LLMアプリケーションを運用されているみなさんは新しいLLMモデルが出た時どのように検証して、どのようにモデルをアップデートされているでしょうか?
性能が高いモデルが出たから変更してみたいということもあれば、性能は低いけれども価格が圧倒的に安いから変更したいというケースもあるでしょう。
今回は、LLMの新しいモデルが出た際の検証と実際にリリースする運用をシェアします。
モデル間の比較検証の手順
同じプロンプトでデータセットに対して出力して評価する
データセットの準備
当然ですが、検証するためのデータセットが必要です。
データセットを作るのには、LangSmithのAnnotation Queuesでの運用を激推ししています。
LangSmithの運用の詳細は下記の記事を見ていただくとして、本番データをアノテーションしてデータセット化して溜めて置くことができれば、このような検証をする際に使えます。
LangSmithのデータセット画面
必要なのは入力と理想とする出力のペアです。
データセットの管理だけなら、あえてLangSmithなどのツールを使う必要はありません。
SpreadSheetなどで管理してもいいのです。
LangSmithなどのツールを使うのが特に便利なのは、データセットを蓄積する運用においてです。
後述する評価結果を比較する場合などには一覧でパッと見で比較したい場合にも、LangSmithなどのツールは可視化機能を持っていたりするので、多少便利かもしれません。
評価基準の作成と評価
当然ながら、モデル間の出力を比較するには評価基準を決める必要があります。
まず簡単に思いつく評価基準は、理想とする出力と新しいモデルの出力とを比較することでしょう。
識別などのタスクであれば、JSONなどのフォーマットから重要な要素を抽出して直接比較してみればいいでしょう。
例えば、識別タスクであれば、識別結果が等しいかを直接確かめればいいですし、Scoreを出すような回帰タスクであれば、二乗誤差などを計算してみればいいでしょう。
文章作成のタスクであれば、期待する出力との文字列間の距離をembedding-distanceやlevenshtein-distanceでスコアリングしたりします。
ここでは詳細は省きますが、例えば、embedding-distanceは文字列間の意味的な距離を測ることが出来ます。
文字列間の"距離"なので、0に近いほうが似通った文章ということになります。
ただし、比較的自由な文章生成タスクでは、元の出力に必ずしも近しいことが正義だとは限りません。
目的が達成できればそれでいいわけです。
もしかしたら、モデルとなる文章とはかなり違う文章だけれども、本来の目的に照らし合わせれば、新しいモデルが出した文章の方がいいなと思うこともあるかもしれません。
つまり、その文章が目的を達成しているのか?、あるいは目的に対して妥当な文章であるか?という評価が必要です。
そのような評価をルールベースなどで下すことは難しいことも多いので、評価もLLMで行うLLM-as-a-Judgeという出力が注目を集めています。
LLM-as-a-Judgeについては、下記の記事を参考にしてください。
重要なのは、普段から出力を評価するために使っているLLM-as-a-Judgeをモデル間比較でも使うということです。
LLM-as-a-Judgeは、評価をLLMで行うという特性上、評価自体にも精度も考える必要があります。
LLM-as-a-Judge用のプロンプトも研ぎ澄ませていかなければならないため、普段から運用していて、プロンプトが十分改善しているものでなければ使い物になりません。
普段から運用していれば、元のモデルでどの程度の評価点数が出ているか?のデータもあるでしょうから、新しいモデルの出力の評価の点数と比較してみて、十分妥当だと判断できるレベルであれば、モデルを置き換えてみてもよいでしょう。
モデルによるtemperatureへの感度の違いを検証する
同じGPTシリーズでも、モデルによってtemperatureへの感度が違います。
どういうことかと言えば、同じプロンプトを使った場合でも、
- GPT-4oのtemperatureが0.7
- GPT-4o-miniのtemperatureが0.6
が同じような出力を出すということがありました。
あくまで数値は例です。
しかも、面倒くさいことに、これはタスクによって異なります。
タスクによっては、モデルを変えてもtemperatureは変えなくてもいい場合もあります。
そのため、同じプロンプトで、temperatureを一旦0.1刻みで変えて評価するということをしています。
もちろん、もとのモデルのtemperature周辺からで試してみればよくて、0から0.1刻みですべてのtemperatureを初めから試してみる必要はありません。
0.1刻みである程度、目星がついたら0.05単位で動かしたりしますが、それ以下の細かい調整は行っていません。
プロンプトを変更して検証する
ここまで同じプロンプトでの検証を書いてきましたが、モデルを変更した際に同じぷろんぷとに少しも手を入れずに元のモデルと同等以上の性能が出ることはあまりないかと思います。
完全に経験則ですが、同じ企業内のモデルで、しかも性能が上がったと言われていても、なんか微妙だな?という出力が出ることがほとんどでした。
ここでモデルの更新を諦めることもできますが、特に新しいモデルがコスト的に圧倒的に安いから使いたいような場合には、同じプロンプトで多少性能が劣化しても、新しいモデルを諦めきれない場合もあるでしょう。
ただし、私たちPharmaXの場合は、基本的には早期に最新のモデルには追従するぐらいの考えでやっています。
ちなみにPharmaXでは、最新のモデルのリリース1ヶ月以内ぐらいにはすべてのエージェントでモデルを入れ替えるぐらいのスピードです。
もちろんGPT-4o-miniのように性能が低い場合にはかなり慎重にやります。
その場合には、下記のようにfine-tuningを行うのも一つの手です。
また、注意が必要な点としては、プロンプトを変更したら、temperatureへの感度がまた変わってしまうことです。
多少の変更であればそこまで変わらないかもしれませんが、大きく変更した場合は、temperatureを±0.1の範囲ぐらいは変更してみて、上述の検証フローを回してみるとよいでしょう。
リリースして検証
当然ながら、最終的にはリリースして見るしかありません。
PharmaXでは、オンラインでもLLM-as-a-Judgeを行っています。
LLM-a-a-Judgeであれば、出力を自動で評価することが可能なので、オンラインでリアルタイムで評価することができます。
PharmaXのYOJOというサービスのメッセージサジェスト機能の例で言えば、下記のようにオンラインでの評価結果の集計を日次で可視化することもしています。
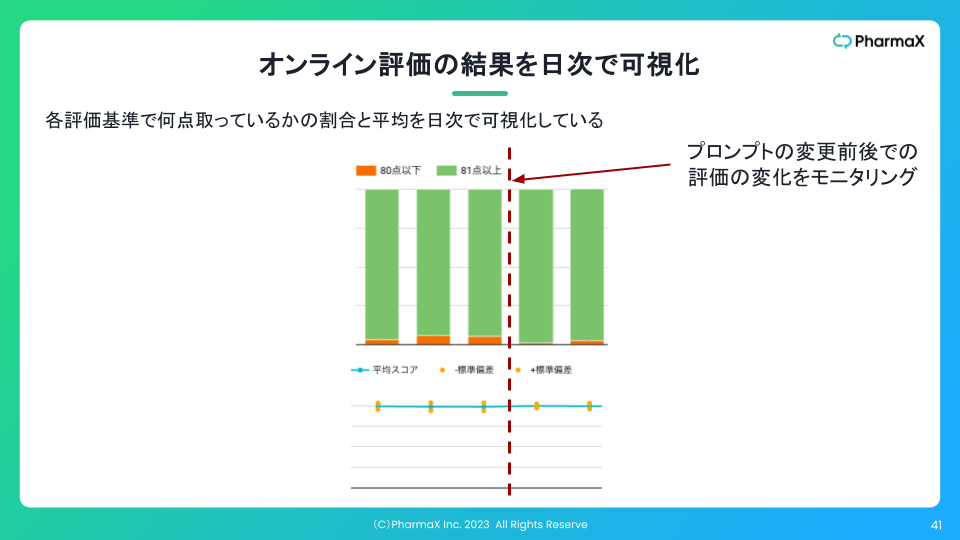
このように可視化していれば、プロンプトやモデルの変更などをした前後で、実際に出力がよくなったのかどうかを判断することができます。
重要なことは、プロンプトやモデルの良し悪しは最終的には本番データで比較する必要があるということです。
また、LangSmithのAnnotation Queuesを使えば、簡単に本番での出力がイケているかイケていないかをチェックすることが出来るので、こういうツールを使って確認して行くこともオススメです。
モデル提供企業を超えての検証
では、モデル提供企業を超えての検証についても考えてみましょう。
つまり、普段OpenAI社のGPTシリーズのモデルを使っているが、Anthropic社のClaudeの最新モデルが出たから試してみたいとうような場合ですね。
前述の通り、私たちPharmaXではOpenAI社のモデルを使用しています。
Claudeなどの最新モデルが出たときに一応試しはするのですが、結論、同じプロンプトではまず満足いく精度は得られません。
正確に言えば、今後はどうなるか分かりませんが、これまではすべての実験で著しく性能が劣化しました。
私個人の勝手な想像では、今後もしばらくの間は、他社のモデルに対して同じプロンプトを書いた場合には、同じような精度でタスクはこなせないと考えています。(数年後は分かりません)
一部の実験の結果を下記に記載しているので、軽く目を通していただくとよいかと思います。
ちなみに実験対象は評価用のLLM、いわゆるLLM-as-a-Judgeのプロンプトです。
同じ程度の性能を持つとされるモデルでも精度が落ちてしまうのは、我々の書くプロンプトが知らず知らずのうちにOpenAIのGPTに最適化されているためだと考えています。
例えば、GPT-4oで何度もPDCAを回して最適化されたプロンプトは、Claude 3.5 Sonnetが理解しやすいようにはなっていないということです。
文章のフォーマットだけではなく、書く順番や言葉遣いなども出力に影響しますから、みなさんが書くプロンプトはどうしても普段使っているモデルに最適化されてしまっているはずです。
企業を超えてモデルを変えたければ、そのままのプロンプトではなく、調査対象のモデルに最適化されたプロンプトを書くべきです。
ただし、どこまで他社のモデルに適したプロンプトを書いて検証できるかは、チームとしての余裕がどこまであるのか?というと、そこまでしてどの程度の利益が見込めるのか?などの総合的な判断が必要でしょう。
私たちのプロンプトは、数千トークンとかなり長いので、一から別のモデルに最適なプロンプトを探して検証し直すのはかなり労力がかかります。
正直に言えば、そこまでして他社のモデルに乗り換えるほどの性能差はないなと判断してしまっています。
ある意味モデルにロックインされてしまっていると考えることもできるでしょう。
特にプロンプトが長い場合には、この傾向が顕著でしょう。
例えば、プロンプトが数百トークン程度の短い場合には、そこまで差がないかもしれません。
その場合は、最高性能のモデルに更新し続けるという意思決定もできるかもしれませんね。
まとめ
今回は、LLMの新しいモデルが出た際の検証と実際にリリースする運用をシェアしました。
古いモデルはいつか止められてしまう可能性もあるので、それなりに難しさはあるものの、ある程度最新版のモデルに追従して行くのがいいのかなと思っています。
どうやって検証のための工数を絞り出すのか?などの各社難しい論点はあるかと思いますが、一度フローを作り込めば、案外簡単に検証できるので是非やってみていただけるといいのではないでしょうか!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion