Stable Diffusion専用プロセッサのアーキテクチャに関する試論とChiselコード
概要
画像生成などで使われるアルゴリズムであるStable Diffusionの生成処理をリアルタイム動画変換等目的とした高スループットで実行するための回路アーキテクチャSDIPを提唱する。
またその特性とアルゴリズムとの関係を既存のAIアクセラレーターと比較して述べる。
回路構成と機能
SDIPは数多くある拡散モデルのアルゴリズムのうちVAEで圧縮した隠れ変数に対して拡散過程を適用するlatent diffusionの演算を特にターゲットとしている。
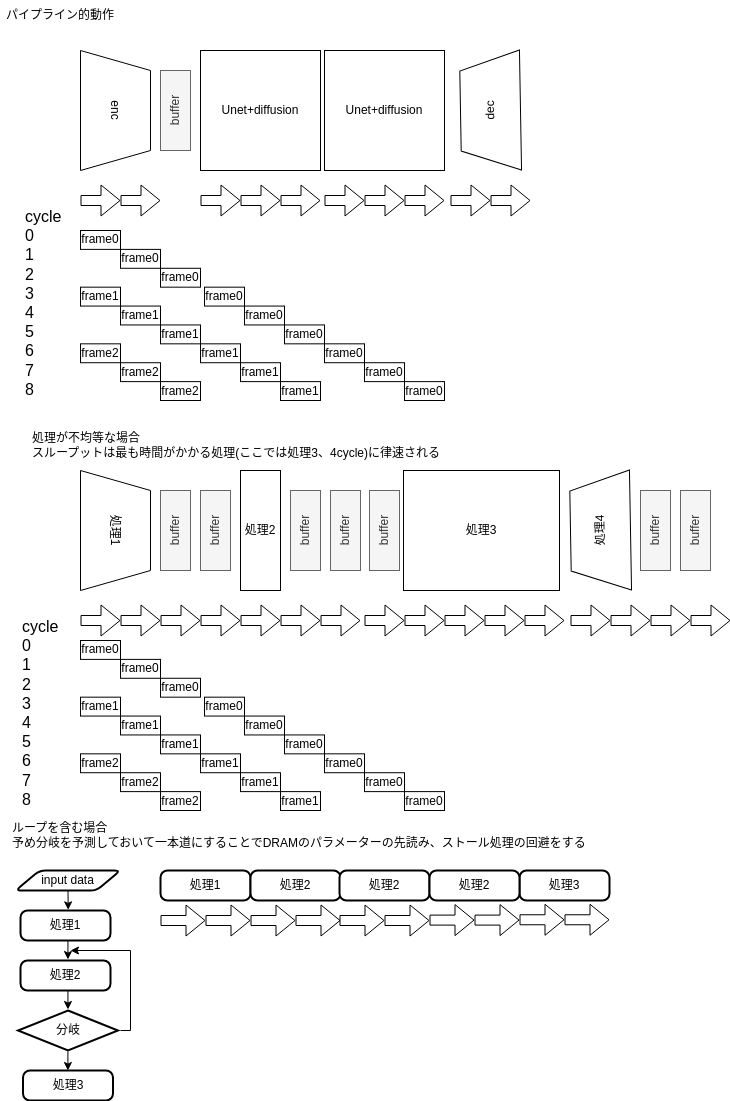
回路全体の構成を以下に図示する。

モジュール
| モジュール名 | 機能 |
|---|---|
| SDIP_top | トップモジュール、複数のcoreを持つ |
| SDIP_encoder | VAE encoder |
| SDIP_decoder | VAE decoder |
| SDIP_core | 1~数stepの拡散過程を演算するcore |
| SDIP_IMEM | 命令メモリ |
| SDIP_STM | ステートマシン |
| SDIP_PSRAM | DRAMから読んだ1step分の重みパラメーターを格納するSRAM |
| SDIP_DSRAM | 前段のcoreで計算されたデータと計算途中のデータの保持のためのSRAM |
| SDIP_STACKRAM | Resnet, U-netで必要になるResidual変数の保持のためのスタック |
| SDIP_ALU | 各演算器とその出力選択器を含むモジュール |
1 coreの動作
実装は https://github.com/xiangze/SDIP/blob/main/src/main/scala/sdip/SDIP_core.scala
onnxファイルから抽出したgraph構造を記述した.graphファイルのPC(program counter)レジスタが指定したある1行をIMEMから読み出し、そのoperationの値に基づいて信号op信号が選択される。
.graphファイルは分岐がなく順番に読み込まれる機械語に相当し以下のような固定長のフォーマットを持つ。
| operation | src1 | src2 | dst | src1 size | src2 size |
|---|
src1,src2は前段のcoreの計算結果、STACKRAMに保存されたデータ、gereral registerに保存されたスカラー値を複製したもの、あるいはアドレスを指定することでそれを読み出されるPSRAMの特定のアドレスに保存された重みパラメーター(weight)のいずれかに対応する。src1,src2に対応したそれらをarg1,arg2信号として選択する。PSRAMのアドレスはsrc1 size, src2 sizeのぶんだけインクリメントする。
operation(op)に従って選択されたconv2d,linear,Transposeその他の演算回路の出力をdataとしてDSRAM、必要であればSTACKRAMに記録する。
各operationはsrc1 size, src2 sizeに応じた所要サイクルが有り信号dulationによってそれはカウントされる。
operationが完了すると最終結果が書き込まれたDSRAM1はDSRAM0と交代し、dulationはリセットされ、PCはインクリメントして次のgraphの行が読み込まれ動作を繰り返す。DSRAM、STACKRAMのアドレスはsrc1,src2のsizeから計算されたdstのsizr分だけインクリメントする。
coreのパイプライン動作
実装は https://github.com/xiangze/SDIP/blob/main/src/main/scala/sdip/SDIP_top.scala
入力画像データをVAE(variable autoencoder)のencoderで圧縮し、それに複数ステップの拡散過程を適用し、decoderで画像に戻す。複数ステップの拡散過程を直列したcoreで分担することで動画のようなストリーミング入力をリアルタイムに処理することを目標とする。
各coreでははステップ数t,周期性を表すsin(t),promptをベクトル空間に埋め込んだ
入力画像をランダムにした場合はtext(prompt)の情報のみから生成するtext to image(t2i)に相当する。
拡散モデルの大きな特徴であるのが複数のstepでデータを生成すること、各ステップで必要になるパラメーターは共通でノイズの分散のみが異なること
である。このため図のように全く同じ重みパラメーターをPSRAMから各coreに読み出すことができる。ただしVAE encoder,decoderだけは異なるパラメーターを読み出すことになる。必要なstep数に対してcoreの数が足りない場合には1つのcoreが複数のstepの演算を行いその分だけスループットは低下する。
2番目の図はより一般的な状況として処理ごとに所要サイクルが異なる場合である。この場合スループットは最も時間がかかる処理に律速される。
.graphファイルは通常の機械語と異なり分岐命令、ループは存在しない。onnxの論理的にはループがあってもそれを展開したもののみを受け入れることとする。
onnx変換プログラム
stable-diffusion-pytorchの記述に基づくと
onnxの仕様に定義されたoperationのうち、Stable diffusionの動作に最低限必要なオペレーションは以下のものになる。
| operations | input引数(arg)の数 | weight | latencyの次元 |
|---|---|---|---|
| copy | 1 | 無 | 0 |
| add | 2 | 無 | 0 |
| sub | 2 | 無 | 0 |
| mul | 2 | 無 | 0 |
| div | 2 | 無 | 0 |
| rand | 0 | 無 | 0 |
| sqrt | 1 | 無 | 0 |
| softmax | 1 | 無 | 0 |
| relu | 1 | 無 | 0 |
| silu | 1 | 無 | 0 |
| Transpose | 1 | 無 | 2~ |
| Matrix-Vector product | 2 | 無 | 2 |
| Matrix-Matrix product | 2 | 無 | 2 |
| conv2d | 1 | 有 | 1 |
| linear(full connection) | 1 | 有 | 2 |
| linear_batch(full connection) | 1 | 有 | 2~ |
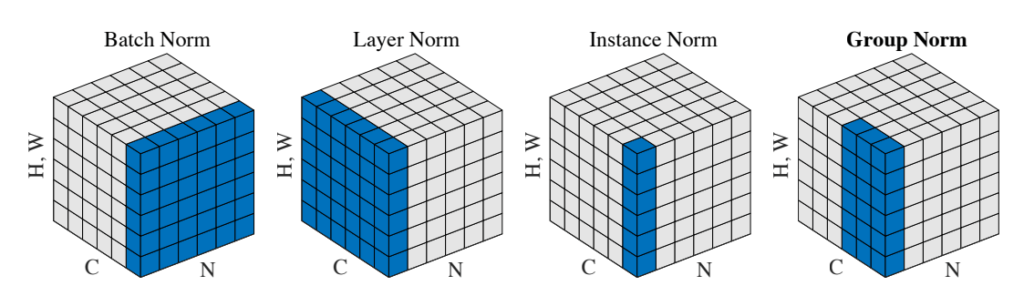
| groupnorm | 1 | 有 | 2~ |
| layernorm | 1 | 有 | 2~ |
groupnorm,layernormに関しては下図及びその他参考にしたリンクも参照
これ以外のonnxで定義されたoperationもSDIP_ALU、SDIP_STMに演算、所要サイクルを追加することで拡張可能である。
設計空間とPPA解析
SDIPのアーキテクチャでは
- coreの数
- 演算精度(数値のビット幅)
- SRAMのデータ幅
- DRAMとのクロック周波数比率
- 演算回路、SRAMの共有の程度
などが可変なパラメーターとして挙げられその組み合わせの数だけ可能な回路が存在する。Stable Diffusionのような特定のネットワークにおけるデータ転送上のボトルネックを見つけるために回路シミュレーションを利用することができる。
固定されたネットワークパラメーターに対して行われる生成処理では、演算量、速度は入力画像データ、学習データに依存しない。しかしパラメーターに対して粗行列圧縮や蒸留を用いた場合はその限りではない。
ChiselのコードをVerilogに変換、論理合成を行うことで後述の発展的機能実装も含めてスループット性能、消費電力、回路面積(PPA)に影響する度合いを評価することができる。
よく用いられるネットワークの集合を入力とした特定の回路構成のスループット、動作周波数、面積、精度は目的関数として定義でき、その最適化を機械学習を用いて行うことが考えられる。この場合データ生成は学習で得られたポテンシャル関数(score関数)の最適化、ポテンシャル関数(score関数)の学習は固定された入力データ集合とネットワークアーキテクチャに対する最適化、回路構成の最適化はよく用いられるネットワークの集合に対する最適化と階層的になっていると言えるかもしれない。
演算子の粒度
後述の他のAIアクセラレータと比べるとSDIPは粗粒度といえる。粗粒度はonnxを加工することなく命令列(.graph)を生成できることが利点であり、冗長な演算回路を持つことが欠点である。
実装テクノロジー
FPGAあるいはASIC(専用LSI)、それぞれの製造プロセスによって演算器、SRAMのサイズや速度は異なりその最適な組み合わせも異なる。
最先端の微細化した半導体製造プロセスでは相対的にSRAMの面積、電力コストが高く、ロジックのコストが低くなることが報告されている。このことから冗長な演算回路を許容し、SRAMを節約することが高効率化の鍵となると予想される。SDIPではALU内の演算回路の共有を行わず、DSRAMとSTACKRAMを共有するなどの回路構成がこの方向性に合致する。
onnxからのプログラム、重みデータの作成とRAMへの書き込み
onnxを分離、変換することで命令列(.graph), パラメーターを並べたバイナリ(.weight)を作り前者はIMEM、後者はDRAMへとデータ処理前に書き込む。データ生成実行時にgraphの各行読みそのoperation,src,dstに基づいて演算、用いるデータ、パラメーターを決めるのは上述のとおりである。
graph作成時onnxに現れるデータをPSRAMの特定の場所に割り当てる工程はコンパイラのレジスタ割付に相当する。
Residual dataに対してはgraphの行に印をつけることでSTACKRAMへの読み書きを指示するようにする。
発展的機能実装
現状のSDIPとそのonnx converterでは実装していないが機能、効率化の観点から重要な事項を列挙する。
共通パラメータのハードコーディング
画像生成においては学習済みパラメーターを頻繁に変えることはなく入力テキスト(プロンプト)を変更して描きたい事物や画風を変更するのが常である。そのため特化した画風や情景を求めないユーザーに対しては固定されたネットワークパラメーターのみを提供する方法も考えられる。これは入力テキストの工夫のみでLLMに所望の動作をさせることを試みるプロンプトエンジニアリングに類似する使用方法である。
自然言語処理の分野など用いられる基盤モデルと呼ばれる多くのタスクに共通して使われるニューラルネットは汎用性が高いため同様にハードコーディングが可能な局面が多いと考えられる。
ASIC(専用LSI)で実装する場合には物理的配線が固定され、FPGAで実装する場合は回路情報を記録するSRAMに直接回路情報が埋め込まれる形になる。AMDのNPU(Neural Processing Unit)は FPGAをベースにしたものとされ、起動時に回路情報をSRAMに書き込むのと同じ仕組みでニューラルネットパラメーターをNPUに書き込んでいると推測される。FPGAに読み込まれる回路と同様にチップ内でのネットワークの2次元的配置がタイミング制約に影響することも考慮しているかもしれない。
ベクトル折返し
SRAMのビット幅以上のデータを読み書きする場合には複数サイクルをかけて順番にアクセスする必要がある。データがまた演算回路のビット幅を超えるも同様に複数サイクルに分けて順番に演算が必要になる。これは回路規模とスループットのトレードオフとなる。
layer fusion
点処理(入力テンソルの1要素にのみ出力が依存する演算)のoperationが連続する場合にはそれを統合して一つのoperationとしてSRAMアクセスを削減すること手法が AIアクセラレーターの業界ではよく知られている。onnxをgraph、weightに変換する際に加工することで実現できる。
暗黙の転置
これもonnxには明示的には書かれないが、演算器入力に対してテンソルの転置を行うことで効率的な並列演算ができる場合がある。onnxを編集することで特定のハードウェアに対する高速化を実現している事例がある。.graphを加工するときにTranspose operationを挿入することで対応する(静的対応)か、実行時にTranspose→他の処理という動作を行う(動的対応)が考えられ、他社のAIアクセラレーターでも実装されていると思われる。
固定小数点化、量子化
一般に機械学習は浮動小数点精度で行われることが多いが、エッジデバイスで推論、生成処理を行う際には重みパラメーターのサイズが問題になることが多く、固定小数点化、8bit,4bitなど低ビットに量子化することが行われる。
量子化により精度を犠牲にして重みパラメーターの容量は小さくなり、場合によってはメモリが不要になることもある。Chiselのgeneric programmingにより対応が可能であり、精度と性能のトレードオフを探索することもできる。また浮動小数点回路が固定小数点回路、より大きなビット数の回路がより小さなビット数の回路を包含することもできる。
LLMにおいては4bitでも許容可能な精度が出ることが報告されている[1]。
蒸留、動的行列分解、圧縮されたパラメーターの伸長
量子化と比べると精度への影響が小さいものと考えられる。動的行列分解、圧縮されたパラメーターの伸長の演算はCPUなど別の回路に行わせる方法がある。
疎行列、テンソル対応
Hardware-Software Co-Design of an In-Memory Transformer Network AcceleratorではTransformer, Attension(注意機構)で用いられる疎行列積を変換する機能が実装され、演算量削減が報告されている。
回路規模削減
各演算回路に並列積和演算器がある状況は冗長である。これらを共有することで回路規模が削減できる。
既に挙げたベクトル折返し、暗黙の転置と同様onnxの演算粒度をより細かい命令列に噛み砕くように変換しなければならず、CPUのマイクロコードに相当するような動的変換が必要になる。
汎用化、あるいはさらなる専用化
Stable diffusion専用回路としてはターゲットが限定的すぎるので汎用化が要求される。
- DSRAM, STACKRAMの一体化
- core間にbuffer,crossbarを設けて接続の自由度を高める
- PSRAMへの書き込みを許可し階層的キャッシュを作る
などが考えられる。またステートマシンSTMの機能を完全にソフトウェア化してCPUに行わせる方法も考えられる。stete変数を
int state=imem[pc];
などとpcで指されるimemの値として定義する。PSRAM,DSRAMのアドレス、write enableも変数として書き換え、DMA(Direct Memory Access)回路を起動させてcore間データ、パラメーターを転送させる方法である。この場合すべてのcoreが同一の動作をする場合はアドレス、write enableの書き換えは一回でいいが汎用化のため異なる動作を可能とするとcore数分だけ軌道にサイクルがかかってしまうことになる。
逆に専用化を突き詰める方向としては既に挙げたパラメータのハードコーディングの他にDSRAMを演算器ごとに持つことで完全に独立動作するようにしCPUでいうスーパースカラー的な動作を行わせスループットを高める。VAE encoder/decoderの専用回路化などがありえる。
coreごとに異なる重み(weight)の使用
拡散モデル以外のネットワークをパイプライン処理する場合はSDIPでもVAE encoder/decoder部分は拡散モデルとは異なるネットワークである。単純にPSRAMの幅を増やす、あるいは異なるネットワーク分複数のPSRAMを用意する。または各ネットワークで並列に実行されるoperationを隣接するように予めDRAMに置いておくなどの工夫が必要になる。
並列ネットワーク
Resnet, U-netのResidual部分の分岐は片方は演算処理せずそのままデータを残しておく構成であった。それ以外の分岐の双方でするネットワークとしてはTransformerに見られるMulti head attentionなどが典型的である。あるいは同一のネットワークを異なる入力データに対して適用する場合もこれに相当する。ネットワークの並列パイプライン実行のハードウェア対応として入出力データ、core間あるいはcore同士の間の連結を分岐させるような接続を追加する必要がある。
Resnet, U-net以外の分岐するネットワーク対応
Resnet, U-netはResidual dataの作成と消費が入れ子になる形のみ許容しているためstack構造で対応できた。それ以外の分岐を許容すると動的なメモリ確保と開放が必要になりOSによるメモリ管理に近い仕組みが必要になる。
多段パイプラインによる動作周波数向上
CPUを含む一般のクロック同期回路と同様に組み合わせ回路の間にパイプラインレジスタを挿入することで動作周波数が向上する。SDIPでは予め直列化され分岐のないgraphを読み込んでいくためハザードによるパイプラインストールが存在せず、常に高効率で演算処理ができるが上記の演算ごとのメモリ分離、スーパースカラー化を行った場合はこの限りではない。
ステートマシンの分散化
機能的なまとまりの観点からALU内の各演算器がそれぞれステートマシンを持ち状態を管理するほうがわかりやすく、operationを追加する際にもSDIP_ALUのみを編集すればよくなる。一方で演算器間の調停は理解が難しくなる。
他アーキテクチャとの類似点、相違点とアルゴリズムとの関係性
特にサーバー、クラウドを標榜したものだとGoogleのTPU
、PFNのMN-Core、quadricのChimera GPNPU、Tesla のDojo、tenstorrentのRISC-Vベースのマルチコアプロセッサ、graphcoreのIPUなどがある。これらは拡散モデルも含む大規模なニューラルネットの学習、推論、生成処理を行うためのものである。多くはonnxインターフェースに加えpytorch等のディープラーニング記述をサポートしている。
Quadricはc++によるプログラミングがサポートされ、tensortorrentはCUDAとpytorchのバックエンドcupy(PFNによってメンテナンスされている)を置き換えるようなBUDAの開発を標榜している。
画像等を処理するCNNの高速化、低消費電力化のためには隣接するコアでメモリ、レジスタを共有するアーキテクチャが組み込み系では特によく見られる。一方でSDIPは1 core内部で直線的な計算グラフの演算を完結させ、ハードウェア並列性をデータ並列化ではなくパイプライン化、スループットの向上に用いている。VAEを用いて画像をより次元の小さい潜在変数空間に圧縮するlatent diffusionの構成と親和性が高いと言え、同時にその限界に制約されると思われる。
このようなlatent diffusionの特質は専らNvidiaのGPUを用いそのハードウェア的制約のなかで行われている画像生成アルゴリズムの研究開発の歴史の結果として生じたものであるとも推測できる。上記の他のニューラルアクセラレータを用いた学習が一般的になると異なった形のネットワークが脚光を浴びるようになるかもしれない。
ディープラーニングによって得られた大量のパラメーターを使った識別、生成処理では巨大なパラメーターをメモリから読み出す際の帯域がボトルネックとなりやすい。その中でも同じパラメーターをデータを変化させながら繰り返し用いるLSTMのようなRNNの系統のネットワークがハードウェアアーキテクチャとの親和性が高いと予想されるが、GPUによる研究開発の歴史は逆に巨大な行列積をAttentionを用いるという選択をした。同一のパラメーターを複数ステップに少しづつ変えて使う拡散モデルが制約のあるメモリ帯域に対する性能効率が高いとは単純には言えないが、画像のような自己相似的な構造をもったデータの特徴を学習の過程で捉えることができているとは言えるのかもしれない。
まとめ
本文ではStable Diffusion専用プロセッサの構成、動作の一例とその実装のあたって考慮すべき事項を列挙した。その特徴は
- 直列動作によるクロスバー、分岐予測、ストールが不要な回路構成
- 生成処理のみを行うので重みパラメーターはDRAMから読み出すのみでありキャッシュが不要
- 拡散モデル実行では全step, coreで用いるパラメーターが同じ
- 拡散過程では隠れ変数を処理するので1 core内で並列処理が完結する
である。また既存のAIアクセラレーターとの類似点、相違点と拡散モデルや他のアルゴリズムが性能に与える影響について考察した。
各社のニューラルアクセラレータに関する情報とニュース
各社紹介、ネットニュース
- tenstorrernt RISC-V
-
PFN MN-Core
- PFNにおけるDeep Leaningアクセラレータの開発について(pdf)
-
神戸大学牧野淳一郎先生によるスライド(pdf)
ハードウェアアーキテクト、ソフトウェア(アプリ)それぞれから見た最適なメモリ階層が図示されている。HBM(High Bandwidth Memory)の困難とそれを解決するであろう3次元実装の紹介もされている。
22 pageの各社アーキテクチャの表の引用
| MN-Core | Sunway | PEZY | GPU(A100) | |
|---|---|---|---|---|
| SIMD/MIMD | SIMD | MIMD | MIMD | SIMDブロック |
| キャッシュ | なし | なし | あり | あり |
| コア間通信 | ツリー | ハイパークロスバー | キャッシュ経由 | キャッシュ経由 |
MN-Coreは伝統的なスパコンやGPUと異なりキャッシュを持たず、階層的なコア間通信を行う。
-
-
ホワイトペーパー
-AI dayの情報が各所に散在していてWikipediaが比較的まとまっている。 - https://www.nextplatform.com/2022/08/23/inside-teslas-innovative-and-homegrown-dojo-ai-supercomputer/
-
ホワイトペーパー
-
- ベンチマーク
- SDKとソフトウェアスタック,dockerが利用できる
- インタビュー記事クラウドでの学習をターゲットとしている
AMDによれば、このNPUは、AMDが買収したXilinxのFPGAがベースになっており、そのFPGAのロジックがPhoenixのダイに含まれており、プログラマブルになっているのも大きな特徴だ。 https://pc.watch.impress.co.jp/docs/news/event/1467965.html
論文
-
Co-Design of an In-Memory Transformer Network Accelerator
疎行列処理に対応しLLMをターゲットとしたアクセラレータであり、CMOSと共存でき演算回路に近接した不揮発性の強誘電体電界効果トランジスタ (FeFET)をメモリとして重みパラメーターを記憶させている。Processing-in-memory (PIM)と呼ばれるこの技術によってメモリ帯域幅のボトルネックを解決している。
-
Symphony: Orchestrating Sparse and Dense Tensors with Hierarchical Heterogeneous Processing
メモリ階層全体のデータ編成の最適化を行うことで疎テンソルと密テンソルを共存、協調させた設計 -
Calculon: a methodology and tool for high-level co-design of systems and large language models
LLM用のハードウェア、ソフトウェア協調設計で性能やメモリ量などの制約のもとに設計空間を探索するツールCalculonをpythonで実装し使用した結果
その他参考にしたリンク
- layernorm,groupnormについて
Discussion