LLM-as-a-Judgeとは
LLMをアプリケーションに組み込んでいると、LLMの出力を評価する必要が出てきます。
LLMの「出力は確率的である(毎回異なる)」ためです。
また、LLMの出力はハルシネーションを含む可能性がありますし、間違いではないにしてもサービス提供者の意図とは違った出力をエンドユーザーに提示してしまうかもしれません。
LLMの出力を評価して、出力が適切でないことを判定できれば、ユーザーには表示しない、出力を再度行わせる(出力をLLMに修正させるのもよいでしょう)というようなことができるようになります。
ただし、LLMのすべての出力を人が評価していたのでは、手が回りません。
そこで、注目されているのが、LLM-as-a-Judgeと呼ばれるLLMにLLMの出力を評価させる手法(以後、単に評価と呼ぶ)です。
評価にLLMを使えば、出力をすぐに評価し、評価結果をアプリケーションで活用することが可能です。
何よりLLMは疲れません。気分によって評価が変わるということもありません。
しかし、LLMの評価も確率的なゆらぎは毎回生じます。
当然、LLMにLLMを評価させる以上は、評価が本当に正しいのか?ということも問題になってきます。
LLMの評価の精度が低ければ、そもそもLLMによって評価してもあまり意味がないということになってしまいます。
評価にかかったコストが無駄になるだけならまだしも、間違った出力がエンドユーザーに提示されてしまった結果、予期せぬ事故を招いたり、サービスの評判が悪くなってしまう危険性もあります。
今回は、評価精度を改善していくためにPharmaXで行った試行錯誤をご紹介しようと思います。
下記のような記事や資料でも、PharmaXで行っている評価の運用についてはご紹介しておりますので、ご参考にしていただければと思います。
YOJOにおけるチャット・サジェスト機能へのLLMの活用
ここでは、この後の話のイメージが付く程度の簡単な説明に留めておきたいと思います。
PharmaXが運営するYOJOは、オンラインで薬剤師に相談し、医薬品を購入できるtoC(顧客向け)サービスです。
このサービスの1機能として、薬剤師から患者へのメッセージ生成をLLMで支援する「チャット・サジェスト機能」を開発しています。
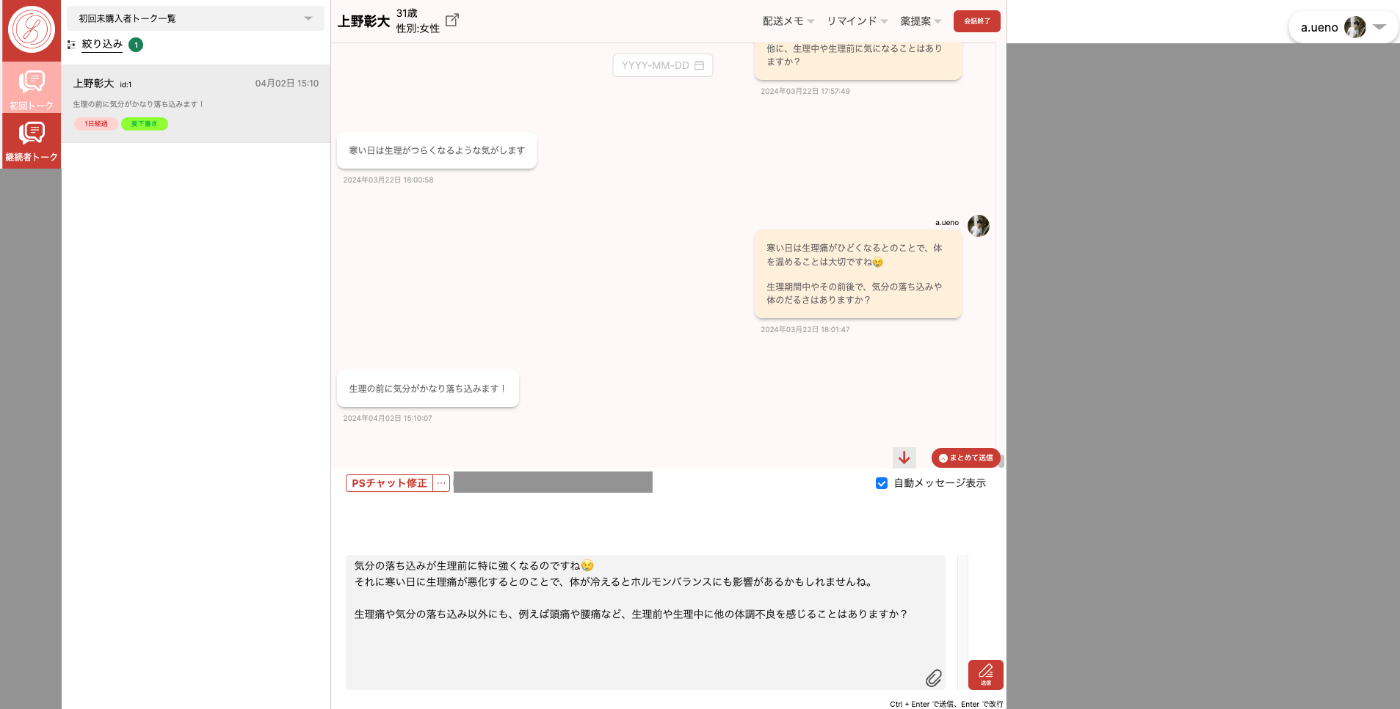
メッセージ入力欄にLLMからのサジェスト内容が表示される
このチャット・サジェスト機能のためのプロンプトは下記のようなイメージです。

このプロンプトで作成されたサジェスト内容をLLMで評価し、その評価精度を向上させようというのが今回の話題になります。
アプリケーション独自の評価基準の作り方
PharmaXでは、「チャット・サジェスト機能」によってサジェストされた内容を複数の観点で評価しています。
具体的には、①質問内容が適切か、②共感できているか、③文章作成マニュアルに従っているか、④医療的に正しい内容を伝えているか、⑤プロダクト的に正しいことを伝えているか等の観点です。
これらの評価基準は、弊社独自の評価基準であり、LLMのリーダーボードで用いられるような一般的な日本語能力を問うようなものではありません。
自社独自の評価をどう作るのかについての考察は、seyaさん下記の記事が参考になるでしょう。
PharmaXで実運用している評価用のプロンプトは下記のようなイメージです。

この添付画像のように評価はスコアを出すか、真偽値を返すかのどちらかになっています。
私たちは、JSONモードで返ってきた評価結果をアプリケーション側で処理するように実装しています。
{ "evaluated_text": {評価対象の文章}, "reason": {判断理由}, "score": {score} }
ガードレールの役割として、どのプロダクトでも守りたいような(卑猥語が含まれていないか等の)評価をするということも考えられますが、ここではあくまで自社独自の評価基準に絞って議論します。
ちなみにGuardrails Hubというライブラリにみんなが欲しいバリデーション関数が登録されているようなので、興味のある方は見てみるといいでしょう。
事前(オフライン)評価と事後(オンライン)評価
前提として評価には、事前評価と事後評価があることを認識しておいていただく必要があります。
| 評価の種類 | 説明 |
|---|---|
| 事前評価 | プロンプトを変更した際に事前に準備したデータセットに対して機能の結果出力を行い、それを評価する。「オフライン評価」と呼ばれることもある。 |
| 事後評価 | LLM機能が実際に稼働した後、その結果を評価する。「オンライン評価」と呼ばれることもある。 |
私たちも、事前評価と事後評価の両方を行って、サジェスト内容を評価しています。
オフライン評価は自分たちで実装しているので、どのようなアーキテクチャになっているかについては、弊社の諸岡@hakotenの記事をご覧ください。
事前評価は、プロンプトを変更して、本番環境に適用させる前に実行しています。
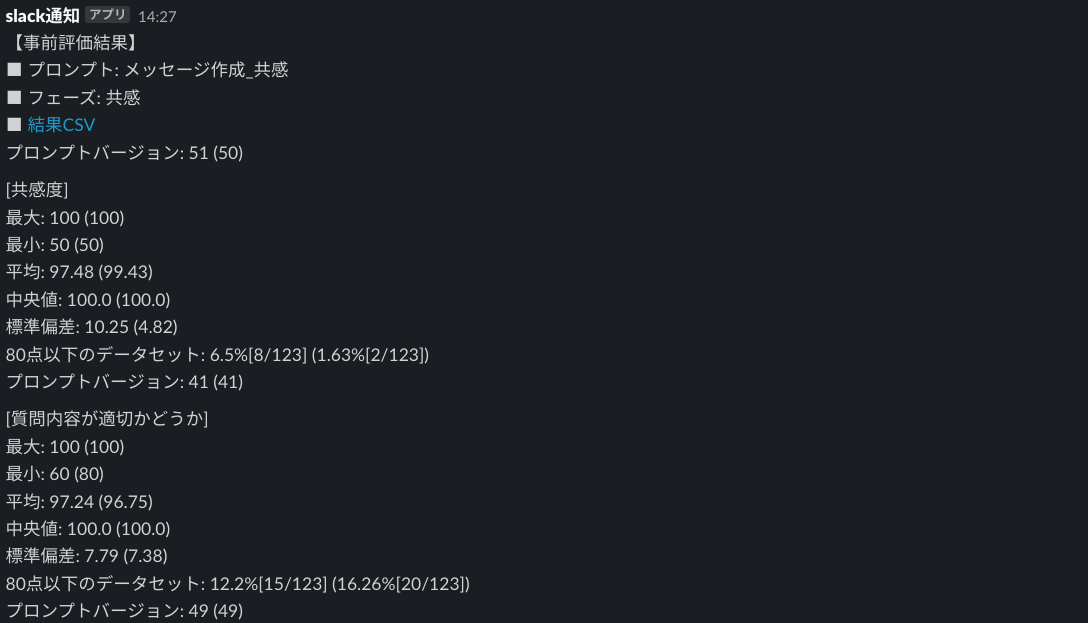
評価結果はSlackに通知が来るようになっています。一部抜粋すると添付写真のようなイメージです。
事後評価は運用しながら都度出力を評価し、下図のように評価結果を可視化しています。
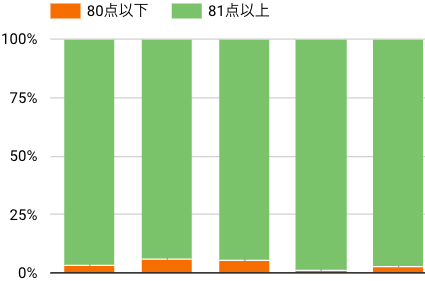
1つの評価観点で80点以上・以下の出力割合を日次で可視化した結果
実際の数字は消していますが、イメージは掴んでいただけるのではないかと思います。
LLMの出力に対する評価精度を向上させることの意義
ここで改めて、そもそもなぜそこまでして「出力を評価したいのか?」ということと、「評価精度を向上させたいのか?」ということをじっくり考えてみたいと思います。
PharmaXの例では、チャットのサジェストの精度が高ければ高いほど薬剤師さんが修正する手間を減らすことが出来ます。
もちろん患者さんにとってもチャットは速く正確に返ってきた方がいいでしょうから、サジェストの精度は非常に重要です。
そのため、チャット・サジェスト用のプロンプトを改善し続けることが重要です。
チャット・サジェストのプロンプトを変更した前後で事前評価し、評価結果を比較すれば、本番環境に投入せずともプロンプトが改善できたのかを確認することができます。
出力結果が大幅にデグレって、実アプリケーションで大事故を起こす事態を回避することがもできるでしょう。
複数のプロンプトでの出力を事前評価して比較することができれば、下記の記事でも紹介されているようにプロンプトチューニングを自動化できる可能性もあります。
(コストを無視すれば、)誰でも思いつく一番簡単なプロンプトの自動チューニングの方法は、LLMにプロンプトを何通りも作成させ、事前評価で総合点が一番高いプロンプトを一番良いプロンプトとして採用するというものがあるでしょう。
評価ができていれば、このように自動化せずに人力でプロンプトを改善するとしても、定量的に良し悪しを判断でき、プロンプト改善を高速化することが可能です。
また、チャット・サジェストのプロンプトを変更した前後で評価の変動を可視化し、比較することができば、プロンプトが改善できているかどうかを本番環境で判断することができます。
LLMをAPI経由で利用している以上、モデル提供企業が裏側で何をしているか分かりませんから、プロンプトに何も手を加えていなくとも、ある日突然意図せぬ出力が大量に生成される可能性もあります。
オンライン評価を日々可視化していれば、そんなときにも違和感にいち早く気がつくことができます。
まとめると、LLMの出力をLLMに評価させることの意義は、
- ① 本番投入前に出力用のプロンプトの変更の良し悪しを判断することができ、プロンプトの改善を高速化(あわよくば自動化)できる
- ② 本番環境でも、プロンプト変更の良し悪しや、出力の健全性を確認することができる
ということです。
ただし、これらはすべて評価の精度が高ければの話です
評価の精度が低い、つまり評価者の正しい評価(正解ラベル)とズレまくっているのであれば、全く意味がありません。
だからこそ、評価の精度を向上させることは重要なのです。
LLM-as-a-Judgeの注意点
一方、LLMによる評価が完璧ではないことも理解しておく必要があるでしょう。
本来であれば、LLMの出力が、どの程度実際のユーザーの"役に立ったのか"やビジネス指標を向上させたのか?という出力がもたらした結果も評価対象にすべきです。
ビジネスKPIと相関がある評価指標で評価させることができればいいのですが、LLMに評価可能で、ビジネスKPIと強い相関を示す評価指標はそう簡単には見つかりません。
PharmaXの例で言えば、チャットのサジェストが「医学的に正しい内容を出力しているか?」という評価をクリアしたからといって、購入率が上がるとは思えません。
医学的に正しい内容を出力できていれば、薬剤師が手直しする手間は減るでしょうし、医学的に不適切な出力がされて事故が起こる可能性は防げるかもしれませんが、それは当たり前の水準をクリアしてるというに過ぎないでしょう。
このような場合、あくまで評価できるのは、回答がどの程度妥当か(不適切ではないか)でしかないということに注意が必要です。
上述したとおり、本来的には、評価スコアが高くなればなるほど、ビジネスKPIも上がるような評価を行うことが望ましいのですが、一筋縄では行きません。
このあたりの評価指標の作り方の難しさについては、下記の本をご一読されるとイメージが付くでしょう。

また、ここまで何度も引用させていただいているseyaさんも下記記事で評価指標の作り方について考察をされています。
PharmaXでの評価の活用と課題
前置きが長くなってしまいましたが、ここからは、実際にPharmaXの抱えていた評価に関する課題とその課題を乗り越えるための試行錯誤を見てきましょう。
PharmaXでは、①一部の評価の精度が低いという課題と、②評価のコストが高いという課題がありました。
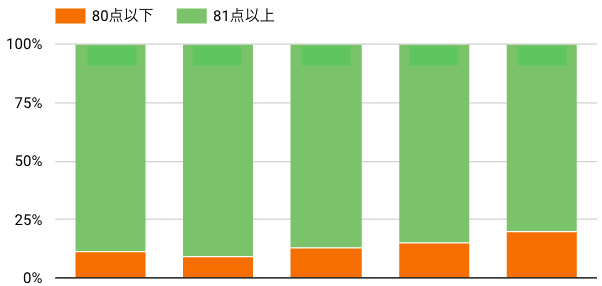
質問内容が適切かどうか?という評価観点で80点以上・以下の出力割合を日次で可視化した結果
メッセージ作成のプロンプトをどれだけ改善しても、上図のように質問内容が適切かどうか?という観点で、かなりの割合のメッセージが80点を下回ってしまっていました。
しかし、評価者が作成されたメッセージをランダムに評価したところ、本来は上図のような割合では、80点を下回っていないのではないか?という疑問が湧いてきました。
これはサジェストされるメッセージの質が実際に低いのではなく、評価の精度が悪く、不当に低く評価されているからだと判断しました。
そして、評価の精度が低い原因は、おそらく1つの評価項目内に実際には複数の評価観点を含んでいるからだと考えました。
複数の観点で評価して、最後に減点するという方式なので、かなり難しいタスクになっていそうです。
そこで、下記のスライドのように評価観点ごとに評価を分け、最後に集計する方式にすれば、精度が向上するのではないかと考えました。
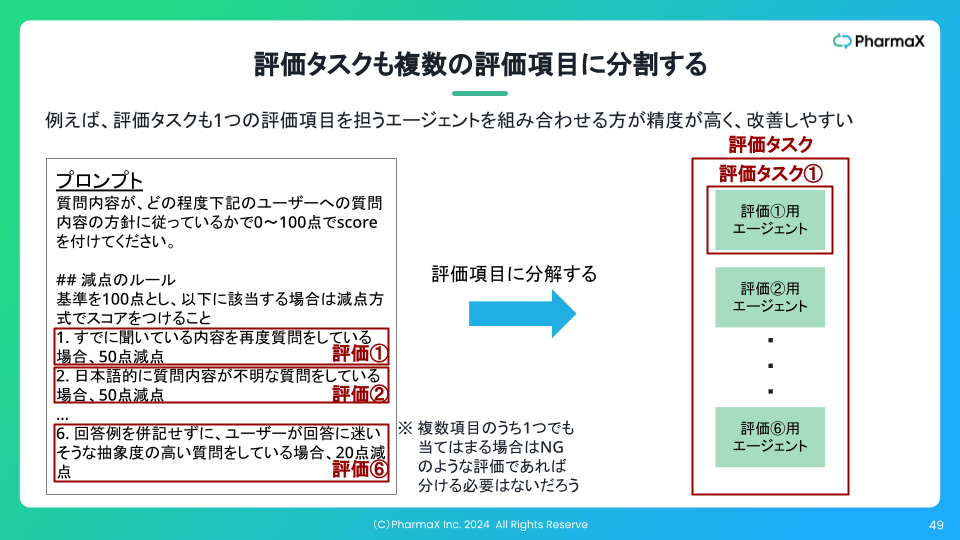
そして次に、評価には、GPT-3.5 Turboではなく、GPT-4 Turboを使わないと精度が低いため、コストが割高になってしまうという問題もありました。
上記のように評価を分割すれば、精度は上がるかもしれませんが、コストはさらに多くかかってしまいます。
ただし、この時点では、GPT-3.5 TurboとGPT-4 Turboを比較しているだけで、ClaudeやGeminiの比較を行っていませんでした。
評価を分割し、タスクの難易度を下げた上で、Claude 3 HaikuやSonnet、Gemini Pro 1.5で精度高く評価できれば、GPT-4 Turboを使うよりはかなりコストが低くなります。
そこで、
- ① 評価の精度を向上させるために1評価1観点になるように分割して評価を実行する
- ② コスト削減のためにGPT-4 Turboよりも安価なモデルでの評価精度を確認する
という2つの実験を行いました。
評価の実験
ここで実験内容の詳細まで説明しているとあまりにも長くなってしまうので、簡単な解説に留めたいと思います。
実験の概要
精度が低かった「質問内容が適切か」の評価を6項目に分け、用意した30個のデータセットに対して評価を行い、複数のモデルで精度を比較しました。
使用したモデルは、GPT-4 Turbo、GPT-4o、GPT-3.5 Turbo、Claude 3 Sonnet、Claude 3 Haiku、Gemini Pro 1.5の6モデルです。
1つの評価に対して各モデルから3回リクエストを行い、3回の多数決(True, True, FalseならTrue)で最終的な回答を算出しました。
実験1
用意した30個のデータセットに対して、6つの評価を別々に行い、正解ラベルと比較しました。
6つの評価はスコアではなく、真偽値を返すようにしています。
これまでスコアで出力していた評価を分割して真偽値にするということは、本番での実運用では、真偽値をアプリケーション側で集計して点数の計算をするという想定しているということです。

実験結果の一部抜粋。赤が間違った箇所
実験2
実験1でプロンプトがGPT-4に最適化されているからClaude 3 HaikuとSonnetのパフォーマンスを最大化できていない可能性があると考えました。
Claude 3 HaikuとSonnetのプロンプトを下記のようなイメージでXML記法に変換し、再度実験してみました。
<instructions>
判定してください。evaluated_textのうち、question_textの内容のみを判定してください。
不適切な条件に該当する場合はunsuitableをtrueとしてください。
</instructions>
<unsuitable_conditions>
文章が質問ではない(?を使用した文章ではない)場合
</unsuitable_conditions>
<example>
<conversation>
user:「冷えも気になってます。」
chat-assistant:「冷えも気になっているとのことですね。\n\n温めてくださいね。」
</conversation>
<evaluation>
evaluated_text: "冷えも気になっているとのことですね。\n\n温めてくださいね。"
question_text: "温めてくださいね。"
reason: "質問ではないので、不適切な条件に該当する"
unsuitable: true
</evaluation>
</example>
まずは、プロンプトをChatGPTを使ってXML形式に変更し、間違っているところや情報が欠けてしまっているところを人手で修正しました。
※モデル間の評価精度の比較についての注意
この後の結果に登場するモデル間の比較ですが、あくまでPharmaXでの実験結果です。
まず大前提として、PharmaXではこれまでGPT-4をメインに扱っており、私たちの書くプロンプトがGPT-4に最適化されている可能性があります。
というか、確実にされています。
特に実験1は、モデルによってプロンプトを変えて実験しているわけではないので、Claude 3シリーズにとっては決してフェアな比較ではないでしょう。
私たちは研究機関でもないですし、一般論としてどちらのモデルが優れているかを主張するつもりもないので、あくまでPharmaXが行ったPharmaXのユースケースに限定されたモデル比較の結果だと考えていただければと思います。
結果と考察
実験1では、GPT-4 Turboの精度が最も高い結果となりました。
GPT-4 Turboでは、180個のラベル(30個のデータセットに6つの評価を行った)に対して、間違いは5つでした。
GPT-4 Turbo含む各モデルでの不正解数は、下記のような結果になりました。
| モデル | GPT-4 Turbo | GPT-4o | GPT-3.5 Turbo | Claude 3 Sonnet | Claude 3 Haiku | Gemini Pro 1.5 |
|---|---|---|---|---|---|---|
| 不正解数 | 5 | 11 | 19 | 13 | 18 | 15 |
実験1の結果を受けておこなった実験2では、プロンプトをXML形式に変換しましたが、むしろ精度が低くなる結果になりました。
嬉しい結果ではなかったので、実際の数値は省略します。
結果的には、GPT-4 Turboが最も精度が高いという結果となりましたが、※モデル間の評価精度の比較についての注意 でも述べたように私たちの記述するプロンプトがGPT-4 Turboに最適化されているためにGPT-4 Turbo以外は、本来のポテンシャル以上に精度が低くなっているのだと考えています。
例えば、プロンプト内容の記述順などでも各モデルの精度が変わってしまうのだろうと推測しています。
ただし、私たちのプロンプトがGPT-4 Turboに最適化されてしまっているのは、これまでの経過を考えるとある程度仕方がないことであり、プロンプトを他のモデルに最適化するためのコストもかかってしまうため、今後もしばらくは評価にGPT-4 Turboを使っていくこととしました。
まとめ
今回は、あらためてのLLMによるLLMの評価、通称LLM as a judgeの精度向上の重要性について述べてきました。
その上で、PharmaXの抱えていた課題とそれを乗り越えるための試行錯誤をご紹介してきました。
結果的には、評価を項目ごとに分割することで精度を向上させることができました。
一方で、モデル間の比較では、私たちのプロンプトでは、GPT-4 Turboの精度が最も高かったため、GPT-4 Turboを使い続けようという結論となりました。
コストダウンさせることはできませんでした、むしろ、評価項目が増えてしまい、トータルのトークン数も増え、コストは上がってしまう結果となりました。
これまできちんとモデル間の比較を行ったことはなかったため、知見を溜めることはできました。
今回シェアしたPharmaXの課題感などが、LLMアプリケーションを運用されている皆さまの参考になれば嬉しいです!!
もしより詳しく聞きたいという方がいらっしゃれば、是非お気軽にご連絡ください。
また、PharmaXでは毎月何かしらのテックイベントを行っており、下記イベントを2024/6/19に行いますので、ご興味ある方はご参加ください!
LLMアプリケーションのアーキテクチャについて色々語りたいと思います!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion