こんにちは。PharmaXの上野(@ueniki)です。
LLMアプリケーションを運用されている皆さんは、アノテーションを活用されていらっしゃるでしょうか?
アノテーションとは、データに対して、正解ラベルやメタ情報などを付与することです。
一般的には、機械学習モデルの作成のために、正解ラベルを付与したデータセットを作る作業を指します。
今回は、LangSmithのAnnotation Queuesという仕組みで、LLMアプリケーションを運用しながら、本番データを使ってアノテーションしていく方法についてシェアしたいと思います。
特に機械学習に習熟していない方、専任の機械学習エンジニアがいない企業の方向けの内容になっています。
LangSmithついて詳しく知りたい方は、下記の記事も合わせてご覧ください。
アノテーションの目的
アノテーションとは、データに対して、正解ラベルやメタ情報などを付与することです。
一番わかり易い例は、画像認識用の機械学習モデルの学習データを作るために、画像に正解ラベルを付与していくような作業です。
写真に写っている動物の名前を当てるモデルの作成のために、何千枚、何万枚の写真にひたすら動物名を付与していくようなイメージですね。
アノテーションされたデータは、教師データとしてモデルの学習に使われたり、オフライン評価用のデータセットとして使われます。
オフライン評価とは何か?というのを詳しく知りたい方は、私の『LLMアプリケーションの評価入門〜基礎から運用まで徹底解説〜』という記事をご覧ください。
ざっくり言えば、オフライン評価とは、LLMアプリケーションのリリース前にLLMの出力が正しく行われていることを事前準備したデータセットについて確かめることです。
本番データを使ったアノテーション
ただし、今回扱うのは、LLMアプリケーションの本番運用中のアノテーションです。
つまり、本番に投入する前の機械学習モデル作成のためのアノテーションではありません。
LLMアプリケーションを本番運用しながら、アノテーションする目的は大きく分けて2つです。
- ①本番でのLLMアプリケーションの出力が本当に正しいのかを人間がチェックする
- ②本番での入力に対してアノテーションを行い、オフライン評価用や学習用のデータセットを作るため
それぞれを詳しく見ていきましょう。
①本番でのLLMアプリケーションの出力のチェック
LLMのアプリケーションは、出力がどの程度正しかったのかを評価する必要があります。
LLMの出力の評価について詳しくは下記の私の記事をご覧いただくとして、
LLM-as-a-Judgeという評価をLLMに自動で行わせる方法があります。
LLMを使って、LLMの出力の妥当性を評価する手法です。
ただし、どれだけ自動で出力を評価しようとしても限界があります。
評価そのものもLLMで行っている以上、その評価も本当に正しいのかも必ずしも正しいとは限らないからです。
オフライン評価でリリース前に評価する方法もありますが、オフライン評価はあくまで事前に用意したデータセットに対しての出力を評価する手法です。
事前に用意したデータセットと本番で、入力データの傾向が異なる可能性もあります。
そのため、オフライン評価で高い性能を示していたからといって、必ずしも本番でも高い性能を示すとは限りません。
そこで、本番での出力が本当に正しかったのかどうかは、最終的には人間が判定する必要があります。
すべての出力を確認することは難しくても、一部の出力を確認すれば、本番での精度が想定(事前評価の結果など)よりも劇的に低くないかぐらいは判定可能です。
後ほど詳しく説明いたしますが、LangSmithを使っていれば、本番の各出力に対して、Feedbackという機能でスコアや合否判定を付けることが可能です。
この機能を使えば、リリース後のLLMアプリケーションの出力の良し悪しの判定を蓄積することができます。
②アノテーションしてオフライン評価用や学習用のデータセットを作成する
オフライン評価用と学習用のデータセットを分けてご説明いたします。
オフライン評価用のデータセット作成
LLMの出力をリリース前に評価することをオフライン評価といいます。
オフライン評価を行えば、リリース前にLLMの出力を網羅的に検査できるため、LLMアプリケーションをリリースしたい企業に取っては重要な評価手法です。
ただし、上記でも述べたように、オフライン評価で使うデータは事前に準備する必要があるため、事前に用意したデータセットと本番で入力データの傾向が異なる可能性があります。
これは、そもそもデータの事前準備の段階で本番データの特徴を捉えられていなかったという可能性と、本番データの特徴が途中から変わってしまったという可能性とが考えられます。
後者はデータドリフトとも呼ばれる現象で、決して珍しいことではありません。
このような事態を防ぐためには、本番で発生したデータをデータセットして追加するのが一番簡単な方法です。
継続的に本番のデータを追加し続ければ、データの傾向が変わってしまったとしても、追従することもできます。
LangSmithを使えば、アノテーションしたデータを事前評価用のデータセットに追加することも簡単に行うことが可能です。
学習用のデータセット作成
次にLLMアプリケーションでアノテーションして蓄積したデータを他のモデルの学習に使うということを考えましょう。
LLMは処理が遅く、かつ高価なので、同じ出力を出すことができる機械学習モデルを作成したり、安価で軽量なモデルをfine-tuningできれば、処理速度向上・コスト削減することが可能です。
特に、LLMで、話題のカテゴリー識別(例:ニュース文をスポーツ、事件、経済、政治...etcに分類する)や、感情識別(喜怒哀楽...etc)のようなタスクを行っている場合には、機械学習モデルに置き換えることが可能です。
また、LLMによる評価(LLM-as-a-Judge)も、データさえあれば、必ずしもLLMで行う必要はなく、機械学習モデルで評価することは可能です。
結局のところ、これらのタスクは、判別や回帰といった従来の機械学習モデルでも解ける問題に過ぎないからです。
GPT-3.5登場以前の自然言語処理のタスクとしても解けるものもあるでしょう。
そして、必ずしもLLMを使う必要のないタスクでは、LLMを使わない方が、一般的には安く速くなるはずです。
下記の記事でも、LLMのフローエンジニアリングの速度向上・コスト削減戦略として、機械学習モデルの作成とfine-tuningを挙げています。
ただし、LLMを使って、下記のようなの文章の感情識別を行うことは、アプリケーションの立ち上げ期には決して悪くない選択肢です。
文章の感情識別を行って、その結果によって次の処理を分岐させるようなアプリケーションを考えましょう。

LLMによる入力文章の感情識別。この例ではうまく判定できていそう。私はいたるところによくスマホを落とします。
プロンプトを調整するだけで速くPDCAを回すことができ、それでいてある程度の精度を担保することができるからです。
言うなれば、データがなくても、ルールさえきちんと言語化できれば、人間と同じような判断をできることがLLMの強みです。
一方で、機械学習モデル化あるいはfine-tuningしようとすると、データセットの準備やモデルのチューニングなどに時間がかかってしまいます。
これが、機械学習におけるコールドスタート問題と呼ばれる問題です。
本来的には従来の機械学習タストして解ける問題も、初期的にはLLMで行い、データが溜まってきたところで機械学習モデルに切り替えていくというのは、悪くない選択肢でしょう。
注意:他のモデルへの学習データの使用
ただし、ここで重要な注意点があります。
いくつかのモデルで、モデルの出力をそのまま使って他のモデルを学習させることは禁止されています
例えば、OpenAIの利用規約には、禁止事項として、
Use Output to develop models that compete with OpenAI.
(Outputを使用して、OpenAIと競合するモデルを開発すること)
が挙げられています。
モデル提供者がこれを防ぎたくなるのは当たり前と言えば当たり前です。
自分たちのモデルの出力を使って別のモデルを作られてしまっては、提供者は儲からなくなってしまいます。
ですが、おそらくLLMからの出力を山行にしつつも、人の手でアノテーションして、LLMからの出力を修正した場合は、学習に使用しても問題ないのでしょう。
また、上記の利用規約の書き方では、OpenAI社が提供するモデルAの出力を使って、モデルBの学習に使うことが禁じられているのかは解釈できません。
例えば、GPT-4oの出力結果を使って、GPT-4o-miniのfine-tuningに使用するようなケースですね。
(すでに利用規約などの書かれているのを発見された方はご教示くださいませ!)
近いうちにこのあたりは各社から徐々に見解が出揃うと思います。
私の予想では、同じ企業のモデルであれば、大きなモデルの出力を使って軽量なモデルをfine-tuningすることは、いずれ許容される方向性になるのではないかと思っています。
そうすれば、モデル利用者は、固定されたユースケースでは、コストメリットを受けることができます。
また、モデル提供者側としても自社のモデルを使い続けてくれることにはなるので、他社の安価なモデルに移られるよりはいいでしょう。
(※ あくまで個人的な将来予想です)
ここまでは、LLMアプリケーションでアノテーションする目的を語ってきたので、LangSmithを使って、アノテーションする運用について見ていきましょう。
LangSmithとは
さっそくLangSmithでアノテーションする方法について見ていきたいのですが、
LangSmithを全くご存じない方もいらっしゃるかもしれませんので、簡単に概要を述べます。
LangSmithは、LangChainの開発元であるLangChain社が開発しているLLMアプリケーションのライフサイクル管理ツールです。
日本でよく知られている言葉を使えば、実験管理、評価用のツールだと思ってしまって間違いではないですが、それ以外の機能も持っているので、ライフサイクル管理ツールと呼ばれています。
LLMに特化しているということにはなっていますが、他の機械学習アプリケーションでも使えます。
LangSmithの開発速度はかなり速く、爆速でいろいろな機能が追加されています。
LangChain社にとってのマネタイズポイントなので、今後もかなり力を入れて開発されるだろうと予想しています。
LangSmithの基本機能トレーシング
LangSmithの基本機能はトレーシング機能です。
下図のようにLangSmithのトレーシング機能を使うことで、実行ログのトレースが非常に簡単に行えます。

各実行単位(メソッドやLLMの実行)は「Run」という単位で記録され、一連の処理はツリー構造としてトレースすることができます。
Annotation Queuesの使い方
LangSmithでアノテーションするならば、Annotation Queuesという機能を使うのが便利です。
概要
Annotation Queuesは、一言で言えば、LangSmithに記録されているRunをQueueに飛ばし、どんどんアノテーションして行くことができるという機能です。

公式ドキュメントから引用
添付の画像のようにLLMの出力結果を評価することができます。
また、"本当はこういう出力であるべきだった"という内容に出力を修正することも可能です。
Queueに溜まっていくという機能があることで、確認したい処理のRunを一つ一つ検索するのではなく、Queueの中で順次確認することができます。
アノテーション役の人がいれば、ただただQueueに飛んできたRunを見てアノテーションをこなすことができて、非常に便利です。
そして、アノテーションしたデータをデータセットに追加することも簡単です。
溜めたデータセットは、上記でも述べたようにオフライン評価用や学習用に使うことが出来ます。
このように、アノテーションしてデータセットに追加するまでの運用をスムーズにできるのがAnnotation Queuesの素晴らしさです。
Annotation Queuesへの追加
下記の画像のようなイメージでルールを追加すれば、それに該当するRunを自動的にQueueに入れることができます。
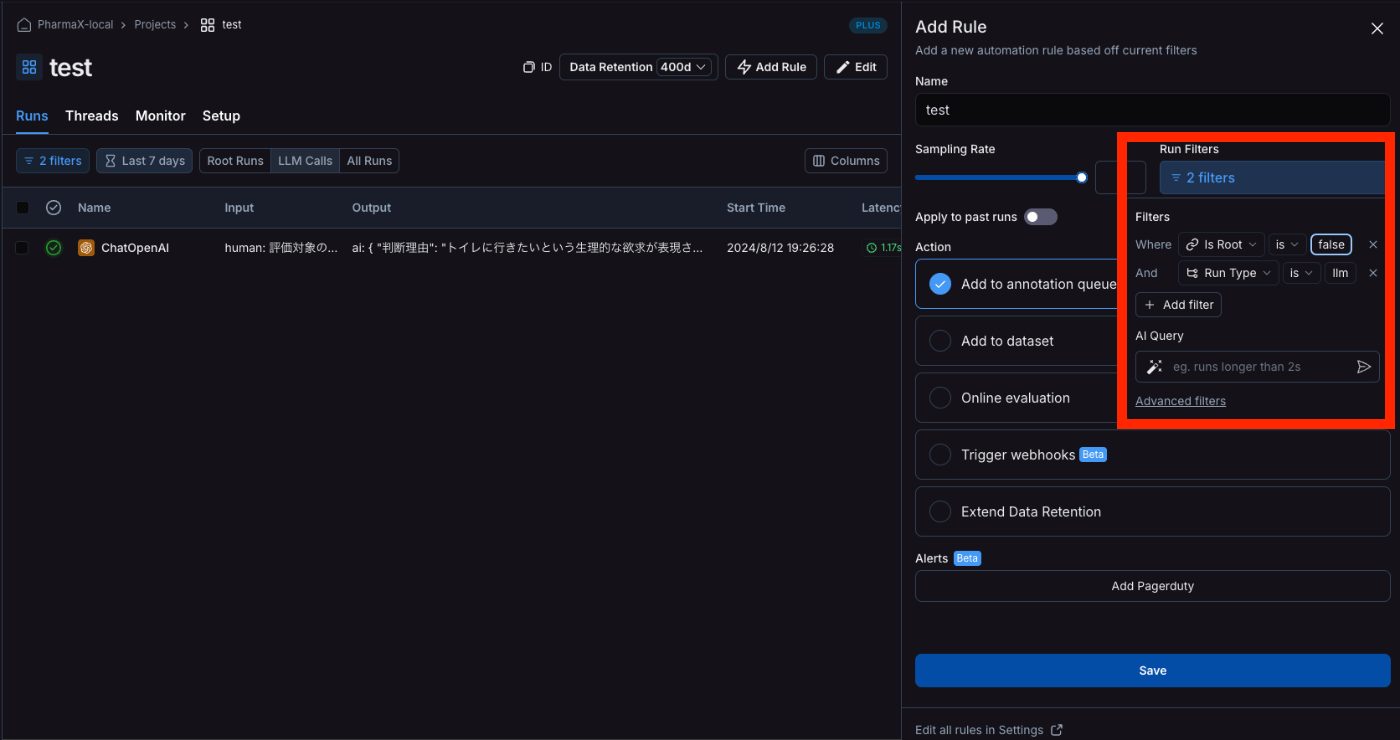
Actionとしては、Add to Annotation queueを選択してください。
追加するAnnotationQueueの名前を選択します。
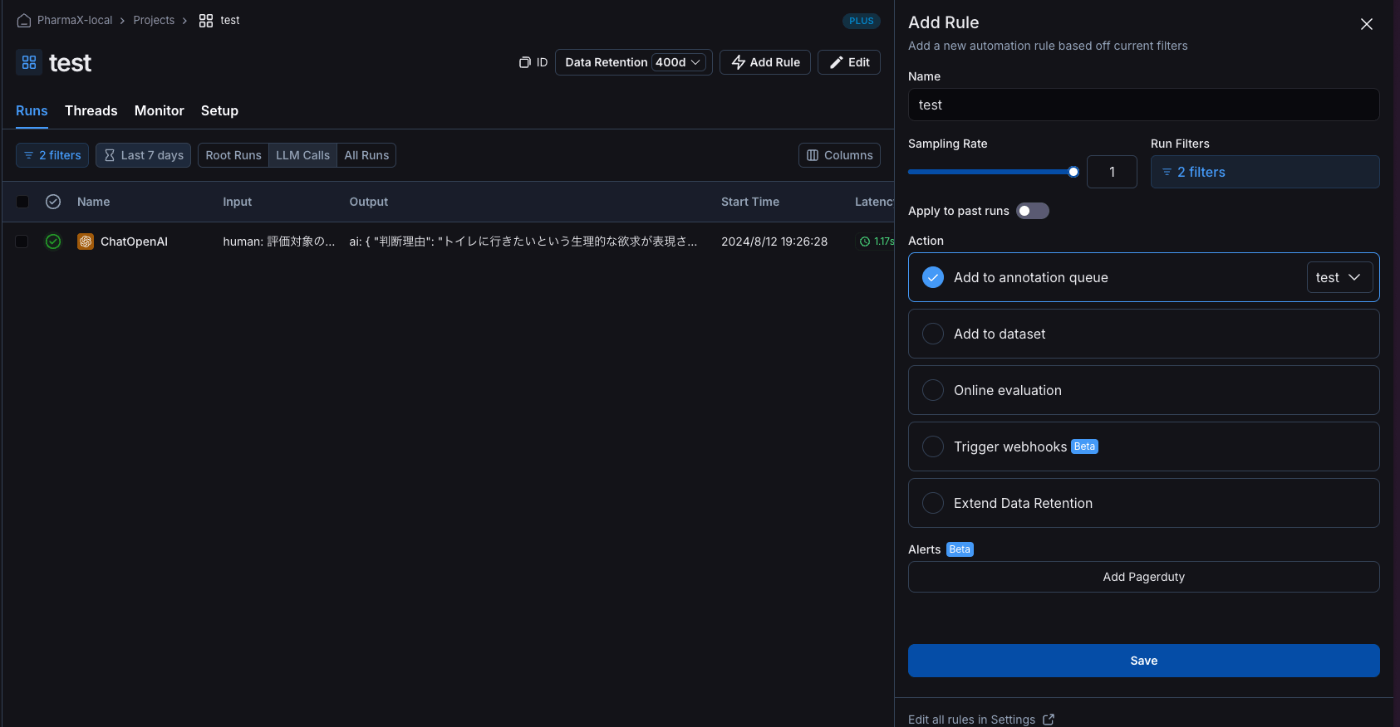
まだ、Annotation Queueを作成していない場合には下記のような画面で作成してください。

ちなみに、ルールを設定せずとも手動でRunをAnnotation Queuesに追加することも可能です。

アノテーション&データセットへの追加
では、実際にアノテーションする画面を見ていきましょう。
データを追加したAnnotation Queuesを開くと下記のような画面になります。

右の画面で、この出力対しての評価をし、コメントを残すことができます。

これで、実際に本番データでLLMの出力が正しかったのかのデータを蓄積可能です。
また、下記のようにoutputを修正してデータセットに追加することも可能です。

データセットへの追加はボタンを押すだけです。
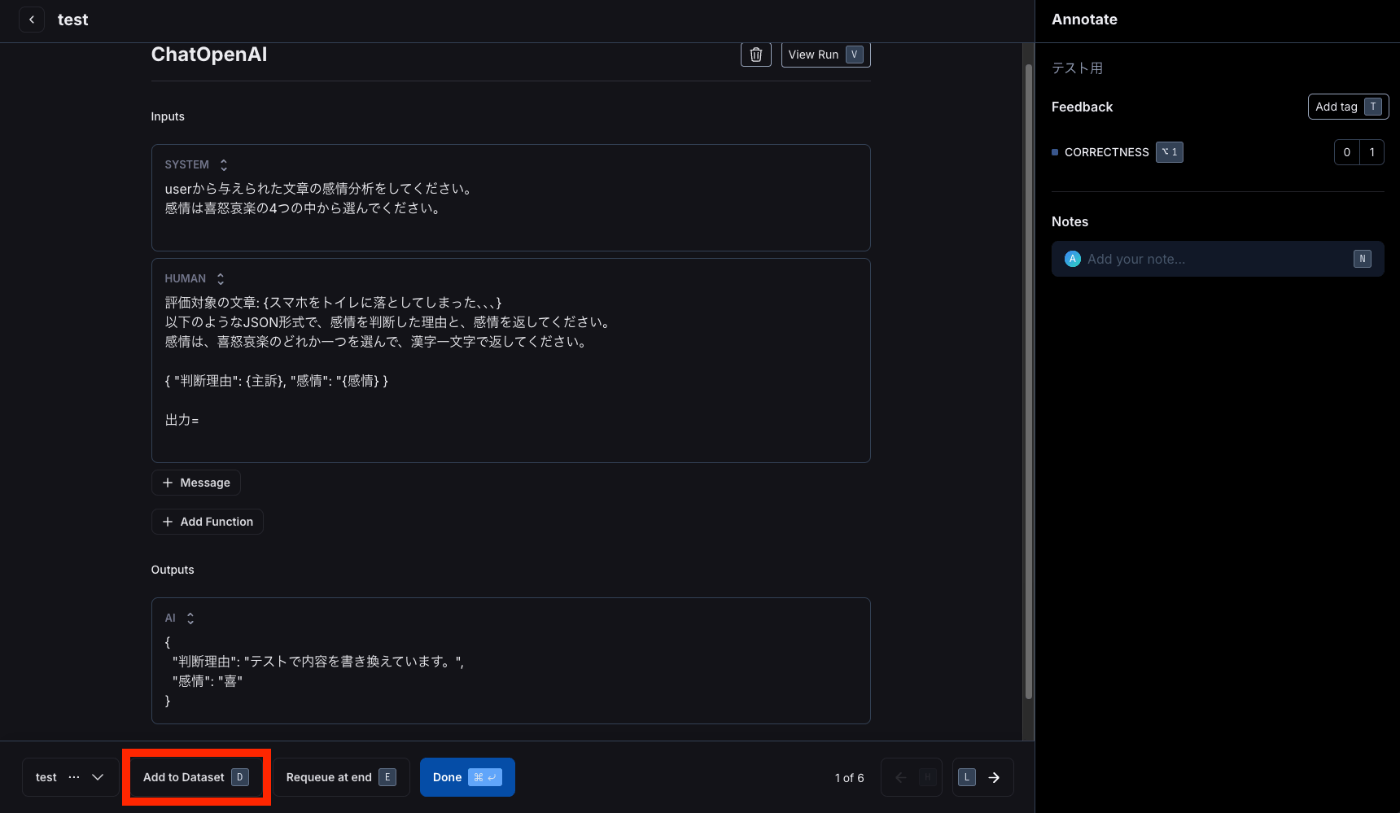
追加するデータセットを作成していない場合は、下記のような画面でデータセットを作成してください。

使い勝手を考えて、紹介したすべての操作がショートカットで可能になっているのにもご注目ください。
こういった細かいユーザビリティが追求されてるのもLangSmithの素晴らしさです。
まとめ
今回は、LLMアプリケーションのアノテーションについて取り上げました。
LangSmithを使えば機械学習の専門家でなくとも簡単にアノテーションを行うことが可能です。
エンジニアである必要すらありません。
LLMから機械学習に入門した方にとっては、馴染みのない概念かもしれませんが、本番環境でのアノテーションは非常に重要です。
本番のデータに即したデータセットを作ることが出来るからです。
今回ご紹介したようにLangSmithを使えば、非常に簡単にアノテーションが可能なので、是非やってみていただくと良いのではないでしょうか。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion