はじめに
Turing 株式会社のリサーチチームでインターンをしている東京工業大学 横田研究室B4の藤井(@okoge_kaz)です。
2022年11月末にChatGPTがリリースされてから早1年、2023年は大規模言語モデル開発の領域において飛躍の1年となりました。国内でもCyberAgent, PFN, ELYZAを筆頭に3B〜13B程度のモデルが多数公開され、多くの方にとってLLMが身近になった1年であったかと思われます。
Turingでは完全自動運転の実現に向けた研究開発の一環としてLLMに早くから着目し、社内で研究開発を行ってきました。
また、私はLLM-jp 13Bの開発など国内の言語モデル開発に複数関わっている関係上、それらを通じて様々な生きた開発知見を多数得てきました。
そのような中で、実際に手を動かす実働部隊が「公開されている知見」をきちんと理解しておくことの重要性を日々感じています。他社、他機関の公開知見をただ知っているだけでは役に立ちませんし、実際に手を動かすことに傾倒しすぎてもいけません。その2つの絶妙なバランスを常に保ちつつ、知識を更新し続ける必要があると個人的に感じています。
今回の記事では、これまでの言語モデル開発における個人的に重要であると感じた知見を概況し、2024年以降のLLM開発の一助となれればと思い執筆しています。
BLOOM
以下で紹介する内容は、次のTechnical Reportから主に抜粋しています。
より詳細について知りたい方は、適時参照ください。
なぜ BLOOM に着目するのか
LLaMAなどの着目するべきモデルが多数存在するなか、なぜ今更BLOOMについての知見が有用なのか疑問に思う方も多いでしょう。私は以下の理由でBLOOMにおける知見は有用であると思います。
- 多くの失敗例(試行錯誤)が公開されている点
GitHub上に、176Bモデルを学習させるまでに失敗した事例に関する詳細なレポートが多数公開されています。LLaMAアーキテクチャが主流になった今日では参考にならない点もありますが、学ぶ点も多いです。 - 学習に使用したライブラリが公開されている点
多くのOpen Modelはモデルのcheckpointを公開しても、学習に使用したライブラリについては公開しない場合が多いです。しかしながら、BLOOMではbigscience-workshop/Megatron-DeepSpeedのように使用したMegatron-DeepSpeedから改変した実装を公開しています。
Training の詳細
ハードウェア: NVIDIA A100 80GB x 384 (= 48 node)
ソフトウェア: Megatron-DeepSpeed
データセット: 350B Token (59 Language)
モデルアーキテクチャ
-
Embedding LayerNorm
176Bモデルを学習させる前に、104Bモデルを予備実験としてBLOOM projectでは行っているのですが、その際に数多くのLossの発散を経験しています。その中で、学習を安定化させる工夫としてword embeddingの直後に追加でLayerNormを入れることがなされました。
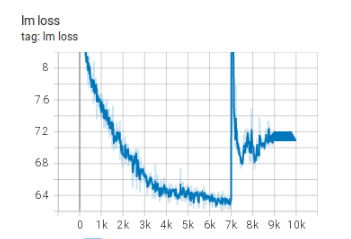
( https://github.com/bigscience-workshop/bigscience/blob/master/train/tr8-104B-wide/chronicles.md より) -
Positional Encoding
現在競争力があるモデルの多くは、Rotary Positonal Embedding(RoPE)を利用していますが、BLOOMではAliBiが利用されました。infrence時にTraining時よりも長いsequnceを入れることができることが利点とTechnical Reportでは説明されています。AliBi論文: https://arxiv.org/abs/2108.12409
学習Tips
-
GPU故障について
BLOOMの学習においては約400個のGPUからなるクラスターを利用していたようですが、週に1, 2個のGPU障害が発生していたようです。100iteration(=3時間)ごとにcheckpointを作成していたようですが、それでも最悪の場合はGPU不良により99iteration分の進捗が無駄になる可能性があります。学習チームは、故障GPUの復旧と、バックアップノードを利用することでこれに対処していたようです。 -
いわゆるBabysitting について
上述のようなハードウェア故障だけでなく、Loss Spikeが発生する可能性もあるため、誰かが学習状況を監視する必要があったと報告しています。As the training was happening 24/7 we needed someone to be on call - but since we had people both in Europe and West Coast Canada overall there was no need for someone to carry a pager, we would just overlap nicely. Of course, someone had to watch the training on the weekends as well. We automated most things, including recovery from hardware crashes, but sometimes a human intervention was needed as well.
-
checkpointについて
176BモデルのcheckpointはFP32のoptimizer stateとBF16, FP32のモデルweightsのせいで2.3TBになったようです。
分散並列学習
Megatron-DeepSpeedの実装を元としているのため、Pipeline ParallelはDeepSpeed側の機能が、Tensor Parallelに関しては Megatron-LM のコードによる実装が使用されるようになっていると報告されています。
学習には3D Parallelismが利用されており、ZeRO DP, Tensor Parallel, Pipeline Parallelを利用した効率的な学習が行われています。

(3D Parallelism: microsoft research blogより)
Megatron-DeepSpeedに関する実践的な使用方法については以下の記事をご覧ください。
(最新版のpart-3についても記事を執筆中です。)
巨大なvocabulary size による弊害
BLOOMでは250Kもの語彙サイズを有しているためword embedding matrixが非常に巨大です。通常は、Transformer Blockと比較してword embedding matrixがメモリを消費する量はさほど大きくないためPipeline Parallelを行なう際にembedding layerとlm-head部分を考慮する必要はないです。
しかし前述した通り、BLOOMにおいては話が変わってきます。実際、embedding layerだけで7.2GBのメモリを消費します。(BF16) 対してTransformer Blockは4.9GBであり、通常とはサイズの大小関係が逆転してしまっています。そのため、BLOOMではMegatron-DeepSpeedに以下のような変更を行いました。
コンセプトとしては、単純です。Megatron-DeepSpeedにおけるPipeline Parallelにおいてembedding layerについてもPipeline Parallelの対象としてみなし、Transformer Blockと同様に扱ってしまえば良いという方法です。すなわち、BLOOMのモデル構造では72 lyaerありますが、そこにembedding layerとlm-headの2つを足した74 layer Transformer BlockがあるかのようにみなしてPipeline Parallelを行ったということです。
これにより、embedding layerとlm-headを担当するGPUにおいてメモリが逼迫しており、その他のGPUでは空きがあるような偏在状態から、比較的バランスのとれたGPUメモリ消費を実現することに成功しました。
Pipeline Parallelなどの用語に馴染みのない方は以下をご覧ください
LLaMA
LLaMA-2 ではなく、どうしてLLaMA-1?
以下ではLLaMA-1 (以下では単にLLaMA)における知見を紹介します。
なぜ、最新の知見が取り入れられており性能面でも一世を風靡したLLaMA-2ではなくLLaMAについて紹介するのかと言いますと、LLaMAのTechnical Paperの方が学習の詳細についても触れられており、紹介するべき点が多いと感じたからです。LLaMA-2のTechnical Paperについても一読の価値はありますので、ぜひ目を通すことをおすすめします。
概要
以下のセクションでは、LLaMA: Open and Efficient Foundation Language Modelsの内容をもとに説明していきます。
LLaMAは7Bから65Bまでのparameterを有するモデル群を指します。もっとも注目するべき点は、世の中に公開されているデータセットのみを利用して学習された点と、これまでのモデルと比較して非常に多いToken数で学習された点です。
またモデルを公開した当時、メジャーであったモデルの多くを少ないパラメーター数でベンチマークスコアにおいて圧倒、もしくは並ぶ性能を見せたことも特筆するべき点です。
In particular, LLaMA-13B outperforms GPT-3(175B) on most benchmarks, and LLaMA65B is competitive with the best models,Chinchilla-70B and PaLM-540B
Scaling Law に関連して
背景
まずLLaMAの論文において、なぜTrillion Tokenも学習を行ったのかについて説明をしている背景について紹介します。ご存じの方も多いと思いますので適時飛ばしてください。
膨大なテキストコーパスで学習された大規模言語モデルはテキスト中の指示(instructions)や、少数の事例から新しいタスクに対応するいわゆるfew-shot能力を示すことが分かっています。こちらについては、GPT-3の論文において詳細に説明されており、モデルを十分な大きさ(sufficient size)にした際に、初めてこのような驚異的な能力が現れるものであり、それゆえにモデルサイズを増加させることに重点が置かれて開発が進められてきました。
この試みは、あくまでも「より大きなモデルサイズで学習を行えば、より良い性能のモデルが得られる」との仮説のもとに成り立っていました。しかしながら、Chinchillaの論文で指摘されているように、特定の計算資源量(compute budget)内では、最良のモデルとは大きいモデルではなく、小さめのモデルを多めのデータで学習した際に得られることが分かってきました。
また、Chinchillaのscaling lawは特定の学習時の計算資源制約において最良のモデルサイズとデータセット規模を決定づけるものであり、推論コスト(inference cost)を無視しています。
モデルを実際に運用する際においては、推論コストは非常に重要です。そのため、学習時においては大きいモデルを学習させたほうが特定の性能レベルに到達するまでのコストは安上がりかもしれませんが、そうではなく、より小さなモデルを大量のデータで学習させることこそが推論時まで考えた際においては理にかなっています。
LLaMA のアプローチ
Training Compute-Optimal Large Language Modelsでは10Bパラメーターのモデルを200B token学習させることを推奨していますが、LLaMAを学習させる過程において7Bで1 T Token学習させた後もモデル性能が停滞することなく、なお改善していることを発見しています。
データセットについて
使用されたデータセットについては以下にまとめられています。
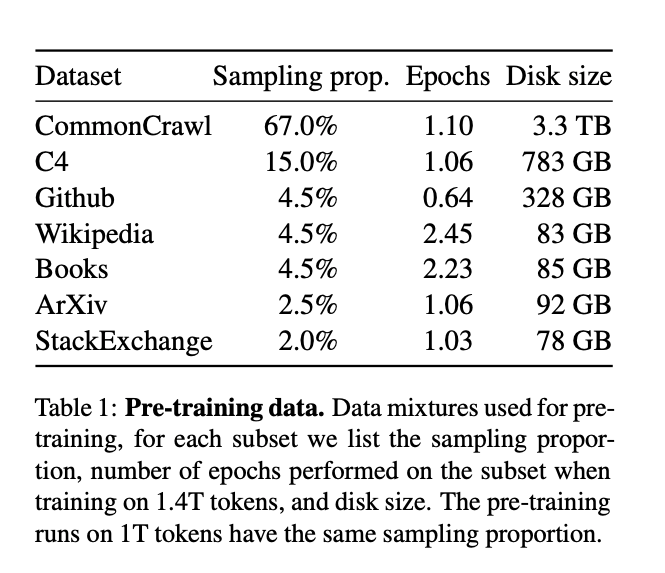
( https://arxiv.org/pdf/2302.13971.pdf より)
モデルアーキテクチャ
Pre-Normalization
学習安定性を高めるために、transformer sub-layerごとにinputの値をnormalizeしています。
(この工夫はLLaMA-2にも引き継がれています)
SwiGLU
ReLU 非線形関数をSwiGLUに置き換えました。
またPaLMと同様に、FFN(Feed-Forward Network)のintermediate sizeをhidden sizeの4倍から
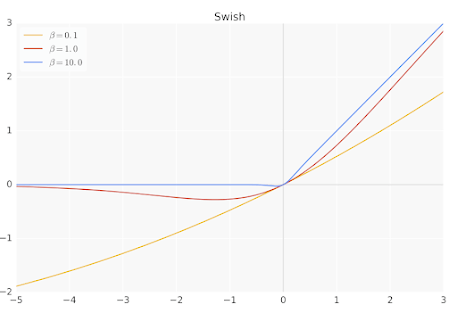
(https://www.ai-contentlab.com/2023/03/swishglu-activation-function.html より)
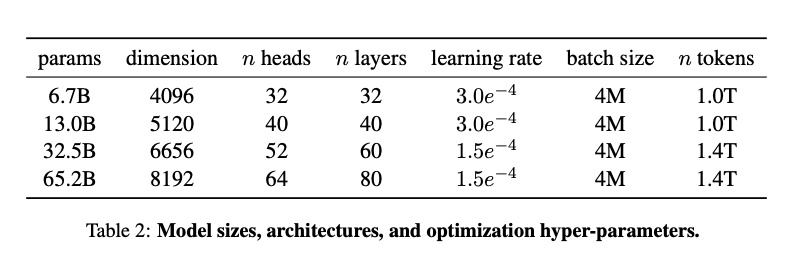
学習設定
学習設定については以下の通りです。後続のLLaMA-2と比較して異なる点は、32.5Bと65.2BのモデルにGrouped Query Attentionが導入されていない点と、Context Lengthが2048であり、LLaMA-2の4096に比べて短い点です。

(LLaMA より)
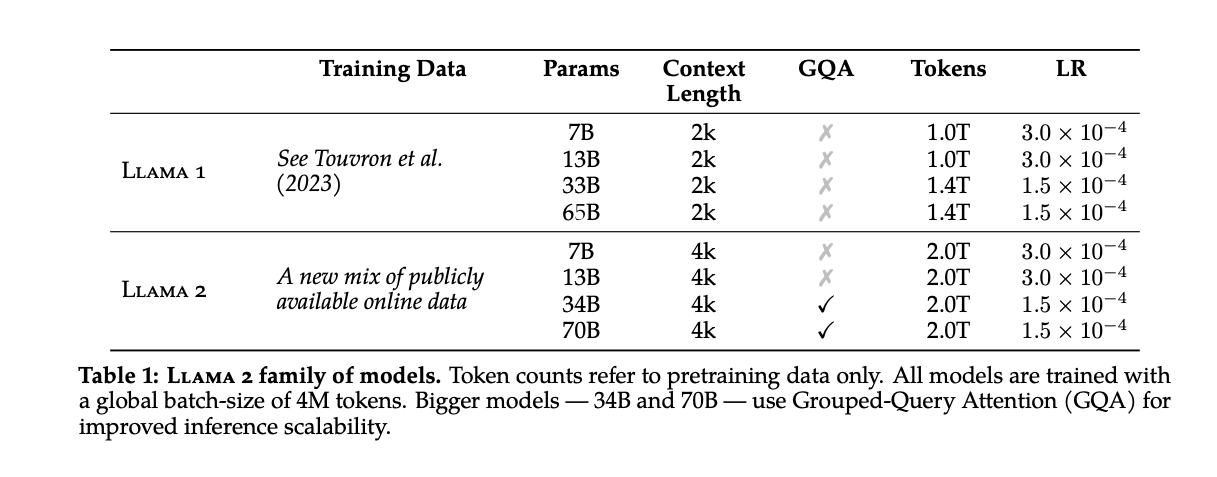
(LLaMA-2より)
Qwen
Qwen とは ?
中国Alibaba Qwen Teamが開発した言語モデルです。
1.8B, 7B, 14B, 70B の4つのモデルサイズが存在します。
中国語と英語を中心とする様々なドメイン(wide coverage of domains)を含む2.2T〜3.0T Tokenのデータにより学習されています。
特徴
Qwen-72B は前述のLLaMA-2 70Bをすべてのタスクで上回り、一部のタスクではGPT-3.5を上回ったと報告されています。
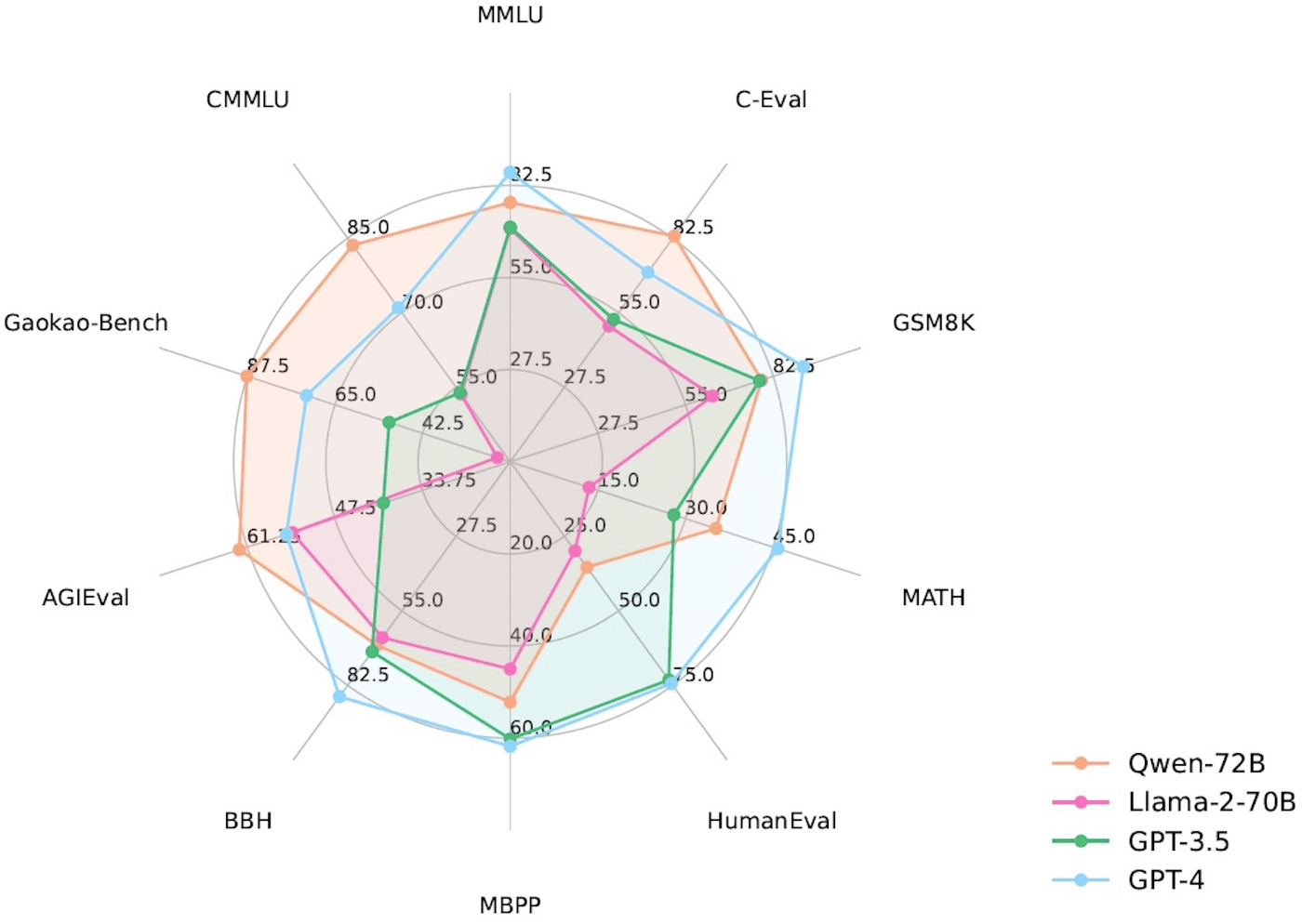
(https://github.com/QwenLM/Qwen より)
人間が実際に感じる性能は、ベンチマークのスコアだけでは一概に判断できないという点もあり、この結果から何か大きな事柄が言えるわけではありません。しかし、日本国内においても、日本語性能でスコア上でGPT-3.5やGPT-4を上回ろうという試みがある中で、中国語では可能であることが実証されたことは大きな意味を持つでしょう。
学習詳細
Technical Report: https://arxiv.org/abs/2309.16609
以下の内容は、Technical Reportからの抜粋です。適時、原文を参照頂けると幸いです。
事前学習 Pre-Training
データセット
The size of data has proven to be a crucial factor in developing a robust large language model, as highlighted in previous research
Chinchillaでの実験で示されたように、robustな大規模言語モデルを作成するにはデータサイズが非常に重要です。効果的な事前学習用データセットを作成するために、多様で様々な分野、様々なタスクを含むデータをQwenでは採用しています。主なデータソースとしては、webテキスト、百科事典、本、コードなどです。また、データセットの大部分は英語と中国語から構成されている多言語(multilingual)データセットです。
データセットの質を担保するために、webデータについては言語識別機(language identification tools)を利用してHTMLデータからテキストを抽出する作業を行っています。また、データの多様性を向上させるために、deduplication(重複除去)を行っています。質の悪いデータを除去するために、ルールベースの手法と、機械学習ベースの手法を統合しています。
Tokenization

( 再掲: https://arxiv.org/pdf/2309.16609.pdf より)
上図は、QwenのEncoding compression ratesを示しています。(注意: 大雑把に言うと小さい方が良いです。)
上記のようにTokenizationが効率的であるので、同じToken数でLLaMAなどと比較して多くの情報を伝えることが可能です。従来、巨大な語彙サイズ(vocabulary size)は下流タスクに悪影響を与えるものと思われてきました。(前述のBLOOMの例) しかしながら、Qwenでは語彙サイズを増加させたのにも関わらず、下流タスクの評価においては性能を維持できていたと報告しています。
Despite the increase in vocabulary size, our experiments have shown that QWEN maintains its performance levels in downstream evaluation.
Architecture
LLaMAアーキテクチャをベースにしているようです。
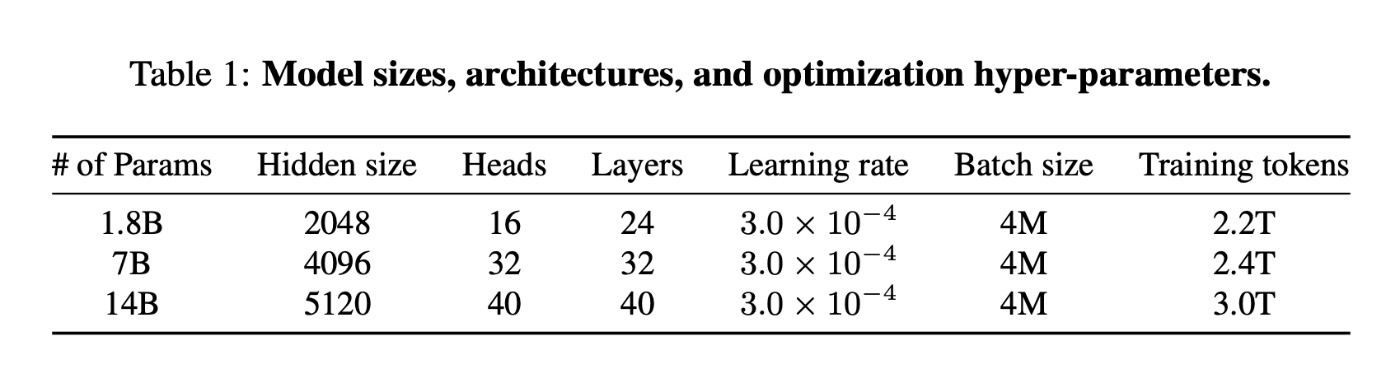
主なモデル構造についてはLLaMAと酷似しています。実際、以下のLLaMAのconfigと比較しても同じモデルパラメータサイズでは学習Token数以外は同じになっています。
(LLaMA: Open and Efficient Foundation Language Models より)
モデルの特徴は以下のとおりです。
-
untied embedding approach
LLaMA-2でも採用されていたように、input embeddingの重みと、output projectionの重みを共有せず、別々に保持する方針をとっています。Qwenでは予備実験を行い、メモリコストを犠牲にしてでも、untied embeeding approachをとることが性能面に寄与することが重要であると結論づけたようである。 -
Rotary Positional Embedding
RoPE(Rotary Positional Embedding)を利用しています。この点では、PaLM, LLaMAと同様ですが、特筆するべきはRoPEのinverse frequencey matrix(逆周波数行列)にFP32を利用していることです。FP16, BF16ではなく、FP32を利用することで高い精度を実現するための措置と説明されています。
-
Bias
PaLMの例に習い、ほとんどの層ではbias項を排除しているが、近年の他のモデルと異なる点として、QKV layerではbias項を追加していることが上げられています。この理由として、モデルの外挿能力を高めるためと説明されています。
-
Pre-Norm & RMSNorm
pre-normalizationは、post-normalizationと比較して学習安定性(training stability)が向上するため、近年、広く利用されている手法です。LLaMA-2からの変化はこの点ではありません。
-
SwiGLU
LLaMA-2でも採用されていたように、GeLUではなく活性化関数にSwiGLUを採用しています。Qwenでは実験を行い、GeLUなどの他の活性化関数よりもGLUベースの活性化関数の方が良いことを確かめているようです。
また、FFN(Feed_Forward Network)の次元数をGPTのhidden size(隠れサイズ)の4倍から8/3に変更しています。この点も、LLaMA-2で採用されている構造と一致しています。
Training
context length(=sequence length)は2048で学習しており、LLaMA-2の4096と比べると短くしています。またデータの用意方法としては、Megatron-LM, Megatron-DeepSpeedがサポートしている方法と同じ方法を採用しています。
This involves training the model to predict the next token based on the
context provided by the previous tokens. We train models with context lengths of 2048. To create batches of data, we shuffle and merge the documents, and then truncate them to the specified context lengths.
また学習時の計算効率を高めるためと、メモリ使用量を削減するためにFlash Attentionを利用しています。
OptimizerはAdamWを利用しており、
Learning RateのscheduleについてもLLaMA-2と同様に、peak時の10%に最終的になるようにdecayされています。
さいごに
今回の記事では、網羅的に様々なモデルにおける事前学習に焦点を当てて、情報を紹介してきました。また、自分が有している知識についても追加的な補足という形で共有させて頂きました。
今回の記事で分散並列学習に興味が湧いた方は、「大規模モデルを支える分散並列学習のしくみ Part 1」 をご覧ください。
Turing では自動運転モデルの学習や、自動運転を支えるための基盤モデルの作成のために分散並列学習の知見を取り入れた研究開発を行っています。興味がある方は、Turing の公式 Web サイト、採用情報などをご覧ください。話を聞きたいという方は私や AI チームのマネージャーの山口さん, CTOの青木さんの Twitter DM からでもお気軽にご連絡ください。

Discussion
素晴らしい記事をありがとうございます!大変よくまとめられていて非常に読みやすかったです!
ALiBiが使われない理由は、Attention Mapに細工をするという関係上Flash Attentionが使えなくなってしまうのを嫌っているというシンプルなものではないでしょうか?
また、Bloomのデータ量の話を少し補足させて頂きますと、当時のScaling Low検証論文として有名なのはopenAIのKaplan et al.でした。ここでは今知られているChinchilla則とは違い、computing budgetが100倍になった場合はモデルサイズを25倍、データ量を4倍するのが良い、とされていました(参考・岡野原さんの記事→https://xtech.nikkei.com/atcl/nxt/mag/rob/18/00007/00035/?P=2)
つまり、少々過剰にも思えるようなモデルサイズのスケーリングを行うことこそ、最小の計算資源で最大の精度を叩き出すためのスマートな手法だ!と、当時は思われていたわけです。
もっとも、176Bというパラメータからして、「GPT-3のマネがしたかった」というのが第一の動機でほぼ間違いないとは思いますが(笑)
情報ありがとうございます!
自分がきちんと理解できていないことが判明したので、時間をとってもう一度読んでみます。