はじめに
こんにちは。PharmaX でエンジニアをしている諸岡(@hakoten)です。
この記事では、LLMアプリケーション開発のための統合環境であるLangSmithを使って、アプリケーションのトレーシングを行う方法について紹介します。
LangSmithはトレーシング以外にも多くの機能を備えていますが、一度の記事で全てを紹介するのは難しいため、今回はトレーシング機能に焦点を当て、弊社での事例も交えながら説明していきます。
この記事を通じて、トレーシング機能の基本的な使い方の参考になれば幸いです。
環境
この記事を執筆した時点では、以下のバージョンで検証を行っています。特にLangChain関連のツールは開発が非常に速いため、検証の際は最新バージョンの挙動も併せてご確認ください。
- langchain: 0.2.14
- langgraph: 0.2.3
- langsmith: 0.1.99
- Python: 3.10.12
LangSmithとは
LangSmithは、LangChain.incが開発したLLMアプリケーション開発を支援する統合的なSaaSプラットフォームです。
「LLMOpsのための統合プラットフォーム」のような位置づけで開発されており、LLMアプリケーションの運用や管理に必要な様々な機能を提供しています。
類似のサービスには、mlflowなどがあり、こちらもMLやLLM関連の統合プラットフォームです。mlflowについては業務で使用した経験がないため、詳しくは言及できませんが、LangSmithと近しい機能も多く、ツール選定の際には比較検討の対象になるかと思います。
LangSmith移行への経緯
PharmaXでは、最近PromptLayerというSaaSからLangSmithへの移行を進めています。この移行に至った経緯については、弊社の上野が執筆した記事で詳しく紹介していますので、ぜひご覧ください。
LangSmithの主な機能
LangSmithは、数多くの機能を提供していますが、大まかに分類すると以下の3つの機能が中心となります。
| 機能分類 | 説明 |
|---|---|
| Tracing | LLMアプリケーションの実行をトレースする機能です。各実行フローにタグやメタデータを付与し、後でフィルタリングして解析やデバッグが可能です。 |
| Evaluation | LLMの実行データセットを登録し、評価を行う機能です。プロダクトリリース前のオフライン検証や、リリース後のオンライン検証に対応しています。 |
| Prompts | LLM用のプロンプトをクラウド上で管理する機能です。プライベートな管理が可能であるだけでなく、Docker Hubのようにプロンプトを一般公開することもできます。 |
この他にも、LangGraph CloudというLangChain.incが提供するグラフ実行ツールであるLangGraphをクラウド上で提供する機能や、Playground機能などもあります。
LangSmithのトレーシング
LangSmithのトレーシング機能を使うことで、実行ログのトレースが非常に簡単に行えます。以下は、実際のトレースログのサンプルです。

LangSmithのトレースログ
トレースログは、各実行単位(メソッドやLLMの実行)ごとに「Run」という単位で記録され、ツリー構造として表示されます。各Runにはユニークな「RunID」が付与され、その実行内容であるINPUTとOUTPUTをコンソール上で確認できます。
さらに、Runの集合全体を追跡できるように、ルートからのRunの集まりに対して「TraceID」が付与されています。
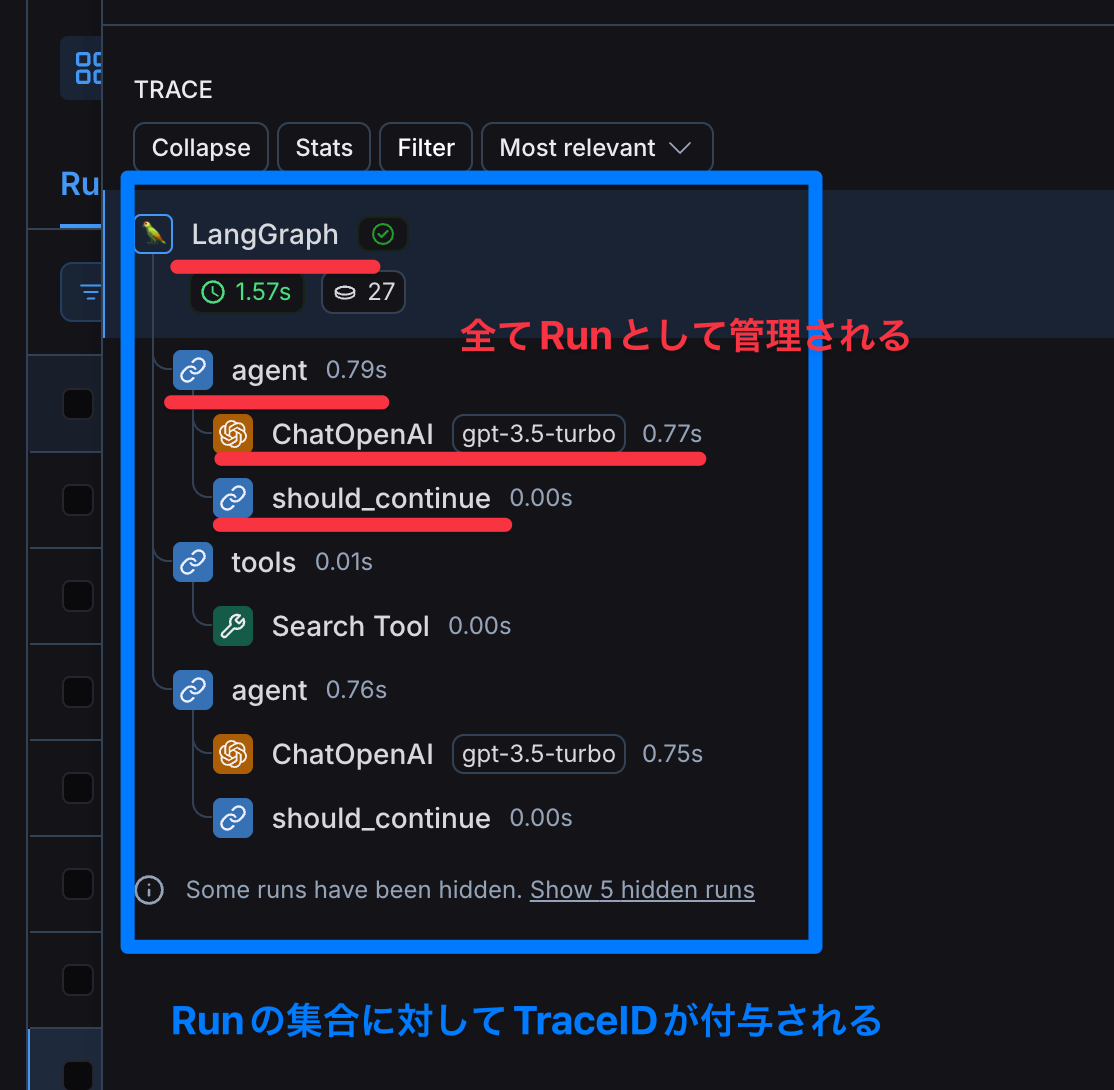
LangSmithに記録されたRunは、このRunIDやメタデータ、タグを使って、さまざまな条件でフィルタリング(検索)することが可能です。これにより、実行後の分析やデバッグに役立てることができます。

実行後のRunをフィルタできる
また、この記事では詳しく触れていませんが、実行されたRunの結果からLangSmithの主要機能の一つである「Evaluation(評価機能)」のデータセットを作成することもできます。
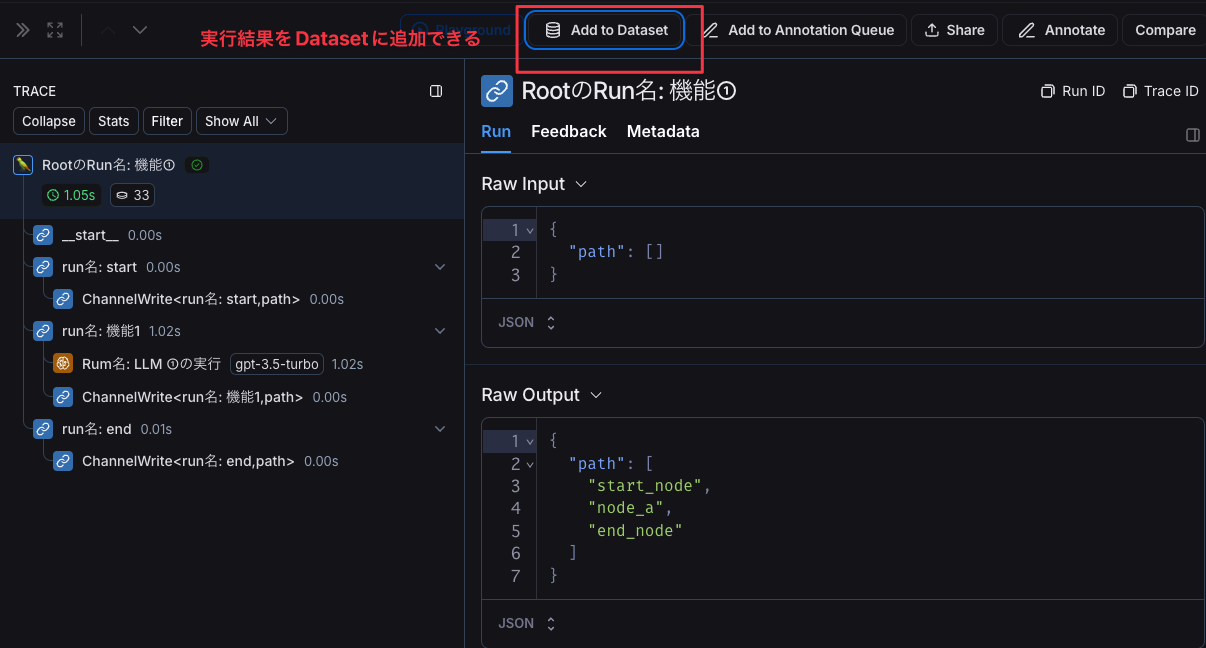
実行後のRunからデータセットを作成できる
トレースの実装方法
ここからは、実際にRunをトレースする方法を紹介します。
環境変数の設定
LangSmithでトレースを開始するための方法の一つに、環境変数を設定する方法があります。基本的には、以下の3つの環境変数を設定するだけでトレーシングが有効になります。
LANGSMITH_API_KEY=<LangSmithコンソールから発行したAPI Key>
LANGCHAIN_TRACING_V2="true"
LANGCHAIN_PROJECT=<LangSmithのプロジェクト名>
関数のトレース
関数をトレースする代表的な方法は、関数に @traceable アノテーションを付与することです。特に設定を行わない場合、Runの名前は関数名がそのまま使用されます。
import openai
from langsmith import traceable
# 関数のトレースは@traceableをつけることで自動的に行われる
# run名は関数名
@traceable
def pipeline(user_input: str):
...
return result.choices[0].message.content
pipeline("Hello, world!")
@traceable に引数を渡すことで、Runの名前などをカスタマイズすることも可能です。例えば、Runに別名を付けたい場合は、次のように name パラメータを使用して名前を指定します。
・・・
# nameパラメタでrunの名前を上書きできる
@traceable(name="my run name")
def pipeline(user_input: str):
...
return result.choices[0].message.content
・・・
LLM実行のトレース
LLMの実行をトレースするには、wrap_openaiという関数を使ってクライアントインスタンスをラップします(OpenAI以外のモデルの場合は、別のラッパー関数が存在します)。この方法でトレースすると、Runの名前は「ChatOpenAI」として記録されます。
import openai
from langsmith.wrappers import wrap_openai
# LLMのトレースはwrap_openaiで自動で行われる
client = wrap_openai(openai.Client())
@traceable
def pipeline(user_input: str):
result = client.chat.completions.create(
messages=[{"role": "user", "content": user_input}],
model="gpt-3.5-turbo"
)
return result.choices[0].message.content
pipeline("Hello, world!")
LangSmithコンソール上で見ると以下のようになります。
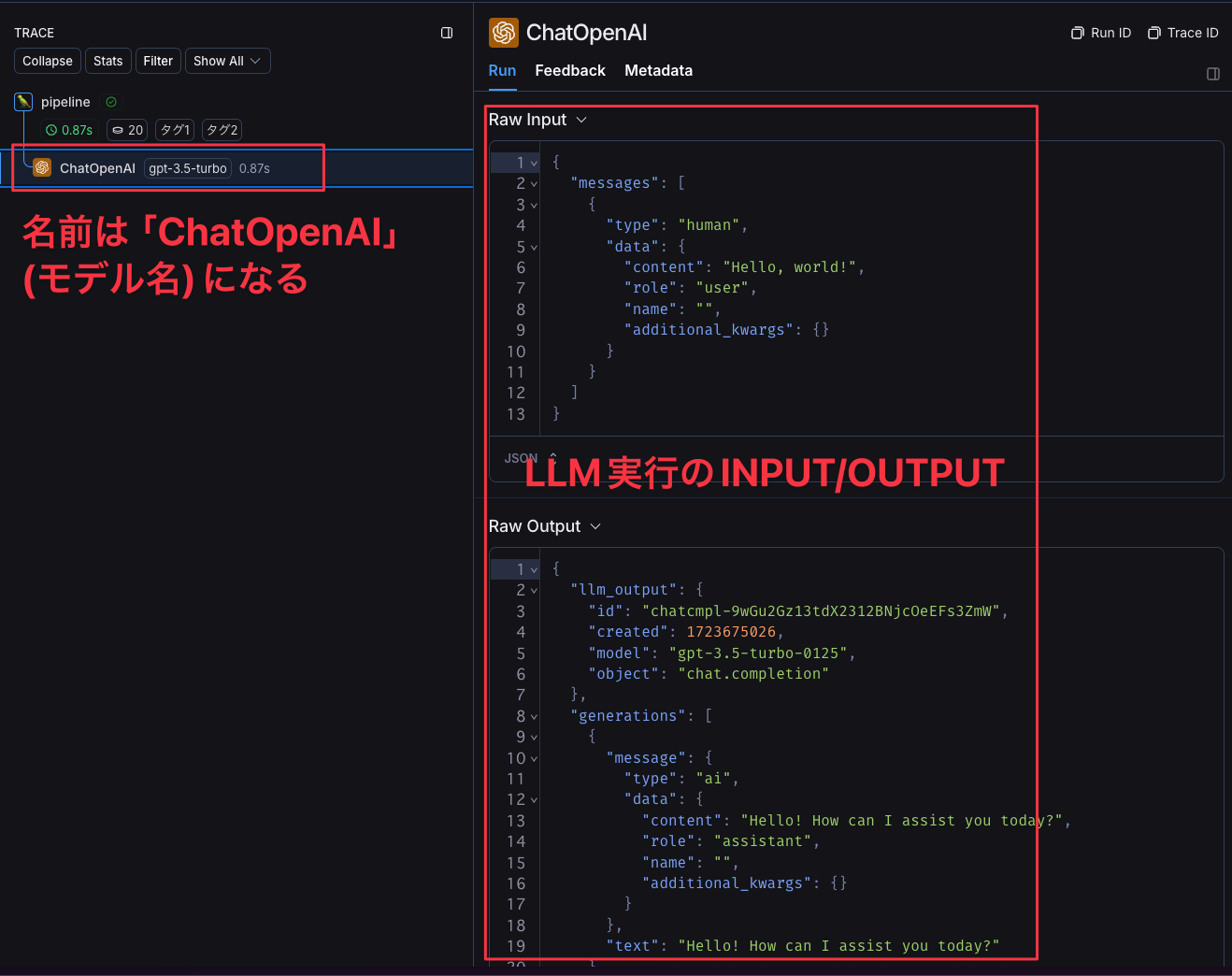
LLM実行のRun
Runを独自で定義する
RunTree クラスのインスタンスを作成することで、独自にRunを定義することが可能です。RunTreeを作成する際には、Runの名前や入力・出力(input/output)などの各種パラメータを自分で設定する必要があります。
例えば、先ほどの @traceable で実行したRunと同じような階層をRunTreeインスタンスで表現すると、以下のようなコードになります。
import openai
from langsmith import traceable
from langsmith.run_trees import RunTree
client = openai.Client()
def pipeline(user_input: str):
messages = [{"role": "user", "content": user_input}]
result = client.chat.completions.create(
messages=messages,
model="gpt-3.5-turbo"
)
# run_treeはネストするRunを作成できる
child = run_tree.create_child(
run_type="llm",
name="OpenAI Call",
inputs={"messages": messages},
outputs={"result": result}
)
child.post()
return result.choices[0].message.content
input = "Hello, world!"
# RunTreeクラスから独自のRunを作成
# input/nameも自分で定義できる
run_tree = RunTree(
run_type="tool",
name="pipeline",
inputs={"user_input": input},
)
output = pipeline(input)
# outputも自分で定義する
run_tree.end(outputs={"output": output})
run_tree.post()
メタデータとタグを設定する
Runには、メタデータやタグを設定することができます。@traceable を使用する場合、引数として tags や metadata を指定するだけです。
import openai
from langsmith.wrappers import wrap_openai
from langsmith import traceable
client = wrap_openai(openai.Client())
@traceable(
tags=["タグ1", "タグ2"],
metadata={
"metadata_key": "メタデータの値"
}
)
def pipeline(user_input: str):
result = client.chat.completions.create(
messages=[{"role": "user", "content": user_input}],
model="gpt-3.5-turbo"
)
return result.choices[0].message.content
pipeline("Hello, world!")
LangSmithのコンソールでは、Runのツリー構造上にタグが表示され、Run詳細画面の「Metadata」タブからメタデータを確認できます。
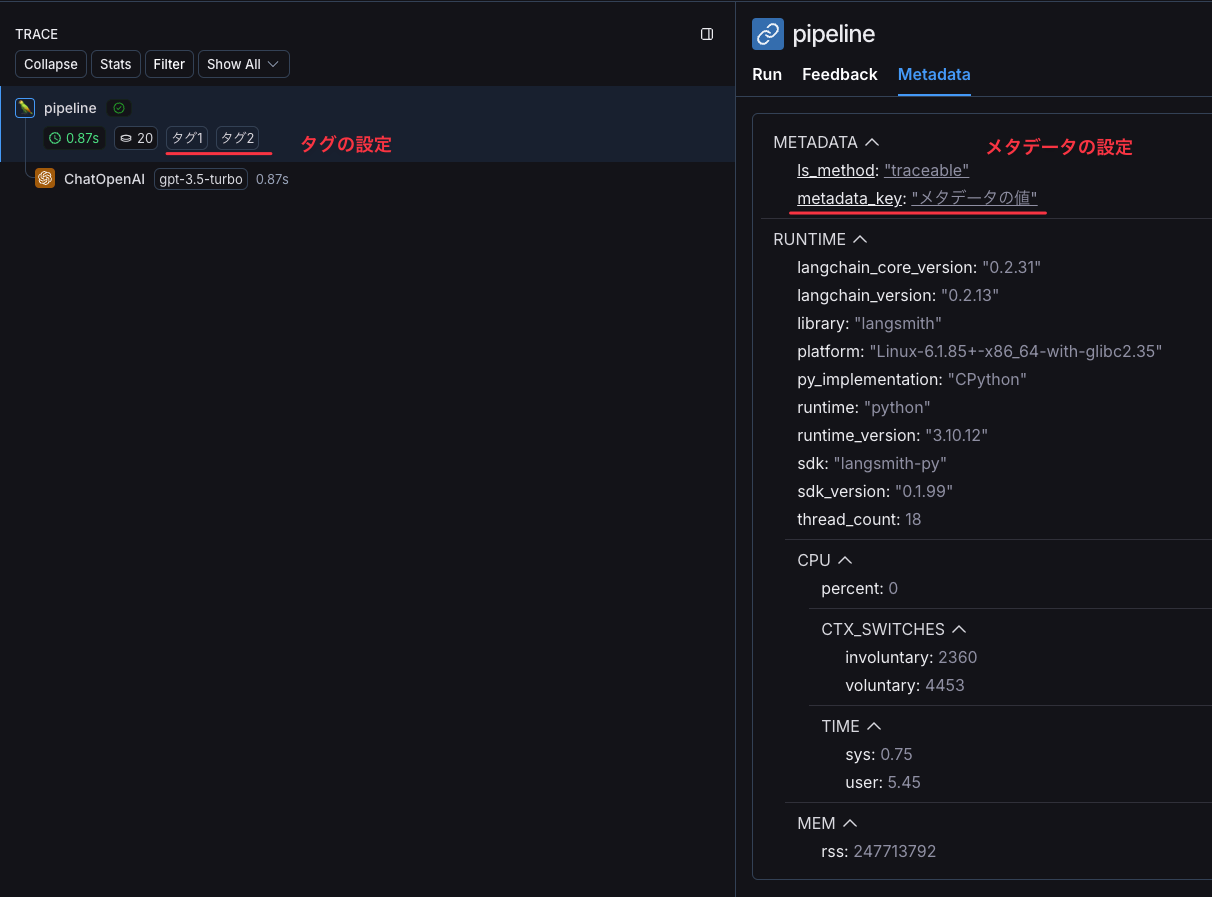
LangSmithコンソールでのタグ、メタデータの表示
Threads
トレーシングとは直接関係ありませんが、記録されたRunをチャットのスレッドのようなUIで確認できる「Threads」という機能があります。

Threadsタブ
この機能は、同じユーザーに対して複数ターンの会話(複数のRun実行)が行われる場合に、一連の会話の流れを確認するために使用されます。

一連の会話のように表示されるRun
Threadsを利用するには、RootのRunに対して次の特定のIDをメタデータとして追加する必要があります。
- session_id
- thread_id
- conversation_id
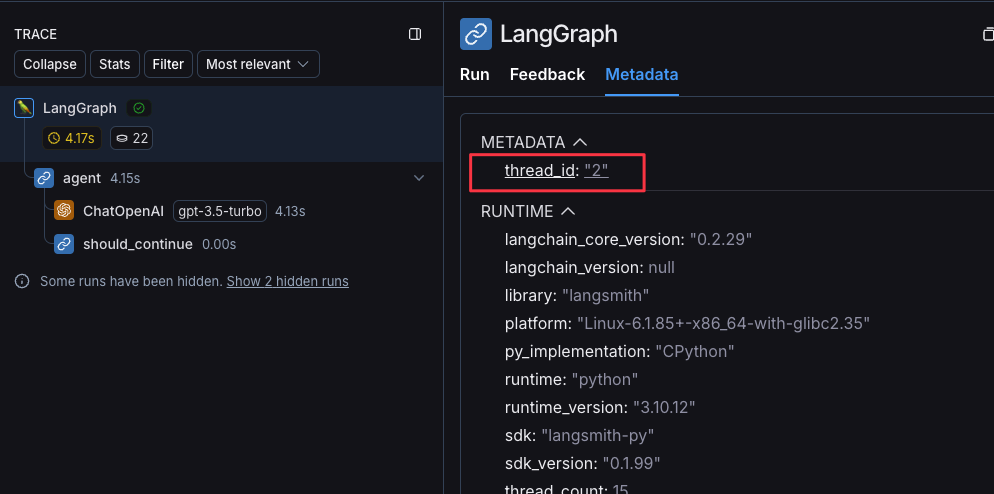
metadataにthread_idを設定することでスレッド表示されるようになる
会話のようなUIで可視化するためには、出力がLangChainの Messageフォーマットである必要があります。
LangChain SDKでMessageを直接出力する場合は問題ありませんが、出力を独自フォーマットで行う場合、そのままでは会話形式のUIにはならないため注意が必要です。
詳細なリファレンスは確認できませんでしたが、少なくとも以下のように、contentとtypeを持つメッセージ形式で出力する必要があるようです。
{
"messages": [
{
"content": "<会話として表示したい文字列>",
"type": "<human or ai>",
}
...
]
}
詳しくは、公式ドキュメントも参照ください。
LangGraphでトレース
LangGraphを使用している場合、前述した「環境変数の設定」を行うだけで、自動的にトレーシングが有効になります。
デフォルトの実行時の挙動
以下は、LangGraphのHow-to guidesで紹介されているサンプルコードです。
from typing import Literal
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.graph import StateGraph, MessagesState
from langgraph.prebuilt import ToolNode
@tool
def search(query: str):
"""Call to surf the web."""
if "sf" in query.lower() or "san francisco" in query.lower():
return "It's 60 degrees and foggy."
return "It's 90 degrees and sunny."
tools = [search]
tool_node = ToolNode(tools)
model = ChatOpenAI(model="gpt-4o", temperature=0).bind_tools(tools)
def should_continue(state: MessagesState) -> Literal["tools", "__end__"]:
messages = state['messages']
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return "__end__"
def call_model(state: MessagesState):
messages = state['messages']
# Invoking `model` will automatically infer the correct tracing context
response = model.invoke(messages)
return {"messages": [response]}
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.add_edge("__start__", "agent")
workflow.add_conditional_edges(
"agent",
should_continue,
)
workflow.add_edge("tools", 'agent')
app = workflow.compile()
final_state = app.invoke(
{"messages": [HumanMessage(content="what is the weather in sf")]},
config={"configurable": {"thread_id": 42}}
)
final_state["messages"][-1].content
このコードを実行すると、Runは次のように表示されます。

このように、LangGraphを使用すると、LLMの実行やツールの関数(search 関数)も自動的にトレーシングされます。
各Runの名前は、RootのRun名が「LangGraph」となり、LangGraphのNode名(__start__やagent)がRun名として記録されます。
また、ChannelWrite など、LangGraph内部でのStateの更新処理もRunとして記録されることが確認できます。
LangGraphのRun名を更新する
PharmaXでは、アプリケーションエンジニア以外もLangSmithコンソールを利用するため、LangGraphのRun名をより分析しやすいように独自に定義しています。
ここでは、LangGraphのデフォルト設定で使用されるRun名を更新する方法についていくつかご紹介します。
NodeのRun名
前述のとおり、LangGraphでは、Nodeの名前がそのままRun名として使用されます。そのため、Run名を変更したい場合は、Nodeの名前を変更することで対応しています。
...
graph_builder = StateGraph(State)
...
# Node名にわかりやすいRun名を定義する
RUN_NAME_START = "run名: start"
RUN_NAME_A = "run名: 機能1"
RUN_NAME_END = "run名: end"
graph_builder.add_node(RUN_NAME_START, start_node)
graph_builder.add_node(RUN_NAME_A, node_a)
graph_builder.add_node(RUN_NAME_END, end_node)
...
全てのコード
from langgraph.graph import StateGraph
from operator import add
from typing_extensions import TypedDict
from typing import Annotated
class State(TypedDict):
path: Annotated[list[str], add]
graph_builder = StateGraph(State)
def start_node(state: State) -> State:
return { "path": ["start_node"]}
def node_a(state: State) -> State:
return { "path": ["node_a"]}
def end_node(state: State) -> State:
return { "path": ["end_node"]}
# Node名にわかりやすいRun名を定義する
RUN_NAME_START = "run名: start"
RUN_NAME_A = "run名: 機能1"
RUN_NAME_END = "run名: end"
graph_builder.add_node(RUN_NAME_START, start_node)
graph_builder.add_node(RUN_NAME_A, node_a)
graph_builder.add_node(RUN_NAME_END, end_node)
graph_builder.set_entry_point(RUN_NAME_START)
graph_builder.add_edge(RUN_NAME_START, RUN_NAME_A)
graph_builder.add_edge(RUN_NAME_A, RUN_NAME_END)
graph_builder.set_finish_point(RUN_NAME_END)
graph = graph_builder.compile()
graph.invoke({"path": []}, debug=True)
LangSmithコンソールでの表示は以下のようになります。

RootのRun名
LangSmithのRootのRun名はコンソール上で一覧表示されるため、PharmaXでは「機能名」を付けるようにしています。しかし、LangGraphを実行するとRootのRun名が「LangGraph」になってしまうため、こちらも修正が必要です。

RootのRun名は、LangGraphをinvokeする際に、引数として config に run_name を渡すことで上書きできます。
...
graph = graph_builder.compile()
graph.invoke({"path": []}, config={"run_name": "RootのRun名: 機能①"})
...
全てのコード
from langgraph.graph import StateGraph
from operator import add
from typing_extensions import TypedDict
from typing import Annotated
class State(TypedDict):
path: Annotated[list[str], add]
graph_builder = StateGraph(State)
def start_node(state: State) -> State:
return { "path": ["start_node"]}
def node_a(state: State) -> State:
return { "path": ["node_a"]}
def end_node(state: State) -> State:
return { "path": ["end_node"]}
# Node名にわかりやすいRun名を定義する
RUN_NAME_START = "run名: start"
RUN_NAME_A = "run名: 機能1"
RUN_NAME_END = "run名: end"
graph_builder.add_node(RUN_NAME_START, start_node)
graph_builder.add_node(RUN_NAME_A, node_a)
graph_builder.add_node(RUN_NAME_END, end_node)
graph_builder.set_entry_point(RUN_NAME_START)
graph_builder.add_edge(RUN_NAME_START, RUN_NAME_A)
graph_builder.add_edge(RUN_NAME_A, RUN_NAME_END)
graph_builder.set_finish_point(RUN_NAME_END)
graph = graph_builder.compile()
graph.invoke({"path": []}, config={"run_name": "RootのRun名: 機能①"})
LangSmithコンソールでの表示は以下のようになります。

LLM実行のRun名
LangGraphでは、LLMの実行も自動的にトレースされますが、Run名にはLLMのモデル名が自動で付与されます。

OpenAIのモデルを使った場合は「ChatOpenAI」というRun名になる
LLM実行のRunに任意の名前を付けたい場合は、with_configメソッドを使ってRun名を上書きすることが可能です。
...
model = ChatOpenAI(temperature=0).with_config(
run_name="Rum名: LLM ①の実行",
)
...
全てのコード
from langgraph.graph import StateGraph
from operator import add
from typing_extensions import TypedDict
from typing import Annotated
from langchain_openai import ChatOpenAI
class State(TypedDict):
path: Annotated[list[str], add]
graph_builder = StateGraph(State)
model = ChatOpenAI(temperature=0).with_config(
run_name="Rum名: LLM ①の実行",
)
def start_node(state: State) -> State:
return { "path": ["start_node"]}
def node_a(state: State) -> State:
model.invoke("こんにちは!")
return { "path": ["node_a"]}
def end_node(state: State) -> State:
return { "path": ["end_node"]}
RUN_NAME_START = "run名: start"
RUN_NAME_A = "run名: 機能1"
RUN_NAME_END = "run名: end"
graph_builder.add_node(RUN_NAME_START, start_node)
graph_builder.add_node(RUN_NAME_A, node_a)
graph_builder.add_node(RUN_NAME_END, end_node)
graph_builder.set_entry_point(RUN_NAME_START)
graph_builder.add_edge(RUN_NAME_START, RUN_NAME_A)
graph_builder.add_edge(RUN_NAME_A, RUN_NAME_END)
graph_builder.set_finish_point(RUN_NAME_END)
graph = graph_builder.compile()
graph.invoke({"path": []}, debug=True, config={"run_name": "RootのRun名: 機能①"})
with_config は、Runnable に対して設定情報を付与できるメソッドで、このメソッドの run_name パラメータに任意の名前を設定することで、Run名を上書きすることができます。
LangSmithのコンソールで確認すると、以下のように表示されます。
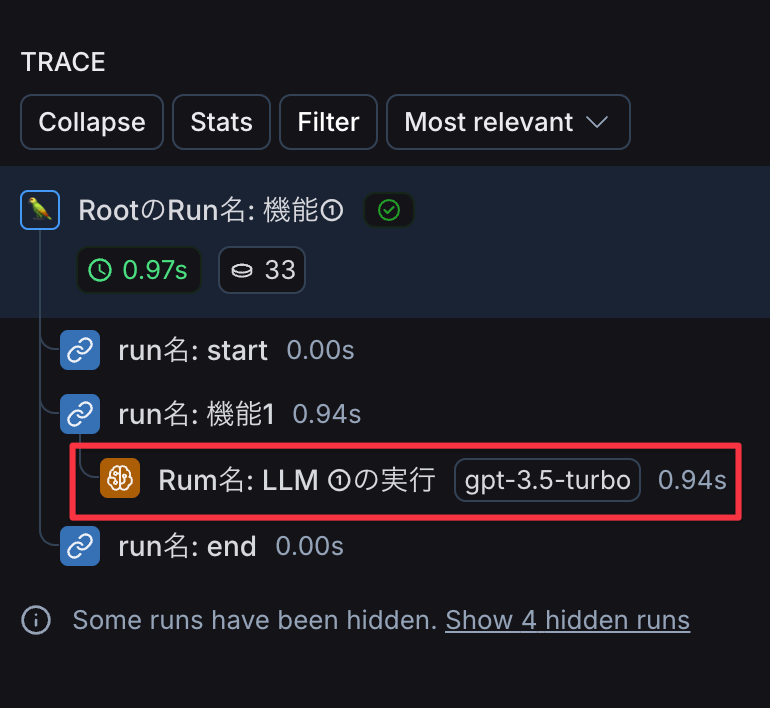
現在のRunの情報を取得する(get_current_run_tree)
get_current_run_tree という関数を使用すると、現在のRunTreeインスタンスを取得できます。PharmaXでは、この関数を使って、特定のRunに対し、Runの実行中にメタデータや入力/出力(Input/Output)の更新を行っています。
from langsmith import get_current_run_tree
...
def node_a(state: State) -> State:
# 現在のrunを取得
run = get_current_run_tree()
# runは取れない場合もある
if run is not None:
# add_metadataメソッドを使用して、メタデータを追加
run.add_metadata({"メタデータキー": "12345"})
...
全てのコード
from langgraph.graph import StateGraph
from operator import add
from typing_extensions import TypedDict
from typing import Annotated
from langchain_openai import ChatOpenAI
from langsmith import get_current_run_tree
class State(TypedDict):
path: Annotated[list[str], add]
graph_builder = StateGraph(State)
model = ChatOpenAI(temperature=0).with_config(
run_name="Rum名: LLM ①の実行",
)
def start_node(state: State) -> State:
return { "path": ["start_node"]}
def node_a(state: State) -> State:
# 現在のrunを取得
run = get_current_run_tree()
# runは取れない場合もある
if run is not None:
# add_metadataメソッドを使用して、メタデータを追加
run.add_metadata({"メタデータキー": "12345"})
model.invoke("こんにちは!")
return { "path": ["node_a"]}
def end_node(state: State) -> State:
return { "path": ["end_node"]}
RUN_NAME_START = "run名: start"
RUN_NAME_A = "run名: 機能1"
RUN_NAME_END = "run名: end"
graph_builder.add_node(RUN_NAME_START, start_node)
graph_builder.add_node(RUN_NAME_A, node_a)
graph_builder.add_node(RUN_NAME_END, end_node)
graph_builder.set_entry_point(RUN_NAME_START)
graph_builder.add_edge(RUN_NAME_START, RUN_NAME_A)
graph_builder.add_edge(RUN_NAME_A, RUN_NAME_END)
graph_builder.set_finish_point(RUN_NAME_END)
graph = graph_builder.compile()
graph.invoke({"path": []}, config={"run_name": "RootのRun名: 機能①"})```
おわりに
以上、LangSmithのトレーシングについての基本的な使い方と、弊社での事例をご紹介しました。
LangSmithを活用することで、LLMの実行だけでなく、業務フロー全体の可視化が容易になり、デバッグや問題の早期検知がスムーズになりました。
さらに、関連するメタデータもLangSmith上に集約されるため、データ分析フローがシンプルになり、今のところ導入に対して非常に満足しています。
PharmaXでは、様々なバックグラウンドを持つエンジニアの採用をお待ちしております。弊社はAI活用にも力を入れていますので、LLM関連の開発に興味がある方もぜひ気軽にお声がけください。
興味をお持ちの場合は、私のXアカウント(@hakoten)や記事のコメントにお気軽にメッセージをいただければと思います。まずはカジュアルにお話できれば嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion