
基盤モデルが自動運転車を操ってる筆者のイメージ created by DALL-E
Turingで機械学習チームでエンジニアをしている井ノ上です。(Twitter: いのいち)
Turingは2030年までにあらゆる場所で自動走行が可能で、ハンドルが必要ない完全自動運転システム(Level 5自動運転)の開発を目指して様々な技術の調査や検証を行っています。このテックブログではTuringがどのようにしてLevel 5完全自動運転にアプローチしていくのか、近年の基盤モデルやGoogleのロボティクス研究から考えていきたいと思います。
TuringのLevel 5への仮説
Level 5の自動運転をどのようにして作るのか。これは多くの人が気になるところだと思います。TuringではLevel 5自動運転の実現の鍵は「知能」にあると考えています。従来の自動運転の開発によって、LiDARやレーダー、カメラなどのセンサーを使って周囲を認識することは高いレベルで実現できているように感じます。さらに、GPSや高精度マップと組み合わせることで限定区間での完全自動運転(Level 4自動運転)は実現してきたと思います。しかし、Level 5自動運転には走ったことのない道や一時的な交通整理、首都高速での合流などハイコンテキストな状況で車同士のコミュニケーションが必要となる運転もできなくてはいけません。こういった複雑な状況を理解し、適切に運転するための「知能」がLevel 5自動運転には必要だと考えています。
このような知能を持った自動運転を実現するために、Turingでは 「4つの機能、3つの学習、2つのモデル、1つのシステム」 という思想を掲げています。
自動運転に必要とされる4つの機能は、1. 解釈 2. 想像 3. 決断 4. 交渉であり、これにはマルチモーダル学習、Vision and languageの学習、強化学習の3つの学習が必要だと考えています。これを実現するために2つのモデル: driverとnavigatorを実装する必要があります。Driverは、センサを中心とした認知・推論を高速に行うモデル。Navigatorは、総合的な認知・意思決定を行う大規模モデルで、人から受けた指示を背景も含めて解釈して判断を行い、driverに伝えます。最後にこのdriver、navigatorを機能させて正しく車を制御できる1つのシステムがTuringが考える完全自動運転システムです。
近年の基盤モデルの進歩を見ていると、この仮説は夢物語ではないと思わせてくれます。今回は特にNavigatorの方に注目して説明しようと思います。
基盤モデルとは
ChatGPT(OpenAI)やLLaMa(Meta)、PaLM(Google)、Chinchilla(DeepMind)などの大規模言語モデル(Large Language Model, LLM)が話題を呼んでいます。このような自然言語の大規模なモデルは大量のデータで自己教師あり学習で訓練されており、様々なタスクに応用可能です。こういったモデルのことを「基盤モデル」と呼んでいます。自然言語に限らず、画像や動画、音声などさまざまなデータに対して基盤モデルを作成して活用しようという研究が増えてきています。
さらにはVision and languageのように複数のモーダルを融合させたようなモデルも基盤モデルとして開発されてきました。中でもCLIPという手法が一つのゲームチェンジャーだと思います。この手法はCNNやVision Transformerで画像をエンコードした特徴ベクトルと、ペアとなるテキストをTransformerを用いてエンコードした特徴ベクトルが近づくようにモデルを学習しています。これにより自然言語と画像の情報が特徴ベクトルの空間で結びつけることができ、DALL-EやStable Diffusionのようにテキストを与えると、それにあった高精細な映像が出力できるようになり大きな話題を呼びました。

A Generalist Agentより引用
CLIPのように自然言語と画像を潜在空間で結びつける手法の他にも、GatoやFlamingoといったモデルのように画像など他の形式のデータも自然言語と同じような埋め込み表現にしてモデルに入力するというマルチモーダルな方法も提案されています。このように、基盤モデルは様々なドメインの知識を獲得すべく研究が進められています。
"Navigator"としての基盤モデル
では、実際に基盤モデルはどのように活用されているのでしょうか。まずは基盤モデルの中でもLLMを活用しようという研究に注目しました。LLMは自然言語で学習されているため、基本的には物理世界の情報を持っていませんが、たとえば、「LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action」では基盤モデルを含む複数のモデルを活用することで、フリーテキストで説明を与えると目的地まで移動できるシステムを提案しています。

LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Actionより引用
与えられた説明からLLMを用いてランドマークとなる単語を見つけてきます。次に、CLIPを使うことでランドマークとターゲット環境の映像を結びつけます。最後に視点の映像からロボットのナビゲーションを行うVisual Navigation Model(VNM)でLLMで抽出したランドマークの通りにプランニングを行い、実際にロボットを動かしています。
他にもLLMを活用することで、これまで短い定形の言葉しかロボットへの指示として入力できなかったのが、人間の抽象的な説明でもその意味やコンテキストを機械に理解可能な形にすることができるようになりました。「Do As I Can, Not As I Say: Grounding Language in Robotic Affordances」という論文で提案されているPaLM-SayCanというモデルは、抽象的な説明文を与えてもLLMで具体的なタスクに落とし込み、ロボット視点から実際に起こせるアクションを判断して目的を達成しようとします。

Do As I Can, Not As I Say: Grounding Language in Robotic Affordancesより引用
図中の左の部分では、与えられた抽象的な説明をプロンプトエンジニアリングを駆使して具体的なタスクにスコア付きで分解しています。右の部分では、ロボット視点の画像から価値観数を用いてどういったアクションがとれるかを計算しています。両者についたスコアを比較し、目的を達成するために今の状況にあったアクションを選択することができます。これを繰り返して最終的にはじめに与えられた指示を完遂しようとします。各タスクをこなしていく過程が分解された言語で表されているので解釈性が高いところも非常に面白いポイントだと思います。
PaLM-SayCanではLLMに指示を与えられるのは最初だけで、アクションの実行中にはLLMにフィードバックがないためタスクが失敗してもそれを知ることができません。この課題を解決してよりタスクの成功率を上げるために、「Inner Monologue: Embodied Reasoning through Planning with Language Models」という手法が提案されました。

Inner Monologue: Embodied Reasoning through Planning with Language Modelsより引用
人の説明を解釈するメインのLLMに加えて、映像から状況をキャプションしたScene Descriptorやアクションが成功したかどうかを判断するSuccess Detectorを用いて、メインのLLMに状況のフィードバックを行います。さらに、ときにはメインのLLMが質問を行うことでより適切な判断を行ったり状況が変化しても対応できるようになりました。このシステムを構築するのに追加でモデルの訓練は行っておらず、既存のモデルを組み合わせて作り上げていることから、LLMのような大規模モデルの性能をうまく引き出してくるシステム開発が重要になってくると考えられます。
これまで紹介した研究から、LLMにどのように現実世界の情報を伝えるかがポイントになっていることがわかるかと思います。ここまでのモデルは既存のLLMを駆使してロボットの操作につなげていましたが、LLM自体に現実世界を学習させる方法も提案されています。「PaLM-E: An embodied multimodal language model」ではGoogleが持っている最強のLLMであるPaLMを使ってより現実世界を理解できるモデルが提案されています。

PaLM-E: An Embodied Multimodal Language Modelより引用
視点映像やロボットの状態などのセンサーデータもLLMに入力することでLLMに身体性(Embodiment)を持たせようという発想です。センサーデータを自然言語のように埋め込みベクトルに変換し、テキストと一緒に入力して学習済みのLLMをファインチューニングしています。画像の埋め込みベクトル変換に220億パラメータのVision Transformer(ViT 22B)を使い、LLMに5400億パラメータのPaLMを使っており、合わせて5620億パラメータのモデルをPaLM-E 562Bとしています。PaLM-SayCanのようにいくつかのサブタスクを必要とする抽象的な説明でも実行できるし、Inner Monologueのように途中でサブタスクを邪魔しても再度そのサブタスクをやりなおすことができます。
面白いことに、PaLM-Eはロボットのタスクをこなせるだけでなく、追加学習無しで一般的なVision and languageの課題もこなすことができます。たとえば以下の結果では写真から自転車でこの道を進んでいいかどうかを理解して判断していることがわかります。

PaLM-E: An Embodied Multimodal Language Modelより引用
こういった結果をみているとモデルが「知能」を持ち始めていることを感じさせます。
最後に、GPT4についても軽く触れたいと思います。2023年の3月15日に公開された基盤モデルで、公開と同時にものすごい反響を呼んでいます。GPT3系とは違い、GPT4では画像も入力できることから活用の範囲や方法が広がることは間違いないと思います。
公開されたTechnical Reportの結果を見ていると、映像を解釈する能力の高さに驚かされます。畳み込みニューラルネットの発展で機械は良い目を獲得したと言われていましたが、目が脳につながった感覚です。例えば、以下の結果は映像から常識に照らし合わせて何がおかしいかを指摘しています。

GPT-4 Technical Reportより引用
車の運転では事故などの稀にしか起こらないコーナーケースが無数にありますが、そういったデータを狙って集めるのは非常に難しいです。コーナーケースでも適切に対応できるシステムのためには、GPT4が獲得した「常識」をうまく組み込むことが鍵になってくるかもしれません。
このように、GPT4はかなりのポテンシャルを秘めており、エンジニアとして継続して使い続ける必要があると思います。大規模モデルのポテンシャルを最大限に引き出すことが自動運転の開発だけでなく、アノテーションに活用したり開発効率を高めたりとあらゆる場所で必要とされるスキルになると思います。
基盤モデルの自動運転における課題
これまでの内容を考慮して、基盤モデルを用いて完全自動運転を実現するための特に重要な技術的課題は以下の3つです。
- モデルの現実世界への適応力: 基盤モデルは自然言語で学習されているため、物理世界の情報を持っていません。そのため、基盤モデルが現実世界の情報を効果的に取り込み、理解する能力を向上させることが重要です。これには、視覚情報やセンサーデータなどの入力データを適切に処理できるようにモデルを設計・学習する技術が求められます。
- 安全性と堅牢性: 自動運転システムは人命に関わるため、高い安全性が求められます。基盤モデルを用いた自動運転技術においても、外部環境やシステムへの攻撃に対する堅牢性や、予期しない状況に適切に対応できる技術が重要です。これには、敵対的攻撃に対する耐性を持つモデルの設計や、不確実性に対処するための推論技術が必要となります。
- リアルタイム性と計算効率: 自動運転システムはリアルタイムでの判断や行動が求められますが、基盤モデルは大規模で計算負荷が高いことが課題となります。そのため、基盤モデルを効率的に計算し、リアルタイムで適切な判断や行動を行えるようにする技術が重要です。これには、モデルの圧縮や車載ハードウェアへの最適化などの技術が必要となります。
これらの技術的課題を克服することで、基盤モデルを活用した完全自動運転技術の実現が期待されます。今後の研究や技術開発がこれらの課題に取り組むことで、より安全で効率的な自動運転システムが実現されるでしょう。
上の文章はGPT4に書いてもらいました。 それまでの文章を入力して、課題を上げてくださいと質問することで、このようにまとまった文章を書いてくれます。「リアルタイム性や計算効率」のようにこのブログでは言及していないが、重要な項目についても説明しています。与える説明をもっと工夫すればより良い文章に仕上がると思います。さらに、GPT4のAPIも近日中に公開されるということから、ブログのスクリーンショットを与えるだけでより洗練された文章を生成してくれるかもしれません。
せっかくなので基盤モデルを自動運転で使うための課題についてもう少し補足をしようと思います。
GPT4が出力した課題にも上がっていたとおり、基盤モデルと言われるものはまだ自動車レベルでの身体性を持ってはいません。しかし、安全に運転を遂行するためには、やはり車の大きさや重さ、運動性能といった特性を一定以上理解しておく必要があると思います。
基盤モデルに身体性を与えるために、PaLM-Eのように運転データも合わせてLLMを学習するという方法が考えられます。動画や点群データも扱えるマルチモーダルなモデルも提案されているので、自動運転に必要な身体性を持つことができるモデルを設計できるはずです。どういったデータがどの程度必要で学習させるために一体どれだけコストがかかるのか計り知れませんが、LLMを運転データでファインチューニングする方法はぜひとも試してみたいアプローチです。
LM-NavやPaLM-SayCanのように複数のモデルを組み合わせるという手法も欠かせないと思います。複数のドメインで学習させたモデルを自然言語をインターフェースとしてうまく活用するフレームワークは「Socratic Model」として提案されています。
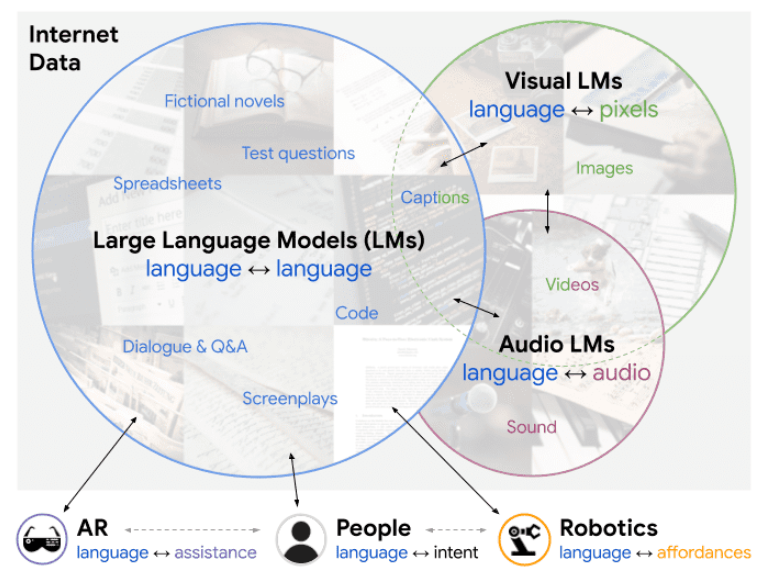
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Languageより引用
幸運にも、GPT4に加えてPaLMのAPIも公開予定だというアナウンスがGoogleからありました。さらに、モデルのチューニングを行えるMaker Suitも公開予定だそうです。これらの既存LLMなどをうまく使い、それらが持つポテンシャルを最大限引き出して組み合わせる技術が自動運転システムを作る上で必要になってくると感じています。
「基盤モデルのような大規模なモデルをそもそも1台の車に載せれるんですか?」「基盤モデルの常識はどの地域、文化圏での常識ですか?」など、開発してればすぐに直面する課題も山積みです。しかし、基盤モデルのポテンシャルはまだまだ計り知れないので、完全自動運転を実現するための重要な技術として今後も追求していきたいと思います。
終わりに
今回のブログでは、Turingが完全自動運転を実現するために、基盤モデルのどういった技術に注目しているかを説明しました。このブログを読んで、基盤モデルは完全自動運転につながりそうだと感じてもらえると嬉しいです。
Turingでは大規模モデルが完全自動運転の実現のための重要な技術だと捉えています。
完全自動運転という前人未到の難題に、世界を震撼させている基盤モデルを駆使して挑戦できる、こんなにワクワクさせてくれる環境はなかなかないと思います。実現に向けて課題は無限にありますが、必ず実現できると信じて日々取り組んでいます。
もしこのチャレンジに興味がありましたら、私やAIチームのディレクターである山口さん、CEOの山本さん、CTO 青木さんの誰でもいいのでぜひとも声をかけてください!一緒に挑戦できるメンバーが増えるととても嬉しいです!

再び基盤モデルが車を操ってる筆者のイメージ図

この絵を生成するためのプロンプトもGPT4に作ってもらいました。

Discussion