この記事の概要
こんにちは。PharmaX でエンジニアをしている諸岡(@hakoten)です。
この記事では、大規模言語モデル(LLM)を活用したアプリケーションの開発を支援するフレームワークであるLangChain内にあるツールの一つ、LangGraphを使ってグラフからグラフを呼び出すネスト構造を作る方法についてご紹介します。
LangGraphの基本的な使い方については、以下の記事もぜひご覧ください。
環境
この記事執筆時点では、以下のバージョンで実施しています。
とくにLangChain周りは非常に開発速度が早いため、現在の最新バージョンを合わせてご確認ください
- langgraph: 0.1.5
- Python: 3.10.12
ネスト構造のグラフ(Subgraph)
LangGraphでは、以下の図に示すように、特定のグラフから別のグラフを呼び出すことができます。(黄色い枠で囲まれている部分が別のグラフを表しています)
LangGraphのドキュメントでは、このような構造を「Subgraph」と呼び、How-to Guidesでその使い方が紹介されています。LangGraphでは、このようなネスト構造で、複数のグラフを組み合わせることで、エージェント間の複雑な連携をグラフの形で直感的に表現することが可能となっています。
複数のグラフの定義方法
前述したグラフの具体的なコードは以下の通りです。
実際のコード
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from operator import add
######## 子グラフの定義 ##########
class ChildState(TypedDict):
path: Annotated[list[str], add]
child_builder = StateGraph(ChildState)
def child_start(state: ChildState) -> ChildState:
return { "path": ["child_start"]}
def parallel_1(state: ChildState) -> ChildState:
return { "path": ["parallel_1"]}
def parallel_2(state: ChildState) -> ChildState:
return { "path": ["parallel_2"]}
def parallel_3(state: ChildState) -> ChildState:
return { "path": ["parallel_3"]}
def child_end(state: ChildState) -> ChildState:
return { "path": ["child_end"]}
child_builder.add_node("child_start", child_start)
child_builder.add_node("parallel_1", parallel_1)
child_builder.add_node("parallel_2", parallel_2)
child_builder.add_node("parallel_3", parallel_3)
child_builder.add_node("child_end", child_end)
child_builder.set_entry_point("child_start")
child_builder.add_edge("child_start", "parallel_1")
child_builder.add_edge("child_start", "parallel_2")
child_builder.add_edge("child_start", "parallel_3")
child_builder.add_edge(["parallel_1", "parallel_2", "parallel_3"], "child_end")
child_builder.set_finish_point("child_end")
######## 親グラフの定義 ##########
class ParentState(TypedDict):
path: Annotated[list[str], add]
parent_builder = StateGraph(ParentState)
def parent_start(state: ParentState) -> ParentState:
return { "path": ["parent_start"]}
def parent_end(state: ParentState) -> ParentState:
return { "path": ["parent_end"]}
parent_builder.add_node("parent_start", parent_start)
# 子グラフは、compileし、add_nodeで追加する
parent_builder.add_node("start_subgraph", child_builder.compile())
parent_builder.add_node("parent_end", parent_end)
parent_builder.set_entry_point("parent_start")
parent_builder.add_edge("parent_start", "start_subgraph")
parent_builder.add_edge("start_subgraph", "parent_end")
parent_builder.set_finish_point("parent_end")
...
# Subgraph(子グラフ)の定義
child_builder = StateGraph(ChildState)
...
# add_nodeで、compile()した結果を渡す
parent_builder.add_node("start_subgraph", child_builder.compile())
...
child_builder = StateGraph(ChildState)がネストされる子のグラフです。
parent_builder.add_node で親グラフに子グラフのコンパイル結果をセットしています。あるグラフから別のグラフを呼び出す場合は、通常のNodeと同じように add_node を使ってグラフに追加することが可能です。
SubgraphにおけるStateの取り扱い
ここでは、あるグラフからネスト構造の別のグラフを呼び出す場合に、Stateがどのように扱われるかを、前述の親子関係のグラフを例に説明します。
親のグラフと子のグラフで同じStateを更新する
まず、親子のグラフが同一のStateを共有しているケースを解説します。
この例では、ChildStateとParentStateが共にpathというプロパティを持っており、各ノードは呼び出された際にそのpath文字列を返してStateを更新するよう設計されています。
...
class ChildState(TypedDict):
path: Annotated[list[str], add]
...
# 子のノード(抜粋)
def child_start(state: ChildState) -> ChildState:
return { "path": ["child_start"]}
...
class ParentState(TypedDict):
# pathのStateを更新
path: Annotated[list[str], add]
...
# 親のノード(抜粋)
def parent_start(state: ParentState) -> ParentState:
# pathのStateを更新
return { "path": ["parent_start"]}
グラフの実行
このグラフを、debugオプションを使用して実行した結果は以下の通りです。
parent_builder.compile().invoke({"path": []}, debug=True)
実行結果のログ
[0:tasks] Starting step 0 with 1 task:
- __start__ -> {'path': []}
[0:writes] Finished step 0 with writes to 1 channel:
- path -> []
[1:tasks] Starting step 1 with 1 task:
- parent_start -> {'path': []}
[1:writes] Finished step 1 with writes to 1 channel:
- path -> ['parent_start']
[2:tasks] Starting step 2 with 1 task:
- start_subgraph -> {'path': ['parent_start']}
[2:writes] Finished step 2 with writes to 1 channel:
- path -> ['parent_start',
'child_start',
'parallel_1',
'parallel_2',
'parallel_3',
'child_end']
[3:tasks] Starting step 3 with 1 task:
- parent_end -> {'path': ['parent_start',
'parent_start',
'child_start',
'parallel_1',
'parallel_2',
'parallel_3',
'child_end']}
[3:writes] Finished step 3 with writes to 1 channel:
- path -> ['parent_end']
{'path': ['parent_start',
'parent_start',
'child_start',
'parallel_1',
'parallel_2',
'parallel_3',
'child_end',
'parent_end']}
ログを詳しく見ると、最後のStateにおいて parent_start が2回登場していることが確認できます。
[3:tasks] Starting step 3 with 1 task:
- parent_end -> {'path': ['parent_start',
'parent_start',
'child_start',
'parallel_1',
'parallel_2',
'parallel_3',
'child_end']}
Nodeの呼び出しログを確認すると、parent_start ノードが複数回呼び出されているわけではなく、parent_end ノードの呼び出し直前のStateで parent_state が2回更新されています。
これは、親のStateが子に引き継がれ、子から親に戻る際に、「最初に親が保持していたStateの値が子ノードからそのまま返される」という挙動によるものです。
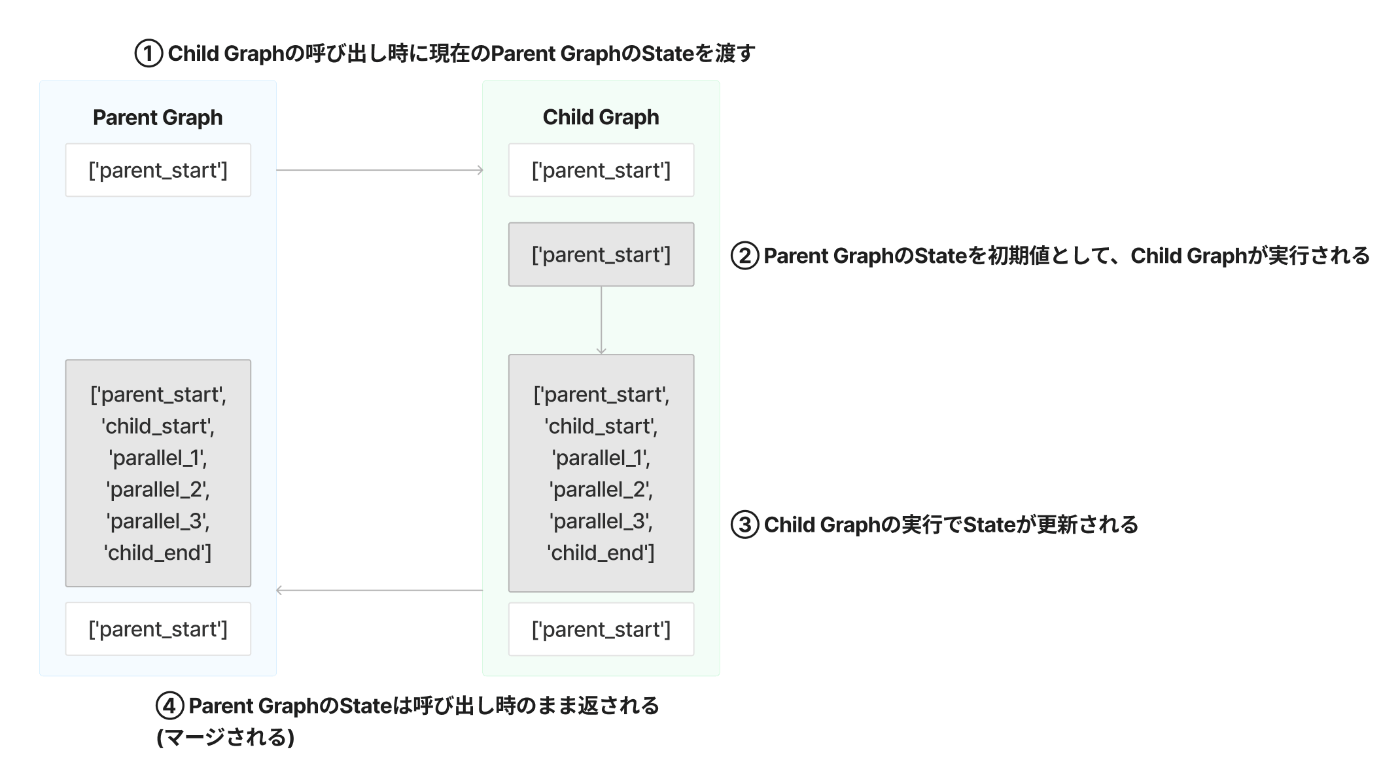
このように、親子関係にあるグラフで共通のStateを使用する際は、意図しない更新が行われないよう注意が必要です。
この点については、 How-to Guides でも解説されています。
親のグラフが子のグラフのState(実行結果)を受け取る
次に、親のグラフが子のグラフからState(実行結果)を受け取る場合について説明します。たとえば、親が子のグラフに何らかの処理を依頼し、その処理結果を子が返す場合です。
実際のコードは以下のようになります。グラフの構造自体は、先ほどの例と同様ですが、Stateの扱い方に変更があります。
実際のコード
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from operator import add
######## subgraphの定義 ##########
class ChildState(TypedDict):
value: Annotated[list[int], add]
child_builder = StateGraph(ChildState)
def child_start(state: ChildState) -> ChildState:
return { "value": [] }
def parallel_1(state: ChildState) -> ChildState:
return { "value": [10] }
def parallel_2(state: ChildState) -> ChildState:
return { "value": [20] }
def parallel_3(state: ChildState) -> ChildState:
return { "value": [30] }
def child_end(state: ChildState) -> ChildState:
return { "value": [] }
child_builder.add_node("child_start", child_start)
child_builder.add_node("parallel_1", parallel_1)
child_builder.add_node("parallel_2", parallel_2)
child_builder.add_node("parallel_3", parallel_3)
child_builder.add_node("child_end", child_end)
child_builder.set_entry_point("child_start")
child_builder.add_edge("child_start", "parallel_1")
child_builder.add_edge("child_start", "parallel_2")
child_builder.add_edge("child_start", "parallel_3")
child_builder.add_edge(["parallel_1", "parallel_2", "parallel_3"], "child_end")
child_builder.set_finish_point("child_end")
######## 呼び出し元(親graph)の定義 ##########
class ParentState(TypedDict):
value: Annotated[list[int], add]
path: Annotated[list[str], add]
parent_builder = StateGraph(ParentState)
def parent_start(state: ParentState) -> ParentState:
return { "path": ["parent_start"]}
def parent_end(state: ParentState) -> ParentState:
return { "path": ["parent_end"]}
parent_builder.add_node("parent_start", parent_start)
# subgraphは、add_nodeとして呼び出す
parent_builder.add_node("start_subgraph", child_builder.compile())
parent_builder.add_node("parent_end", parent_end)
parent_builder.set_entry_point("parent_start")
parent_builder.add_edge("parent_start", "start_subgraph")
parent_builder.add_edge("start_subgraph", "parent_end")
parent_builder.set_finish_point("parent_end")
このグラフでは、親のノードがpathプロパティを更新し、子のノードがvalueという異なるプロパティを持っています。この設計は、親が子のグラフからvalueという結果を受け取ることを想定しています。
...
# valueプロパティを宣言
class ChildState(TypedDict):
value: Annotated[list[int], add]
...
# 子のノードはvalueプロパティを更新する(抜粋)
def parallel_1(state: ChildState) -> ChildState:
return { "value": [20] }
...
# 親のノードはpathとvaluプロパティを持つ
class ParentState(TypedDict):
value: Annotated[list[int], add]
path: Annotated[list[str], add]
...
# 親のノードはpathプロパティを更新する(抜粋)
def parent_start(state: ParentState) -> ParentState:
return { "path": ["parent_start"]}
...
グラフの実行
このグラフを、debugオプションを使用して実行した結果は以下の通りです。
実行結果のログ
[0:tasks] Starting step 0 with 1 task:
- __start__ -> {'path': []}
[0:writes] Finished step 0 with writes to 1 channel:
- path -> []
[1:tasks] Starting step 1 with 1 task:
- parent_start -> {'path': [], 'value': []}
[1:writes] Finished step 1 with writes to 1 channel:
- path -> ['parent_start']
[2:tasks] Starting step 2 with 1 task:
- start_subgraph -> {'path': ['parent_start'], 'value': []}
[2:writes] Finished step 2 with writes to 1 channel:
- value -> [10, 20, 30]
[3:tasks] Starting step 3 with 1 task:
- parent_end -> {'path': ['parent_start'], 'value': [10, 20, 30]}
[3:writes] Finished step 3 with writes to 1 channel:
- path -> ['parent_end']
{'path': ['parent_start', 'parent_end'], 'value': [10, 20, 30]}
最後のparent_endノードで、子のグラフの結果(value)が正しく受け取られていることが確認できます。
ポイントは、親グラフのState(ParentState)が子グラフのStateのvalueプロパティを持っていることです。
子グラフから特定のStateの結果を受け取る場合、親グラフのStateにその対象のプロパティが存在している必要があります。
まとめ
| 用途 | ポイント |
|---|---|
| 親のグラフと子のグラフで同じStateを更新する | 子グラフから親グラフへ戻る際に、最初に親が保持していたStateの値が子ノードからそのまま返される。必要に応じて、reducerを通じてStateの値を管理する必要がある。 |
| 親のグラフが子のグラフのState(実行結果)を受け取る | 子グラフから特定のStateのプロパティを受け取る場合は、親グラフのStateにその対象のプロパティを含める必要がある。 |
(補足) StateGraph(CompiledGraph)をadd_nodeでセットできる理由
parent_builder.add_node("start_subgraph", child_builder.compile())
このようにStateGraphをコンパイルした結果をadd_nodeメソッドでセットし、その結果を別のグラフとしてノード内で実行する方法を紹介しました。しかし、なぜGraphのコンパイル結果をadd_nodeにセットできるのでしょうか。ここでは簡単にその理由を補足します。
StateGraphをcompile()メソッドでコンパイルすると、CompiledGraphというクラスのインスタンスが生成されます。
class CompiledGraph(Pregel):
builder: Graph
...
コードに示されているように、このクラスは、Pregelという基底クラスを継承しています。更にこのクラスを遡ると RunnableSerializable というクラスを継承していることがわかります。
class Pregel(
RunnableSerializable[Union[dict[str, Any], Any], Union[dict[str, Any], Any]]
):
(実際のコード)
RunnableSerializableは、langchain_core(Langchainの中核をなすライブラリ郡)内で定義される、Runnableというコンポーネントの1形態です。
from langchain_core.runnables import (
Runnable,
RunnableSequence,
RunnableSerializable,
)
Runnableについて
Runnableは、LangChainの設計上、非常に重要なクラスです。
Runnableを基に構築されたインスタンスは、
- invoke/ainvoke
- batch/abatch
- stream/astream
などの共通インターフェースを通じて入力と出力を制御することが可能です。
LangChainがさまざまなコンポーネントを柔軟に組み合わせることができる理由の一つは、Runnableが基底クラスとして設計されているためです。
Runnableについてもっと知りたい方は、LangChainのLCELの章を一読することをお勧めします。
一方 add_node のシグネチャを見てみると、以下のように記述されています。
def add_node(self, node: str, action: RunnableLike) -> None:
このRunnableLikeという型も、langchain_coreで定義されており、次のようなユニオン型になっています。
RunnableLike = Union[
Runnable[Input, Output],
Callable[[Input], Output],
Callable[[Input], Awaitable[Output]],
Callable[[Iterator[Input]], Iterator[Output]],
Callable[[AsyncIterator[Input]], AsyncIterator[Output]],
Mapping[str, Any],
]
(実際のコード)
RunnableLikeはRunnableおよびCallable(関数の型)を包含しているため、add_nodeはRunnableを引数として受け入れることが可能です。
その結果、RunnableSerializableを基に作成されたStateGraph(CompiledGraph)のインスタンスを指定し、Nodeと同じ方法で扱うことができます。
これは、NodeとGraphが実行コンポーネントとして抽象化され、同じ方法で扱える設計になっているためだと思われます。
終わりに
以上、LangGraphでグラフからグラフを呼び出す方法についてご紹介しました。今後も引き続きLangGraphの色々な使い方の紹介などやっていきたいと思います。
PharmaXでは、様々なバックグラウンドを持つエンジニアの採用をお待ちしております。弊社はAI活用にも力を入れていますので、LLM関連の開発に興味がある方もぜひ気軽にお声がけください。
もし興味をお持ちの場合は、私のXアカウント(@hakoten)や記事のコメントにお気軽にメッセージいただければと思います。まずはカジュアルにお話できれば嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion