LLM-as-a-Judgeとは
LLMをアプリケーションに組み込んでいると、LLMの出力を評価する必要が出てきます。
LLMの「出力は確率的である(毎回異なる)」ためです。
また、LLMの出力はハルシネーションを含む可能性がありますし、間違いではないにしてもサービス提供者の意図とは違った出力をエンドユーザーに提示してしまうかもしれません。
LLMの出力を評価して、出力が適切でないことを判定できれば、ユーザーには表示しない、出力を再度行わせる(出力をLLMに修正させるのもよいでしょう)というようなことができるようになります。
ただし、LLMのすべての出力を人が評価していたのでは、手が回りません。
そこで、注目されているのが、LLM-as-a-Judgeと呼ばれるLLMにLLMの出力を評価させる手法(以後、単に評価と呼ぶ)です。
評価にLLMを使えば、出力をすぐに評価し、評価結果をアプリケーションで活用することが可能です。
何よりLLMは疲れません。気分によって評価が変わるということもありません。
しかし、LLMの評価も確率的なゆらぎは毎回生じます。
当然、LLMにLLMを評価させる以上は、評価が本当に正しいのか?ということも問題になってきます。
LLMの評価の精度が低ければ、そもそもLLMによって評価してもあまり意味がないということになってしまいます。
評価にかかったコストが無駄になるだけならまだしも、間違った出力がエンドユーザーに提示されてしまった結果、予期せぬ事故を招いたり、サービスの評判が悪くなってしまう危険性もあります。
本記事では、PharmaX内で効果のあった評価精度向上に効果があったプロンプトエンジニアリングの工夫をご紹介します。
あくまでPharmaXでの実験によって得た結論であり、みなさんに応用可能かは試してみていただく必要がある点にはご注意ください。
下記の記事でもご紹介しましたが、PharmaXでは評価にGPT-4 Turboを使用しています。
評価に使用するモデルが異なれば、結果も異なる可能性がある点にもご注意いただければと思います。
前提・注意事項
これから評価のプロンプトを改善するためのアイディアをいくつかご紹介しますが、前提として、下図のようにプロンプトが長くなりすぎるとどうしても精度が下がってしまうことが知られています。
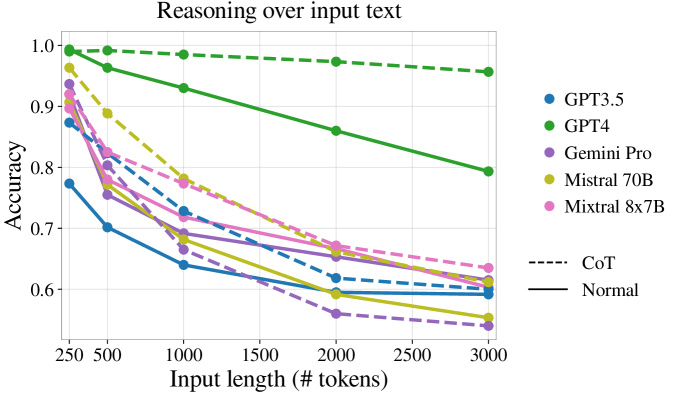
下記のアイディアの要素を詰め込み過ぎるとどうしてもプロンプトが長くなってしまうことには注意が必要です。
回答以外の情報を出力させるというテクニックもご紹介しますが、アウトプットのトークン数が多くなれば、出力速度も当然遅くなるので、その点にもご注意いただければと思います。
はっきり言ってしまえば、今回ご紹介する手法で精度向上のためにあれこれ工夫することによって、出力速度を犠牲にしてしまう可能性が高いです。
精度が重要なタスクなのか、速度が重要なタスクなのかを見極めて適用することが重要でしょう。
「要はバランス」と言ってしまってはそれまでですが、各評価の抱える課題ごとに取捨選択いただく必要はあるでしょう。
1つの評価の中に複数観点を盛り込みすぎない(評価を項目ごとに分割する)
この工夫は下記の記事でもご紹介しました。
Scoreで評価を出そうとすると、1つの評価に複数の観点を盛り込みたくなります。
加点方式なら、
- 〇〇なら10点加点
- 〇〇なら30点加点
- 〇〇なら50点加点
のようにです。(減点方式でも同じです)
しかし、これでは評価の難易度はどうしても高くなってしまいます。
数個程度の観点ならまだしも、5個も10個も評価観点を含めてしまうと、GPT-4のような賢いモデルでも間違う可能性は高くなります。
いくつかの評価観点を見逃してしまったり、計算を間違えたりします。
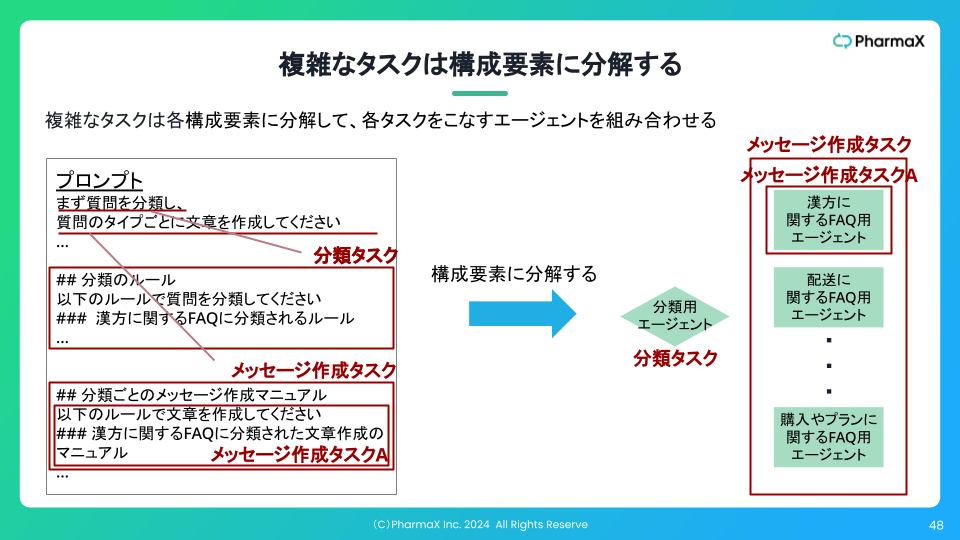
上記のスライドのようにして、評価の観点を分割し、最後に集計するような形式にすれば精度は向上します。
できる限りシンプルに、できることなら1評価1観点にするのが望ましいかと思います。
もちろん、実装コストや評価の時間的・金銭的コストは多少上昇しますが、評価に高い精度が必要な場合には有効なアイディアです。
評価基準(OKとNGの境界)を明確に言語化する
例えば、
抽象的な質問をしていないか?
というのは、あいまいな基準です。
「どういう質問が抽象的か」というのは、様々な観点が含まれるでしょう。
評価者が何をもって抽象的だと言っているのかを、より厳密に言語化すべきです。
上記の「抽象的な質問をしていないか?」という評価の場合、評価者が意図しているのは、「具体的な質問をして欲しい」ということだとします。
具体的な質問とは何か?をより突き詰めると、
オープンクエッション(YES or Noで答えられない質問)はNG、
クローズドクエッション(YES or Noで答えらる質問)はOK
ということだったとします。
つまり、
好きなフルーツは何?
という質問はNGで、
(いちごのような)甘いフルーツが好き?、それとも(グレープフルーツのような)酸っぱいフルーツが好き?
という質問はOKということです。
このように評価観点を言語化するのは簡単ではないですが、この程度まで言語化できれば、LLMも答えやすいだろうというのは想像に難くないでしょう。
逆に曖昧な指示のまま評価させても、評価結果は評価者の思い通りにはいかない確率が高いでしょう。
評価もFew-shotプロンプティングする
評価にもFew-shotプロンプティングでしっかり例を与えてあげることが重要なようです。
上記のように評価基準(OKとNGの境界)を明確に言語化することは非常に重要ですが、それだけではどうしても限界があることはあります。
例えば、ユーザーに対して「ツンデレ」キャラで返答できているのか?というのは非常に評価の難しい問題です。
同じツンデレであっても、『新世紀エヴァンゲリオン』のアスカと『涼宮ハルヒの憂鬱』のハルヒと『シュタインズ・ゲート』の紅莉栖のツンデレキャラは微妙に異なるはずです(たぶん)。
(私には上手くできる気はしませんが、)好ましいツンデレキャラとそうではないキャラの違いを明確に言語化した上で、実際に例を与えてみたほうがより正確なニュアンスの違いを判定することができるでしょう。
ちなみに私がツンデレというものを明確に理解したのは、小学生の時、TSUTAYAで借りたDVDで『新世紀エヴァンゲリオン』を観てからでした。
人もLLMも例がなければ、微妙なニュアンスを掴むことはできないのです。
そして、評価基準をクリアしている例だけではなく、できることならNGの例も与えることで精度が上がるように感じています。
また、上述した「1つの評価の中に複数観点を盛り込みすぎない」というのは、Few-shotプロンプトティングを行う上でも重要です。
1つの評価の中に複数観点を盛り込むということは、それだけ多くの組合せの例が必要になるということだということです。
1つの評価に5つの観点がある場合、各評価にOKとNGの例を与えるとすると、最低でも2×5、組合せを考えるなら2^5の例が必要ということになってしまいます。
Few-shotプロンプティングした方が評価も正確になるということからも、1つの評価の中に複数観点を盛り込みすぎないというのは重要だと考えています。
評価理由やスコアの計算過程を出力させる
CoTやReActから着想を得ていますが、評価の理由を言語化させることで評価の精度も向上しました。
評価理由だけではなく、1つの評価の複数観点が含まれ、加点方式や減点方式でスコアの計算が発生する場合は、スコアの計算過程も出力させるべきです。
JSONモードなどを使って、
{ "reason": {判断理由}, "calculation": {計算過程}, "score": {最終score} }
のように出力させればよいでしょう。
また、このアイディアは評価精度向上だけではなく、デバッグにも使えます。
評価理由やスコアの計算過程を出力させておけば、LLMがどこで間違ってしまったのかを評価者が確認することができるというデバッグの意味も持ちます。
評価精度を向上させるためには、評価のプロンプト自体も改善し続ける必要があるため、プロンプトの修正の手がかりを掴む必要があるのです。
例えば、直接的な攻撃表現をするのではなく、知的で皮肉やユーモアを交えたツンデレ表現をするキャラクターを作りたい場合、評価結果で、
「あんたってほんとバカね!こんな簡単なこともできないの?まあ仕方がないからあたしが教えてあげてもいいわ!」という表現はツンデレであり、
知的でユーモアの混ざった表現なので望ましいと言えるでしょう。
という評価理由が返ってきたとしたら、この評価用エージェントは、
表現がツンデレであることは理解できているけれども、
ユーモアに対する理解が間違っている
のだと分かるでしょう。
このように評価理由を出力させていれば、プロンプト内で「ユーモアがあるとはどういうことか?」を言語化したり、ユーモアのある表現の例を与えてあげるというネクストアクションを取ることができます。
このように評価のプロンプトもPDCAを回すための材料を集めることが重要なのです。
評価対象の文章を出力させる
最後に評価対象の文章を出力させるというテクニックをご紹介しましょう。
普通にLLMにメッセージを出力させ、そのメッセージだけを評価するなら必要はありません。
ですが、文脈を与えて、その文脈に即したメッセージを出力できているかを確かめるような場合には、効果のあるテクニックです。
例えば、会話の流れを与えて、「相手からの問いかけにきちんと答えられているか?」や「同じ質問を繰り返してしまっていないか?」ということを評価したいという状況を考えます。
このような時には、評価対象はあくまで最後の文章であることをプロンプトに指示したうえで、評価結果に評価対象の文章も出力させることが有効です。
JSONモードを使えば、
{ "evaluated_text": {評価対象の文章}, "reason": {判断理由}, "calculation": {計算過程}, "score": {最終score} }
のようなイメージです。
実際に評価対象の文章を出力させてみて、無駄な会話の流れまで含めてしまっていたり、評価対象の文章が複数行(複数段落)にも渡るにも関わらず、最後の一文のみが評価対象になっている場合には、プロンプトでより明確に指示する必要があることが分かるようになるでしょう。
まとめ
今回は、LLMによるLLMの評価、通称LLM as a judgeの精度向上のためのプロンプトエンジニアリング
をご紹介しました。
今回ご紹介したテクニックを改めて並べると
- 1つの評価の中に複数観点を盛り込みすぎない(評価を項目ごとに分割する)
- 評価基準(OKとNGの境界)を明確に言語化する
- 評価もFew-shotプロンプティングする
- 評価理由やスコアの計算過程を出力させる
- 評価対象の文章を出力させる
というものでした。
こうやって眺めてみると、当たり前のことを愚直にやろうと言っているに過ぎない気もしますが、少なくとも私たちはこれらアイディアでかなり評価精度を向上させることができました。
冒頭でも述べたように、あくまでPharmaXでの実験によって得た結論ですので、是非いろいろ試してみて取り入れていただければと思います。
今回シェアした内容が、LLMアプリケーションを運用されている皆さまに少しでもヒントになれば嬉しいです!
今後も得た知見はどんどんご紹介できればと思っています。
もしより詳しく聞きたいという方がいらっしゃれば、是非お気軽にご連絡ください。
また、PharmaXでは毎月何かしらのテックイベントを行っており、下記イベントを2024/6/19に行いますので、ご興味ある方はご参加ください!
今回はLLMアプリケーションのアーキテクチャについて色々語りたいと思います!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion