PharmaXでは、YOJOというサービスで複数のLLMエージェントを組み合わせたマルチエージェントの構成でチャットボットシステムを構築しています。
組み合わせると言っても曖昧ですが、具体的には、LLMの出力結果に基づいて、次の処理を分岐したり、分岐によってLLMを呼び分けたりするフローエンジニアリング(Agentic Workflow)と呼ばれる手法を用いています。
※ 記事執筆当時はフローエンジニアリングと呼んでいましたが、AIエージェントという言葉がバズワード化したことで、フローエンジニアリングよりもAgentic Workflowという言葉のほうがしっくりするようになった気がしています
フローエンジニアリング(Agentic Workflow)自体は徐々に知られつつある概念ですが、日本語で解説した記事や実用事例の紹介がないので、今回はガッツリ解説してみようと思います。
上記で触れられている論文はコード生成に使われていますが、他の分野でも十分使えます。
というよりもフローエンジニアリング(Agentic Workflow)がなければ、複雑な処理をLLMに入れ込むことは難しいかと思います。
フローエンジニアリング(Agentic Workflow)とは何か、どのようなことを考えればいいのか?というコツをYOJOの例にも触れながらご説明いたします。
今回例に取り上げるLLMアプリケーションの概要
フローエンジニアリング(Agentic Workflow)がイメージしやすくなるように、YOJOというサービスの例を簡単にご説明します。
PharmaXのYOJOというサービスは、LINEで薬剤師に相談をして医薬品を購入できるというtoCサービスです。
PharmaX内には、ユーザーである患者さんからの質問にチャットで答える薬剤師が多数在籍しています。
PharmaXは薬局にシステムを販売するのではなく、直接患者さんに医薬品を販売するオンライン薬局であり、薬剤師の方々はあくまでPharmaXに所属する薬剤師です。
詳細は省きますが、メインで扱っているのは、処方箋が必要な処方薬ではなく、処方箋が不要なOTC医薬品です。
今回例として取り上げるLLM機能は、薬剤師がチャットするメッセージ内容をサジェストします。
エンジニアにとってのcopilotのような役割だと思っていただければよいでしょう。
下記が薬剤師メンバーが使うチャット画面です。
(ローカル環境での私自身との会話画面なのでセンシティブな情報は含みませんが、画面の一部をマスクしていることをご了承ください。)
患者さん(ユーザー)からメッセージを受信したタイミングでLLMによる返信のサジェストが作られます。
サジェストされた内容を薬剤師が確認し、必要があれば修正して送信します。
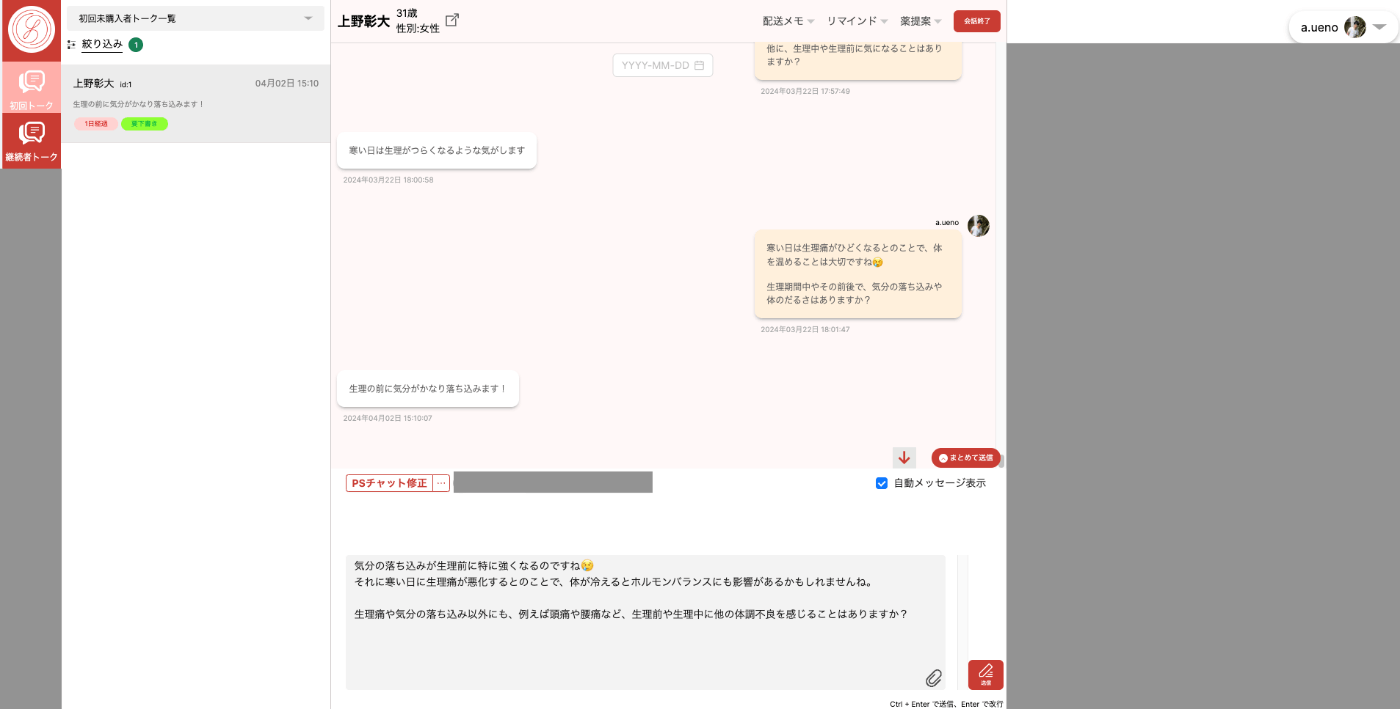
薬剤師が患者さんの状態を確認しつつ、チャットするための管理画面
詳細は省きますが、現在では、LINE登録〜購入までの流れのかなりの割合が薬剤師の修正なしで、承認するだけで送信することができています。
フローエンジニアリング(Agentic Workflow)とはなにか
フローエンジニアリング(Agentic Workflow)とは、あるタスクを1つのLLMエージェントですべて解かせるのではなく、そのタスクを細分化して、エージェントやアプリケーションの実装を組み合わせてどう解いていくかをデザインすることを指します。
私の理解では、タスクの分岐によっては、LLMに解かせるのを諦めて人が解くパターンが含まれるものもフローエンジニアリング(Agentic Workflow)と呼びます。
例えば、カウンセリングAIを作ろうとしているとしたら、普段はLLMエージェントが対応しつつ、自殺願望を仄めかすような発言をした場合には、人間が対応するモードに切り替わるというようなイメージです。
このようにシステム、エージェントの組み合わせ全体デザインし、目的とする処理系を作り上げることをフローエンジニアリング(Agentic Workflow)と呼ぶと理解しています。
PharmaXでは、フローエンジニアリング(Agentic Workflow)という言葉が注目される前から、実質的にフローエンジニアリング(Agentic Workflow)を行っていましたが、
アプリケーションの実装コストが高いので、なかなか一般には受け入れられないだろうなと思っていました。
ですが、最近は、DifyやBedrock Studioのようなほぼノーコードなツールや、PromptFlowのようなローコードツールも人気を博し、徐々にフローエンジニアリングを実現しやすくなってきた印象です。
YOJOのマルチエージェント・フローエンジニアリング(Agentic Workflow)の概要
早速、YOJOのメッセージ提案機能におけるフローエンジニアリング(Agentic Workflow)の概要をご説明します。
YOJOのメッセージ提案機能は、
- ルールベースでLLM処理可能かを判定
- LLMで会話を分類しLLM処理可能かを判定
- LLMで次のフェーズに移るべきかどうかを判定
- LLMでメッセージを作成
- LLMで作成されたメッセージを評価(LLM as a Judge)し、一定の水準を下回ったら再生成して、クリアしたもののみをサジェストする
という順番で動きます。
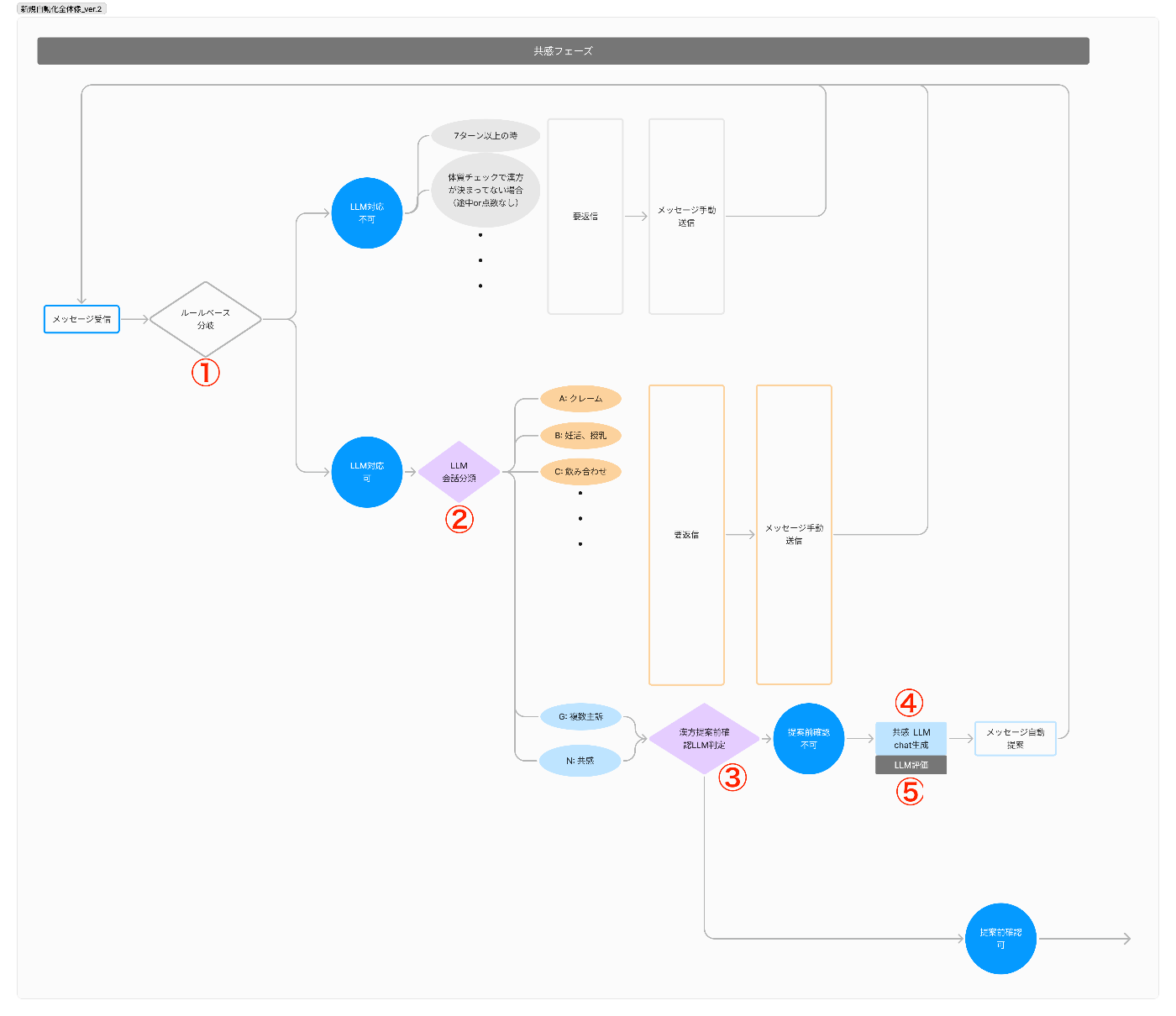
メッセージが作成されるまでの一連の処理イメージ
ただメッセージを生成させるだけで、かなり複雑な手順を踏んでいるのがお分かりいただけるかと思います。
会話分類の結果によっては、LLMでのメッセージ生成を諦めて、最初から人が対応するパターンもあります。
これは、危険性を鑑みてということでもありますが、(リソース不足や優先順位の問題で)精度高く出力するプロンプトをまだ作れていないだけという場合もあります。
今回は、詳細を省きますが、YOJOでは、フェーズという考え方で患者対応の段階を捉えていて、フェーズごとに動く処理のパターンやプロンプトを切替えています。
そのため、今このタイミングでフェーズを切り替えるかべきか?というのを判断するLLMエージェントも動いています。
このように目的とする処理を完了するまでに、ルールベースやエージェントの出力結果によってその後の処理を切替えたり、呼び出すプロンプトが変わったするのがフローエンジニアリング(Agentic Workflow)です。
なぜエージェントを分割をするのか
まず前提として押さえておいていただきたいのは、基本的には、一つのLLMに多くの仕事を任せた方が実装コストは低いということです。
当たり前といえば当たり前なのですが、多くのエージェントを組み合わせた処理系を作るためには、アプリケーション側で分岐やグラフ構造を実装する必要があります。
YOJOの例はややこしいので、単純な例を出しますが、
「Aのプロンプトを呼び出して、その結果によってBまたはCのどちらかのエージェントを呼び出す。」
というようなイメージです。
これを一つの汎用プロンプトにしてしまうことは可能です。
例えば、YOJOの例で言えば、会話分類をして、メッセージ作成までするようなLLMを作ってもいいはずです。
以下のように社内のバックオフィス系の質問に答えるチャットボットを作成することを考えると、1つのプロンプトに分類とメッセージ作成をタスクをぶち込むプロンプトは下記のようになります。
## 質問分類のルール
### 労務系
有給や休暇などの就業規則に関わる質問は労務として扱う
#### 質問の例
「○○○ですか?」
ーーーー
### 人事系
社内の教育制度、採用活動などに関わる質問は人事として扱う
#### 質問の例
「○○○ですか?」
ーーーーーーーーーーーーーーー
## 回答作成のルール
### 労務系の質問への回答
労務系の質問には下記のようなルールで回答すること
①〇〇
②✕✕
③△△
ーーーー
### 人事系の質問への回答
人事系の質問には下記のようなルールで回答すること
①〇〇
②✕✕
③△△
この場合の処理系は下記のようになります。

1エージェントにすべてのタスクを任せる例
一方、下記のように質問内容を分岐して、その分岐結果に応じて次の質問回答をするプロンプトを呼び分けるアーキテクチャを取ることもできます。
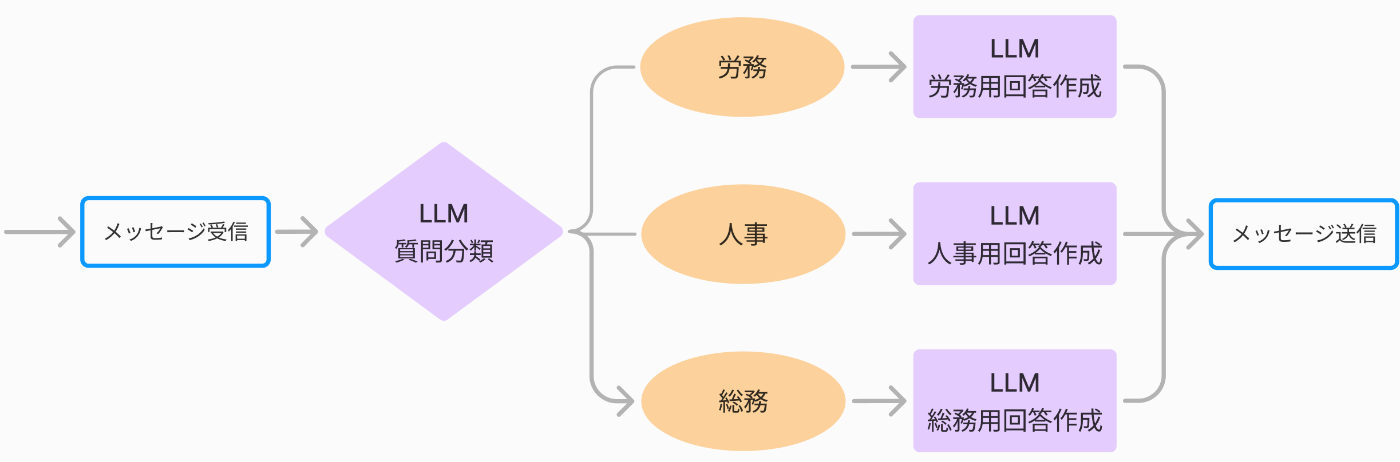
タスクごとにエージェントを分ける例。この例では4エージェントある。
これがフローエンジニアリング(Agentic Workflow)の例です。
プロンプトの分割の仕方は下記のようなイメージになるでしょう。

上の図の1エージェントにすべてのタスクを任せるアーキテクチャは、分岐を実装する必要もないので、アプリケーションの実装は簡単になります。
しかし、1つのプロンプトに多くのタスクを任せる方式は、それはそれで余分な複雑性を抱えることにもなります。
1つのプロンプトに多くのタスクを任せてしまえば、プロンプトを肥大化させ、ソフトウェアエンジニアリングにおけるいわゆる神クラス(神オブジェクト)のようなプロンプトを爆誕させることになります。
プロンプトの肥大化は、精度と改善容易性・保守性を著しく低下させます。
まず第一に、プロンプトを大きくしても、すべての指示には従ってくれません。
というよりプロンプトを大きくすればするほど、1つ1つの指示は正確に理解されなくなっていきます。
また、プロンプトが大きくなれば、どこを変更すればどのように出力結果が変わるのかが分かりにくくなっていきます。
プロンプトのある箇所を変更したことが、全く予期せぬ箇所に思わぬ結果を招くこともあります。
ありとあらゆるケースを事前にテストできればいいですが、そうではない場合は、リリース後に思わぬ出力がされてしまうケースが発生するかもしれません。
ソフトウェアでも全く同じような議論を見たことがあるはずです。
エージェント分割の基準
それでは、各LLMエージェントはどの単位で分割すればいいのでしょうか?
結論から言えば、実験して決めていくしかありません。
精度・実装難易度・処理速度・コストなどのバランスで判断するしかないでしょう。
1つのLLMに複数のタスクを任せてしまえば、いくつかのケースに対応しきれず、精度の低い出力がされてしまう可能性があります。
エージェントを分割すれば、各エージェントは特定のタスクに専念できるので、専門のタスクに対しては精度が上がっていきます。
一方で、最終出力までに通るLLMエージェントが増えれば増えるほど精度は掛け算的に下がっていきます。
特に、系の中のどこかに精度の怪しいLLMエージェントがあれば、その系全体の精度が一気に下がってしまうことになります。
また、例えば、上記のバックオフィス系質問回答ボットの例では、会話分類の精度が低ければ、労務系の質問回答LLMに人事系の質問を回答させてしまうというようなことさえあり得ます。
その場合、労務系の質問回答LLMは人事系の質問への回答のルールは知らないので、回答の精度は著しく下がってしまうでしょう。
このような例では、会話分類の精度がかなりキモであることがお分かりいただけると思います。
今自分たちが作ろうとしている処理系にとって、どの構成のときに最もトータルの精度が高くなるのか?は処理系全体で判断するしかありません。
すなわち実験して判断するしかありません。
そして、上記の会話分類のように、系の中で精度が重要なエージェントはどれなのかを見極め、そのエージェントがどの程度の精度を達成できるのか?を冷静に判断する必要があります。
また、複数のエージェントを通って最終出力がされるパターンと、1つの巨大エージェントにタスクを任せるパターンを比較すると、前者の方は、1エージェントあたりの平均処理速度は速くなりますが、処理系全体の速度は遅くなる可能性があります。
これは、処理をどの程度平行に処理できるのか?などにもよるので、実装コストと相談して総合的に判断するしかありません。
私たちは、一度ある程度大きなサイズのプロンプトを作ることを考えて、精度的に難しければタスクごとに分割するという順番で考えることにしています。
ただし、巨大すぎるプロンプトになりそうな場合や、タスクがかなり複雑な場合は、最初からエージェントを分割する方針で進めることもあります。
LLMの知能向上によってマルチエージェントの構成は不要になるか
いずれLLMが汎用的な知能を獲得し、1つのLLMエージェントに多くの仕事を任せられるようになっていくはずだという意見があります。
実際、YOJOでも、もう少しLLMの知能が向上すれば、一部の分岐を1つの大きなプロンプトに閉じ込めてしまいたいと思っている箇所はあります。
これまで、エージェントを分割せよと述べてきましたが、私個人の立場は、決して単一タスク型プロンプト至上主義(今作った言葉です 笑)ではありません。
なぜエージェントを分割をするのかでも述べたようにある程度の複雑性を1つのLLMに閉じ込められれば、アプリケーションの実装のコストを下げられます。
そのため、バランスを見ながら多少の複雑な仕事はLLMエージェントに任せてしまいたいと思っています。
ですが、巨大な汎用LLMを爆誕させることには決して得策だとは思ってもいません。
単一タスク型と汎用型の中間志向というイメージでしょうか。
系全体の複雑性とプロンプトの複雑性のトレードオフの中で程よいラインがあるということです。
先程のバックオフィス系質問回答チャットボットの例で言えば、例えば、
下記のように分類と質問回答のエージェントは分けるけれども、質問回答のLLMは細かく分割しない
という程度がほどよいラインかもしれません。
(あくまで例えばの話です)
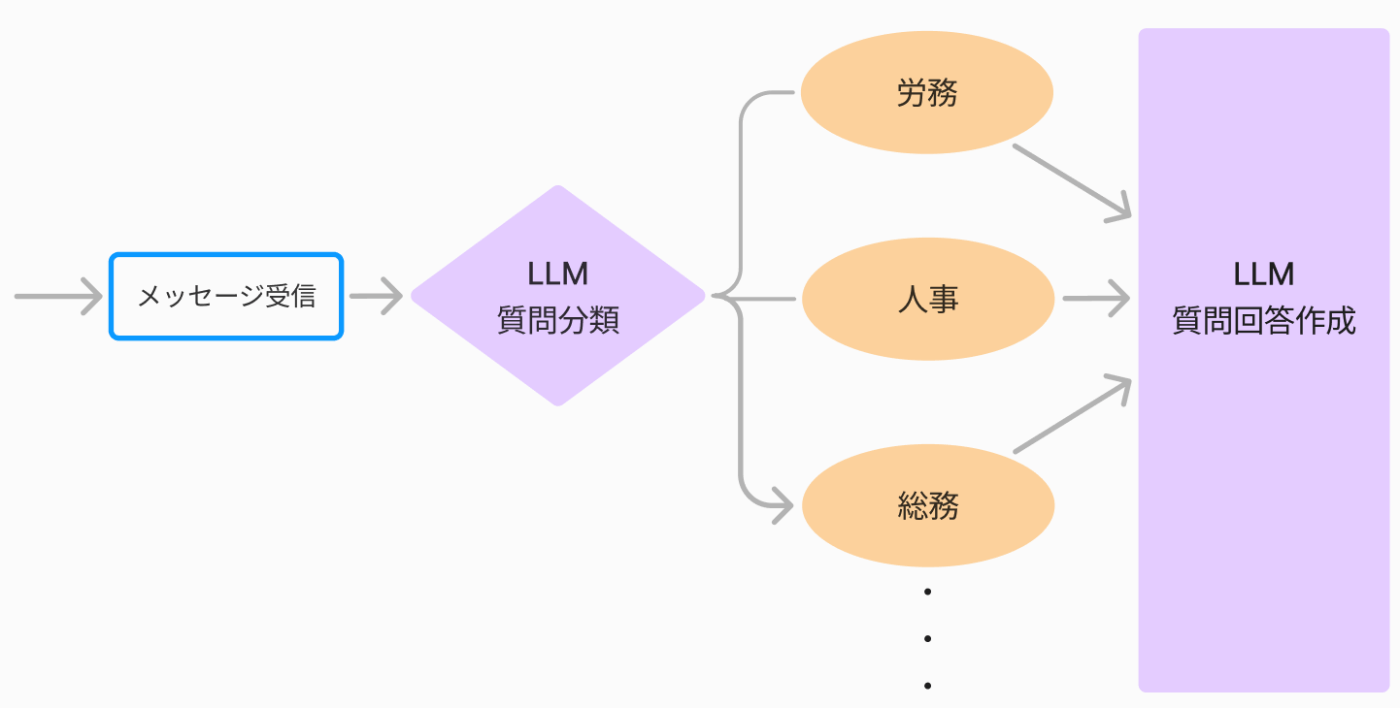
LLMエージェントが質問分類と質問回答作成の2つになった例
このパターンであれば、上記で議論したように仮に労務系を人事系と会話分類を間違えた場合でも、プロンプト自体には労務系の知識が入っているので、プロンプト次第では、労務系との分類されつつも人事系の回答ルールも踏まえてよしなに答えられるかもしれません。
(プロンプトの書き方次第なところはあるので、実際にはやってみなければ分かりませんが。)
ある意味では汎用AIである人も職種によって分かれているように、LLMもある程度専門性に分かれていた方が効率的でしょう。
LLMがより汎用的になったとしても、指示をするプロンプトがなくなるわけではないと思います。
(プロンプトという形式かは分かりませんが)
なぜエージェントを分割をするのかでも述べたようにあまりにも複雑なことを1つのLLMにさせようとしすぎると制御しづらくなっていくので、今後もLLMにもある程度の専門分科は発生すると考えています。
マルチエージェント構成を作る上での技術構成
グラフ化
マルチエージェントでフローエンジニアリング(Agentic Workflow)を実現するには、処理のグラフ化を行う必要があります。
LangSmithのPromptFlowやを使えば、簡単にグラフ構造を作ることが可能です。
私たちはLangSmithを使っていて、PromptFlowをがっつり使っているわけではないので正確な比較はできませんが、話を聞いている限りは結論、どちらでもあまり変わらないような気もします。
LangGraphの使い方については、弊社諸岡(@hakoten)の記事や私が運営メンバーであるStudyCoのしまさん発表のYoutubeをご覧ください。
実験管理
マルチエージェントの構成を構築する上で重要なのは、実験管理です。
複数のエージェントの出力結果を追って管理していく必要があるので、
YOJOではLangSmithを使っています。
LangSmithはフローエンジニアリング(Agentic Workflow)の一連の処理をまとめて可視化することができます。

上図の例は、会話分類でLLM処理の流れが止まってしまったケースです。
このように処理がどこまで行って止まったのかが一目瞭然です。
LangSmithを採用した理由は詳しくは下記の記事をご覧ください。
まとめ
今回は、徐々に認知されつつあるフローエンジニアリング(Agentic Workflow)という概念について解説しました。
フローエンジニアリング(Agentic Workflow)を取り込むことで、精度高くLLMにサジェストさせることが可能です。
今後LLMアプリケーションを開発しようとしている方には必須の知識だと考えています。
今回の内容が参考になれば嬉しいです。
今後もLLM関連の有益な情報をシェアして行きたいと思います!
2024/8/7(水)19:30〜下記のようなイベントも行いますので、ご興味のある方は是非ご参加下さい。
フローエンジニアリング(Agentic Workflow)についても触れられると思います!
[参考]フローエンジニアリング(Agentic Workflow)に触れられている記事
下記の記事でもフローエンジニアリング(Agentic Workflow)について触れられています。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion