こんにちは。PharmaXの上野(@ueeeeniki)です。
PharmaXでは、YOJOというサービスで複数のLLMエージェントを組み合わせたマルチエージェントの構成でチャットボットシステムを構築しています。
本日は、そんなPharmaXのLLMプロダクト開発で学んだエージェント設計の原則をまとめてみたいと思います。
これまでLLMプロダクト開発に関する知見を様々なところで公開してきました。
YOJOのマルチエージェントの仕組みは下記の記事をご覧いただければと思います。
LLMアプリケーションのアーキテクチャについてまとめた資料もあります。
このあたりで、エージェントの設計のコツを一度まとめて置こうという意図です。
LLMエージェント設計原則まとめ
PharmaXで培ったLLMエージェントの設計原則をまとめると以下のようになります。
- RAGは本当に必要な時のみ使う
- エージェントがこなすタスクはできる限り小さく単一にする
- エージェントの出力を次のエージェントの入力に使う直列構造はできる限り避ける
- 無理してエージェントでやり切ろうせず、必要があれば人を介在させる
何を言っているかはなんとなく想像が付くと思いますが、詳しくご説明していきます。
弊社内での学びではありますが、LLMエージェントを扱っている多くの企業で参考になる内容だと思っています。
さっそく各原則を深堀って行きたいのですが、その前に簡単に弊社のサービスの概要を説明します。
YOJOのLLMマルチエージェント・アプリケーションの概要
PharmaXでLLMマルチエージェントのアプリケーションを構築してる、YOJOというサービスを簡単にご説明します。
PharmaXのYOJOというサービスは、LINEで薬剤師に相談をして医薬品を購入できるというtoCサービスです。
詳細は省きますが、メインで扱っているのは、処方箋が必要な処方薬ではなく、処方箋が不要なOTC医薬品です。
PharmaX内には、ユーザーである患者さんからの質問にチャットで答える薬剤師が多数在籍しています。
PharmaXは薬局にシステムを販売するのではなく、直接患者さんに医薬品を販売するオンライン薬局であり、薬剤師の方々はPharmaXに所属しています。
今回例として取り上げるLLM機能は、薬剤師がチャットするメッセージ内容をサジェストします。
下記が薬剤師メンバーが使うチャット画面です。
(ローカル環境での私自身との会話画面なのでセンシティブな情報は含みませんが、画面の一部をマスクしていることをご了承ください。)
患者さん(ユーザー)からメッセージを受信したタイミングでLLMによる返信のサジェストが作られます。
サジェストされた内容を薬剤師が確認し、必要があれば修正して送信します。
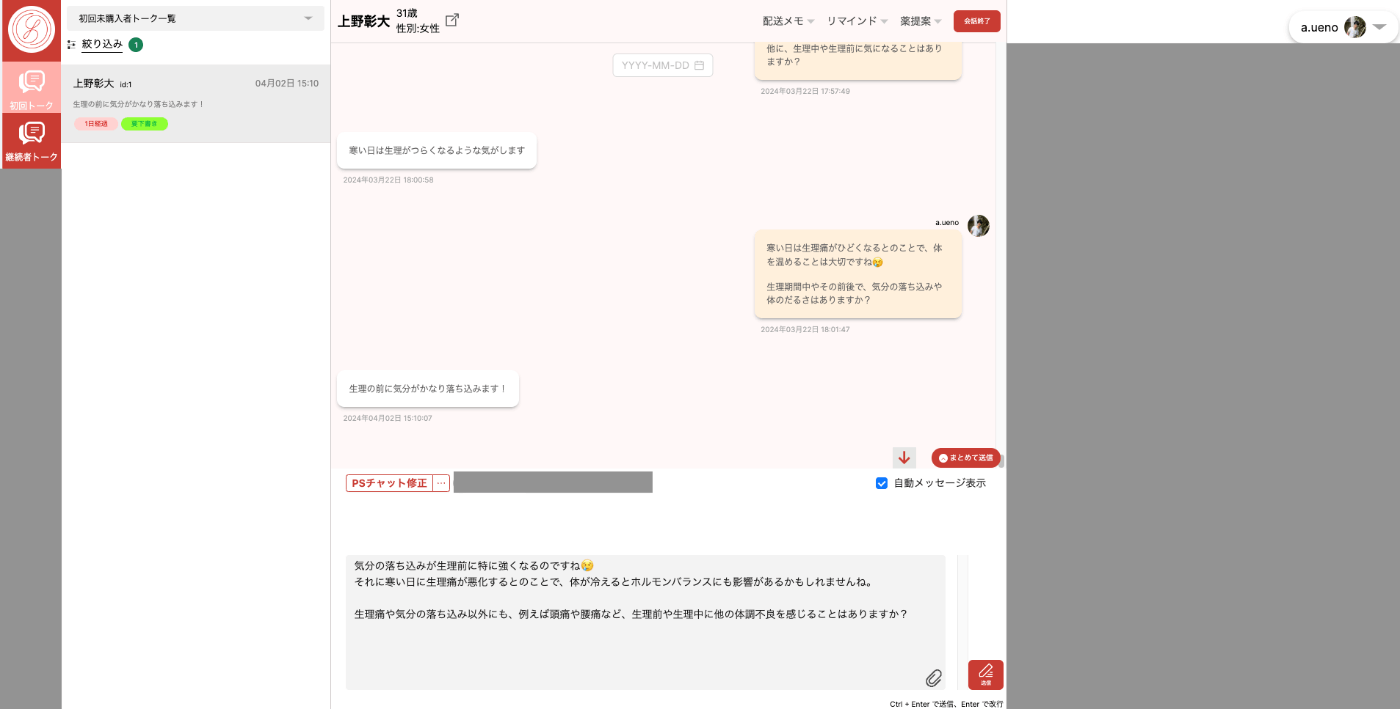
薬剤師が患者さんの状態を確認しつつ、チャットするための管理画面
詳細は省きますが、現在では、LINE登録〜購入までの流れのかなりの割合が薬剤師の修正なしで、承認するだけで送信することができています。
それでは早速各原則を詳しくご説明いたしましょう。
RAGは本当に必要な時のみ使う
登壇やイベントに出席するとよく質問される質問にRAGはどうしていますか?やRAGはどうやって精度向上させていますか?というものがあります。
しかし、実はPharmaxでは、RAGを「全く」活用していません。
YOJOはユーザーからの医学的・薬学的な質問に答えることもあれば、YOJOのサービス自体の質問や購入に関する質問などに答えなければならないので、RAGを使っているはずだと考えて、このようにご質問いただくのでしょう。
ですが、個人的にはあまりRAG、つまり検索の精度には期待していません。
正確言うと、近いうちにどこかのタイミングでプロダクション実用レベルになると思っていますが、今はまだ工夫によって検索精度を向上させるのは難しいと考えているということです。
頑張って工夫したところで、大して精度が向上しないのでコスパが悪く、代替手段を積極的に採用すべきではないか?と考えていると言い換えてもいいかもしれません。
もちろん、本当にRAGが必要なサービスもあります。
そのようなサービス以外は、RAGを使うのはできる限り避けた方がいいのではないか?というのがここでお伝えしたいことです。
ではYOJOでは、RAGを使わずにどうやってLLMエージェントの知らない知識を与えているのでしょうか。
簡単に言えば、質問に対して関連情報を取得してプロンプトに与える(RAG)のではなく、タスクごとに必要なマニュアルをすべて与えたプロンプトを作成しています。
例えば、配送料のことを聞かれた場面では、配送料以外にも配送会社や配送日数、解約期日なども含む配送に関連し得るFAQ系のマニュアルをすべて与えたプロンプトを呼び出しています。
アーキテクチャを比較すると下記のような図になります。
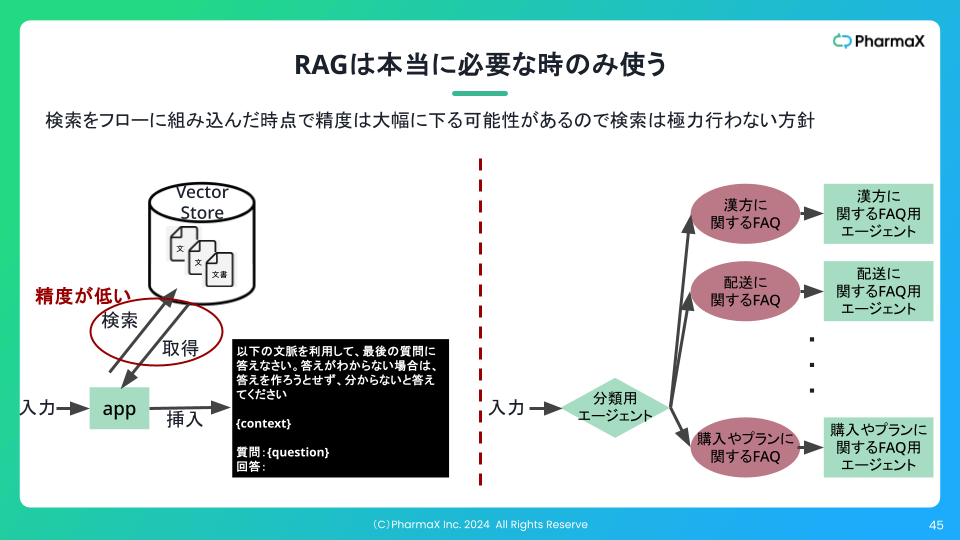
左がRAGで、右がYOJOで採用している会話分類でエージェントを呼び分けるアーキテクチャです。
右のアーキテクチャでは、まず分類用のLLMエージェントで会話のタイプを分類し、その結果によって次に呼ぶメッセージ作成のエージェントを呼び分けます。
この場合は、会話分類をLLMで行う方が、質問があるたびにRAGを行って情報を取得するよりも平均的な精度は高いのではないか?ということです。
実際には、会話分類の精度を高めるプロンプトの労力と検索精度向上の労力のどっちが大きいのかを見極めて判断すると良いでしょう。
ただし、YOJOにおいてもあり得るすべての会話パターンを分類しているとキリがないので、フェーズという概念を導入し、フェーズごとにあり得る会話分類の数を絞ることで会話分類の精度を向上させるといったた工夫は行っています。
(ここではこれ以上のフェーズの詳細には立ち入らないこととし、別の記事で解説します。)
確かに、直接は関係ない内容も含めてマニュアルをすべてプロンプトに与えれば、当然、RAGを行うよりはトークン数も大きくなり、スピードは遅くなりやコストは上がってしまいます。
ですが、現在の(もしくは今後の現れる)LLMは、扱えるコンテキストも大きく、コストも低くなっているので、十分ペイできるラインに到達しつつあると感じます。
エージェントがこなすタスクはできる限り小さく単一にする
これは下記のフローエンジニアリングの記事でも述べましたが、あまり多くのタスクをプロンプトに詰め込んでしまえば、精度と保守性を低下させます。
あるタスクを1つのLLMエージェントですべて解かせるのではなく、そのタスクを細分化して、エージェントやアプリケーションの実装を組み合わせて解いていく、フローエンジニアリングを実践すべきです。
RAGは本当に必要な時のみ使うで説明した、LLMエージェントの分類結果によって次のLLMエージェントを呼び分けるというアーキテクチャもシンプルなフローエンジニアリングの例です。
確かにフローエンジニアリングは、実装コストは高くなります。
ですが、プロンプトを小さくすることで、コストを小さく、スピードを速く、精度も高くできるので、
処理系全体としては、コントロールしやすくなります。
こちらの記事でも「1つのことをうまく行う小さなプロンプトを作る」という同じ原則が紹介されています。
エージェントの出力を次のエージェントの入力に使う直列構造はできる限り避ける
これは、一言で言えば、LLMの出力を次のLLMの入力に入れるということを繰り返してはならないということです。
できれば1直列までに留めておきたいところです。
これまで何度も登場している、LLMエージェントによる会話を分類の結果をもとに文章作成LLMのエージェントを呼び分けるというアーキテクチャは、出力を次のLLMの入力に使っているわけではないので、
このパターンには当てはまりません。
もちろんこのアーキテクチャでも、処理系全体が複雑になりすぎれば、扱いづらくはなっていくので注意は必要ですが。
特に避けるべきは、あくまでLLMの出力を別のLLMの入力に使う構造の連鎖だということです。
LLMの出力を別のLLMの入力に使う一番よくある例は、いわゆるLLM as a Judgeとも呼ばれるLLMによう評価ではないでしょうか。
LLM as a Judgeは、LLMの出力をLLMに入力して評価するので、1直列の例であり、この原則的には問題はありません。
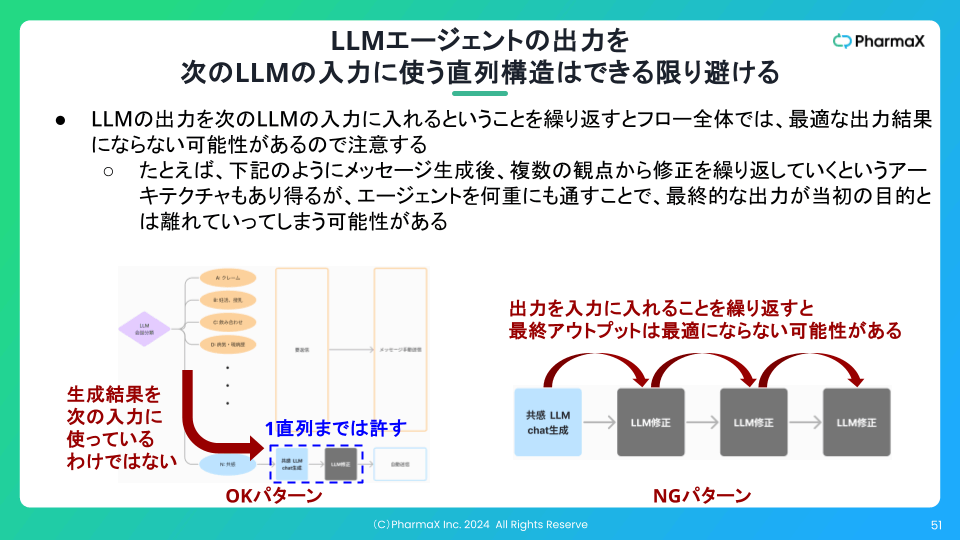
直列構造が複数続く場合には注意が必要です。
例えば、チャットサービスでメッセージ生成後、より良いメッセージ作りたいがためにそのメッセージを繰り返し修正するというパターンを考えます。
複数の観点からの修正を繰り返すことで、最終的な出力が当初の目的とは離れていってしまう可能性があります。
人の仕事も色んな人の間を伝言されて、変更されていくうちに当初のアウトプットの良さが全くなくなっていたということがあるでしょう。
LLMエージェントの出力をまた別のLLMエージェントの入力に使ってしまうことを繰り返していくうちに、毎回エージェントによって局所最適が行われて、全体最適の視点を失っていきます。
全く同じことが書いてるだけですが、私の登壇資料からも引用しておきます。
無理してエージェントでやり切ろうとせず、必要があれば人を介在させる
これも読んでいただければご理解いただけるでしょうが、LLMアプリケーションでフローエンジニアリングを行っている場合は、すべての処理をLLMでさせる必要はありません。
むしろどこに人を介在させるかを判断するのが、LLMアプリケーションのアーキテクトの腕の見せどころです。
特定のケースでLLMに上手く処理できなかったり、ハルシネーションすることを恐れて何もしないよりは、躊躇なく人間に任せて行きたいところです。
また、単純にあまり頻度の高くないケースにLLMで対応させるためのプロンプトエンジニアリングやアプリケーション実装のリソースが足りないのであれば、人に任せてしまうことも一案です。
YOJOの例でも、医学的に難しいタイプの会話に分類され、あまり頻度高く来ないような会話のパターンは、LLMでメッセージをサジェストせずに初めから人が対応します。
下図のように会話分類して、その結果にもとづいてLLMがメッセージをサジェストするのかを決めています。

図の分類は、あくまでイメージですが、実際に薬剤師に任せている分類でプロンプトを作ることが特段難しいと考えているか?と問われれば、実はそうではありません。
そもそもYOJOの場合は、どのみち薬剤師が修正できるので、完璧な精度でメッセージをサジェストしなければならないわけではありません。
ただ、会話分類のエッジケースを埋めることの優先順位を下げているだけです。
最初から完璧なLLMアプリケーションを作ることを目指してしまうといつまで経ってもリリースできないという事が起こります。
多少、処理時間がかかっても人が介在して処理したり、素直に答えられないことを認めてしまうケースがあってもいいでしょう。
まとめ
今回は、私たちがYOJOというプロダクトで実践してきたLLMエージェント設計の原則をまとめてみました。
他にも言語化できていないことはあるようにも感じますが、一番気をつけていることはシェアすることができたのではないかと思います。
実は登壇の中では何度かお話したことのある内容だったのですが、資料やアーカイブ動画が公開されていないこともあり、記事にもまとめてみました。
LLMアプリケーション開発をされている方の参考になれば嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion