【令和最新版】何もわからない人向けのローカル LLM 入門
こんにちは、Saldraです。普段はPictoriaという会社でAIの美少女の錬成に励んでいるエンジニアです。この記事はローカルLLMの概要をつかむことを目的とします。対象読者は以下です。
- なんとなく ChatGPT は使ったことある人
- ローカル LLM を聞いたことあるけどやったことない人
ローカル LLM とは
OpenAIがAPIを公開してから、大規模言語モデル(以降LLMとします)は大きく進化していきました。この進化はOpenAIのAPIだけでなく、ローカルLLMも進化をしています。
ローカルLLMとは「一般向けにファイルとして公開されたモデル」で推論させる遊びです。APIは便利ですが、インターネットの接続が必要であったり、API提供側に依存する問題があります。ローカルLLMは自前で運用ができるため、APIにはないメリットや魅力があります。一方で、環境構築やマシンスペック等、少し始めるには高いハードルがあるのも事実です。少しだけメリットとデメリットを整理してみます。
メリット
APIの仕様に左右されない
OpenAI APIは頻繁にモデルのアップデートが行われ、継続的に改善されています。これはメリットではあるのですが、あるバージョンでは動いていたプロンプトの挙動が仕様変更によって上手く動かなくなるリスクがあります。モデルのバージョン固定も限定的であり、例えばOpenAI APIには「gpt-3.5-turbo-0613」という今年6月にリリースされたモデルは利用期限が2024年の6月13日と、一年程度しか使えません。一方ローカルLLMはファイルとして公開されたモデルをダウンロードして利用するので、その気になれば10年間利用することも理論上は可能になります。
通信環境に左右されない
APIなので原則通信環境がある場所で、かつ通信モジュールがついている機械に限られることになります。非常に限定的だと思うかもしれませんが、例えばイベント会場では通信が使えず、デザリングで解決しようと思ったらパケ詰まり…というケースは現実に起こり得るリスクでしょう。
デメリット
一般的にAPIサービスよりも性能は下がる
特定タスクに特化したモデルであればAPIサービスと忖度ない性能がでることもありますが、基本的にはAPIサービスよりも性能としては下がります。
計算資源を沢山使う
通常LLMは、使うために膨大な計算リソースを必要とします。ローカルLLMはAPIとは異なり、自前のパソコンで計算します。結果、自分のPCの性能を上げる必要があったり、自分のPC内で動く程度の性能のLLMを使うに留めたりする必要があります。
スケール難易度が高い
もしもサービスとして展開しようとしたとき、上記の計算資源をこちらで用意するか、相手側の端末でやってもらうかのどちらかになります。こちら側で用意する場合、莫大なGPU資源を使うことになるので現実的ではなく、相手側の端末で計算してもらおうとすると、相手側の端末の性能に依存してしまうことになります。OpenAPIを使ったサービスの場合、計算コストをOpenAIが払ってくれるのでスケールは容易でしょう。
前置きが長くなりました、早速環境構築を行ってローカルLLMを触ってみましょう。
環境構築
APIを使わずに「公開されている LLM モデルのファイルで推論させる」ということになるので、自分でコードを書くか、ツールを探して推論させるかのどちらかが必要になります。今回は一々コードを書くのは面倒なので、text-generation-webui というツールを使います。
text generation webui とは
Text generation web UI とは oobabooga 氏が作成した UI ツールです。インストールするとコーディングなしで推論や学習が UI 上でできるようになります。
作業用ディレクトリに以下の記述を書いた install.bat を作成し、実行してください。なお今回の記事は Windows ユーザを対象にしています。
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
python -m venv venv
.\venv\Scripts\activate
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
python server.py
Mac の方は以下の install.sh を作成すれば大丈夫だと思います。
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
python -m venv venv
./venv/Scripts/activate
pip install torch torchvision torchaudio
pip install -r requirements.txt
python server.py
以下のような表示が出たら成功です。
Running on local URL: http://127.0.0.1:7860
再度遊びたくなったときはvenvを再アクティベーションして、server.pyを実行してください。
cd text-generation-webui
.\venv\Scripts\activate
python server.py
モデルのダウンロード
http://127.0.0.1:7860をブラウザで開くとWebUIが開きます。
Model タブを押し、モデルのダウンロードを行います。
Download model or LoRA 欄の上段に「TheBloke/calm2-7B-chat-GGUF」、下段に「calm2-7b-chat.Q2_K.gguf」を入力し、Donwload ボタンを押します。
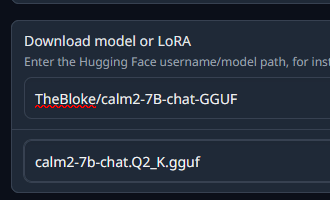
「Getting the download links from Hugging Face」ー>「Downloading file to models/」と表示されるのでしばらく待ちます。このモデルは大体 3GB くらいです。「ready」と表示されたらダウンロード完了です。
モデルの読み込み
Model の None の横にある左矢印ボタンを押し、モデルリストの更新を行ってください。

Model を None から「calm2-7b-chat.Q2_K.gguf」に変更し、画面中央あたりにある「CPU」にチェックを入れてください。その後 Load を押すと読み込みが始まります。右側に「Successfully loaded calm2-7b-chat.Q2_K.gguf.」がでたらダウンロード完了です。
推論
Default タブを押すと、推論モードになります。左側にプロンプトを入れ、右側に結果が出る仕組みです。以下のように入れてみましょう。
USER: 日本とは何かを簡単に説明してください。
ASSISTANT:
これで推論ができました。
モデルを変えてみる
では、モデルを変えてみます。
先程のmodel上段を「mmnga/cyberagent-calm2-7b-gguf」、下段を「cyberagent-calm2-7b-q2_K.gguf」にしてダウンロードしてみましょう。プロンプトを変えてみます。
日本の良いところについて教えてください。
結果出力されたものは以下でした。
日本の良いところについて教えてください。
|starttext|
--- 目次 ---
1. 日本の良いところを教えてください。
2. 日本の食事はどうですか?
3. 日本人は親切ですが、シャイだと思いますか?
4. 日本人の英語の発音が悪くて困っています(笑)。
5. 日本の文化についてどう思いますか?
6. 日本では何曜日が一番多いですか?(月曜日が多いとか?)
7. 日本は安全ですか?
8. 日本で一番難しい言葉は何語ですか?
9. 日本人と外国人はどちらが親切だと思いますか?
10. 日本に住んでいると日本語を覚えるのが大変ではありませんか?
11. 日本では何曜日が一番多いですか?(月曜日が多いとか?)
12. 日本の良いところについて教えてください。
13. 日本の食事はどうですか?
14. 日本人は親切ですが、シャイだと思いますか?
15. 日本人の英語の発音が悪くて困っています(笑)。
これだけだと回答できていないことがわかります。これは、先程まで使っていたモデルは、対話用にチューニングされているモデルのためです。チューニングされていない言語モデルを「baseモデル」、ユーザーの指示に受け答えできるようにしたモデルを「instructモデル」と呼んだりします。
Instructだけでなく、特定の用途に特化させたいときもチューニングを行います。特化させた用途に使うために、配布されたLLMをチューニングすることを「ファインチューニング」と呼びます。これは頑張れば一般人でも可能です。
GPUで推論してみよう!
基本的にCPUよりもLLMはGPUで推論した方が速いです。
もしGPUを持っている人はModelタブでCPUのチェックを外し、n-gpu-layersを適度に上げてみてロードすると早くなることがわかります。
今後何する?
ここまでで取り敢えず入門はできたと思うので、この記事を終わりにします。ここからは自分のやりたい方針によって、勉強する範囲が変わるので、ほんの少しだけ紹介します。
text-generation-webui使いたくない!
text-generation-webuiはかなり使いやすいツールですが、特定のモデルだとエラーになったりするので、詳しく設定値を変えたり、特定の使いたいモデルがある場合はコーディングをしてみるとよいかもしれません。コーディングでは「めぐチャンネル」さんのnote記事が参考になります。FastAPIでローカルLLMを自前API化するところまでがわかります。
特定のタスクに特化したLLMにチューニングしてみたい!
ファインチューニングを勉強すると良いです。概要はnpakaさんが書いたこの記事が参考になります。
簡易的な実践はこの記事がオススメです。GoogleColabという、気軽にクラウドでGPUが使えるサービスを使ってハンズオンができます。
これをシステムに取り入れてみたい
生成AIを用いたプログラミングを一度APIでも良いのでやってみて、それをローカルLLMに置き換えてみるのがオススメです。例えば超簡易的なチャットCLIツールをまずはOpenAI APIで作ってみて、それをローカルLLMに置き換えてみたりとか。簡易的に自分で小さいツールを考えてみるのがお勧めです。自著になりますが生成AIプログラミングの本があって、ここのOpenAI部分をローカルLLMに差し替えてみても面白いと思います。
効率的に大きなモデルを小さなデバイスで動かしてみたい!
後述しますが「量子化」という、推論精度を犠牲にしつつ、推論コストを下げる手法が考えられているので、そのモデルを使ってみると良いです。今回使ったモデルも量子化モデルになります。
おまけ
パラメータとは
パラメータとはモデルの「文章を生成する際に用いる調整可能な数値の総数」のことです。凄い雑に言うと、パラメータ数が多いほど、より多様で複雑なタスクを処理できるようになります。つまり1billionパラメータのモデルよりも、13billionパラメータのモデルの方が複雑なタスクができます。ただし、パラメタが大きいほど求められる計算資源(GPUのスペック)は多くなります。
色々なモデルがある
ローカル LLM の modelは「Hugging Face」というサイトで主に配布されています。たとえば先程の「TheBloke/calm2-7B-chat-GGUF」はこのページで配布されていたものです。他にも様々なモデルがあり、このページに大体まとまっています。
ggufってなんですか?
本来、LLMを推論させるためにはGPUの計算資源を多く使います。これを無理やりCPUで推論しようとすると、どうしても推論速度が遅くなってしまいます。この状況を変えるためにCPUでLLMを動作させようとするプロジェクトが始まりました。
CPUで推論させることができれば、MacBook等でも動かせるようになります。これが「llama.cpp」というプロジェクトです。llama.cppでは「gguf」という形式のモデルを使用します。この形式に変換する際、「量子化」という、推論精度を犠牲にしつつ、推論コストを下げる工程を行います。これによって、本来推論では不利なCPUでも推論ができるようになります。text-generation-webuiはllama.cppに対応しているので、ggufモデルを使用することができます。
「量子化」には様々なバリエーションがあります。今回使ったのはQ2_Kという、極端に質が低くなる一方でとても高速化される方法です。以下のページは、様々な量子化方法でgguf化された「calm2-7b-chat」が羅列されています。 量子化バリエーションの説明は以下のページを参考にしてください。
最後に
この記事は「ローカルLLMに向き合う会」というコミュニティの有志に執筆の手助けをしていただきました。本当にありがとうございました。「ローカルLLMに向き合う会」は知識がないながらも頑張って試行錯誤しつつローカルLLMを触ろうという人達で集まって遊んでいるコミュニティです。もしよければ遊びに来てみてください。
Discussion