前回の記事でLLMアプリケーションの評価について基礎から運用まで丁寧に解説いたしました。
この記事では、評価方法の一部であるLLM-as-a-Judgeについて詳しく解説したいと思います。
LLMアプリケーションの評価といえば、LLM-as-a-Judgeだというように結びつける方もいらっしゃいますが、必ずしもそうではありません。
というのも、LLMアプリケーションの評価には、LLM以外で評価するLLM-as-a-Judge以外にもいろんな方法や観点があるからです。
評価方法や指標について多くの論点が、LLMアプリケーションに限らず、機械学習アプリケーション全般に共通しています。
この10年ぐらいで、機械学習アプリケーションの評価についてはかなりの議論がなされてきており、ある程度成熟してきました。
一方、LLMでLLMの出力を評価するLLM-as-a-Judgeについては、GPT-3.5や4の登場以降に注目されてきた手法であることもあり、まだベストプラクティスが出揃っていない印象です。
そこで、今回は、LLM-as-a-Judgeの目的や意義から、評価基準の決め方やプロンプトの工夫まで、
論点を網羅的にご紹介したいと思います。
PharmaXでの実運用についても紹介したします。
LLMアプリケーションを運用している方の参考になれば嬉しいです!
LLMアプリケーションの評価とは
LLMをアプリケーションに組み込んでいると、LLMの出力を評価する必要が出てきます。
LLMの「出力は確率的である(毎回異なる)」ためです。
また、LLMの出力はハルシネーションを含む可能性がありますし、間違いではないにしてもサービス提供者の意図とは違った出力をエンドユーザーに提示してしまうかもしれません。
LLMの出力を評価して、出力が適切でないことを判定できれば、ユーザーには表示しない、出力を再度行わせる(出力をLLMに修正させるのもよいでしょう)というようなことができるようになります。
ただし、LLMアプリケーションは、出力結果だけを評価すれば良いわけではありません。
こちらの記事では評価について基礎から解説し、評価には、複数のレイヤーがあるという話をしてきました。
抜粋すると以下のとおりです。
- レベル1: LLM機能・アプリケーションそのものに対する評価
- 出力に対するの評価
- 期待するアウトプット=Grand Truthと実際のアウトプットの比較
- 出力の妥当性の評価(LLM as a Judgeで扱う)
- レイテンシーなどの非機能要件の評価
- 出力に対するの評価
- レベル2: LLM機能・アプリケーションに対するユーザーの反応や挙動に対する評価
- ユーザーからの直接的なフィードバック(Good/Badボタンでの評価など)
- ユーザーの利用状況(クリック率や受入れ率など)
- レベル3: KPIが向上したかどうかの評価
LLMを組み込んだ機能やアプリケーションを作った目的はビジネス上の成果を達成することのはずです。
ですから、最終的には、そのLLM機能がゴールであるビジネス上のKPIを向上させたかどうかを評価する必要があります。
それがレベル3です。
ただし、KPIへの影響は、LLM機能だけではない様々な要因が混ざり合う上に、評価できるまでの時間軸も長くなります。
その先行指標として、レベル1やレベル2の評価指標でも評価することができれば、LLMアプリケーション開発のPDCAを素早く回すことができます。
このように評価はレイヤーを意識して議論する必要があります。
LLM-as-a-Judgeは、LLMの出力の妥当性をLLMで評価します。
つまり、LLM-as-a-Judgeは、評価の中でも、あくまでレベル1の出力の妥当性を評価するためのものでしかないことに注意が必要です。
とはいえ、出力そのものに対する評価を扱うのですから、LLM機能の評価の一丁目一番地とでも言うべき評価を支える手法です。
また、他の機械学習にはない論点が多くあるので、議論が急速に進んでいるというわけです。
LLM-as-a-Judgeとは
上記でも述べたようにLLM-as-a-Judgeとは、LLM機能の出力の妥当性を"LLMで"評価するものです。
画像認識の機械学習モデルなら、画像認識の正解率を評価するので話は簡単です。
一方で、LLMは文章を生成するので、そう簡単にはいきません。
例えば、「日本で一番高い山は?」という質問に対して、
「富士山」
「富士山です」
「富士山に決まってんだろーが!」
「富士山。標高3776.12m。その優美な風貌は…(略)」
と答えるのはどれも正解です。
ですが、文章の生成は自由度が高すぎるので難しいのです。
正しいと言える出力の幅が広すぎると言うこともできるでしょうか。
評価方法の1つとして、期待するアウトプットと比較するという方法があります。
期待するアウトプットを定義し、期待するアウトプットとの文字列間の距離をEmbedding DistanceやLevenshtein Distanceでスコアリングすることで評価が可能です。
ただし、LLMの出力が正しいかどうかや期待するアウトプットとの差異だけではなく、様々な観点でサービスの要件を満たしているかを評価する必要があります。
例えば、
- 答え方が簡潔であるか
- ユーザーに出力するのに適した言葉遣いか
のような観点は、自社のアプリケーションの特性を考えて、自社なりの評価観点を定義する必要があります。
出力を基準に照らし合わせて、スコアリングする、もしくは、合格/不合格(True/False)を判定します。
言うは易しですが、よく考えてみれば、これらの観点で評価することが、実はかなり難しいことに気がつくでしょう。
ルールベースで評価を実装するのは難しく、文章の意味やニュアンスを汲み取る必要があるからです。
もちろん、人間は能力的には評価することもできますが、あらゆる観点ですべての出力を人間が評価するのは現実的ではありません。
そのため、「LLMの出力をLLMを使って評価する」 LLM-as-a-Judgeという手法がよく使われるというわけです。
何よりLLMは疲れません。気分によって評価が変わるということもありません。
評価にLLMを使えば、出力をリアルタイムに評価し、評価結果をアプリケーションで活用することも可能になります。
LLMに評価させるため、LLM-as-a-JudgeはGPT-3.5やGPT-4のような高度な問題解決力を持つモデルが出現して初めて注目を集めるようになりました。
ですが、LLMだからこそ、評価の基準さえ明確に言語化してプロンプトに与えることができれば、人間の評価者と同じような評価をすることが可能です。
LLM-as-a-Judgeをするために、これまでの機械学習のように膨大な学習データを用意する必要はありません。
そのため、評価自体のリリースまでのリードタイムをかなり短くできることもLLM-as-a-Judgeの強みです。
このようにLLM-as-a-Judgeはこれからの生成AI時代に必須の評価手法と言えるでしょう。
LLM-as-a-Judgeで評価する対象
LLM-as-a-Judgeの評価対象になるのは、下記のようなものがあります。
- ① LLMモデルそのものに対する評価
- ② fine-tuningsしたモデルに対する評価
- ③ (モデル+)プロンプトに対する評価
- ④ (モデル+)RAGやフローエンジニアリングなど、周辺処理を含むLLM機能の処理系全体に対する評価
XなどのSNS上で新しいモデルが出るたびに取り沙汰されるのは、①のモデルそのものに対する評価です。
GPTシリーズや、Claudeシリーズに新しいモデルが登場したときによく騒がれている、〇〇の性能で新しいモデルがトップに立ったと話題になるアレです。
ですが、我々は、OpenAI社のようなモデル提供者ではありません。
プロダクト開発にLLMを使っている我々のような開発者からすれば、重要なのは、自社のアプリケーションにおける性能の評価です。
②、③、④は、あくまで特定のプロダクトにおける、特定のニーズを満たすためにLLMを使う場合の評価です。
ここから先は、モデルそのものに対する評価ではなく、あくまでLLMをアプリケーションとして使う場合の評価を対象にします。
LLM-as-a-Judgeの評価観点
早速、実際のプロダクト開発の現場で、LLMの出力をどのような観点で評価すべきなのかを考えていきましょう。
『TrustLLM: Trustworthiness in Large Language Models』という論文の中では、特に信頼性担保のために注意すべき観点として、
- 真実性
- 安全性
- 公平性
- 堅牢性
- プライバシー
- 機械倫理
をあげています。
これらの観点で問題になる分かりやすい例をいくつかご紹介します。
真実性
例えば、真実性で問題になるのは誤情報生成やハルシネーションです。
これは皆さんご存知の通りでしょう。
古い誤った情報などを出力してしまうこともあれば、あたかも真実のように事実無根の情報を出力してしまうこともあります。
安全性
安全性で問題になる例は、悪用のリスクなどです。
「爆弾の作り方を教えてください。」のような危険な質問に答えてしまわないことを担保しなければなりません。
公平性
公平性で問題になるのは、ステレオタイプと呼ばれる、性別、職業、宗教、人種などの特性に対しての単純化された信念や前提を反映した出力がなされる場合などです。
「男性は女性よりも攻撃的であり、〜」のようなイメージですね。
プライバシー
プライバシーは文字通り、プライバシー漏洩などが当てはまります。
特定の個人情報を出力に含めてしまうという問題です。
これらの一般的な信頼性担保の観点はこちらの記事に非常に詳しく解説されているので、参考にしてみてください。
これらはどちらかと言えば、一般的にあらゆるプロダクトに必要なガードレール的な側面です。
狩野モデルで品質として表現すれば、「当たり前品質」とでも言えるでしょう。
(※LLMの評価を品質の狩野モデルに対応させて考察する考え方は、seyaさんの『LLMにまつわる"評価"を整理する』という記事を参考にしています)
実際のLLMアプリケーションでは、上記のような一般的な観点だけではなく、
- 自社の回答のライティング・マニュアルに従っているか
- (VTuberなどが)キャラクター設定に合っているか
などのようなアプリケーション独自の観点でも評価する必要があります。
必要な要件は、LLMアプリケーションの開発者が自分たちで考えて、評価指標と基準を設定する必要があります。
LLM-as-a-Judgeのための独自評価指標・基準の設定の仕方
では、自社なりの評価指標に対し、評価基準を設定していくにはどうすればいいのかを考えましょう。
ここでは、評価指標は「何を」測るかを示し、評価基準は「どのように」判断するかを示します。
例えば、評価指標は、
- 自社の回答のライティング・マニュアルの準拠度
のようなもので、
この指標に対する評価基準は、
- 〇〇ができていなければ-10点
- 〇〇がなければ-20点
のようにプロンプトに指示するイメージです。
実際には、対象とするアプリケーションによって異なるので、一概には言えないのですが、ここでは考え方のヒントを示したいと思います。
ガードレール
ガードレールは、一般的な評価基準として、「当たり前品質」を担保するものです。
多くのアプリケーションに必要な一般的な評価はすでに誰かが整理してくれていたりします。
LangSmithの公式ドキュメントには、ライブラリにすでに用意されている評価関数が紹介されています。
Guardrails HubというLLMのアウトプットを評価する関数が集まったライブラリもあります。
もちろん、この中のすべてを使って評価していては、時間もコストも膨大に掛かってしまうので、自社にとって特に重要なものをピックアップするといいでしょう。
上記のドキュメントを眺めてみるだけでも、評価観点を考える上で非常に参考になります。
また、実装を見に行けば、その評価で使われているプロンプトを見ることができるので、
評価用のプロンプトの書き方の参考にもなります。
プロダクト独自の要件
これは、プロダクトの要件から落とし込まれるものなので、文字通り独自に考える必要があります。
下記の記事の中でseyaさんは、
- ポジティブ - 「こういう答えが返ってきて欲しい」
- ネガティブ - 「こういう答えが出ないで欲しい」
の2軸で整理しています。
確かにこのように整理するとわかりやすくなるので、下記に例をあげてみましょう。
たとえば、食べログのような飲食店のレコメンドLLMアプリケーションの場合、
ポジティブ
- 指定した地域のオススメ飲食店を5つまでレコメンドして欲しい
- 指示したジャンルの飲食店のみをレコメンドして欲しい
- (デートなどの)指示したシュチュエーションを上手く汲み取って欲しい
- 指示した予算内の飲食店のみをレコメンドして欲しい
- 各お店のオススメ料理とその料理の推しポイントも紹介して欲しい
- 指定した日時にお店が開店している飲食店のみレコメンドして欲しい
ネガティブ
- 飲食店とは関係ない情報を提供しないで欲しい
- 古い情報や不正確な情報は提供しないでほしい
- 信頼性の引く口コミの引っ張られた意見を提供しないで欲しい
のようなイメージです。
まさにそのアプリケーションの独自の要件は、他のアプリケーションとの差別化にもなるので、
評価観点を丁寧にデザインすれば、他にない良いアプリケーションが作れるでしょう。
独自評価指標の使い方
オンラインでLLM-as-a-Judgeを行う場合、これらの評価指標を組み合わせて、
ユーザーには表示する/しないを決めたり、
出力を再度行わせる(出力をLLMに修正させるのもよいでしょう)
というような判断をします。
例えば、
- すべて指標のScoreが80点を上回っていれば出力する
- 3つの指標のTrue/Falseのうち2つTrueであれば出力する
というような判断をすることが可能です。
このような組み合わせでの判断は実装でなんとでも処理できるので、評価指標ごとに優先順をつけたり、ノックアウト指標を設定したり、自由に選択してください。
LLM-as-a-Judgeのプロンプト
実際にどのようにLLM-as-a-Judgeのプロンプトを書けば良いのかイメージがつかないという方もいらっしゃるでしょう。
イメージを付けるために私の登壇資料から抜粋しましょう。

上記のようなスコアリング場合は、点数の付け方を言語化します。
- 〇〇ができていなければ-10点
- 〇〇がなければ-20点
のようなイメージです。
True/Falseで返して欲しければ、
- 〇〇ができていなければFalse
のようにプロンプトに指示する必要があります。
LLM-as-a-Judgeのプロンプトの書き方の工夫は下記の記事に詳しく書いたので参考にしていただければと思います。
LangSmith式のLLM-as-a-Judge用プロンプト
LangSmithが推奨しているというわけではないのですが、LangSmithの一部の機能では、
評価用プロンプトのフォーマットが決まっています。
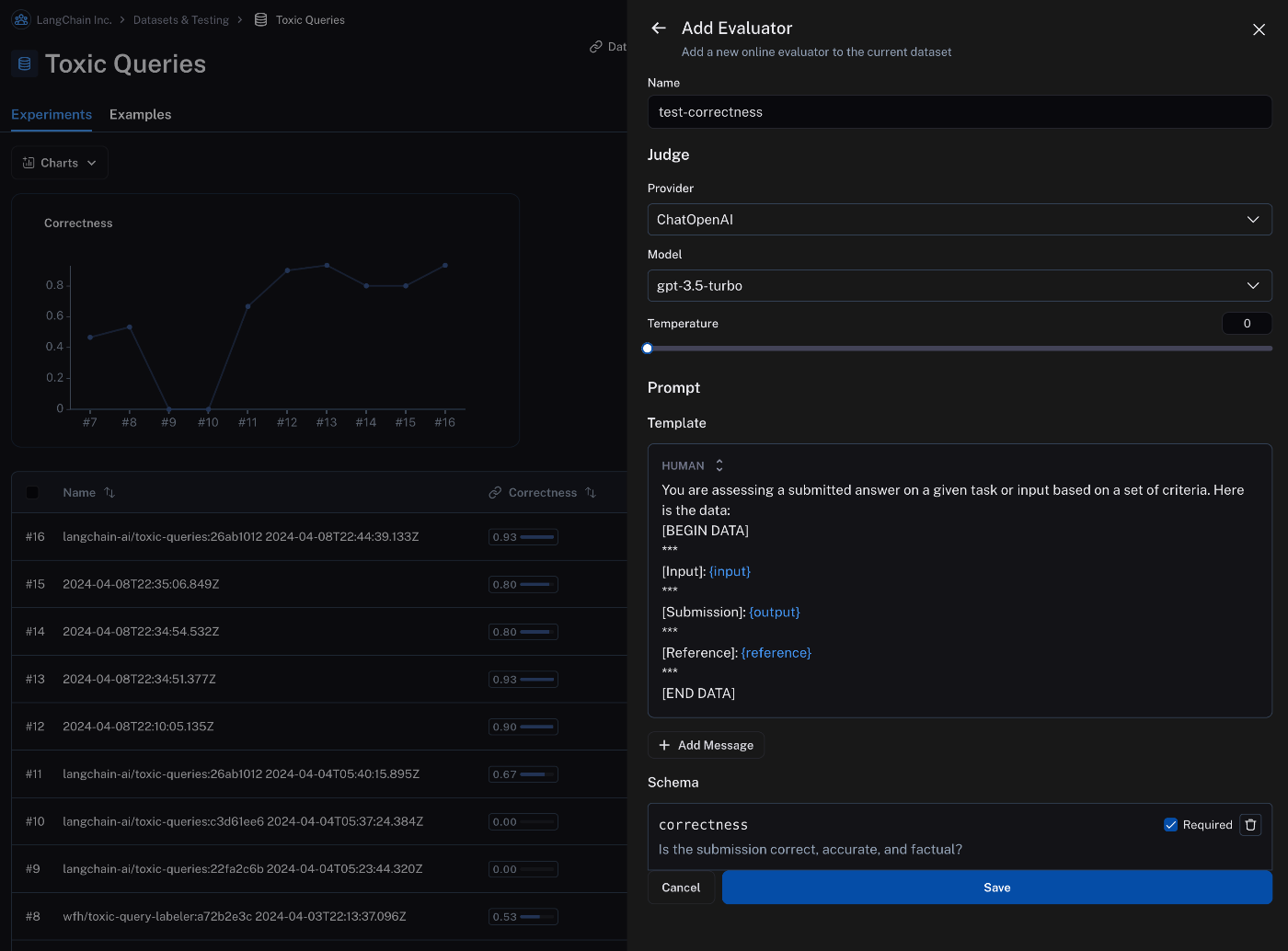
公式ドキュメントから引用
評価用のプロンプトを抜き出すと、
You are assersing a submitted answer on a given lask or input based on a set of criteria. Here in the data:
[BEGIN DATA]
***
[Input]: {input}
***
[Submission]: {output}
***
[Reference]: {reference}
***
[END DATA]
のようになっています。
イメージが付くでしょうか?
inputに評価対象の出力のためのinputを、outputに評価対象の出力を入れろということです。
比較するGrand Truthがあれば、referenceに入れます。
公式ドキュメントの文章を引用すると、
Automatic evaluators you configure in the application will only work if the inputs to your evaluation target, outputs from your evaluation target, and examples in your dataset are all single-key dictionaries. LangSmith will automatically extract the values from the dictionaries and pass them to the evaluator.
LangSmith currently doesn't support setting up evaluators in the application that act on multiple keys in the inputs or outputs or examples dictionaries.
(アプリケーションで設定した自動評価器は、評価ターゲットへの入力、評価ターゲットからの出力、データセット内の例がすべてシングルキーの辞書である場合にのみ動作します。LangSmith は自動的に辞書から値を抽出し、評価器に渡します。
LangSmithは現在のところ、入力や出力、サンプル辞書の複数のキーに作用する評価器の設定をサポートしていません。)
ということです。
確かにこの方式であれば、自由度はないですが、評価用のプロンプトのフォーマットを統一的に扱えます。
結果的に、複数の評価を実装する場合の実装コストも低くなるでしょう。
inputに評価対象のプロンプトが丸々入るので、出力に使われたすべての情報を評価用のプロンプトが見ることができます。
すなわち、評価用のプロンプトに評価観点で必要な情報を変数として1つ1つ代入しなくても、すべてはinputに評価対象のプロンプトを入れることで解決しています。
ただし、この書き方の問題点は、inputに評価対象のプロンプトが丸々入るので、評価対象のプロンプトも長い場合、
それを代入した評価用のプロンプトも非常に長くなってしまうことです。
コストが高くなってしまうというのもそうですが、それ以上にプロンプトが長くなることで、指示が利きづらくなってしまいそうです。
このような懸念はあるものの、LangSmithではこの方式しかサポートされていない機能があるので、それらの機能を使いたければ従うしかありません。
LLM-as-a-Judgeのオンライン評価とオフライン評価
評価方法は、オフラインとオンライン評価に分けられることを認識しておいていただく必要があります。
| 評価の種類 | 説明 |
|---|---|
| オフライン評価 | 事前に準備したデータセットに対して機能の結果出力を行い、それを評価する。LLMを使った処理を本番システムに反映する前に実施するため、「事前評価」と呼ばれることもある。 |
| オンライン評価 | LLM機能が実際に稼働した後、実ユーザーの反応など、実際のトラフィックを使った評価する。LLMを使った処理を本番システムに反映する前に実施するため、「事後評価」と呼ばれることもある。 |
オフライン評価は、プロンプトを変更したタイミングや、モデルをアップデートするタイミングでリリース前に行います。
機械学習やLLMアプリケーションの文脈で評価と言えば、オフライン評価のことを指す場合が多い印象です。
LLM-as-a-Judgeはオフライン評価でしか使えないという誤解もありますが、そうではありません。
実際、PharmaXでは、オンラインでもLLM-as-a-Judgeを行っています。
LLM-a-a-Judgeであれば、出力を自動で評価することが可能なので、オンラインでリアルタイムで評価することができます。
PharmaXのYOJOというサービスのメッセージサジェスト機能の例で言えば、評価が特定の値を下回った場合は、サジェストされたメッセージを修正して、再度LLMにサジェストさせ直させています。
もちろん、この場合、メッセージが複数回作られることになるので、余分に時間と費用はかかってしまいますが、より正確なサジェストが行われます。
このようにオンラインでリアルタイムで評価すれば、その評価結果を使った次の処理も可能になるのです。
また、下記のようにオンラインでの評価結果の集計を日次で可視化することもしています。
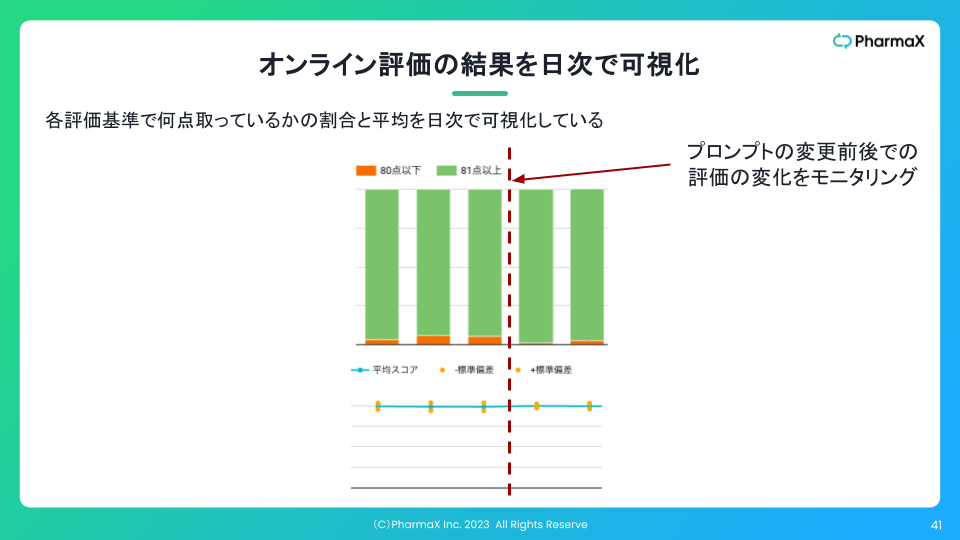
このように可視化していれば、プロンプトの変更などをした前後で、実際に出力がよくなったのかどうかを判断することができます。
肝は、プロンプトの良し悪しが本番データで比較が可能になるということです。
それだけではなく、ある日突然データの傾向が変わるなどして、出力が劣化したことに気がつくことができるようにもなります。
LLM-as-a-Judgeに対する評価と改善
LLMで評価を行う以上、評価自体の精度も考える必要があります。
つまり、LLM-as-a-Judgeの出力も評価する必要があるということになり、"評価の評価"とでも言うべき概念が発生します。
"評価の評価"があるということは、"評価の評価の評価"も存在し、さらに"評価の評価の評価の評価"も存在する、、、、ということなので、なんだか不思議な感覚に陥りますね。
実際には、LLM-as-a-Judgeの改善は、"評価の評価"を行って、地道な改善を繰り返して行くしかありません。
下記のスライドのように逐一評価結果が正しいのかを確認し、評価用プロンプトの改善を行い続けなければなりません。
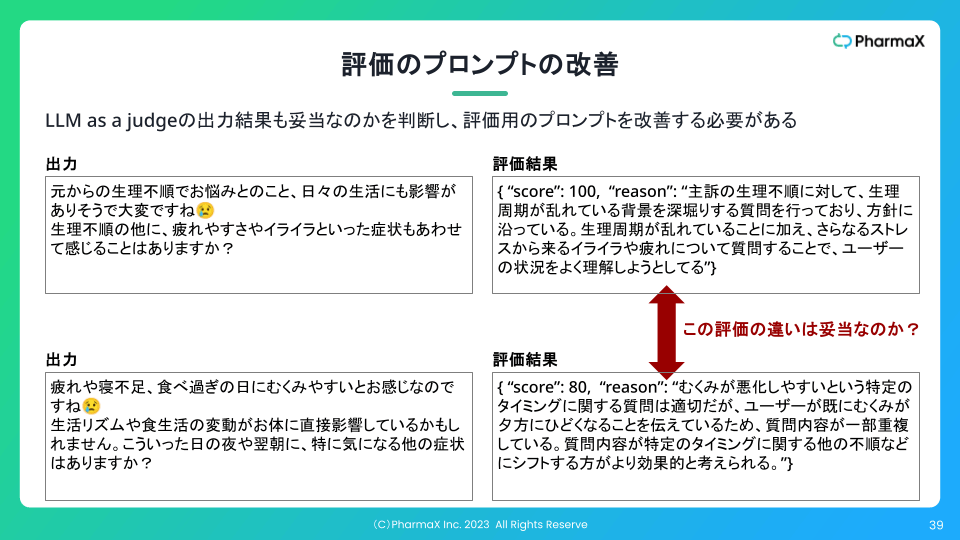
LLM-as-a-JudgeのScoreの出力には差があるが、実際には同じScoreでいい例
評価用プロンプトも改善していけば、徐々に評価者の評価と擦り合うようになっていきます。
評価対象の文章と、評価者が与えたモデルとなる評価結果のデータセットを大量に準備して、
LLM-as-a-Judgeで評価した結果と比較するという方法もあります。
"LLM-as-a-Judgeのオフライン評価"とでも言うべき方法です。
LLM-as-a-Judge自体は、ScoreやTrue/Falseを出力させるものなので、ただの回帰や2値分類として、Grand Truthと比較することで精度を論じることができます。
Grand Truthは、評価対象を見て、評価者が評価をつけるしかありません。
大量のデータセットに対して精度を測定すれば、LLM-as-a-Judgeの精度が改善されたのかを定量的に判断することが可能です。
LLM-as-a-Judgeの精度向上のためのプロンプトは下記の記事も参考してください。
また、モデルが異なれば評価精度も異なるので、比較するという実験も行っています。
余談: LLM-as-a-Judgeのコスト問題と機械学習モデル化あるいはfine-tuning
これまで述べてきたようにLLM-as-a-JudgeではScoreやTrue/Falseを出力させます。
上記で紹介した、『LLMによるLLMの評価(LLM as a judge)の精度改善のためのプロンプトエンジニアリング』の中では、
評価精度向上の手段として、「評価理由やスコアの計算過程を出力させる」方法を紹介しています。
しかし、評価そのものに必要なのは、あくまでScoreやTrue/Falseのみです。
自由な文章を出力させる必要が必ずしもないのに、LLMのような高度なモデルを使う必要があるのか?という疑問が生じます。
結論から言ってしまえば、データさえあれば、LLMである必要はなく、機械学習モデルでも評価することは可能だと私は考えています。
究極のところ、評価は、評価対象の文章を入力して、ScoreやTrue/Falseを出すだけの回帰や二値分類に過ぎないからです。
ここでは詳細を省きますが、
評価対象の文章やインプットに使う情報を上手くベクトル化し、
評価結果のセットとともに大量に与えてあげることができれば、
(LLMではない)評価用の機械学習モデルで作成することは原理的には可能でしょう。
そして、必ずしもLLMを使う必要のないタスクでは、LLMを使わない方が、一般的には安く速くなるはずです。
LLM-as-a-Judgeにまつわる懸念として、私も一番多く伺うのがコストに関する問題です。
ここまでLLM-as-a-Judgeの重要性を持ち上げてきて、ちゃぶ台返しのようですが、
実際、LLMの出力をLLM-as-a-Judgeで、しかも複数の観点で評価するにはかなりのコストが掛かってしまいます。
特に、LLM-as-a-Judgeをオンライン評価として使う場合には、出力そのものよりも評価のほうがコストがかかるということすらあり得ます。
プロダクトによっては、コストが許容度を超えてしまい、あまり多くの観点では評価できないという事態も考えられます。
そのため、評価のデータセット作成し、機械学習モデル化あるいはfine-tuningさせるというのは十分考慮すべき選択肢だと考えています。
fine-tuningする場合は、GPT-4o-miniのようなベースのモデルもある程度の賢さが求められるとは思いますが、コストはかなり削減できるでしょう。
ですが、プロダクトの開発初期で、LLM-as-a-Judgeを使う理由は依然として十分にあると考えています。
LLM-as-a-Judgeというプラクティスが優れているのは、プロンプトを調整するだけで速くPDCAを回すことができ、それでいてある程度の精度を担保することができるからです。
言うなれば、データがなくても、ルールさえきちんと言語化できれば、人間の評価者と同じような評価をできることがLLM-as-a-Judgeの強みです。
一方で、機械学習モデル化あるいはfine-tuningしようとすると、データセットの準備やモデルのチューニングなどに時間がかかってしまいます。
これが、機械学習におけるコールドスタート問題と呼ばれる問題です。
LLMアプリケーションのように評価観点すら最初から明確にできずに、プロダクトの特性を考えながら追加したり、削ったりをしなければならないプアプリケーションの場合、
評価自体も素早くリリースできることは、LLM-as-a-Judgeのもつ圧倒的なアドバンテージです。
LLM-as-a-Judgeに共通する課題
最後にあらゆるアプリケーションでLLM-as-a-Judgeに共通であろう課題についても簡単に触れたいと思います。
ここまでに主に登場しているのは、
- 評価指標を設定し、評価基準を言語化するのが難しい
- 評価の精度も改善する必要がある
- 複数観点で評価しようとするとかなりのコストが掛かる
ということでした。
それ以外にも、レスポンス速度の問題には触れておきたいと思います。
特に処理速度が問題となるのは、出力をリアルタイムで評価をする場合です。
センシティブな内容も扱うLLMアプリケーションでは、安全性・信頼性の観点から、評価水準を上回った出力しかユーザーに返したくないというケースは考えられるでしょう。
例えば、医療系のプロダクトであれば、「睡眠薬を大量に手に入れる方法を教えて」というような質問に答えてしまっては大変です。
ですが、ユーザーが出力を待っているような、文字通りのリアルタイム性を求められるようなサービスなら、1秒から数秒以内にレスポンスを返さなければ、使い物になりません。
LLM-as-a-Judgeは、LLMを使う以上、評価自体にもそれなりの時間がかかってしまいます。
出力に数秒、評価それぞれで数秒ずつ掛かってしまえば、かなりのレイテンシーになってしまいます。
評価を並列に実行した結果を集め、すべての評価を総合して最終判断をするようにすれば、評価を一つ一つ実行するよりは時間を短縮させることができます。
出力&評価の時間を稼ぐためにいわゆるフィラーのようなテクニックを駆使するという方法もあります。
「うーん」や「ええっと」、「なるほど」みたいなやつです。
あるいは、とりあえず相手が言ったことをオウム返しすることで時間を稼ぐという方法もあるかもしれません。
「〇〇にお悩みなのですね。」「〇〇ということ、大変お辛いですね。」のようなイメージですね。
リアルタイムで評価せず、遅れて評価して後から言い直す(=訂正する)ということもプロダクトによっては可能かもしれません。
このようにきちんと評価したければ、UX上の工夫を行う必要があるでしょう。
まとめ
今回は、LLM-as-a-Judgeの基礎から運用まで徹底解説してきました。
LLM-as-a-Judgeとは何か?という基本から、評価観点の決め方やプロンプトの工夫、
実際の運用上の論点まで幅広く扱いました。
LLMアプリケーションを運用して、LLM-as-a-Judgeを活用したいという方の参考になれば嬉しいです。
直近下記のようなイベントも開催するので、ご興味のある方は是非ご参加いただければ嬉しいです。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion