突然ですが、みなさんLLMのファインチューニングしていますか?
個人的な感想かもしれませんが、ファインチューニングは、幻滅期に入っているように感じています。
GPT-3.5 Turboのファインチューニングが発表されて以降、ファインチューニングしても思ったような出力をしてくれないので、ファインチューニングに期待しないという意見がちらほら聞こえてきました。
ファインチューニングするぐらいなら、Few-shotなどのプロンプトエンジニアリング技法を駆使した方が、結果的には求めている出力をしてくれると考えている方も多かったのではないでしょうか。
正直、私自身もそうでした。
ファインチューニングは、データセットを準備するのも大変ですし、正直コスパがよくないなと感じていました。
実際、プロンプトのチューニングは高速でPDCAを回せるので、ファインチューニングを反復するよりも遥かに高速なフェードバックループを得ることができます。
ですが、一方で、プロンプトエンジニアリングでも求める精度を達成するのには限界があります。
あくまでイメージですが、1つのプロンプトに小さなタスクをこなさせるとしても、体感90%ぐらいの精度までは簡単に持っていけるのですが、それ以上を目指そうとすると、何度もPDCAを回す必要があります。
ある出力を修正できたと思ったら、別の出力が狂ったりして、あちらを立てればこちらが立たず(?)的な状況になったご経験はみなさんあるかと思います。
その課題を解決する方法として、GPT-4o-miniのファインチューニングが思った以上によかったので早速シェアしたいと思います。
気をつけるべきポイントさえ押さえておけば、少ないデータセットで思った通りの出力をしてくれるので、想像以上にオススメです。
ファインチューニングしたGPT-4o-miniのコストは、生のGPT-4o-miniの2倍です。
それでも下記のようにgpt-4oと比較して、10分の1程度のコストにおさまっています。
| モデル | 料金 |
|---|---|
| gpt-4o-2024-08-06 | $2.50 / 1M input tokens $10.00 / 1M output tokens |
| gpt-4o-2024-05-13 | $5.00 / 1M input tokens $15.00 / 1M output tokens |
| gpt-4o-mini | $0.150 / 1M input tokens $0.600 / 1M output tokens |
| fine-tuned gpt-4o-mini | $0.30 / 1M input tokens $1.20 / 1M output tokens |
ファインチューニングで小さく安価なモデルを動かすのは、精度が出るならば試してみたいと考えていらっしゃる方は多いのではないでしょうか。
特にOpenAIのファインチューニングは、GUIを使ってデータをアップロードするだけで行うことができるので、かなり簡単に実行可能です。
さらにLangSmithのアノテーション・データセット機能と組み合わせれば、エンジニアでなくてもファインチューニングしてPDCAを回す運用が可能です。
今回は、どんな場面でファインチューニングを行うべきなのか、どんなことに注意すれば良いのかということから始め、ファインチューニングするための運用についてもご紹介いたします。
ついでにLangSmithを使って簡単にデータセットを作る方法もご紹介したいと思います。
GPT-4o-miniのファインチューニングのすゝめ
冒頭でも述べたように、これまではファインチューニングをするよりは最後の最後までプロンプティングで押し切るのがいいのでは?と考えてきたのですが、最近は見解が少し変わってきました。
ただし、最初からファインチューニングすべき論者でもありません。
「途中まではプロンプトエンジニアリング、最後の一押しはファインチューニング戦法」とでも言うべきパターンをオススメしたいと思います。
プロンプトでのチューニングはある程度のクオリティまでは持っていくのは簡単なのですが、それ以上追求しようとすると一気に難しくなります。
プロンプトに行わせるタスクの粒度次第ですが、あまり多くに責務を負わせず小さなタスクをこなさせるとしても、体感90%ぐらいの精度までは簡単に持っていけるのですが、それ以上を目指そうとすると、何度もPDCAを回す必要があります。
すこし話は逸れますが、「1つのプロンプトでこなすタスクはできる限り小さく単一にする」という原則は下記にもまとめたのでご覧ください。
今回ご紹介するのは、90%以上の精度までプロンプトエンジニアリングで持ってきたら、そこからはファインチューニングに切り替えての精度向上を目指すという戦略です。
数値はあくまで目安なので、ざっくり捉えてください。
下記の数値もただのイメージですが、
まずはプロンプトを作り込んで
GPT-4oのクオリティ(あるいは精度)が90%で、
同じプロンプトでGPT-4o-miniのクオリティが75%
ぐらいまで持っていきます。
(全く同じプロンプトで比較すれば、GPT-4o-miniはGPT-4oの8割〜9割程度の精度になるというのが私の経験則です。)
そのタイミングで、
GPT-4oの出力をきちんと人の手で修正した100%近いクオリティのデータセットを与えてGPT-4o-miniをファインチューニングします。
そうすれば、GPT-4o-miniのクオリティはGPT-4oのクオリティを結構簡単に超えてくるんじゃないかと感じています。
あらゆるタスクに対して検証したわけではないので、あくまで私たちの実験結果ですが、
データセット数も3桁(少なければ2桁)のファインチューニングで十分なクオリティが出ます。
ポイントは、作り込んだプロンプトでファインチューニングを行うことです。
ファインチューニングしたモデルも同じプロンプトで動かす必要があることに注意してください。
あくまで、ファインチューニングはプロンプトエンジニアリングをやりきった後にすべきことだと主張していることに気をつけてください。
オススメのファインチューニング運用案
結論から言えば、オススメの運用は、
- ① GPT-4oでプロンプティングしてある程度(90%以上を目安に)の精度を達成する
- ② GPT-4oで機能をリリース
- ③ LangSmithで本番での出力を集めて修正(=アノテーション)して、クオリティの高いデータセットを作成する
- 特に、1) GPT-4oは正解するが、GPT-4o-miniが間違えるもの、2) GPT-4oが間違えた出力を修正したもの中心にデータセットを作成
- ④ GPT-4o-miniをファインチューニング
- ⑤ (LangSmithの)オフライン評価機能を使ってファインチューニングしたGPT-4o-miniを評価
- ⑤ ファインチューニングしたGPT-4o-miniをリリースして、間違えた出力を修正したデータセットを作成して追加ファインチューニング
という手順です。
最初からGPT-4o-miniのファインチューニングをして精度を担保しようとするのは大変だと思います。
これまでもお伝えした通り、ある程度プロンプトを作り込んだ上でファインチューニングする方がいいかと思います。
プロンプトをチューニングして、これ以上精度が高くならないと感じたら、ファインチューニングを考え始めるといいでしょう。
許されるなら、精度がある程度高まった時点で、GPT-4oでリリースできるのが最高です。
ファインチューニングする上では、データセットを作ることに一番労力がかかるので、まずはGPT-4oでリリースして、本番データをLangSmithでアノテーションしたデータセットを作ります。
早めにGPT-4oでリリースしなければ、データセットを1から自作する必要があるので、コストが掛かってしまいます。
リリースできれば、どんどんデータは溜まってくるので、粛々とLangSmithでアノテーションしていくだけです。
LangSmithでのアノテーション方法は下記を参考にしてください。
特に、1) GPT-4oは正解するが、GPT-4o-miniが間違えるもの、2) GPT-4oが間違えた出力を修正したもの中心にデータセットを作成しましょう。
ここまでくれば、いよいよGPT-4o-miniのファインチューニングです。
上記のようにLangSmithで作ったデータセットを与えてファインチューニングします。
できれば、ファインチューニングしたGPT-4o-miniをリリースする前に事前評価ができるといいでしょう。
本来ならば、ファインチューニングに使ったデータセットと事前評価に使うデータセットは分けるべきです。
議論に深入り過ぎると長くなってしまうので、簡単な説明にとどめますが、機械学習の学習とバリデーション・評価用のデータセットはそれぞれ分けるべきという議論と同様です。
事前評価の結果がよければファインチューニングしたGPT-4o-miniをリリースします。
GPT-4o-miniをリリースして終わりではありません。
リリースした後にGPT-4o-miniが間違えた出力を修正したデータセットを使って追加ファインチューニングすれば、さらに精度が高まります。
ここまでくれば、プロンプトをチューニングしたGPT-4oの精度をファインチューニングしたGPT-4o-miniが超えてくる可能性は十分にあると思います。
特筆すべきは、これらすべての作業でエンジニアは不要なことです。
そこまで膨大なデータセットが必要ないのだとしたら、運用に組み込んでしまいさえすれば、GPT-4oのリリースからファインチューニングしたGPT-4o-miniのリリースまで数日で持っていけるアプリケーションもありそうです。
ファインチューニング用のデータセットを作成
当然ですが、ファインチューニングするためにはデータセットを作る必要があります。
ここで注意なのが、これまでもお伝えしているように作り込んだプロンプトと出力にアノテーションしたセットを与える必要があるということです。
例えば、社内の質問回答ボットを作るとして、
質問内容をカテゴリーに分類するとしたら、
質問内容の分類を"労務", "人事", "総務", ....から選んで下さい。
分類した理由も出力してください。
JSON構造で、{"reason": {分類した理由}, "category": {質問内容の分類}}
## 質問分類のルール
### 労務系
#### 労務系に分類されるルール
有給や休暇などの就業規則に関わる質問は労務として扱う
#### 質問の例
・「○○○ですか?」
・「○○○ですか?」
・「○○○ですか?」
ーーーー
### 人事系
#### 人事系に分類されるルール
社内の教育制度、採用活動などに関わる質問は人事として扱う
#### 質問の例
・「○○○ですか?」
・「○○○ですか?」
・「○○○ですか?」
………
採用活動に関する経費はどこで申請したらいいですか?
{
"reason": "採用活動に関する質問なので人事系に分類される"
"category": "人事"
}
みたいなときにOutputを
{
"reason": "採用活動に関する質問なので人事系に分類される"
"category": "労務"
}
と修正して、プロンプト全部をデータとして与えてあげるようなイメージです。
- GPT-4oが間違えたもの
- GPT-4oは正解するけど、GPT-4o-miniが間違えたもの
を中心にデータとして与えてあげてるのが効率が良さそうです。
ファインチューニングした後のモデルも同じプロンプトを使ってあげる必要があることに注意してください。
もちろんGPT-4oにFew-shotをたくさん与えたり、ルールを厳密に言語化してもいいんですが、プロンプトが長くなると間違えやすくなるし、トークンも消費してしまいます。
私たちも間違った例を正しく修正したものをどんどんプロンプトに与えて変にプロンプトを長くした結果、それまで正解していた回答も間違えるようになってしまったということもありました。
プロンプトが長くなりすぎるとコントロールしづらくなるので、プロンプトの長さは数千トークン以内ぐらいに押さえておいて、その後は経験でモデルを賢くしようという発想と言えるでしょう。
LangSmithのデータセットをファインチューニング用にexportする方法
実は、LangSmithで作ったデータセットをOpenAIのモデルのファインチューニング用にexportする方法は非常に簡単です。
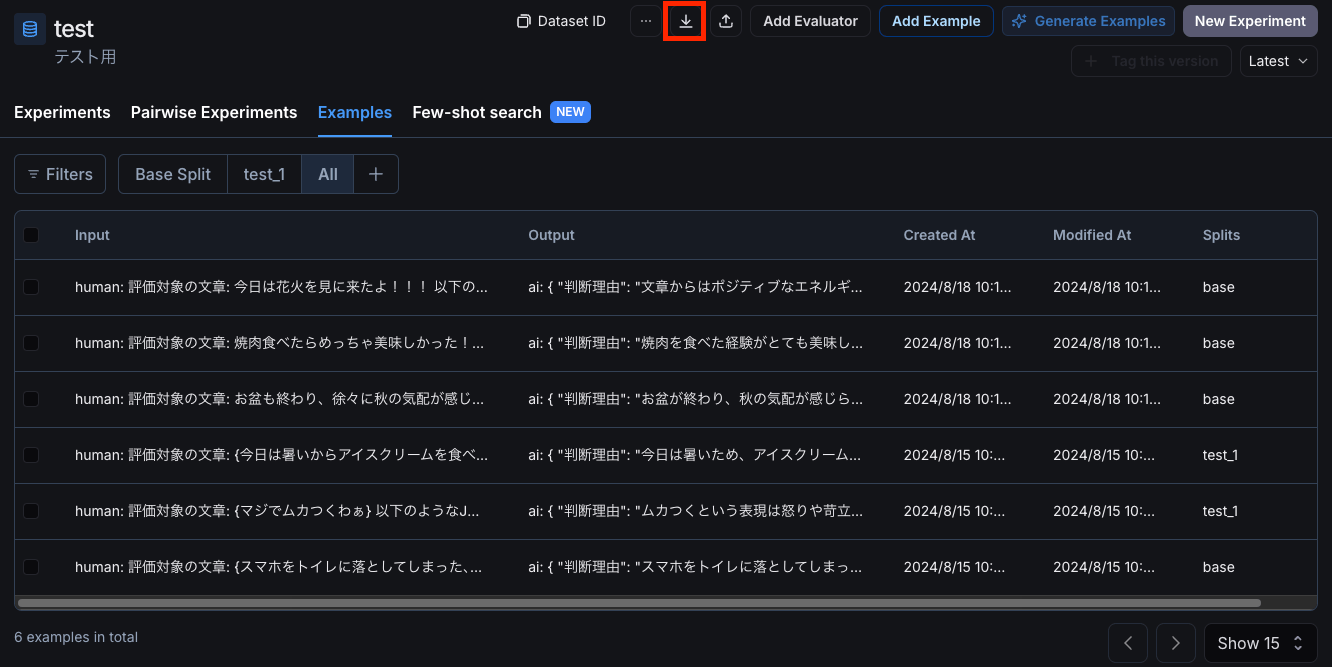
LangSmithのデータセット画面
データセットの画面で上のエクスポートボタンを押します。

LangSmithのデータセットのダウンロード画面
「OpenAI Fine-Tuning JSONL」を選択してダウンロードするだけです。
それだけで、下記のような必要なフォーマットに変換されてダウンロードできます。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
GPT-4o-miniのファインチューニングの仕方
データセットさえダウンロードできてしまえば、GPT-4o-miniのファインチューニング自体も非常に簡単にできます。
OpenAIにGUIが用意されていくので、ボタンを押して行くだけです。
Createボタンを押します。

そうすれば設定画面が開きます。
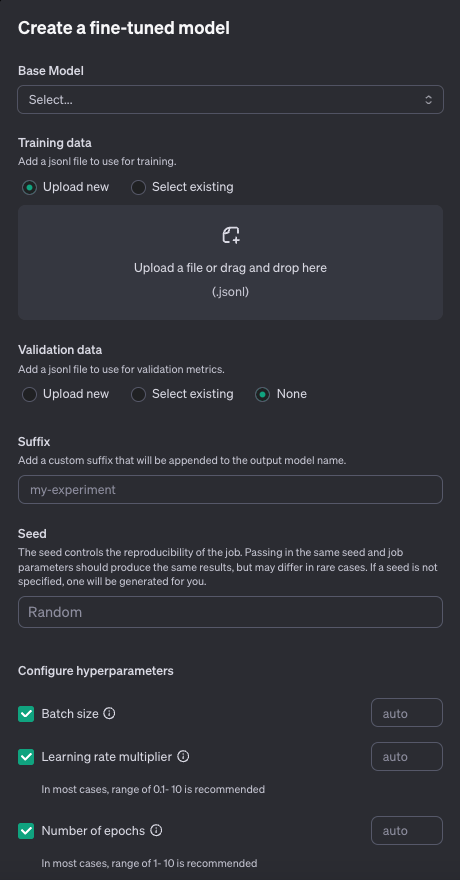
ベースとなるモデルを選択します。
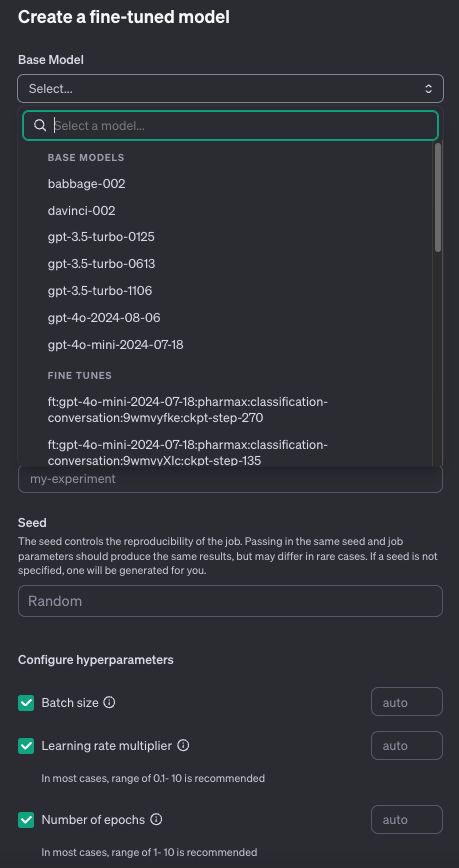
先ほどダウンロードしたデータセットをアップロードします。
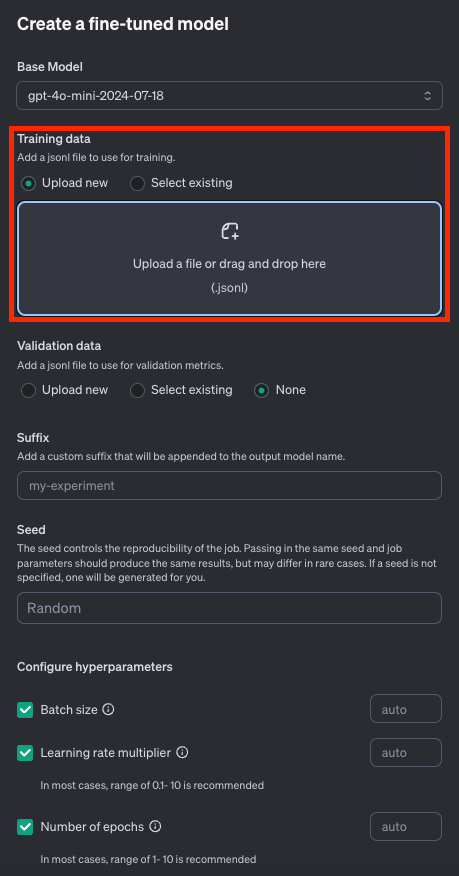
Select existingを選択すればすでにアップロードしているデータを使うことも出来ます。
そしてモデルのsuffixをつけてあげます。これはファインチューニングしたモデルを区別するためです。
あとは、seedやパラメータを決めるだけですが、これはデフォルトのままでも大丈夫です。
これだけでCreateを押して、待っていればファインチューニング可能です。
どうでしょうか?思った以上に簡単だったのではないでしょうか。
ファインチューニングの注意点
最後に今回ご紹介したファインチューニングの注意点を大きく分けて2点お伝えします。
プロンプトを変更した時には再度ファインチューニング必要かも?
今回は、作り込んだプロンプトでのファインチューニングをご紹介しました。
なので、プロンプトを変更する場合には再度ファインチューニングが必要かもしれません。
ここは、正直言うとあまり試しきれていないので、まだ憶測の段階です。
例えば、あるプロンプトでGPT-4o-miniをファインチューニングにしてそれなりに精度が出ていたとしても、精度に限界が見えてきたなとなったときには、プロンプトを修正したいと思うケースもあるでしょう。
そのような場合、再度プロンプトチューニングからやり直す必要があるかもしれません。
つまり、プロンプトを再度チューニングし、また下記の手順を1からやり直す必要があるかもしれないということです。
- ① GPT-4oでプロンプティングしてある程度(90%以上を目安に)の精度を改善する
- ② GPT-4oで機能をリリース
- ③ LangSmithで本番での出力を集めて修正(=アノテーション)して、クオリティの高いデータセットを作成する
- 特に、1) GPT-4oは正解するが、GPT-4o-miniが間違えるもの、2) GPT-4oが間違えた出力を修正したもの中心にデータセットを作成
- ④ GPT-4o-miniをファインチューニング
- ⑤ (LangSmithの)オフライン評価機能を使ってファインチューニングしたGPT-4o-miniを評価
- ⑤ ファインチューニングしたGPT-4o-miniをリリースして、間違えた出力を修正したデータセットを作成して追加ファインチューニング
文章作成などの自由度の高いタスクではファインチューニングの効果は薄いかも
ここまでファインチューニングの良さを語ってきておいて申し訳ないのですが、文章生成などの自由度の高いタスクはファインチューニングの効果は薄いかもしれません。
分類、判別、回帰系のタスクの方がファインチューニングによる精度向上が見込めそうです。
これもあらゆる実験をしたわけではないのですが、弊社内で行った実験ではそのような精度が出ています。
まとめ
今回は、ファインチューニングのすゝめを書いてみました。
繰り返すようですが、オススメはあくまで「途中まではプロンプトエンジニアリング、最後の一押しはファインチューニング戦法」です。
プロンプトチューニングに限界を感じてきたら、後は経験値でゴリ押そうというイメージでしょうか。
ファインチューニング自体は非常に簡単にできるので、サクッと試してみるといいでしょう。
下記のようにファインチューニングするのもそこまでコストが掛かるわけではないので、試してみることにそこまで損はないのではないでしょうか。
GPT-4o fine-tuning training costs $25 per million tokens
(GPT-4oのファインチューニングの学習は100万トークンあたり25ドル)
GPT-4o mini, training cost is $3 per million tokens
(GPT-4o miniのファインチューニングの学習は100万トークンあたり3ドル)
To help you get started, we’re also offering 1M training tokens per day for free for every organization through September 23 for GPT-4o fine-tuning and 2M training tokens per day for free for GPT-4o mini fine-tuning through September 23.
(また、GPT-4oのファインチューニングについては、9月23日まで、すべての組織に対して、1日あたり100万トレーニング・トークンを無料で提供し、GPT-4o miniのファインチューニングについては、9月23日まで、1日あたり200万トレーニング・トークンを無料で提供しています。)
もし何か疑問とかがあればご連絡いただければ幸いです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion