こんにちは。PharmaX共同創業者の上野(@ueeeeniki)です!
過去の記事で、PharmaXで行っているLLMアプリケーションの実験管理のプラクティスについてご紹介しました。
今回は実験管理とセットで語られることの多い評価(LLM as a judge)の運用プラクティスをご紹介します。
LLMアプリケーションを実運用している企業の評価に関するノウハウはあまり公開されていないと感じています。
PharmaXでは、実験管理にPromptLayerというSaaSを利用しており、出力結果に紐づけてスコアも記録しています。
実験管理やPromptLayerの使い方に関しては上記の記事をご覧ください。
ここでは、LLMアプリケーションの出力をどのように評価しているか?や、どのような評価上の工夫を行っているか?にフォーカスしてお伝えしたいと思います。
LLMアプリケーションを運用している方の参考になれば嬉しいです!
是非、FBもいただけると嬉しいです!!
評価とはなにか?
AIの評価とは、AIの出力結果の”良し悪し”を定量的・定性的に判断することです。
特に、この記事では定量的に判断する(つまり、スコアをつける)ことを主に指します。
評価の種類と概要
LLMの評価というときに、
- ①事前学習したLLMのモデルそのものの評価
- ②特定の分野に特化してfine-tuningしたモデルの評価
- ③LLMを使ったアプリケーションでの評価
- プロンプトチューニングやRAG(やfine-tuning)の精度にフォーカス
のどれを指しているのかに注意が必要です。
①は、GPT-4、Gemini Pro、Claude 3 (Opus)のどれが優れているのか?というモデル間の比較です。
下記のようなリーダーボードで評価結果が公開されています。
リーダーボードによって、どのような観点(日本語能力に特化した観点等)で評価しているのかが異なりますが、基本的には一般的な言語能力や問題への回答能力を評価します。
②は、例えば、医療分野に特化してfine-tuningされたモデルが、特化していないGPT-4やGemini Pro等と比べて医療系の問いに答えられるようになったか?といった観点での評価です。
特定の分野に特化してモデルを強化する研究というのは、下記の記事のように盛んに行われています。
こちらも、特定の分野に特化させてはいるものの、その分野では一般的な問題(例えば、医師国家試験など)の回答を評価します。
③は、より特定のケースで正しく生成が行われるかを評価します。
PharmaXのようにモデルそのものを作るのではなく、LLMを活用して自社サービスを強化するような場合は、この③の観点で評価を行います。
ここでは、LLMを活用したいユースケースにとって良い出力であるかが問われます。
自社のアプリケーションの特定のユースケースに特化させた出力をLLMにさせるためには、プロンプトチューニングを行ったり、RAG(やfine-tuning)で精度を高めたりするかと思います。
それらの工夫によって、対象のユースケースに役立つ出力が実際になされているのか?を評価する必要があるでしょう。
この記事では主にこの③のユースケースに特化した評価を扱います
LLMアプリケーションの評価特有の論点について
AIの評価の中でも、LLMアプリケーションの評価は、画像認識などの分類問題などとは異なり、正解が1つに定まらないため、難しいとされています。
例えば、日本で一番高い山は?」という質問に「富士山」「富士山です」「富士山に決まってんだろーが!」「富士山。標高3776.12 m。その優美な風貌は…(略)」と答えるのはどれも正解です。
これらの出力に対して、複数の軸で評価する必要があります。
上記の富士山の例であれば、
- ①問題に正解しているか
- ②簡潔であるか
- ③ユーザーに出力するのに適した言葉遣いか
といった観点で評価することが考えられるでしょう。
このような観点は、自社のアプリケーションの特性を考えて、自社なりの評価軸を定義する必要があります。
アプリケーションによっては、簡潔ではない表現の方が望ましいかもしれませんし、より失礼な言い回しの方が良い(ツンデレキャラを作っているようなケースを想像してください 笑)かもしれません。
もしかしたら、正解を答えるのではなく、嘘や冗談を言って欲しいアプリケーションなのかもしれません。
よく考えれば、上記のような観点で実際に評価することが、実はかなり難しいことに気がつくでしょう。
①は、富士山という正解の文字列を含んでいるか?というルールベースでも評価できそうですが、
②や③のような観点で評価するにはルールベースだけでは限界があり、文章の意味やニュアンスを汲み取る必要があります。
このため、「LLMの出力をLLMを使って評価する」 という手法がよく使われます。
「LLMの出力をLLMを使って評価する」というのはどういうことだと疑問に感じる方もいらっしゃるでしょうが、後ほど詳しく解説します。
まとめると、LLMアプリケーションの評価特有の論点は、
- 評価観点を自分たちで定義しなければならない点
- 評価によっては、ルールベースだけでは評価できないため、LLMによってLLMを評価させる必要がある点
などが挙げられるということです。
この記事では、これらの問題にPharmaXがどのようにアプローチしているのかを解説することが狙いです。
今回例に取り上げるLLMアプリケーションの概要
早速PharmaXで実際に運用している評価のプラクティスを紹介したいのですが、この後の評価の議論をよりイメージしやすくなるように、今回評価の対象とするアプリケーションを簡単にご説明します。
PharmaXのYOJOというサービスは、オンラインで薬剤師に相談をして医薬品を購入できるというtoCサービスです。
PharmaX内には、ユーザーである患者さんからの質問にチャットで答える薬剤師が多数在籍しています。
PharmaXは薬局にシステムを販売するのではなく、直接患者さんに医薬品を販売するオンライン薬局であり、薬剤師の方々はあくまでPharmaXに所属する薬剤師です。
今回例として取り上げるLLM機能は、薬剤師がチャットするメッセージ内容をサジェストします。
エンジニアにとってのcopilotのような役割だと思っていただければよいでしょう。
下記が薬剤師メンバーが使うチャット画面です。
(ローカル環境での私との会話画面なのでセンシティブな情報は含みませんが、画面の一部をマスクしていることをご了承ください。)
「PSチャット提案」というボタンを押す(もしくはショートカットキーをタイプする)と、メッセージ入力欄にメッセージがサジェストされます。
サジェストされた内容を薬剤師が修正して送信します。
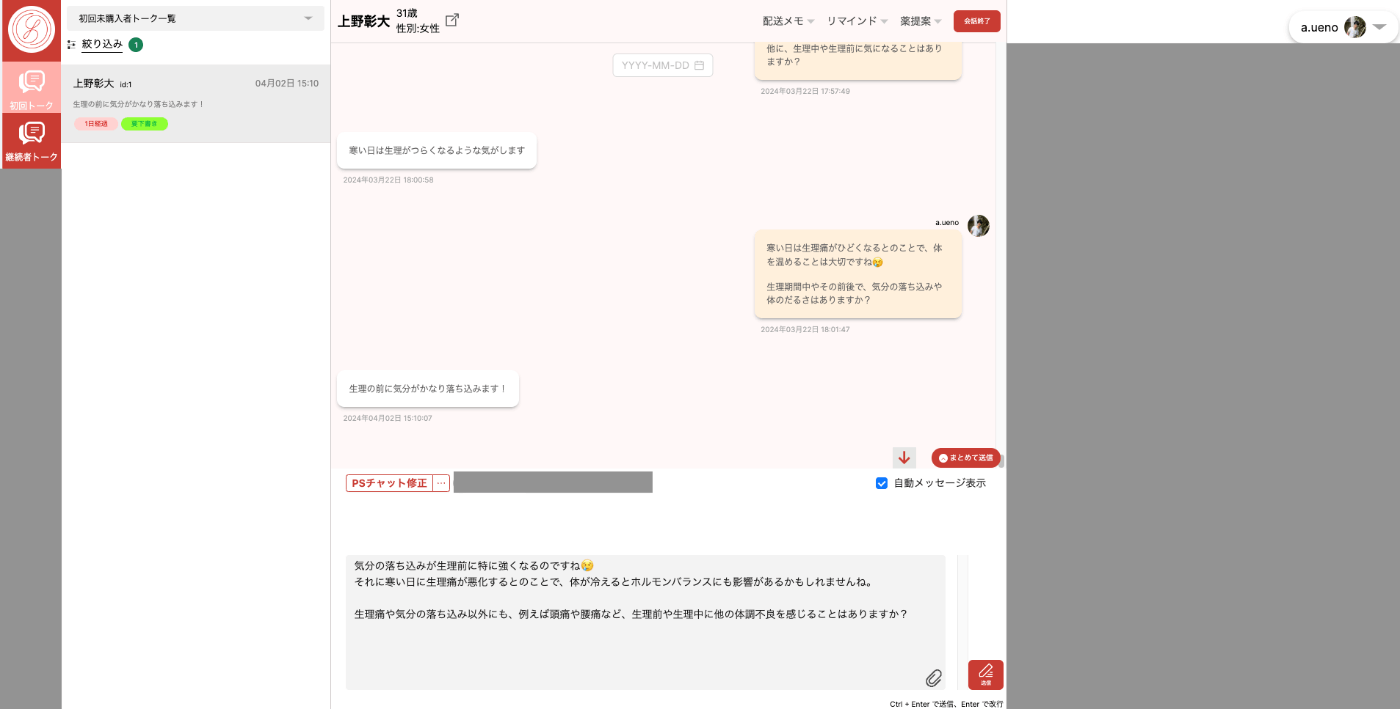
薬剤師が患者さんの状態を確認しつつ、チャットするための管理画面
PharmaXは、単純な質問にはLLMで回答を作成し、薬剤師の仕事をより深く患者さんと信頼関係を構築することにシフトさせようとしているのです。
医療において、客観的な医学的知識を与えることは、いずれAIが完璧にこなせるようになるでしょう。
AIが発展した世界において、医療者がすべきことは、患者さんと信頼関係を構築することによって、健康を支えるパートナーになることです。
このようにPharmaXの事業の根幹を成す、LLMによるメッセージのサジェスト機能を複数の観点で評価しようというのが今回の題材になります。
評価のモチベーション
このタイミングで改めて、なぜこのLLMによるメッセージのサジェスト機能を評価したいのか?を考えてみましょう。
まず第一に、プロンプトやパラメータの改善を正しく行うためには、プロンプトを変更してからしばらく運用してみて、出力結果が良くなったのか悪くなったのかを判断する必要があります。
上記でご紹介したLLM機能を実現するために与えているプロンプトは下記のようなイメージです。

プロンプトのイメージ(実際に運用しているプロンプトとはかなり異なることにご注意ください)
より良い出力を得るためにプロンプトを変更するわけですが、出力結果をいくつかの観点で評価し、プロンプトの変更前後で比較しなければ、本当によくなったのかどうかは分かりません。
そして、YOJOのように膨大な数のチャットをサジェストする必要があるサービスでは、出力結果を人力で評価するのには限界があるため、評価を自動化する必要もあります。
そしてさらに、評価が出来ていれば、評価の結果をトリガーとして、機能のネクストステップを起動させることも可能になります。
今回の機能の例で言えば、評価が特定の値を下回った場合は、メッセージのサジェスト結果を修正して再度LLMにメッセージを作り直させるというような機能の発展が考えられます。
もちろん、この場合、メッセージが2回作られることになるので、余分に時間はかかってしまいますが、より正確なサジェストが行われるので、薬剤師が修正する手間は省けるということになります。
LLMアプリケーションを評価する観点
ここで一つ、ご注意いただきたいことがあります。
本来、特定のユースケースに特化したLLMアプリケーションにおいて最終的に評価するべきは、実際にどの程度ユーザーに”役立ったか”やどの程度ビジネス上の数値を向上させたのかです。
一方で、KGIとなるビジネス指標への影響は様々な要因が混ざり合う上に、評価できるまでの時間軸も長くなるので、現実的にはその手前の評価軸でも評価する必要があります。
例えば、サジェストされた結果がマニュアルなどに沿っているかや、医学的に間違っていないかといった実際のユースケースに照らし合わせた妥当性の観点で評価しています。
また、実際にこの機能が、薬剤師の生産性を高めているかを評価するためには、受入率(どの程度修正せずに受け入れられたか)なども測定する必要があるでしょう。
つまり、LLMアプリケーションが、この評価観点をクリアしていれば(高得点を出していれば)、確実にビジネス上の指標も向上させられるだろうと言える観点で評価する必要があるということです。
PharmaXで採用している評価手法の紹介
前提の説明がかなり長くなってしまいましたが、いよいよPharmaXでのリアルな評価の運用をご紹介しましょう。
評価のタイミングと使用するデータ
LLMアプリケーションを評価するタイミングと評価に使うデータには主に下記の2パターンがあります。
- ①【リリース前の評価】プロンプトを変更した際に事前に準備したデータセットに対して出力を行い評価する
- ②【リリース後の評価】プロンプトの変更後、LLMアプリケーションを実際に活用する場面での出力結果に対して都度評価する
このどちらのパターンも、プロンプトの変更の良し悪しを正しく評価するためには、大量の出力結果を評価して比較する必要があります。
そのため、すべての出力結果を手動で評価するのには限界があるため、後述するような方法で自動で評価する必要があります。
結論から言ってしまえば、PharmaXが行っているのは②のパターンで、①のパターンには手が回っていません。
リリース前のデータセットを用いた評価について
①は、プロンプトやパラメータを変更したタイミングで、評価用のデータセットに対して出力を行って評価します。
YOJOのメッセージサジェスト機能の例で言えば、患者さんと薬剤師の会話の流れ(この場合は会話の流れがデータセットということ)をあらかじめ大量に用意し、最後の患者さんからのメッセージに対しての返信をサジェストさせます。
例えば、1000件の会話パターンが用意できれば、その1000件に対して出力した結果を評価し、プロンプトの変更前後で評価が高まったのかどうかを判断します。
このパターンの利点は、機能を本番環境にリリースする前に評価することで、LLM機能の大幅なデグレを防げる点です。
ミッションクリティカルな機能であれば、このようなリリース前の評価が必須でしょう。
デメリットは、
- ユースケースごとに大量のデータセットを準備しなければならないこと
- プロンプトの変更の度に評価をしていてはコストが掛かりすぎること
- 本番環境で実際のユーザーに対して行う出力の評価とは必ずしも一致しないこと
などが挙げられるでしょう。
特に最後の点は、事前の評価には限界あるという本質的な問題です。実際にリリースして見た結果と、事前の評価とが、大幅にズレてしまうことはあり得ます。
リリース後の都度評価について
先述の通り、PharmaXでは、このリリース前の評価を整えるというところまでは出来ておらず、主にリリース後、出力の度に評価を行っています。
これは、実験管理について説明した下記の記事でもご紹介している通り、本番環境でプロンプトの実験・改善ができる環境を整えており、新しいプロンプトのリリース前に一定の評価を行うことができるからです。
(詳しい運用については下記の記事をご覧ください。)
リリース後の評価は、本番環境での実際のサジェストについて、出力の都度評価を行います。
しばらく実際の現場で運用してみて、運用期間を通じて評価結果を蓄積します。
統計的な処理に深入りするようなことはしませんが、プロンプトやパラメータの変更前後の期間で評価の平均点などを比べれば、変更したことが良かったのか、悪かったのか判断ができるでしょう。
LLMを用いた出力の妥当性の評価
それでは早速、どのような評価を行っているのかを説明していきたいと思います。
まずは、LLMを用いた回答の妥当性の評価についてです。
対象としているYOJOのLLM機能の例では、「医療的に間違っている内容を伝えていないか」や「文章作成マニュアルに従っているか」、「プロダクト的に正しいことを伝えているか」などの観点で評価しています。
(※PharmaXでは、2024年4月現在では合計7つの観点で評価を行っています。)
評価するタイミングはサジェストが作成された時です。
私たちのサービスのマニュアルに従っていればいるほど、当然薬剤師は文章を変更せずにそのまま送ることができます。妥当性が高ければ高いほど、薬剤師は楽をできるようになり、患者さんへの返答も早くなるため、妥当性を評価してるということです。
定量的に評価を行いたい(つまり、スコアをつけたい)ので、下記のようなプロンプトを与えて、点数を返させるようにしています。

プロンプトのイメージ(現在実際に運用しているプロンプトとはかなり異なることにご注意ください)
運用上は正しくフォーマットで返して欲しいので、GPTのJSONモードを使っています。
また、モデルとしては、GPT-3.5Turboを使っています。
これは、評価までGPT-4系を使うとさすがにコストが高すぎるためです。
テキスト間の距離を用いた受入れ率の評価
妥当性の評価だけではなく、サジェストしたテキストと実際に薬剤師が送ったテキストの距離を測って、どの程度サジェスト内容が薬剤師に受け入れられたのか(受入れ率)を測定します。
受入れ率が高ければ高いほど、薬剤師はサジェストされた文章を変更せずに送ることができたとうことなので、受入れ率が生産性に直結する指標なのはお分かりいただけるでしょう。
受入れ率は、Embedding distanceとLevenshtein distanceという距離で測定しています。
Embedding distanceは2つのテキストの意味的な距離を測ります。
Levenshtein distanceは2つのテキストの編集距離を測ります。つまり、片方のAというテキストをどの程度編集されたらBになるのか到達するのかという指標です。
これら2つの指標は距離なので、値が小さければ小さいほど、サジェストされた文章を薬剤師が変更せずにそのまま送ったということになります。
先ほどの妥当性の評価は、サジェストが生成されたタイミングで評価しましたが、受入れ率は、実際に薬剤師がメッセージを患者さんに送信したタイミングで評価しています。
PharmaXにおける評価の課題と今後の展望
最後にPharmaXにおける評価の課題と今後の展望についてご説明して、この記事を締めたいと思います。
現在の課題は大きく分けて以下の3つです。
- ①評価用のデータセットを使ったリリース前の評価を行いたい
- ②プロンプトの運用期間を通しての評価の可視化・分析を行いたい
- ③評価が意図した通りのスコアを出しているのか(直感に則した結果になっているか)を評価し、評価用のプロンプトそのものも改善する
①は、すでにお話したのでご理解いただけているでしょう。
②は、評価のスコアを定期的にBigQueryにインポートして分析、可視化することを想定しています。
プロンプトのバージョンごとにスコアのグラフが可視化されたダッシュボートのようなものをイメージいただければよいでしょう。
このようにきちんと可視化されていれば、プロンプトごとの評価結果を比較することが可能になります。
③は、評価もLLMで行っている以上、評価のプロンプトもPDCAを回し続ける必要があるということです。
評価結果が、本来評価したい通りの結果になっているのかを監査し続ける必要があります。
何を言ってるのか分かりにくいかもしれませんが、
たとえば、スコアが100点がついているサジェスト結果と80点がついているサジェスト結果があるとしたときに、メンバーの感覚では80点がついているサジェストの方が良いとしたら、おそらくその評価用のプロンプトがどこかおかしいのでしょう。
つまり、評価をLLMで行っている以上、評価用のプロンプトもプロンプトエンジニアリングとは切り離せないということです。
その観点でも、②の可視化は重要です。
評価が可視化されてダッシュボード化されていれば、実際にLLM機能を開発したり、使用しているメンバーが誰でも簡単に評価の変遷を見ることができます。
実際に使用しているメンバーの肌感覚と、評価結果がズレているかどうかのFBを集めやすくもなるでしょう。
まとめ
今回はPharmaXで行っている評価の運用について解説しました。
私の体感でも、LLMアプリケーションを本番運用している企業は増えてきましたが、実験管理・評価周りの知見はまだかなり少ない印象です。
評価に限って言っても、モデルそのものの評価についてのまとめた記事などはあるのですが、LLMアプリケーションを実運用している企業の評価ノウハウはあまり公開されていないと感じています。
今回シェアしたPharmaXで行っているリアルな運用のノウハウと、課題感などが、LLMアプリケーションを運用されている皆さまの参考になれば嬉しいです!!
もしより詳しく聞きたいという方がいらっしゃれば、是非お気軽にご連絡ください。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion