はじめに
Turing 株式会社のリサーチチームでインターンをしている東京工業大学 B4 横田研究室の藤井(@okoge_kaz)です。
自然言語処理分野における大規模深層学習の重要性は日に日に高まっていますが、GPT-3, GPT-4 などのモデルの学習には膨大な計算コストがかかり、容易に学習できなくなっています。実際、モデルサイズが近年急速に大きくなっていることにより、学習に必要な計算量(FLOPs)は以下のように年々膨大になっています。近年の大規模モデルでは、NVIDIA H100 80GB であっても 1 つの GPU では、モデルをのせることすらできません。
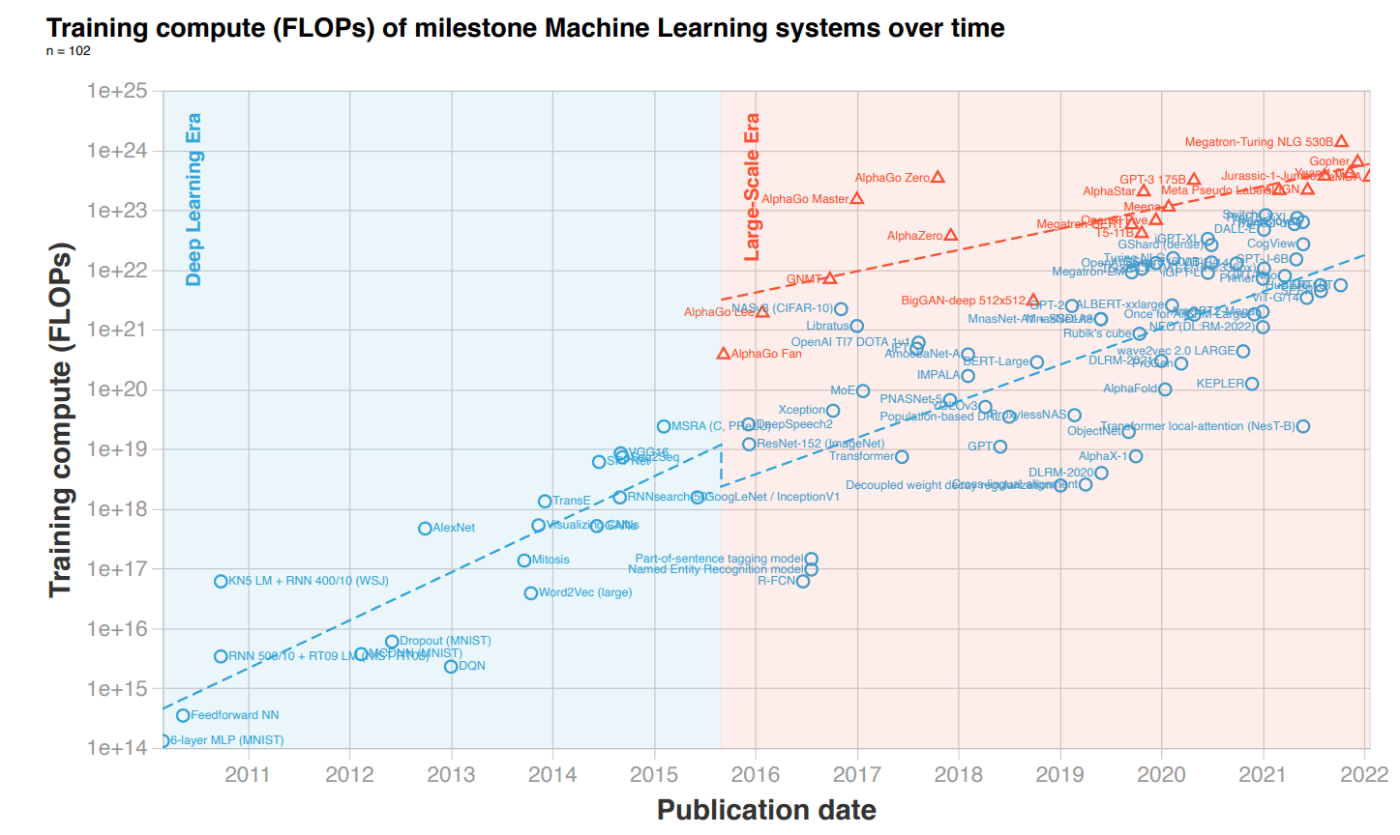
Compute Trends Across Three Eras of Machine Learning より
またScaling Laws によると、大規模なモデルは小さいモデルと比較してより優れた性能を発揮するため、自動運転などの難易度が高いタスクを解くためには大規模なモデルが不可欠です。しかし大規模モデルの学習には、上述のように膨大な計算資源が必要であり、大規模なGPUリソースと時間がかかります。
Turingでは基盤モデルを用いた完全自動運転の実現を目指しており、基盤モデルの学習を支える技術に関して研究開発を行っています。
まさにこの大規模モデルの学習の裏で活躍しているのが分散並列学習です。本記事では、この分散並列学習の技術について説明を行います。
分散並列学習のメリット
モデルが大きすぎて 1 つの GPU に収まらないことや、データセットが大きすぎて 1 つの GPU では 100 日間かかるような場合、後述する Model Parallel や、 Data Parallel を用いることで訓練を可能にしたり、訓練プロセスを高速化し妥当な時間で結果を得ることができます。
16 日かかっていた学習を DDP(Distributed Data Parallel)を用いることで、2 日間に短縮したり、Model Parallel を使うことでバッチサイズを 2 から 16 に拡大したりすることができます。
分散並列学習のコンセプト
次に分散並列学習のコンセプトについて説明します。
まず分散並列学習(Distributed Parallel Training)には複数 GPU (もしくは複数 node) が必要です。
分散並列学習では学習の過程で、デバイスは通信により情報を共有します。
(ここでの情報とはモデルの勾配など学習に必要な情報をイメージしてください)
なぜ「情報の共有」が必要なのかというと、分散並列学習では学習対象のタスクを分割し複数のデバイスでそれを処理します。しかし何も通信しなければ、各デバイスは自分が処理している内容は分かっても、他のデバイスが処理している内容については知り得ません。元々処理したかった分割する前のタスクと同じ結果を得るためには、各デバイスの処理内容を適切なタイミングで同期する必要があります。そのため、分散並列学習ではデバイス間(node間)で情報を共有することが必要となるのです。
分散並列学習をより深く理解するには以下の4つの概念を押さえる必要があります。
- Host
通信ネットワークのメインデバイスのことをホスト(Host)と呼びます。一般的に、分散環境を初期化する際、引数でどのデバイスをホストにするのか指定します。 - Port
分散並列学習の際、通信に用いるホストのマスターポートのことを指します。 - Rank
分散並列学習の際、ネットワーク上の機器に与えられる固有の ID です。 - World Size
分散並列学習に用いるデバイスの数のことです。2 nodes 16 GPUs による分散学習の際は、world_size = 16 となります。
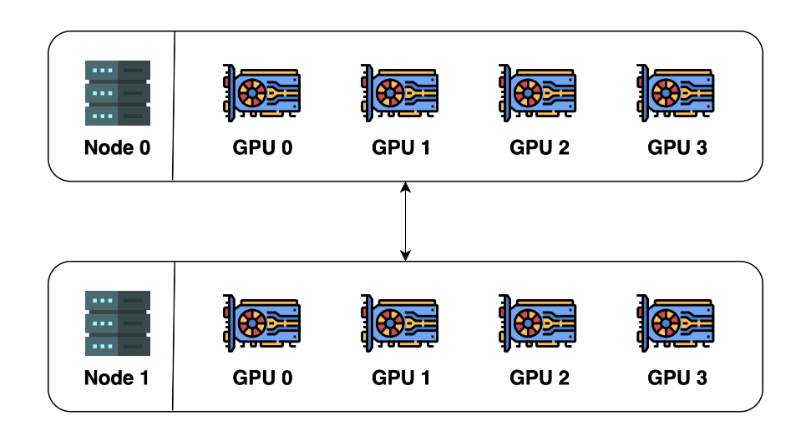
(Colossal-AI Concepts Distributed Trainingsより)
具体例を示します。
上記のような構成の場合は、一般的に Host は Node 0 の GPU 0 が担います。
またポートは、他のユーザーと port 番号が被らないように(JOB_ID + 10000) % CONSTANT_VALUE などを設定することが多いです。
Rank は以下のような形で割り振られます。(必ず一意になるように割り振られます。)
| Node | GPU index | Rank |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 0 | 2 | 2 |
| 0 | 3 | 3 |
| 1 | 0 | 4 |
| 1 | 1 | 5 |
| 1 | 2 | 6 |
| 1 | 3 | 7 |
World Size は 8 枚 GPU があるので 8 です。
分散並列化手法
分散並列学習について「なんとなく」イメージがついてきたのではないかと思います。
以下では、それぞれの手法について詳細な説明を行うことで目的に沿った並列化手法を選べるようになるための説明を行います。
Data Parallel
Data Parallel(データ並列)は、グローバルバッチサイズを大きくすることで学習時間を短縮することを目的とした並列化手法です。
データセットを GPU の個数に分割し、分割したデータセットを各 GPU に割り当てます。各 GPU はモデルの複製をそれぞれ有しているため、割り当てられたデータセットをそれぞれ別々に学習します。そして誤差逆伝播(back-propagation)の後に、モデルの勾配を GPU 間で共有することで同期をとります。
データ並列の様子を表したイラストが下記になります。
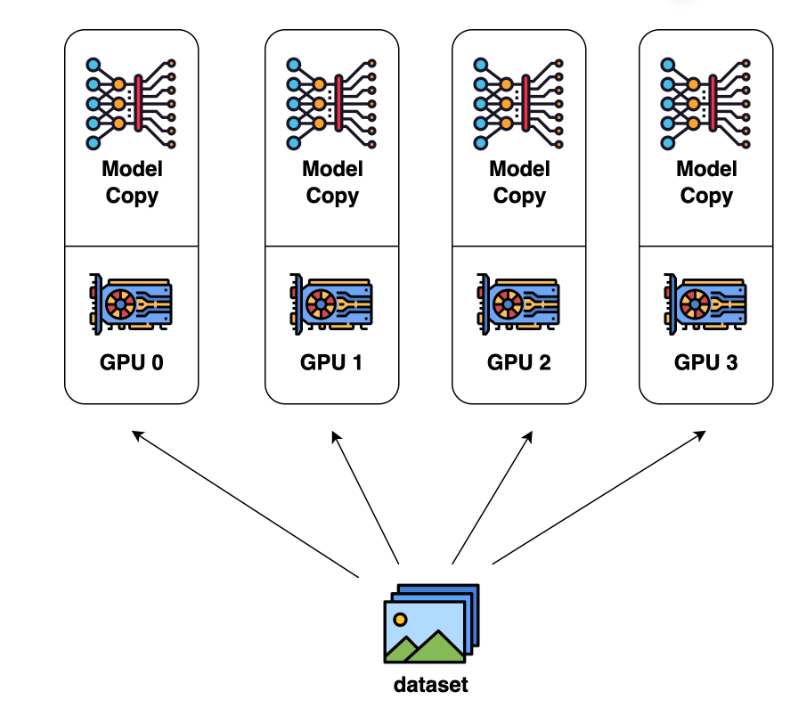
(Colossal-AI Concepts Paradigms of Parallelismより)
各 GPU はデータセット全体の 1/4 のデータを学習しているだけに見えますが、モデルの勾配をデバイス間(GPU 間)で同期することでデータセットをすべて学習したのと同じ結果を得ることができます。
では Data Parallel で何が変わったのでしょうか?大きな変化は、グローバルバッチサイズの変化と、学習時間の短縮です。
まず、グローバルバッチサイズの変化ですが、1 つの GPU だけで学習をしていた際のバッチサイズを
次に学習の短縮ですが、これは直感的にも分かるように、1 つの GPU が担当するべきデータセットサイズが並列数
ZeRO
データ並列(Data Parallel)では、各 GPU がそれぞれモデル全体の重みを有していました。しかし、これは冗長性の観点で見ると無駄があるとも言えます。それぞれの GPU がモデルの状態(Optimizer の状態、勾配、モデルパラメーター)を複製するのではなく、GPU 間で分割することで Data Parallel のメモリの冗長性を排除することができれば、さらに良さそうです。
実はこれを実現しているのが Zero Redundancy Optimizer 通称 ZeRO です。この記事では ZeRO に関する説明は省略しますが、続編の「大規模モデルを支える分散並列学習のしくみ Part2」にて詳しく解説する予定です。
Model Parallel
Data Parallel はモデルの複製をそれぞれの GPU がもつことで、学習を高速化しようとするアプローチでした。これから紹介する Model Parallel は、モデルを分割して複数 GPU に分散させることで 1 つの GPU には収まりきらないようなモデルを学習可能にしようとするアプローチです。
モデル並列には Tensor Parallel(テンソル並列)と Pipeline Parallel(パイプライン並列)の 2 種があります。
以下では、それぞれの並列化手法について説明を行います。
Tensor Parallel
Tensor Parallel の基本
Tensor Parallel(テンソル並列) とは、テンソルを特定の次元に沿って
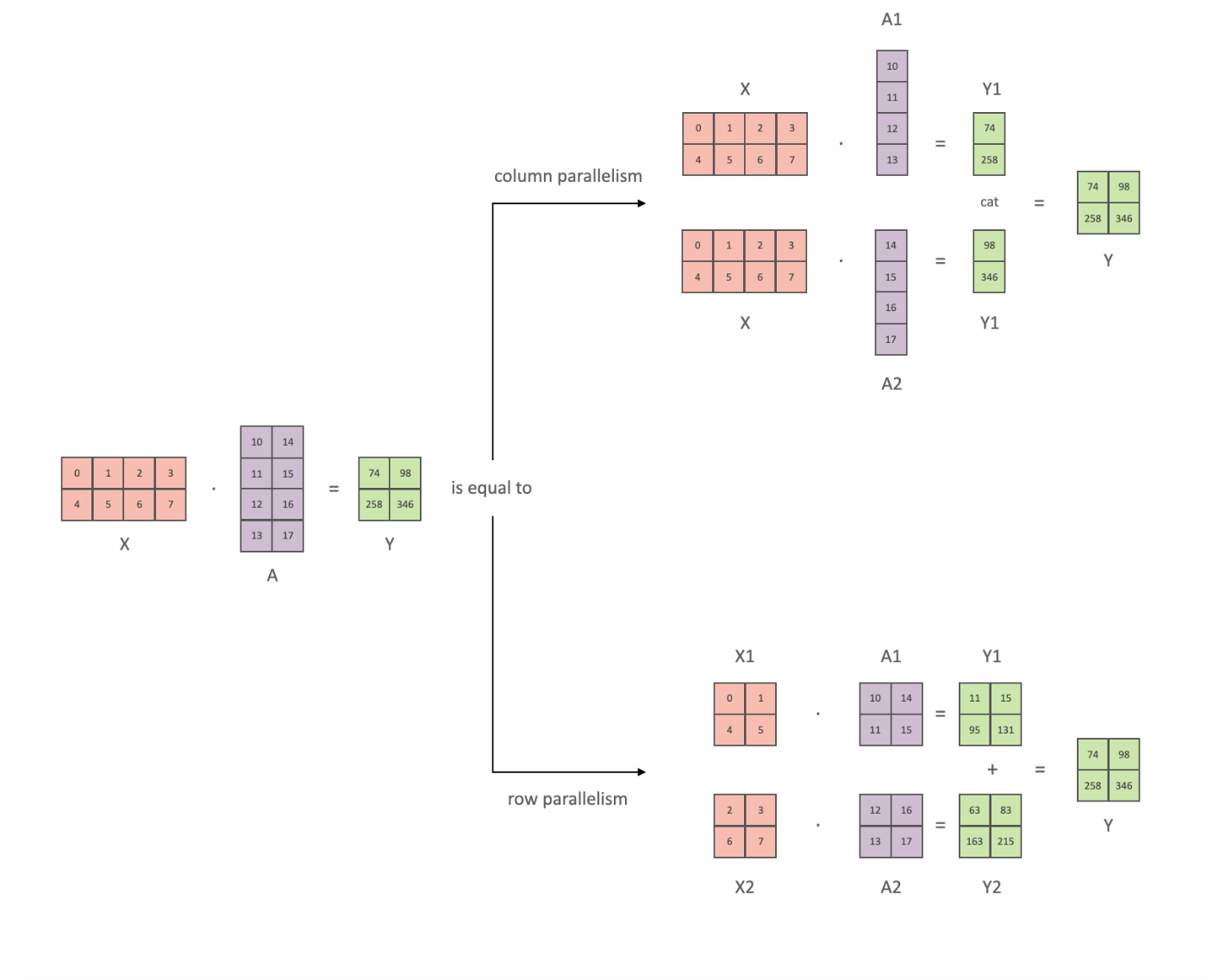
具体例を見たほうが分かりやすいと思うので以下の図を使って説明します。
(huggingface より)
今我々が計算したいのは
とします。ここで
すると計算式は以下のように表せます。
よって各 GPU では
これにより
同様に、行方向の分割についても可能です。以下では列方向の分割と、行方向の分割を組み合わせたものを示します。
と表せます。これにより行列積
活性化関数と Tensor Parallel
上述の列方向分割により、
例えば計算後に活性化関数を通る場合
と表せるので、
行列を分割 → 行列積計算 → 集約 → 得られた行列を分割 → 活性化関数 とするよりも
行列を分割 → 行列積計算 → 活性化関数
としたほうが、集約するための通信コストや、分割する際のオーバーヘッドをなくすことができます。
以下の図のように出力ベクトルを集約する必要があるまで分割したまま処理することで、任意の深さの MLP において GPU 間の同期を必要とせず学習を進めることができます。
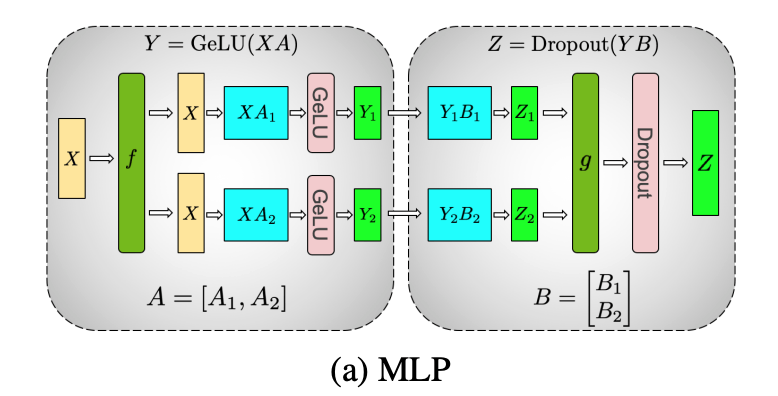
(Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism)
上記のような GPU 間の同期が少なくなくてすむ構造が多い場合は、
Multi-Head Attention 層においては以下のように、並列化可能な構造を有しています。(= それぞれの Head が独立になっている) そのため、
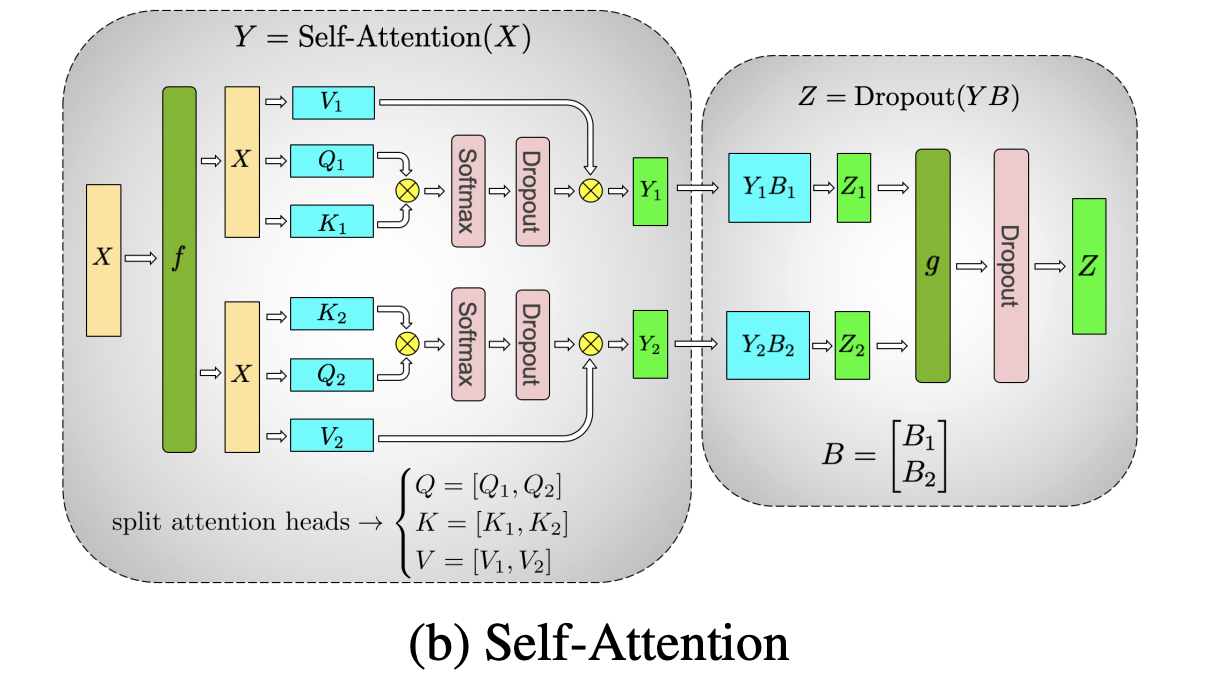
(Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism)
Pipeline Parallel
About
パイプライン並列のコンセプトは、モデルを分割し、分割した Layers を別々の GPU が持つというものです。これにより、1 つの GPU に乗りきらないサイズのモデルを学習することができます。
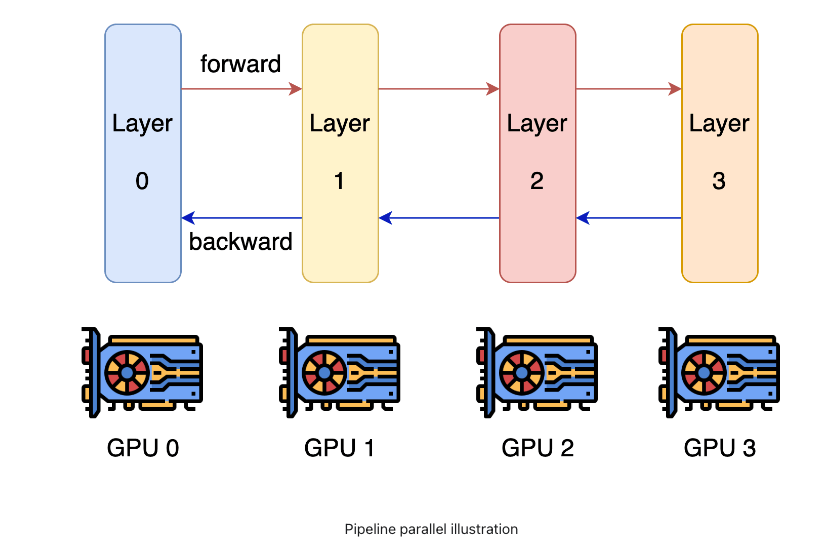
(Colossal-AI: Concepts/Paradigms of Parallelism Pipeline Parallel)
Naive Model Parallel
パイプライン並列の考え方を愚直に行うのが Naive Model Parallell(Vertical)です。この方法では GPU の大部分を活用することができないため実際に用いられることはありません。しかし Pipeline Parallel を理解する助けになるため紹介します。
Naive Model Parallel では以下のようにモデルを複数の GPU に分割します。
================= =================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
================= =================
GPU:0 GPU:1
同一 GPU 内で layer:0 → layer:1 → layer:2 → layer: 3 と伝搬させていく際は通常の場合と変わりありません。しかし、layer: 3 → layer: 4 へ伝搬させる際は GPU が異なるため GPU 間で通信が必要となります。具体的には、中間活性(intermediate activation)を GPU:0 → GPU:1 へ送ることで実現します。
(逆伝搬の際は、GPU:1 → GPU:0 へ入力テンソル(input tensor)を伝達します。)
特に問題がなさそうに見える Naive Model Parallel ですが、GPU:0 で伝搬が行われている際は GPU:1 は idle 状態になってしまっています。これは効率性の観点からは致命的です。例えば、この方法ではGPU 数が 8 枚ある際は 7 枚が常に idle 状態になってしまいます。GPU 間でデータを送ることによるオーバーヘッドも存在するため、このままでは非常に効率が悪い並列処理になってしまいます。
この問題を解決するための手法が、ミニバッチをマイクロバッチに分けてパイプライン化する方法です。
この方法による分割並列をパイプライン並列と呼びます。
Pipeline Parallel
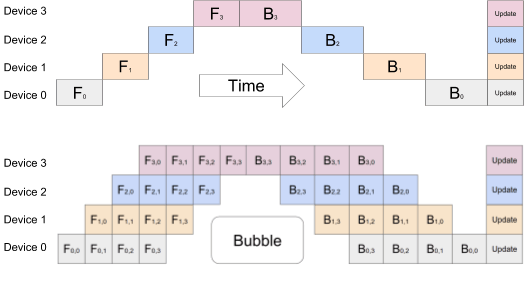
上図は 1 つの GPU 以外が idle になっている非効率な方法から、バッチをさらに分割しマイクロバッチとすることでパイプラインを作り GPU の稼働率を上げている状態を示しています。
ある時刻
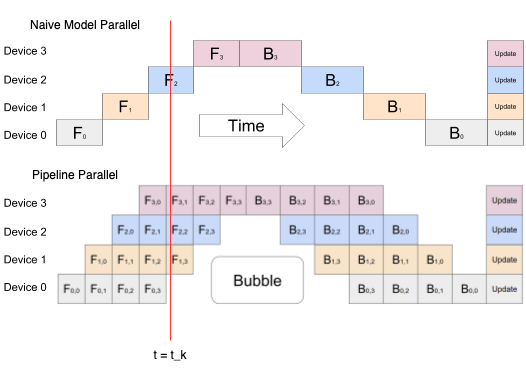
Naive Model Parallel では 1 つの GPU(Device2)しか活用できていないのが、Pipleline Parallel では 3 つの GPU(Device3, Deveice2, Device 1)を利用できていることがわかります。
(Pipeline Parallel の図に”Bubble”と書かれた部分がありますが、ここは GPU デバイスが idle 状態にあり有効活用できていないことを表しています。)
Pipeline Parallel において効率を上げるには Bubble の部分を小さくすることが重要です。Bubble を小さくするにはデータのチャンク数(
つづく
この記事では分散並列学習に関する基本的なコンセプト、各種分散並列学習について概説しました。
続編の 「大規模モデルを支える分散並列学習のしくみ Part 2」 ではさらに ZeRO を始めとする最新の分散学習の技術について解説します。また、「大規模モデルを支える分散並列学習のしくみ 実践編 Part 1」 では今回の記事にて説明した概念を用いて実際に学習を行うための実装例を示します。(PyTorch, DeepSpeedでの実装例を示す予定です。)
Turing では自動運転モデルの学習や、自動運転を支えるための大規模言語モデルの作成のために分散並列学習の知見を取り入れた研究開発を行っています。興味がある方は、Turing の公式 Web サイト、採用情報などをご覧ください。話を聞きたいという方は私や AI チームのディレクターの山口さんの Twitter DM からでもお気軽にご連絡ください。
参考文献
- Colossal-AI
- huggingface
- arXiv
- Google Research

Discussion