが挙げられるでしょう。
上記の論文に関する日本語の記事は、下記あたりがよくまとまっています。
『150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com』の中では、彼らが学んだこととして、
MODELING: OFFLINE MODEL PERFORMANCE IS JUST A HEALTH CHECK
(オフラインモデルのパフォーマンスはヘルスチェックに過ぎない)
と断言されています。
『The Netflix Recommender System: Algorithms, Business Value, and Innovation』でも、
we do not find them (=offline experiments) to be ashighly predictive of A/B test outcomes as we would like.
(オフラインテストは、期待するほどの高い精度でA/Bテストの結果を予測するものではない)
と述べられていることはよく知られています。
評価指標の決め方については、『評価指標入門〜データサイエンスとビジネスをつなぐ架け橋』も参考にするとよいでしょう。

ここからは、レベル1の中でも、LLMアプリケーションの出力に対するの評価について詳しく見てきましょう。
レベル2とレベル3の評価は、LLMアプリケーションに限らず(もはや機械学習に限ったことでもなく)、
すべての機能やアプリケーションに共通する議論なので、ここではこれ以上深く立ち入らないこととします。
LLMアプリケーションの出力に対するの評価指標の設定の仕方
LLMアプリケーションの出力に対するの評価をどのように行うべきなのかを考えていきましょう。
上記でも述べたように、出力に対するの評価には大きく分けて2つの評価方法があって、
- 期待するアウトプット(Grand Truth)と実際のアウトプットを比較してスコアリングする
- 定義した評価基準に基づいて、システムの出力の妥当性をスコアリング(合格/不合格を判定)する
というものがあります。
期待するアウトプット=Grand Truthと実際のアウトプットの比較
出力の評価方法の1つ目はいわゆる"精度"と呼ばれるものです。
画像認識の機械学習モデルなら、画像認識の正解率を評価します。
LLMは文章を生成するので、そう簡単ではなく、期待するアウトプットとの文字列間の距離をEmbedding DistanceやLevenshtein Distanceでスコアリングしたりします。
出力の妥当性の評価(LLM as a Judge)
出力の評価方法の2つ目は、アプリケーションにとって満たすべき出力の要件をクリアしているか(=妥当性)で評価します。
要件は、LLMアプリケーションの開発者が自分たちで考えて設定する必要があります。
例えば、「日本で一番高い山は?」という質問に対して、
「富士山」
「富士山です」
「富士山に決まってんだろーが!」
「富士山。標高3776.12m。その優美な風貌は…(略)」
と答えるのはどれも正解です。
しかし、そのアプリケーションにとって望ましい言葉遣いや答え方というものがあるでしょう。
LLMの出力が正しいかどうかだけではなく、様々な観点でサービスの要件を満たしているかを評価する必要があります。
- 論理的に正しいことを言っているか
- 嘘を含んでいないか
- ヘイトスピーチや攻撃的な表現を含んでいないか
- 個人情報などを出力していないか
と言った一般的な要件だけでなく、
- 自社の回答マニュアルに従っているか
- (VTuberなどが)キャラクター設定に合っているか
などのアプリケーション独自の観点でも評価しなければなりません。
ただし、上記のようなあらゆる観点で、LLMの出力をすべて人が評価していたのでは、到底手が回りません。
そこで、注目されているのが、LLM-as-a-Judgeと呼ばれるLLMにLLMの出力を評価させる手法です。
LLM-as-a-Judgeについは、下記の記事でも詳しくご紹介しています。
下記は、LLM-as-a-Judgeを基礎から解説した記事ではないですが、LLM-as-a-Judgeに関する話題を扱っているのでご参考にしていただければ幸いです。
PharmaXでの評価の運用
PharmaXでは、オフライン評価、オンライン評価の両方で評価をしています。
評価・実験管理ツール
PharmaXでは、少し前までPromptLayerというツールを使っていました。
ですが、2024/8現在では、LangSmithへの移行がほぼ完了しています。
移行した理由は下記をご覧ください。
PharmaXでのオフライン評価
PharmaXでは、プロンプトを大きく変更したタイミングや、モデルをアップデートするタイミングでオフライン評価を行っています。
PharmaXのYOJOというサービスのメッセージサジェスト機能の例に取ります。
患者さん(ユーザー)と薬剤師の会話の流れ(この場合は会話の流れがデータセットということ)をあらかじめ大量に用意し、LLMに返信をサジェストさせます。
例えば、数100〜1000件程度の会話パターンに対する返信のサジェストを評価し、プロンプトの変更前後で評価が高まったのかどうかを判断するようなイメージです。
PharmaXでは、下記のように評価結果をSlackに通知しています。

くどいようですが、オフライン評価では、レベル1の評価しかできないことに注意が必要です。
これまで述べた以外にも、オフライン評価のデメリットとしては、プロンプトの変更の度に評価をしていてはコストが掛かりすぎることなどが挙げられます。
特にLLM as a Judgeを行う場合、それなりの費用が掛かるので、プロンプトのちょっとした変更のたべいにオンライン評価を行うのは、現実的ではないかもしれません。
そこで、私たちは、オフライン評価とオンライン評価を組み合わせて総合的に評価しています。
PharmaXでのオンライン評価
PharmaXでは、オンライン評価として、レベル1の出力に対するの評価や非機能要件の評価も行っています。
オンライン評価というと、レベル2やレベル3の評価のことを指すと考えている方もいらっしゃるようです。
ですが、アプリケーションにはよるものの、オンラインでもレベル1の出力に対する評価をすることは可能です。
特にLLM as a Judgeをしていれば、出力を自動で評価することが可能なので、オンラインでリアルタイムで評価することができます。
YOJOのメッセージサジェスト機能の例で言えば、評価が特定の値を下回った場合は、メッセージのサジェスト結果を修正して再度LLMにメッセージを作り直させています。
もちろん、この場合、メッセージが複数作られることになるので、余分に時間と費用はかかってしまいますが、より正確なサジェストが行われるので、薬剤師が修正する手間は省けるということになります。
このようにリアルタイムで評価すれば、その評価結果を使った次の処理も可能になります。
また、下記のように評価結果の集計を日次で可視化することもしています。
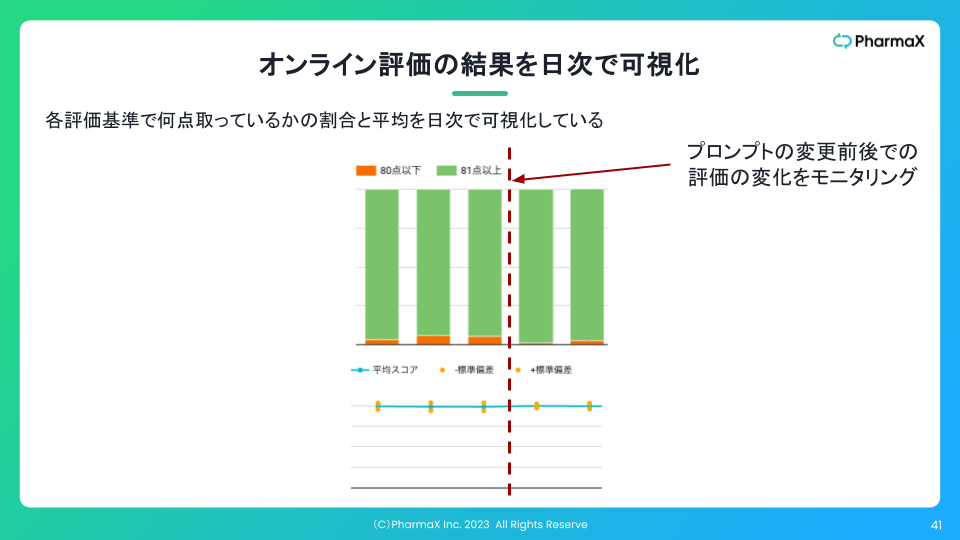
このように可視化していれば、プロンプトの変更などをした前後で、実際に出力がよくなったのかどうかを判断することができます。
肝は、本番データで比較が可能になるということです。
それだけではなく、ある日突然データの傾向が変わるなどして、出力が劣化したことに気がつくことができるようにもなります。
さらに、私たちは、レベル1についてだけではなく、下記のようにレベル2のユーザーの利用状況も可視化しています。
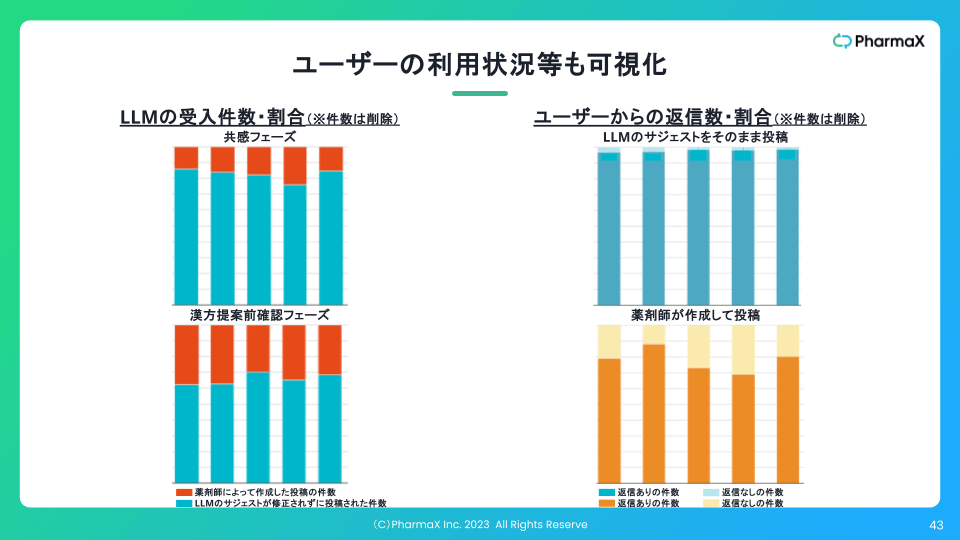
数値を削除したかなり古いデータ
もちろんレベル3のKPIである購入率や継続率にもかなりポジティブな影響は出ていますが、さすがにお見せできないので、ここでは省略します。
まとめ
今回は、LLMアプリケーションの評価についてまとめました。
評価と言っても、
- 評価対象
- オフライン評価とオンライン評価
- 評価指標の設定の仕方
などの複数の観点があり、ややこしくてよく分からないと思っていらっしゃるという方も多いと聞くので、今回は基礎からかなりしっかりとまとめました。
また、LLM as a Judgeなどのホットな話題にも触れることができました。
評価をして、LLMアプリケーションをうまく運用したいと思っている方の参考になれば嬉しいです!
直近下記のようなイベントも開催するので、ご興味のある方は是非ご参加いただければ嬉しいです。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion