大規模言語モデル向けプロセッサ回路の構成に関する考察
生成AI Advent Calendar 2023 いろいろなコンピューター Advent Calendar 2023 11日目の記事です。
概要
Microsoft,Amazonなど大手TI企業から大規模言語モデル(LLM)向けの専用半導体が発表され、脚光を浴びています。
やや遅きに失した感はありますがここではLLM向けハードウェア実現に関してエッジ、サーバーで必要になりそうな要素技術を挙げ、構成例を紹介します。
位置づけと用途
大手IT企業(Google, Amazon, Microsoftなど)は既存のNvidia GPUによる数百万プロセッサで構成されるクラウド環境に加えて独自プロセッサ開発を行っています。
このような巨大企業によって提供されるサービスとしてのLLMは学習のデータ収集、データ並列、パイプラインの意味でスケールするので今後も巨大化が進みそうです。
一方で独自データ使用や学習推論結果の安定性、通信環境の観点からローカルLLMは需要がありそうです。計算規模と用途を一列に並べると下図のようになると思われます。
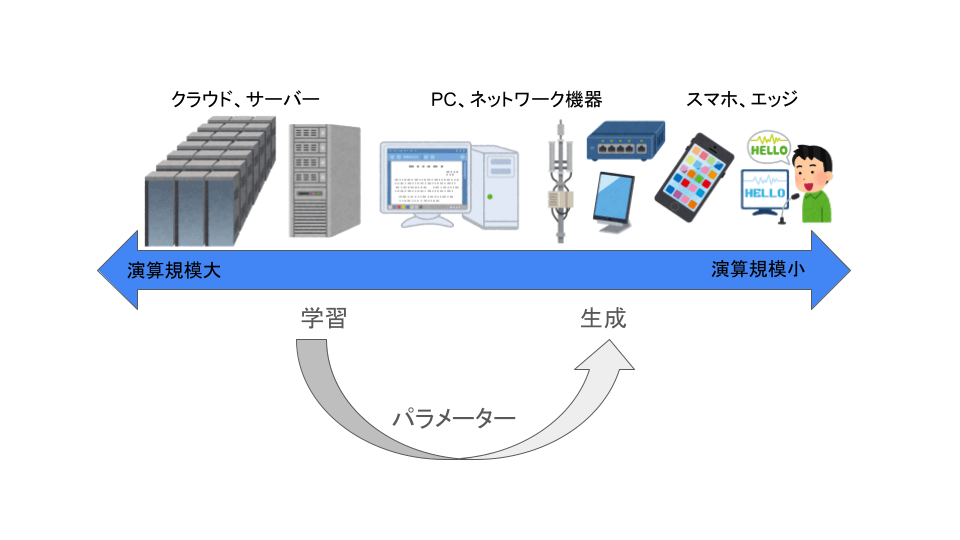
一般に学習には生成よりも大きな演算規模とデータ転送帯域が必要になります。それぞれに対して異なったアーキテクチャが必要となりそうです。
Stable Diffusion専用プロセッサのアーキテクチャに関する試論とChiselコードではStable Diffusionでの動画変換(image to image)の場合はストリーミング処理が要求され、また拡散モデルの同じネットワークを複数回適用するという特性から演算回路を直列に並べる方法が有効でした。しかしLLMでの推論(テキスト生成)のパイプライン処理は複数のプロンプトが異なるクライアントからやってくるようなサーバーでの用途では効果がありますが、単体ではあまり有効ではありません。
学習の計算は推論を含むような形なので現在普及しているように同じ場所(クラウド)で実施し、ネットワークを介してプロンプトを受け取って結果を送信する方法が複数の異なる人からのプロンプトをパイプラインで処理することができて効率的です。
主要なLLMのネットワーク構造
前提として現在MegatronやGPT,Llamaなど多くのLLMでは下図のようにmulti head attention(注意機構), MLP(Multi layer perceptron)の単位transformerを直列に繰り返しつなぎ合わせるネットワークが使われています。
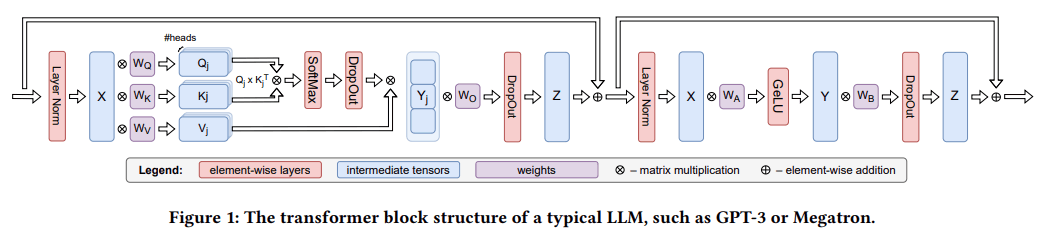
前半がmulti head attention、後半がMLPです。multi head attention内のQ,K,Vの行列演算は並列に実行でき、遠くの層の情報を使うresidual connectionはattention block内で完結しています。これらのネットワークはONNXで記述可能でパソコンのGPU,CPUでの推論処理が実際に行われています。ローカルでも使える規模のサイズと話題のLllamaのONNXはここにあるようです。
学習工程
foward/backward処理のタイムチャート
ニューラルネットの学習プロセスは学習データを用いて誤差関数を計算するforwardとその結果から重みパラメーターの更新量を計算するbackwardからなります。
pytorchのコードで書くと
for epoch in range(num_epochs):
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
のoutputs = net(inputs), loss = criterion(outputs, labels)がforward,loss.backward()がbackwardにあたります。
forwardでは入力データに層ごとに順々にパラメーターを行列積や畳み込み積の形で掛け合わせていき、最後にラベルデータとの間の誤差関数(ここではcriterion)を計算します。backwardではその逆に計算された誤差から層を遡ってforwardで計算される層の出力とパラメーターの微分値を計算します。
Transformerで使われる行列ベクトル積(全結合層)のbackwardの計算は層の入力を
となり誤差(loss)関数Lのxによる微分は出力yにによる微分を用いて
と書かれ、バックプロパゲーションにおいて層の上流へ送られる値と、重みパラメーターの更新値dx,dWの計算はpythonコードで書くと
def backward(self,dout):
self.dx =dout @ self.W.T
self.dW =self.x.T @ dout
return self.x
となります。
多層のニューラルネットのバックプロパゲーションにおいて計算がどのような順序で実行されるかは「ゼロから作るDeep Learning」の5章誤差逆伝搬法の記述とpythonコードがわかりやすいです。
学習におけるタイミングチャートはEfficient large-scale language model training on GPU clusters using megatron-LMに挙げられています。
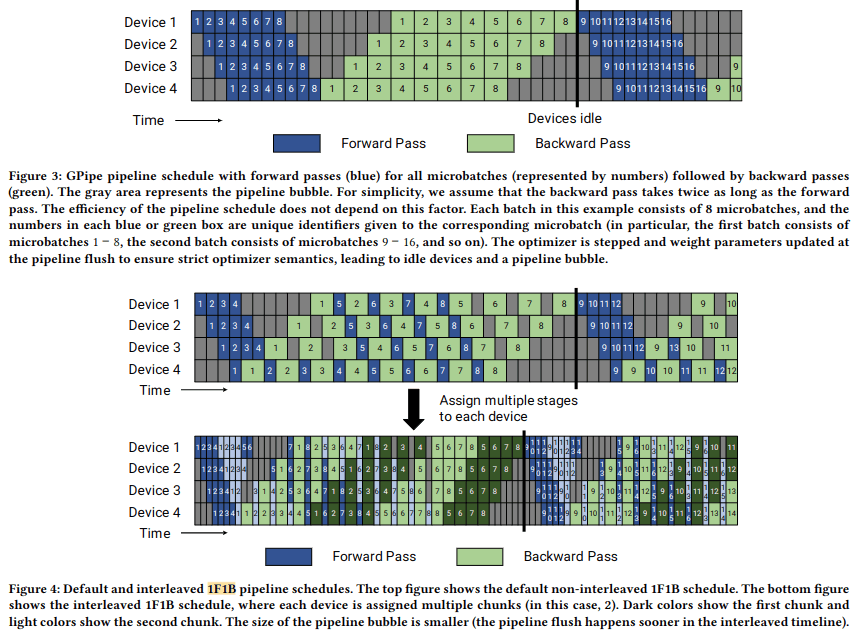
これは複数GPUの並列動作を書いたものであり、そのまま(理想的には)1チップ内の複数コアに当てはめることができると思われます。複数の列が複数のGPUによる並列化を表していますがそれに関して以下で説明します。
並列化
foward/backward処理を並列処理する方法として
- データ並列化(ミニバッチ並列化)
- パイプライン並列化
- テンソル並列化
があります。
データ並列化は同一のモデル(ネットワーク)に対して異なるデータによる学習を異なる並列処理の単位に割り振るものでバッチ処理を並列化(ミニバッチ並列化)したものと言えます。
パイプライン並列化はforward,backwardの処理の各層、あるいはそれより細かい段階を異なる並列処理の単位に担当させるものです。上記のタイムチャートでは同じ番号の四角が同一のネットワーク、データに対する処理の各層を順番に行っているものを指し、各々のDeviceはそれぞれ異なる層を担当していることになります。
テンソル並列化は1つのモデル内の行列、テンソル演算を分割して複数の並列処理の単位に割り振るものです。
これらは でGPUを用いた分散学習の観点から詳しく解説されています
また複数GPUを用いる場合のハードウェアとの対応関係が以下の図に3次元でわかりやすく示されています。
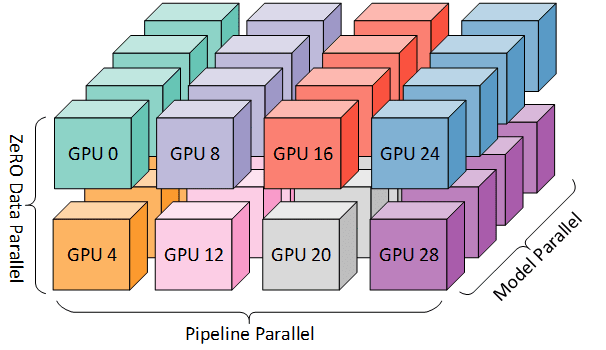
DeepSpeed: Extreme-scale model training for everyoneより引用
この構造を1チップ、1パッケージに納めることはできるのか、そして意味があるのでしょうか。単純に複数GPUの機能を1つのチップあるいはダイにすればよいだけにも思えます。またNvidiaが行えばよくこの後の話はなくて良くなります。そうではなくLLMに特化した場合に機能を取捨選択すべきというのが本文の趣旨になります(Nvidiaのアーキテクチャも単純に前世代をシュリンクして並べたものではなくCUDAからの見え方を保っているようです。)
Calculon論文ではこれらの並列化技術がグループごとに並べられています。
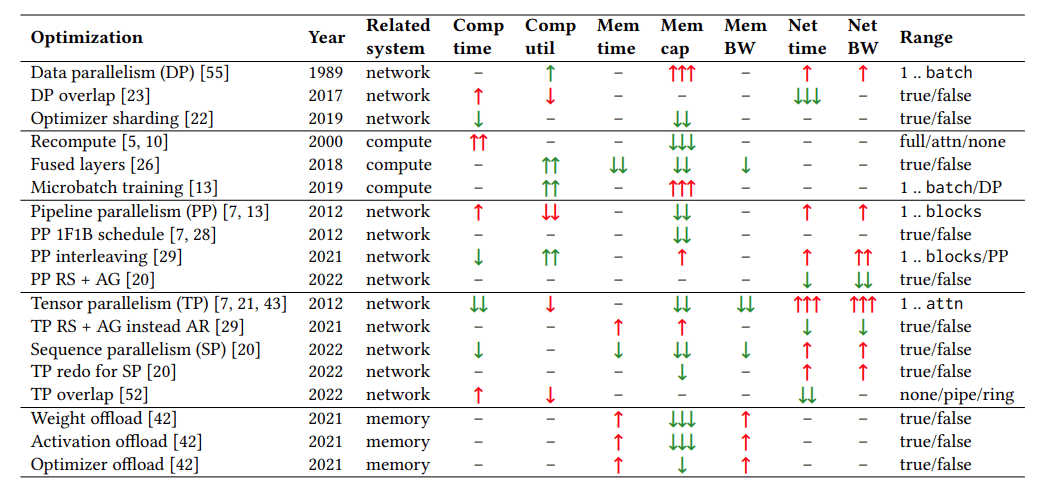
Data parallelism, Pipeline parallelism, Tensor parallelilsmの他に活性化関数の処理を必要になったときに行うrecompute,fused layersのグループとoffloadのグループがあります。recomputeはbackwardで必要になる計算値をfowardの時のものを取っておくのではなく再計算して得ることでメモリ量を節約するものです。offloadで出てくるZeRO(Zero Redundancy Optimizer)は重みを分割して比較的大きなCPUのメインメモリに重みパラメーターを置き、GPUでの計算に先立ってロードを行う手法のようです(日本語資料)。
データ並列化
同一のモデル(ネットワーク)を異なる並列処理の単位で計算し、重みパラメーターの更新値を同期します。
各部分で計算された重みパラメーターの勾配を集約(aggregate)する処理が必要になりそこで並列計算を同期させる必要が出てきます。
パイプライン並列化
多層ニューラルネットの1層あるいはそれより細かい単位を一つの並列処理の単位に担当させます。
前の並列処理の単位からもらった値を計算に用い、あとの並列処理の単位に渡します。
学習、あるいは生成用のデータが連続的に入力されることが効率化の前提となります。
テンソル並列化
Transformerの場合は行列行列積(GEMM)が計算の大半を占めます。Multi head attentionのそれぞれを別のプロセッサで計算させること、あるいは一つの行列積計算を分割して複数のプロセッサに計算を担当させる方法です。入力となるパラメーターの共有が必要となります。例えば下図のように行列行列積を2つのプロセッサで並列に行うのであれば行列Aの上半分、下半分を2つのプロセッサにコピーし、行列Bの左右を分割してそれぞれを2つのプロセッサに配分する方法があります。
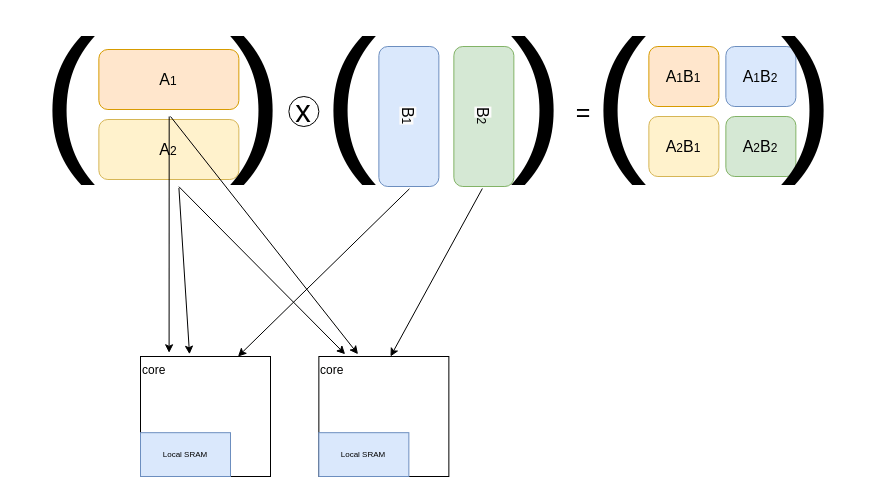
ベクトルプロセッサでの行列ベクトル積、行列行列積の方法はスパコンプログラミング入門で詳しく書かれています。
設計、評価の方針
ハードウェアの並列性を生かしたプロセッサの方向性として
- 特定のアプリケーションに特化して電力性能、速度を重視する
- プログラマビリティー、移植性を高める
があると思います。前者は特定のネットワークを特定の繰り返し方で実行できれば良いという考えで動作は単純なステートマシンで記述され、メモリはネットワークの構造や並列プロセッサ間の共有などの用途専用のものが用意されます。後者は単体でソフトウェアの実行が可能な汎用プロセッサを並べ、キャッシュコヒーレンスを保つようにするな構成方法が考えられます。
前者の方向を追求するとするとすると上記のような特定のTransformerネットワークの繰り返しに特化するのであればその1単位を並列化の単位とするのがもっとも効率的に見えます。
逐次的な実行から外れるResidual構造もself attentionの中で完結しています。しかしTransformerの計算で使われる行列は数千x数千になる大規模なもので
演算精度を固定することができれば演算回路節約ができるように思えますが、より大きなビット幅の演算機はより小さな演算器を含むのでその効果は小さそうです(FP32に固定すればFP64は不要になります。)
Calculon論文では4096個のNVIDIA A100を使った場合の異なるテンソル、データ、パイプライン並列性に対する学習時間、使用メモリ、コスト(価格)をシミュレートしています。
構成例
(メモリを除いて)学習回路全体を1つのチップで完結させようとする場合は下図のように
- 行列、活性化関数、dropoutなどの計算をするcore
- tensor, pipeline並列化を行うcore group
- data並列化の単位、異なるmodelの処理単位となりうるcore groups
- 計算途中の値を保存するlocal RAM, パラメーターを保存するL1,L2の3階層のSRAM,DRAM
- ストレージ、DRAMから学習、推論用データを取り込むdata loader
- 取り込んだデータをベクトル形式に変換するdata converter
- コントローラー
で構成される回路を考えることができます。

動作はforwardの場合図の上の方から下へとloadした
backwardの場合はforwardで使ったパラメーターWの値が残っている場合はそれをLocal SRAMに バッチごとに計算したデータをforwardとは逆方向、図の上の方のcoreに転送していきます。
core内には積和演算器とテンソル要素ごとの平方根、割り算などの演算器、計算結果の行列を記録するレジスタ(実装はRAMかもしれない)を持ちます。1つのcoreが担当する演算、パイプラインの粒度は LLMの繰り返し構造である1つのtransformerとMLPにするのが自然です。それよりも細かい行列行列積の単位とするとMulti head attentionの部分の並列化が効率的にできますがパイプラインの各段で行列積を担当するもの、softmaxやdropoutを担当するものなどが出て負荷がアンバランスになってしまいます。パイプラインはもっとも負荷の大きい演算ステップに律速されます(Stable Diffusion専用プロセッサのアーキテクチャに関する試論とChiselコードも参照)。この構成とは逆に
行列演算、softmax,dropout、layernormをそれぞれ担当する大きさの異なるcoreが存在するような構成も考えることができその場合は実行できるネットワークはさらに限定されることになります。テンソル並列化のため隣接するcore間で入力(図のdout)、計算結果が共有されます。
local RAMには計算途中の行列の値、重みデータが格納され、L1,L2と書いたSRAMとDRAMには重みパラメーター(Transformerの論文では
aggregatorをプログラマブルにすることによって様々な分散学習の更新アルゴリズムに対応させることもできますがその分プログラミングが複雑になってしまいます。
一般的なマルチコアCPUの周辺で用いられる階層的なキャッシュシステムでは値を書き込む時、あるいは読み出す時に遠くのキャッシュを更新することでコヒーレンス(同一性)を保つのですが、機械学習、ディープラーニングにおいては重みパラメーターは局所的にしかしようされないので全てのcoreから読み出せ一貫性を保つ必要なはなく、時間的には学習時の重みパラメーター更新、空間的にはデータ並列化における更新値の共有のみをすればよくその機構がaggregatorになります。
coreで計算される値と演算の関係を模式化したものが以下の図です実際の回路はもっと複雑な構成になると思われます。

計算する行列のサイズがあらかじめわかっているのでテンソル並列化、データ並列化での同期処理機構を明示的には入れておらずcontrollerによって同時に動作します。汎用性を高めるのであればこれらが必要になります。
メモリのダイと同じパッケージに入れた場合には複数のロジックダイが存在することが想定されますが、複数のダイからメモリのダイへ配線ができるのかは個人的知識不足によりわかりません。コア数、接続は機能だけでなくその配置、冗長性も勘案して多めに設定されなければいけません。
ここでは1チップで学習工程を完結させる構成を考えましたが実際には大規模言語モデルは多数のプロセッサを並列にして学習を行わせます。その場合にオーバーヘッドやデータの共有が少ないデータ並列化を複数プロセッサで行うことになり、チップ単体ではパイプライン、テンソル並列化のみを行えば良くなるかもしれません。
設計に必要なパラメータとPPA
理想的には
- 入力Transformerネットワーク層数
- 入力Transformerネットワーク層数
- core内, L1, L2メモリの容量(最大使用量)
- core内のベクトル長
- core内の同時実行命令数
- core数
- core間, group間のトポロジー(つながり方)
などのパラメーターを決めることによっていわゆるPPA(Performance, Power, Area)
- レーテンシー
- スループット
- 回路面積
- 動作周波数
- 消費電力
などが算出されます。この計算を数理最適化問題として捉えることができるはずです。Calculon論文では有限個のGPUクラスタをデータ、パイプライン、テンソル並列に並べてなるべく大きいスループットを出そうとする問題が凸関数であることが説明されています。
推論、生成工程
LLMのパラメーターは一般に巨大で小さいものでも10GB弱、Llamaでは100GB単位(7B/13B/70B)にもなります。これを少しでも小さくし、家電、組み込み機器のストレージに入れることができれば応用が広がります。
使用可能な圧縮技術
利用できそうなパラメーター圧縮技術としては
- 量子化
- 可逆圧縮(ハフマン符号化、算術符号化などのエントロピー符号化、及びその前処理)
- 疎行列、テンソル形式での格納
- テンソル分解
などが挙げられます。
量子化
精度は犠牲になりますが4bitでも実用に耐えうるという主張がされています。メモリ節約に加えて浮動小数点や固定小数点の大きな演算回路が必要なくなるのはロジックの大きな低減、積算器に関してはサイズの2乗で効いてきます。また単純な切り捨てではなくパラメーターの値に応じた適応的な量子化手法などが提案されているようです( リンク参照
可逆圧縮技術
実際のパラメーターに対する可逆圧縮の効果は簡単に調べることができます。
https://huggingface.co/Intel/Llama-2-7b-hf-onnx-int4/tree/main4bitのLlma-2-7bを圧縮したところ約5.3GBがgzip,7zipでは約4.3GB、bzipでは約4.1GBにになりました。
gzipはLZ77bzipはBWT,move to frontと呼ばれるアルゴリズムなどを用いていて異なりますが、結果としては大きくは違いませんでした。複雑度が高い場合は圧縮したほうがデータが大きくなってしまう場合があることを考えるとそこそこの結果と言えるのではないでしょうか。
ただRyzenのPCでも伸長に1分近くかかってしまっています。伸張処理は前のデータを参照するなど専用ハードウェアがあっても並列化不可能な演算があります。分岐予測がどの程度有効かもデータの種類によります。ブロックごとに伸張処理を並列化するのが現実的ですがここが律速になる可能性は高いです。
粗密変換
粗行列をベクトル演算可能な形に伸張するのにHardware-Software Co-Design of an In-Memory Transformer Network AcceleratorではLSH(locality sensitive hashing)が用いられています。CSR,CSC形式などの通常使われる疎行列の格納形式は一種の可逆圧縮(zero run length)であり可逆圧縮技術と同様の降下がのぞめます。
テンソル分解とLoRa(Low Rank Adaptation)によるファインチューニング
その他
モバイルなどでハンズフリーでの動作をさせるのであれば重要な機能として音声をテキストに変換する機能、テキストをベクトルに埋め込む(embedding)機能が必要になります。レーテンシーを犠牲にしてLLM処理と共通化するのであれば汎用的なCPUが必要になりそうです。
こちらの記事ではBLOOMというLLMではボキャブラリーを大きく取っているためembedding layer(上記図のdata converterに相当)のサイズがtransformerを上回ってしまっているそうです。用途によっては注意が必要です。
まとめ
学習、推論処理それぞれに関して実現可能なLLM専用回路の要素技術と構成例を示しました。またCalculonと同様にここで挙げたような技術選定も最適化問題、あるいは機械学習の問題として捉えられることも述べました。
参考
参考書
参考論文
-
Co-Design of an In-Memory Transformer Network Accelerator
疎行列処理に対応しLLMをターゲットとしたアクセラレータであり、CMOSと共存でき演算回路に近接した不揮発性の強誘電体電界効果トランジスタ(FeFET)をメモリとして重みパラメーターを記憶させている。Processing-in-memory(PIM)と呼ばれるこの技術によってメモリ帯域幅のボトルネックを解決している。 -
Symphony: Orchestrating Sparse and Dense Tensors with Hierarchical Heterogeneous Processing
メモリ階層全体のデータ編成の最適化を行うことで疎テンソルと密テンソルを共存、協調させた設計 -
Calculon: a methodology and tool for high-level co-design of systems and large language models
LLM用のハードウェア、ソフトウェア協調設計で性能やメモリ量などの制約のもとに設計空間を探索するツールCalculonをpythonで実装し使用した結果
この論文の手法と評価結果は興味深く改めて紹介したいです。 -
Efficient large-scale language model training on GPU clusters using megatron-LM
GPUクラスタでLLM(megatron)を学習したときのレポートで パイプライン最適化、GPU間通信におけるパラメーターのscatter/gather,
などのアイデアが書かれています。測定結果としてGPU数、並列性、バッチサイズに対する学習速度、性能の評価が書かれています。 -
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
パイプライン並列化を用いて1~8GPUで557MパラメーターのAmoebaNet model、128層のTransformerの学習を行った結果です。 -
https://arxiv.org/abs/2310.16836
浮動小数点精度の量子化Transformerの結果
Webサイト
で各社のAIアクセラレーターをあげました。演算コアでできること、コア間の関係、メモリ階層、I/Oにそれぞれ特徴が有ります。
MN-coreのコンパイラでバックプロパゲーションの計算方法の一端が触れられています。
機械学習用プロセッサをタイリングしたチップ間を100ギガビットイーサネットで通信して動作に成功しつつあるそうです。
テンソル分解、Pointwise, Depthwise convolutionに関して
分散学習に関して
torch.distributed.pipeline.sync.Pipe が使える
圧縮、量子化に関して
少し古いですがニューラルネットの量子化、圧縮の基本的なアイデアが挙げられています。
Discussion