これまでPharmaXでは、LLMの実験管理・評価ツールにPromptLayerを使ってきました。
下記の記事でも運用についてシェアしてきました。
ですが、現在LangSmithへの移行を行っている(2024/7現在では完全移行は完了していない)ので、なぜ移行する意思決定をしたのかの理由を語りたいと思います。
LangSmithとは
LangSmithを全くご存じない方もいらっしゃるかもしれませんので、簡単に概要を述べます。
LangChainの開発元であるLangChain社が開発しているLLMアプリケーションのライフサイクル管理ツールです。
日本でよく知られている言葉を使えば、実験管理、評価用のツールだと思ってしまって間違いではないですが、それ以外の機能も持っているので、ライフサイクル管理ツールだということです。
LLMに特化しているということにはなっていますが、他の機械学習アプリケーションでも使えます。
LangSmithの開発速度はかなり速く、爆速でいろいろな機能が追加されています。
LangChain社にとってのマネタイズポイントなので、今後もかなり力を入れて開発されるだろうと予想しています。
今回例に取り上げるLLMアプリケーションの概要
早速LangSmithの良さをご紹介したいのですが、運用がよりイメージしやすくなるように、実験管理・評価の対象となるアプリケーションを簡単にご説明します。
PharmaXのYOJOというサービスは、オンラインで薬剤師に相談をして医薬品を購入できるというtoCサービスです。
PharmaX内には、ユーザーである患者さんからの質問にチャットで答える薬剤師が多数在籍しています。
PharmaXは薬局にシステムを販売するのではなく、直接患者さんに医薬品を販売するオンライン薬局であり、薬剤師の方々はあくまでPharmaXに所属する薬剤師です。
今回例として取り上げるLLM機能は、薬剤師がチャットするメッセージ内容をサジェストします。
エンジニアにとってのcopilotのような役割だと思っていただければよいでしょう。
下記が薬剤師メンバーが使うチャット画面です。
(ローカル環境での私自身との会話画面なのでセンシティブな情報は含みませんが、画面の一部をマスクしていることをご了承ください。)
患者さん(ユーザー)からメッセージを受信したタイミングでLLMによる返信のサジェストが作られます。
サジェストされた内容を薬剤師が確認し、必要があれば修正して送信します。
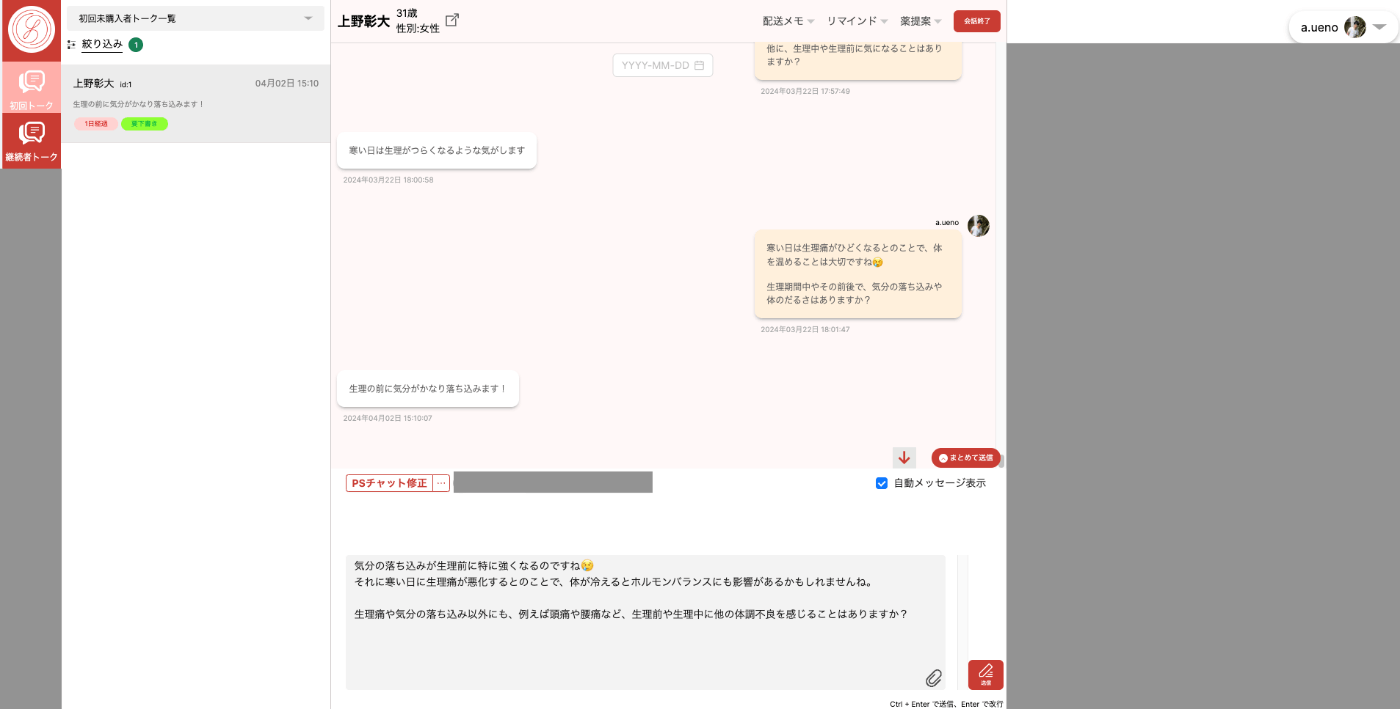
薬剤師が患者さんの状態を確認しつつ、チャットするための管理画面
前置きが長くなりましたが、早速LangSmithの長所を語っていきたいと思います!
LangSmithの長所
処理の記録(Run)を構造化できる
LangSmithの特徴の1つに処理の記録(Runと呼ばれる単位)を構造化できるというものがあります。
YOJOのメッセージ提案機能は、メッセージが提案されるまでにエージェントが複数動きます。
最近の言葉ではフローエンジニアリングと言ったりもするそうです。
具体的に言えば、
- LLM処理をすべきかをルールベースで判定
- LLMで会話を分類
- LLMで次のフェーズに移るべきかどうかを判定
- LLMでメッセージを作成
- LLMで作成されたメッセージを評価(LLM as a Judge)
という順番で動きます。
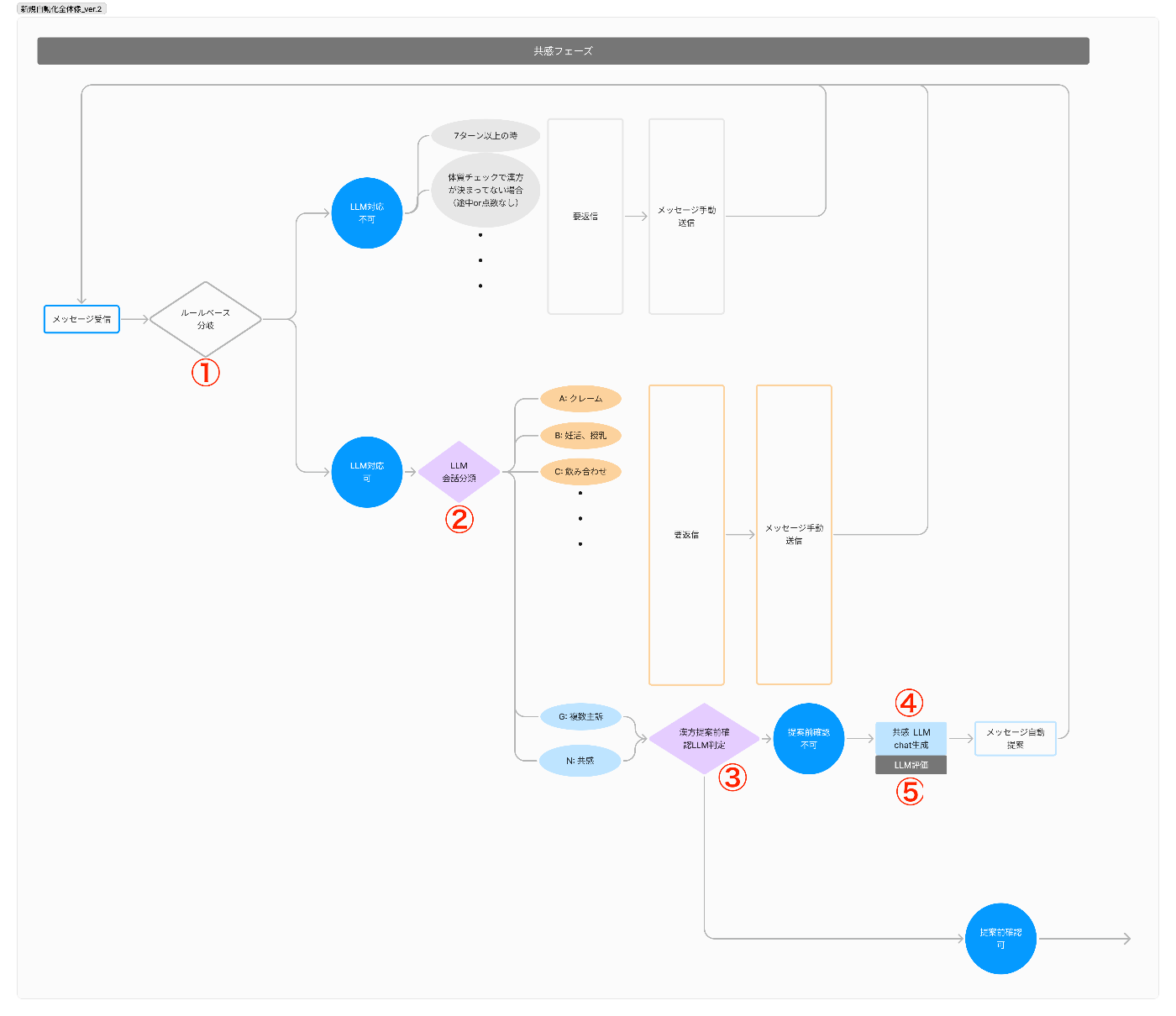
メッセージが作成されるまでの一連の処理イメージ
例えば、会話分類でLLMが提案するのではなく、はじめから薬剤師が提案した方がいいと判断された場合には、そこで処理が止まり、後続のLLM処理は行われません。
PromptLayerでは、これら一連の処理を確認するためには、各処理ごとにmetadata検索する必要がありました。
しかし、LangSmithでは、複数のRunをまとめて構造化する(まとめたものはtraceと呼ばれる)機能がついており、一連の処理の流れを人目で見ることができます。
下図の例では、2番目の処理である会話分類でLLM処理の流れが止まってしまったケースです。
このように処理がどこまで行って止まったのかが一目瞭然です。

複数のRunがまとまったTrace
Thread機能を使って複数Traceをまとめることもできる
YOJOのようなチャットサービスでは、一連の処理が終わってメッセージが送信され、また患者さんからのメッセージを受け取れば、次の処理が開始します。
LangSmithの言葉を使えば、Traceが記録されたのちに、またすぐに次のTraceが記録されます。
LangSmithのThreads機能を使えば、同じthread_idを付与したTraceを下図のようにまとめて見ることができるようになります。
つまり、同じユーザーに対する複数のTraceをまとめて見たいときに、user_idなどで検索する必要がないということです。

公式ドキュメントから引用。説明を追加
Open traceを押せば、各処理のTraceの詳細を確認することもできます。
特にYOJOのようなチャットサービスでは、1つ1つのTraceの結果や詳細も重要ですが、処理群の前後関係なども重要です。
利用者の状況をよく想像できている素晴らしい機能だと思います。
データセットの管理がしやすく、データセットに対する評価の実行も簡単
LangSmithにはデータセットを管理し、事前評価を簡単に行える機能もあります。

公式ドキュメントから引用。データセットの一覧画面
LangSmithに移行するまでYOJOでは、データセットの管理と事前評価を下記記事のように自作していました。
事前評価のオペレーションの流れは、
- データセットの作成
- 評価の実行
- 評価結果の可視化や通知
となります。
PharmaXでは、下記記事で取り上げられている方法で事前評価をパイプラインを自作していました。
そして、自作したパイプラインでの評価結果を添付画像のようにSlackに通知していました。

実はこのオペレーションの中で一番大変なのが、1のデータセットの作成です。
LangSmithの良さは、本番でのRunから質の高い入出力をデータセットに追加することができる点です。
必要があれば修正することもできます。

公式ドキュメントから引用
データセットの作成は非常に大変なので、多くの企業がデータセットの作成で心が折れてしまうでしょう。
後述するAnnotation Queuesという機能を使えば、Queueに入ってきたRunをチェックした上でデータセットに追加することまで簡単に行えます。
さらに、評価の実行も①GUI上で設定して行うことも、②コード上で行うこともできます。
GUI上でデータセットに対して評価を設定する画面を引用します。

公式ドキュメントから引用。GUI上でデータセットに対する評価を設定する画面
このように評価の実行も非常に簡単です。
3の評価の可視化もLagnSmith上でやってはくれますが、どのように可視化したいかは企業の方針次第なので、LangSmithのデフォルトの可視化だけで満足できるかは微妙なところです。
さすがのLangSmithも可視化方法を自由自在に変えられるということまではないので、自社のニーズに合わせて実装する必要はあるかもしれません。
何にしてもトータルとしては、データセットに対する評価の実行が非常に簡単になるこれもまた素晴らしい機能と言えるでしょう。
また、データセットをexportしてfine-tunningや自社でモデルの作成に活かすこともできるので、非常に
Annotation Queuesを使って、本番のデータにAnnotationすることができる
YOJOではLLMのメッセージ提案の出力を評価しています。
本番でのLLMの出力を評価することをオンライン評価(事後評価)と呼びます。
評価の運用の詳細は下記の記事をご覧いただくとして、LLMでLLMの出力を評価を行うプラクティスはLLM as a Judgeと呼ばれています。
ここで一つ問題となるのが、評価そのものもLLMで行っている以上、その出力も本当に正しいのかどうかを判定する必要もあることです。
本番環境での評価の精度を確認するためにはどうすればいいでしょうか?
また、LLMが行っている処理の中でも自動で評価できていないものもあります。
例えば、YOJOでは、会話分類は、分類が正解しているかを自動で確認することはできていません。
この問題を解決するのがAnnotation Queuesという機能です。
機械学習の世界で、Annotation(アノテーション)と言えば、基本的には人手で正解ラベルやメタデータ、評価などをつけること指します。
Annotation Queuesは、一言で言えば、LangSmithに記録されているRunをQueueに飛ばし、どんどんアノテーションして行くことができるという機能です。

公式ドキュメントから引用
添付の画像のようにLLMの出力結果を評価することができます。
もちろん、"本当はこういう出力であるべきだった"という内容に出力を修正することも可能です。
Queueに溜まっていくという機能があることで、確認したい処理のRunを一つ一つ検索するのではなく、Queueの中で順次確認することができます。
アノテーション役の人がいれば、ただただQueueに飛んできたRunを見てアノテーションをこなすことができて、非常に便利です。
さらに、ルールを設定すれば、自動的にQueueに入れることもできます。
詳細は下記の公式ドキュメントを参考にしてください。

この画像のようなイメージでルールを追加すれば、そのルールに従ってQueueに勝手に追加してくれます。
また、このAnnotation Queuesの素晴らしい点は、Runをデータセットにも追加できるという点です。
Annotation Queuesに入れられたRunのうち、いいと思ったものをどんどんデータセットに追加していくことができます。
仮にLLMの出力が間違っていれば、人の手で直してあげることで、理想の入出力をデータセットに追加できるということです。
この機能があれば、データセットを自分で0から作る必要はありません。
本番での入出力を使っているので、本番に近いデータセットを作ることができます。
まとめると、本番環境でAnnotation Queuesすることの意味は大きく分けて2つです。
- 本番でのLLMの出力にアノテーションすることで、出力精度を確認することができる
- アノテーションした本番データからデータセットを作ることができる
つまり、本番でのLLM処理の正しさを監視しつつ、同時にデータセットを作ることができるということなのです。
このような運用がデフォルトの機能でスムーズにできるのがAnnotation Queuesの素晴らしさです。
LangChain&LangGraphとの相性がいい
これはそのように作られているので当たり前なのですが、LangChainとの相性がいい点も最後にあげたいと思います。
YOJOでは、最近LangChainとLangGraphの使用を開始しました。
逆に言えば、LangSmithへの記録が便利だから、LangChainを使い始めたと言っても過言ではありません。
LangChainのver0.1まではversionごとの互換性に不安があったので、本番環境で使うことには及び腰でしたが、ver0.2からはある程度安定してきたと判断していたという背景もあります。
(これが当初PromptLayerを使い始めた理由でもあります。)
LangChainを使用していれば、環境変数の設定さえしてしまえば、勝手にLangSmithへの記録を行ってくれます。
一方、PromptLayerを使用していた時には、当然ですが、PromptLayerへの記録処理は単独で書く必要がありました。
特に、LangGraphは一連のLLMの処理をグラフ構造として記述することができるので、フローエンジニアリングを行う上では非常に便利です。
LangGraphの使い方については下記の弊社諸岡(@hakoten)の記事をご覧いただければと思います。
今回は詳細は省略しますが、LangGraphでグラフ構造を記述して実行すれば、その構造通りに勝手にLangSmithに記録されます。
つまり、処理の記録(Run)を構造化できるでお伝えしたRunの構造化が勝手に行われるということです。
これも非常に便利なので、LangSmithを使いたければ、是非LangChain、LangGraphの使用の検討してみてはいかがでしょうか。
ただし、LangChainをつかわずとも、LangSmithへの記録を単独で行うことは可能です
PromptLayer同様、RESTで投げてあげれば問題なく記録することができます。
LangSmithの短所
ここまではいいところばかり述べてきましたが、逆にLangSmithの欠点についてもお伝えしたいと思います。
プロンプト・テンプレート管理機能が弱い
簡単に言ってしまえば、Langsmithはプロンプト・テンプレートの管理のための機能はかなり弱い印象です。
PromptLayerはプロンプト・テンプレート中心の設計だったので、プロンプト・テンプレートの管理機能は非常に豊富でした。
具体的には下記のような細かいところに手が届かないというイメージです。
プロンプト・テンプレートをワークスペースを超えてコピーできない
LangSmithには、ワークスペースという概念があります。
我々の場合、当初、prod&stg用のワークスペースとlocal用のワークスペースを分ける運用をしていました。
API Keyがワークスペースごとに分かれているので、LocalのRunが本番に絶対に混ざり込まないようにするためです。
LangSmithでは、下図のようにPromptsはワークスペースごとに集約されます。
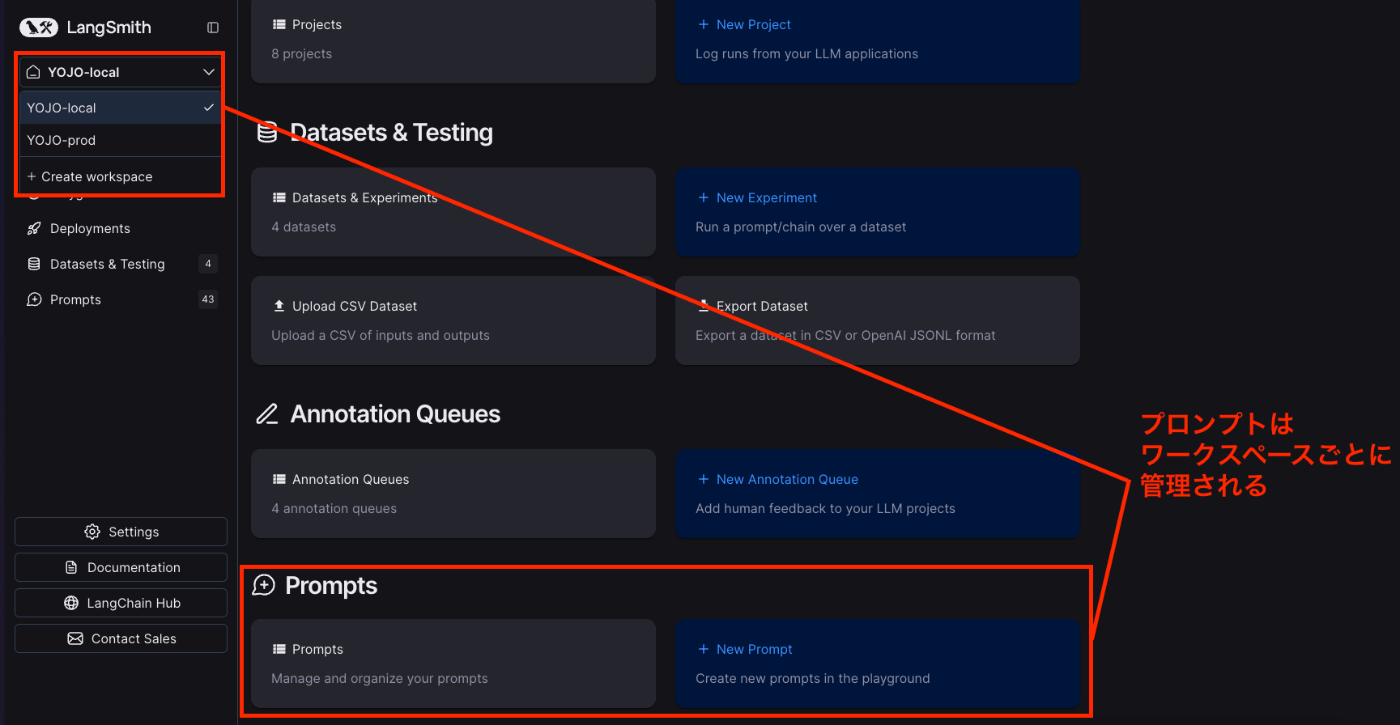
しかし、LangSmithでは、プライベートなプロンプトのテンプレートは、ワークスペースを超えてコピーすることができません。
これは実はかなり不便なのです。
(LangChain Hubを使う抜け穴的な方法を見つけましたが、どのみち不便なのでここで詳細を説明することはしません。)
localで開発しながら実験したテンプレートをprodに反映させたい、または、prodで使っているテンプレートをlocalの開発時に使いたい場面というのは当然あります。
つまり、prod&stg用ワークスペース⇄local用ワークスペースで相互にプロンプト・テンプレートをコピーしたいのですが、これができません。
PromptLayerでは、下図のように数クリックでワークスペースを超えたコピーも簡単にできました。


PropmtLayerのプロンプトテンプレートのDuplicate機能
さすがプロンプト・テンプレートを中心においたサービス設計をしているだけのことはあります。
プロンプト・テンプレートのフォルダ機能がなく、検索機能も弱い
どうでもいいことに聞こえるかもしれませんが、これらも地味に不便です。
YOJOでは、プロンプト・テンプレートを大量に使用しています。
確認してみると、YOJOだけで、すでに40個以上のプロンプト・テンプレートを運用していました。
今の私の見立てでは、2024年内に60個は超えると考えています。
こうなってくると、Promptsに大量にプロンプトが並ぶ上に、ソート機能などもないので、かなり見にくくなります。
ラベルで絞り込む機能などもありません。
プロンプト・テンプレート名に英語しか使えないこともあって、何がなんだかわからなくなってしまいます。
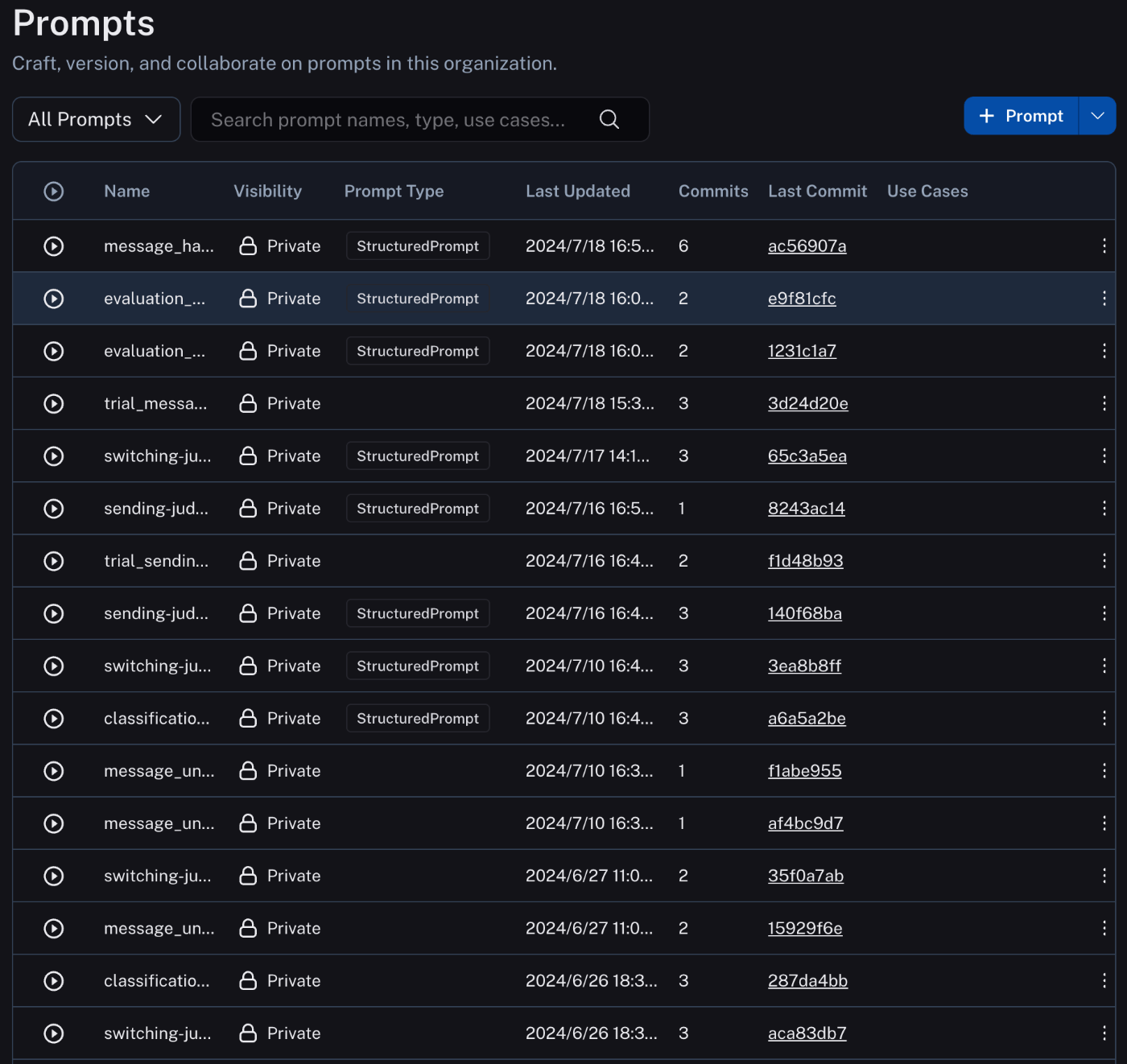
Promtsページ。プロンプト・テンプレートの一覧画面
非常に見にくいのがお分かりいただけるでしょうか、、、
PromptLayer時代は、フォルダ機能があったりとかなり管理がしやすかったのですが、LangSmithになってからはプロンプトをかなり管理しづらくなりました。
正直に言ってしまえば、LangSmithは、プロンプト・テンプレートの管理周りはあまり力を入れて開発していない印象を受けます。
まとめ
最後にLangSmithの不便な点もお伝えしましたが、トータルの感想では非常に満足しています。
今後、実験管理・評価のツールを聞かれれば、LLMを生で実装する場合は、LangSmith一択でオススメすると思います。
もちろん、PromptFlowやAmazon Bedrock StudioやDifyのようなノーコード・ローコードツールを使う場合は、また話が変わってきます。
LLMのノーコード・ローコードツールにご興味のある方は、私がモデレータを務めた下記イベントの動画もご覧いただければ。
LangChain&LangGraphとの相性がいいの箇所でも述べたように必ずしもLangChainを使う必要もないので、LangChainを使っていない方にもオススメできます。
今後もLLM関連の有益な情報をシェアして行きたいと思います!
2024/8/7(水)19:30〜下記のようなイベントも行いますので、ご興味のある方は是非ご参加下さい。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion