はじめに
Turing 株式会社リサーチチームの藤井(@okoge_kaz)です。
Turingでは、自動運転を支える技術のひとつとして大規模言語モデル(Large Language Model: LLM)に注目しており、関連する技術の研究開発を行っています。
つい先日、大規模言語モデルの事前学習を行う際に用いられることが多いmicrosoft/Megatron-DeepSpeedが大きくupdateされました。(日本時間 2023/6/13, 2023/7/21に大きな変更がありました。)
具体的には、fork元であるNVIDIA/Megatron-LMの最新の変更を取り込むことを行ったようです。
セットアップ方法は以下の記事で紹介している通りで、変化はないのですが、Job Scriptの引数や、新機能を使用するためのTipsなど補足するべきことが多数存在します。
そのため、今回は前回の記事にて紹介できなかった点や変更点、マルチノード学習を行うための方法などについて詳しく解説します。
(Megatron-DeepSpeedとはどのようなものなのか?などの説明は、上述のPart1にて行っているのでそちらを確認してください。)
今回の記事にて行った実験のスクリプトなどを以下のRepositoryにpushしてあります。
適時参照ください。
setup方法
大規模言語モデル(LLM)の作り方 Megatron-DeepSpeed編 Part1の記事と同様なので詳しいsetup方法は省きます。代わりに環境によっては遭遇する可能性のあるエラーの解決方法を補足しておきます。
Makefileの書き換え
source .env/bin/activateで仮想環境に入っていても
make: Entering directory '~/kazuki/turing/Megatron-DeepSpeed/megatron/data'
10.x.xx.xxx: /usr/bin/python3: No module named pybind11
10.x.xx.xxx: g++ -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color helpers.cpp -o helpers.cpython-310-x86_64-linux-gnu.so
10.x.xx.xxx: [01m[Khelpers.cpp:10:10:[m[K [01;31m[Kfatal error: [m[Kpybind11/pybind11.h: No such file or directory
10.x.xx.xxx: 10 | #include [01;31m[K<pybind11/pybind11.h>[m[K
10.x.xx.xxx: | [01;31m[K^~~~~~~~~~~~~~~~~~~~~[m[K
10.x.xx.xxx: compilation terminated.
10.x.xx.xxx: make: Leaving directory '~/kazuki/turing/Megatron-DeepSpeed/megatron/data'
10.x.xx.xxx: Making C++ dataset helpers module failed, exiting.
仮想環境外の python3-configが使用される現象が発生しました。
もし、このようなエラーに遭遇した場合は
megatron/data/Makefileを
CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
CPPFLAGS += $(shell python3 -m pybind11 --includes)
LIBNAME = helpers
- LIBEXT = $(shell python3-config --extension-suffix)
+ LIBEXT = $(shell /home/kazuki/.pyenv/versions/3.11.4/bin/python3-config --extension-suffix)
default: $(LIBNAME)$(LIBEXT)
%$(LIBEXT): %.cpp
$(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
のように書き直すと良いでしょう。
mpi4py
Open MPIを用いてマルチノードで分散学習を行うためには、mpi4pyをpip installする必要があります。GitHubにて共有しているrequirements.txtをお使いの場合は、pip install -r requirements.txtですでにinstallされているはずです。
pdsh
deepspeedをlauncherに利用してマルチノード分散学習を行う場合は、pdshをinstallしておく必要があります。
pdshがインストールされていない状態でマルチノード学習を試みると以下のようなエラーに直面します。
Traceback (most recent call last):
File "~/kazuki/turing/Megatron-DeepSpeed/.env/bin/deepspeed", line 6, in <module>
main()
File "~/kazuki/turing/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/deepspeed/launcher/runner.py", line 522, in main
raise RuntimeError(f"launcher '{args.launcher}' not installed.")
RuntimeError: launcher 'pdsh' not installed.
deepspeedではデフォルトで、以下のようにPDSHを用いるようになっています。
laucherをpdshから変更することでエラーを回避する方法もありますが、ここではpdshをinstallする方法を示します。
sudo apt-get update -y
sudo apt-get install -y pdsh
これでマルチノード学習ができるようになったはずです。
1 node 8 GPU 実験
実際に学習できるか実験していきましょう。
まずはシングルノードにて学習してみましょう。
DeepSpeed Launcher
学習に使用するJob Scriptは以下のとおりです。
GitHub
Job Script
scripts/deepspeed/1.3B/ds_gpt_1.3B_dp2_tp2_pp2_zero1.sh
#!/bin/bash
## GPT-3 1.3B
model_size=1.3
num_layers=24
hidden_size=2048
num_attn_heads=16
sequence_length=2048
global_batch_size=512
lr=2.0e-4
min_lr=1.0e-6
init_std=0.013
### Training duration configs
## The main termination condition, original GPT-3 paper trains for 300B tokens.
train_tokens_in_billion=300
train_tokens=$((${train_tokens_in_billion} * 1000000000))
## train_samples is another termination condition and also affect the number of
## data samples to be indexed. Since we want to reach the train_tokens
## above, and data efficiency techniques may change num tokens in some samples,
## so we just set this config large enough to make sure we have enough
## processed data and don't terminate by train_samples.
train_samples=$((300 * 1000000000 * 2 / ${sequence_length}))
## Another wall-clock time termination condition in minutes. Set it large
## enough to avoid undesired early termination.
exit_duration=30000000
###############################################################################
### lr configs
## lr warmup and decay duration.
## Original GPT-3 paper uses 375M warmup tokens and 260B cosine decay tokens.
## Here we increase the warmup tokens to 3B since when batch size warmup is not
## used, there are more tokens per step. Thus we need to increase warmup tokens
## to make sure there are enough warmup steps, which is important for training
## stability.
lr_warmup_tokens_in_million=3000
lr_warmup_tokens=$((${lr_warmup_tokens_in_million} * 1000000))
## Here we changed the LR decay tokens to align with total train tokens, since
## related works (e.g., https://arxiv.org/abs/2203.15556) find that setting the
## learning rate schedule to match the number of training tokens results in the
## best final model quality
lr_decay_tokens_in_billion=${train_tokens_in_billion}
lr_decay_tokens=$((${lr_decay_tokens_in_billion} * 1000000000))
lr_decay_style="cosine"
###############################################################################
### Parallelism configs
## Model parallelism, 1 is no MP
mp_size=2 # tensor model parallel size
## Pipeline parallelism. To disable PP, set pp_size to 1 and no_pp to true.
## Note that currently both curriculum learning and random-LTD are NOT
## compatible with pipeline parallelism.
pp_size=2
no_pp="false"
## ZeRO-based data parallelism, stage=0 will disable ZeRO
zero_stage=1
## Total number of GPUs. ds_ssh is from DeepSpeed library.
num_gpus_pernode=8
num_node=1
num_gpus=$((${num_gpus_pernode} * ${num_node}))
## Data parallel size.
dp_size=$((${num_gpus} / ${pp_size} / ${mp_size}))
## Micro batch size per GPU
## Make sure that batch_size <= global_batch_size*pp_size*mp_size/num_gpus
## Reduce it manually if GPU OOM
# batch_size=$(( ${global_batch_size} / ${dp_size} ))
batch_size=2
###############################################################################
### Misc configs
log_interval=1
eval_iters=10
eval_interval=100
# num_save controls how frequent to save checkpoint. num_save=20 means that a
# checkpoint will be saved every 5% of training. For longer training you would
# want larger num_save to save more frequently, and vice versa.
num_save=100
estimated_train_iter=$((${train_tokens} / ${sequence_length} / ${global_batch_size}))
# save_interval=$((${estimated_train_iter} / ${num_save}))
save_interval=100
## Activation checkpointing saves GPU memory, but reduces training speed
# activation_checkpoint="true"
activation_checkpoint="false"
## Whether or not log optimizer states (norms, max abs values) to tensorboard.
## This is not required for training and might save GPU memory when turned off.
log_optimizer_state="true"
###############################################################################
### Output and data configs
current_time=$(date "+%Y.%m.%d_%H.%M.%S")
host="${HOSTNAME}"
seed=1234
num_workers=0
## Public the Pile dataset, can be downloaded at
## https://mystic.the-eye.eu/public/AI/pile_neox/ or
## https://the-eye.eu/public/AI/pile_neox/ Change data_home to where you
## store the pile_text_document.bin and pile_text_document.idx.
data_path="dataset/BookCorpusDataset_text_document"
vocab_path="dataset/gpt2-vocab.json"
merge_path="dataset/gpt2-merges.txt"
prescale_grad="true"
jobname="gpt_${model_size}B_tok${train_tokens_in_billion}B"
jobname="${jobname}_lr${lr}_min${min_lr}_w${lr_warmup_tokens_in_million}M_d${lr_decay_tokens_in_billion}B_${lr_decay_style}"
jobname="${jobname}_gbs${global_batch_size}_mbs${batch_size}_g${num_gpus}"
if [[ $zero_stage -gt 0 ]]; then
jobname="${jobname}_z${zero_stage}"
prescale_grad="false"
fi
if [[ $mp_size -gt 1 ]]; then
jobname="${jobname}_mp${mp_size}"
fi
if [ "${no_pp}" = "false" ]; then
jobname="${jobname}_pp${pp_size}"
fi
jobname="${jobname}_seed${seed}_rebase"
output_home="outputs"
log_path="${output_home}/log/"
checkpoint_path="${output_home}/checkpoint/${jobname}"
## Microsoft internal constraint: because tensorboard is logged by last rank,
## it's better to put the path in NFS instead of Blob.
tensorboard_dir="${output_home}/tensorboard/"
tensorboard_path="${tensorboard_dir}${jobname}_${host}_${current_time}"
mkdir -p ${log_path}
mkdir -p ${checkpoint_path}
mkdir -p ${tensorboard_path}
###############################################################################
data_options=" \
--vocab-file ${vocab_path} \
--merge-file ${merge_path} \
--data-path ${data_path} \
--data-impl mmap"
## If CL is used, make sure to set "--split" the same as what you used during
## offline data analysis&indexing.
megatron_options=" \
--override-opt_param-scheduler \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--tensor-model-parallel-size ${mp_size} \
--init-method-std ${init_std} \
--lr-decay-tokens ${lr_decay_tokens} \
--lr-warmup-tokens ${lr_warmup_tokens} \
--micro-batch-size ${batch_size} \
--exit-duration-in-mins ${exit_duration} \
--global-batch-size ${global_batch_size} \
--num-layers ${num_layers} \
--hidden-size ${hidden_size} \
--num-attention-heads ${num_attn_heads} \
--seq-length ${sequence_length} \
--max-position-embeddings ${sequence_length} \
--train-tokens ${train_tokens} \
--train-samples ${train_samples} \
--lr ${lr} \
--min-lr ${min_lr} \
--lr-decay-style ${lr_decay_style} \
--split 949,50,1 \
--log-interval ${log_interval} \
--eval-interval ${eval_interval} \
--eval-iters ${eval_iters} \
--save-interval ${save_interval} \
--weight-decay 0.1 \
--clip-grad 1.0 \
--hysteresis 2 \
--num-workers ${num_workers} \
--fp16 \
--seed ${seed} \
--load ${checkpoint_path} \
--save ${checkpoint_path} \
--no-async-tensor-model-parallel-allreduce \
--tensorboard-queue-size 1 \
--log-timers-to-tensorboard \
--log-batch-size-to-tensorboard \
--log-validation-ppl-to-tensorboard \
--tensorboard-dir ${tensorboard_path}"
if [ "${activation_checkpoint}" = "true" ]; then
megatron_options="${megatron_options} \
--checkpoint-activations"
fi
if [ "${log_optimizer_state}" = "true" ]; then
megatron_options="${megatron_options} \
--log-optimizer-states-to-tensorboard"
fi
config_json="scripts/deepspeed/config/ds_config_gbs${global_batch_size}_mbs${batch_size}_log${log_interval}_zero${zero_stage}.json"
template_json="examples_deepspeed/rebase/ds_config_gpt_TEMPLATE.json"
sed "s/GBSIZE/${global_batch_size}/" ${template_json} |
sed "s/MBSIZE/${batch_size}/" |
sed "s/LOG_INTERVAL/${log_interval}/" |
sed "s/ZERO_STAGE/${zero_stage}/" |
sed "s/PRESCALE_GRAD/${prescale_grad}/" \
>${config_json}
deepspeed_options=" \
--deepspeed \
--deepspeed_config ${config_json} \
--zero-stage ${zero_stage} \
--pipeline-model-parallel-size ${pp_size}"
if [[ "${no_pp}" = "true" ]]; then
deepspeed_options="${deepspeed_options} \
--no-pipeline-parallel"
fi
if [ "${activation_checkpoint}" = "true" ]; then
deepspeed_options="${deepspeed_options} \
--deepspeed-activation-checkpointing"
fi
## When saving checkpoint to a storage with cache, their could be consistency
## issue of the pointer to latest checkpoint. Here we find the correct pointer
## and broadcast it to all nodes.
iteration_file="$checkpoint_path/latest_checkpointed_iteration.txt"
iteration_file_2="$checkpoint_path/latest"
iteration=0
for ((node = 0; node <= num_node - 1; node++)); do
if $(ssh -q worker-"$node" "test -f \"$iteration_file\""); then
local_iteration=$(ssh -q worker-"$node" cat $iteration_file)
iteration=$((${local_iteration} > ${iteration} ? ${local_iteration} : ${iteration}))
fi
done
if [[ $iteration -gt 0 ]]; then
iteration_2="global_step${iteration}"
ds_ssh "echo $iteration > $iteration_file"
ds_ssh "echo $iteration_2 > $iteration_file_2"
fi
deepspeed pretrain_gpt.py ${megatron_options} \
${data_options} \
${deepspeed_options} \
--wandb-name "deepspeed-${jobname}" \
&>>${log_path}/${jobname}_${host}_${current_time}.log
job scriptのファイル名にあるdp2_tp2_pp2とは、Data Parallel Size=2, Tensor Parallel Size=2, Pipeline Parallel Size=2という意味です。
これらの用語の理解が怪しい方は以下の記事を参照ください。
実際に学習を行うには
bash scripts/deepspeed/1.3B/ds_gpt_1.3B_dp2_tp2_pp2_zero1.sh
で実行します。
学習が問題なく行えると、以下のようなLossの推移が得られるはずです。

2 node 16 GPU 実験
マルチノードでも学習を行ってみましょう。
上述したように、DeepSpeedでマルチノード学習を行う際は、pdshのinstallと、ノード間でパスフレーズなしSSHができる必要があります。スパコンを利用しているなどの理由で、そのような環境を整備できない場合は、Open MPIのmpirunによる学習に切り替えてください。
(launcherをdeepspeedからOpen MPIにすることによるスループットの低下は、私が試した限りでは確認できていません。そのため、deepspeedに固執する理由はないかと思います。)
DeepSpeed Launcher
GPT-3 13Bを A100(40GB) x 16枚(2node)でDeepSpeed laucherを用いて学習させてみましょう。
GitHub
Job Script
scripts/deepspeed/13B/ds_gpt_13B_dp4_tp4_pp1-flash-attn_zero2.sh
#!/bin/bash
## GPT-3 13B
model_size=13
num_layers=40
hidden_size=5120
num_attn_heads=40
global_batch_size=1024
lr=1.0e-4
min_lr=1.0e-6
init_std=0.008
sequence_length=2048
### Training duration configs
## The main termination condition, original GPT-3 paper trains for 300B tokens.
train_tokens_in_billion=300
train_tokens=$((${train_tokens_in_billion} * 1000 * 1000 * 1000))
## train_samples is another termination condition and also affect the number of
## data samples to be indexed. Since we want to reach the train_tokens
## above, and data efficiency techniques may change num tokens in some samples,
## so we just set this config large enough to make sure we have enough
## processed data and don't terminate by train_samples.
train_samples=$((300 * 1000000000 * 2 / ${sequence_length}))
## Another wall-clock time termination condition in minutes. Set it large
## enough to avoid undesired early termination.
exit_duration=30000000
###############################################################################
### lr configs
## lr warmup and decay duration.
## Original GPT-3 paper uses 375M warmup tokens and 260B cosine decay tokens.
## Here we increase the warmup tokens to 3B since when batch size warmup is not
## used, there are more tokens per step. Thus we need to increase warmup tokens
## to make sure there are enough warmup steps, which is important for training
## stability.
lr_warmup_tokens_in_million=3000
lr_warmup_tokens=$((${lr_warmup_tokens_in_million} * 1000000))
## Here we changed the LR decay tokens to align with total train tokens, since
## related works (e.g., https://arxiv.org/abs/2203.15556) find that setting the
## learning rate schedule to match the number of training tokens results in the
## best final model quality
lr_decay_tokens_in_billion=${train_tokens_in_billion}
lr_decay_tokens=$((${lr_decay_tokens_in_billion} * 1000000000))
lr_decay_style="cosine"
###############################################################################
### Parallelism configs
## Model parallelism, 1 is no MP
mp_size=4 # tensor model parallel size
## Pipeline parallelism. To disable PP, set pp_size to 1 and no_pp to true.
## Note that currently both curriculum learning and random-LTD are NOT
## compatible with pipeline parallelism.
pp_size=1
no_pp="true"
## ZeRO-based data parallelism, stage=0 will disable ZeRO
zero_stage=2
## Total number of GPUs
num_gpus_pernode=8
num_node=2
num_gpus=$((${num_gpus_pernode} * ${num_node}))
## Data parallel size.
dp_size=$((${num_gpus} / ${pp_size} / ${mp_size}))
## Micro batch size per GPU
## Make sure that batch_size <= global_batch_size*pp_size*mp_size/num_gpus
## Reduce it manually if GPU OOM
# batch_size=$(( ${global_batch_size} / ${dp_size} ))
batch_size=2
###############################################################################
### Misc configs
log_interval=1
eval_iters=10
eval_interval=100
# num_save controls how frequent to save checkpoint. num_save=20 means that a
# checkpoint will be saved every 5% of training. For longer training you would
# want larger num_save to save more frequently, and vice versa.
num_save=100
estimated_train_iter=$((${train_tokens} / ${sequence_length} / ${global_batch_size}))
# save_interval=$((${estimated_train_iter} / ${num_save}))
save_interval=100
## Activation checkpointing saves GPU memory, but reduces training speed
# activation_checkpoint="true"
activation_checkpoint="false"
### Output and data configs
current_time=$(date "+%Y.%m.%d_%H.%M.%S")
host="${HOSTNAME}"
seed=1234
num_workers=2
# dataset
data_path="dataset/BookCorpusDataset_text_document"
vocab_path="dataset/gpt2-vocab.json"
merge_path="dataset/gpt2-merges.txt"
prescale_grad="true"
# job name
jobname="gpt_${model_size}B_token${train_tokens_in_billion}B"
jobname="${jobname}_lr${lr}"
jobname="${jobname}_gbs${global_batch_size}_mbs${batch_size}_gpu${num_gpus}"
if [[ $zero_stage -gt 0 ]]; then
jobname="${jobname}_zero${zero_stage}"
prescale_grad="false"
fi
if [[ $mp_size -gt 1 ]]; then
jobname="${jobname}_tp${mp_size}"
fi
if [ "${no_pp}" = "false" ]; then
jobname="${jobname}_pp${pp_size}"
fi
# output dir
output_home="outputs"
log_path="${output_home}/log/"
checkpoint_path="${output_home}/checkpoint/${jobname}"
## Microsoft internal constraint: because tensorboard is logged by last rank,
## it's better to put the path in NFS instead of Blob.
tensorboard_dir="${output_home}/tensorboard/"
tensorboard_path="${tensorboard_dir}${jobname}_${host}_${current_time}"
mkdir -p ${log_path}
mkdir -p ${checkpoint_path}
mkdir -p ${tensorboard_path}
###############################################################################
data_options=" \
--vocab-file ${vocab_path} \
--merge-file ${merge_path} \
--data-path ${data_path} \
--data-impl mmap"
## If CL is used, make sure to set "--split" the same as what you used during
## offline data analysis&indexing.
megatron_options=" \
--override-opt_param-scheduler \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--tensor-model-parallel-size ${mp_size} \
--init-method-std ${init_std} \
--lr-decay-tokens ${lr_decay_tokens} \
--lr-warmup-tokens ${lr_warmup_tokens} \
--micro-batch-size ${batch_size} \
--exit-duration-in-mins ${exit_duration} \
--global-batch-size ${global_batch_size} \
--num-layers ${num_layers} \
--hidden-size ${hidden_size} \
--num-attention-heads ${num_attn_heads} \
--seq-length ${sequence_length} \
--max-position-embeddings ${sequence_length} \
--train-tokens ${train_tokens} \
--train-samples ${train_samples} \
--lr ${lr} \
--min-lr ${min_lr} \
--lr-decay-style ${lr_decay_style} \
--split 949,50,1 \
--log-interval ${log_interval} \
--eval-interval ${eval_interval} \
--eval-iters ${eval_iters} \
--save-interval ${save_interval} \
--weight-decay 0.1 \
--clip-grad 1.0 \
--hysteresis 2 \
--num-workers ${num_workers} \
--distributed-backend nccl \
--fp16 \
--seed ${seed} \
--load ${checkpoint_path} \
--save ${checkpoint_path} \
--no-async-tensor-model-parallel-allreduce \
--use-flash-attn \
--tensorboard-queue-size 1 \
--log-timers-to-tensorboard \
--log-batch-size-to-tensorboard \
--log-validation-ppl-to-tensorboard \
--tensorboard-dir ${tensorboard_path}"
if [ "${activation_checkpoint}" = "true" ]; then
megatron_options="${megatron_options} \
--checkpoint-activations"
fi
## Whether or not log optimizer states (norms, max abs values) to tensorboard.
## This is not required for training and might save GPU memory when turned off.
log_optimizer_state="true"
if [ "${log_optimizer_state}" = "true" ]; then
megatron_options="${megatron_options} \
--log-optimizer-states-to-tensorboard"
fi
# DeepSpeed Config
config_json="scripts/deepspeed/config/ds_config_gbs${global_batch_size}_mbs${batch_size}_log${log_interval}_zero${zero_stage}.json"
template_json="examples_deepspeed/rebase/ds_config_gpt_TEMPLATE.json"
sed "s/GBSIZE/${global_batch_size}/" ${template_json} |
sed "s/MBSIZE/${batch_size}/" |
sed "s/LOG_INTERVAL/${log_interval}/" |
sed "s/ZERO_STAGE/${zero_stage}/" |
sed "s/PRESCALE_GRAD/${prescale_grad}/" \
>${config_json}
deepspeed_options=" \
--deepspeed \
--deepspeed_config ${config_json} \
--zero-stage ${zero_stage} \
--pipeline-model-parallel-size ${pp_size}"
if [[ "${no_pp}" = "true" ]]; then
deepspeed_options="${deepspeed_options} \
--no-pipeline-parallel"
fi
if [ "${activation_checkpoint}" = "true" ]; then
deepspeed_options="${deepspeed_options} \
--deepspeed-activation-checkpointing"
fi
## When saving checkpoint to a storage with cache, their could be consistency
## issue of the pointer to latest checkpoint. Here we find the correct pointer
## and broadcast it to all nodes.
iteration_file="$checkpoint_path/latest_checkpointed_iteration.txt"
iteration_file_2="$checkpoint_path/latest"
iteration=0
for ((node = 0; node <= num_node - 1; node++)); do
if $(ssh -q worker-"$node" "test -f \"$iteration_file\""); then
local_iteration=$(ssh -q worker-"$node" cat $iteration_file)
iteration=$((${local_iteration} > ${iteration} ? ${local_iteration} : ${iteration}))
fi
done
if [[ $iteration -gt 0 ]]; then
iteration_2="global_step${iteration}"
ds_ssh "echo $iteration > $iteration_file"
ds_ssh "echo $iteration_2 > $iteration_file_2"
fi
# hostfile
source .env/bin/activate
export NCCL_DEBUG=INFO
deepspeed --num_nodes ${num_node} \
--num_gpus ${num_gpus_pernode} \
--hostfile scripts/deepspeed/hostfile \
pretrain_gpt.py \
${megatron_options} \
${data_options} \
${deepspeed_options} \
--wandb-name "deepspeed-flash-attn-${jobname}" \
&>>${log_path}/${jobname}_${host}_${current_time}.log
実際に学習を行ってみましょう。実行すると以下のようなLossの推移が得られるはずです。

今回の実験では、16枚のGPUをDP=4, TP=4, PP=1のように用いています。
またZeRO Stage2を用いているため、DPのメモリ冗長性をOptimizer State Partitioning, Gradient Partitioninigを用いて削減しています。
MPI Launcher
DeepSpeedではなくOpen MPIのmpirunを用いても学習を行ってみましょう。
今度は2.7BのモデルをDP=4, TP=2, PP=2 ZeRO Stage1にて学習してみましょう。
GitHub
Job Script
scripts/mpirun/2.7B/2.7B_dp4_tp2_pp2_zero1.sh
#!/bin/bash
# GPT-3 2.7B
model_size=2.7
num_layers=32
hidden_size=2560
num_attn_heads=32
global_batch_size=512
lr=1.6e-4
min_lr=1.0e-6
init_std=0.011
sequence_length=2048
## The main termination condition, original GPT-3 paper trains for 300B tokens.
train_tokens_in_billion=300
train_tokens=$((${train_tokens_in_billion} * 1000 * 1000 * 1000))
## train_samples is another termination condition and also affect the number of
## data samples to be indexed. Since we want to reach the train_tokens
## above, and data efficiency techniques may change num tokens in some samples,
## so we just set this config large enough to make sure we have enough
## processed data and don't terminate by train_samples.
train_samples=$((300 * 1000000000 * 2 / ${sequence_length}))
## Another wall-clock time termination condition in minutes. Set it large
## enough to avoid undesired early termination.
exit_duration=30000000
###############################################################################
### lr configs
## lr warmup and decay duration.
## Original GPT-3 paper uses 375M warmup tokens and 260B cosine decay tokens.
## Here we increase the warmup tokens to 3B since when batch size warmup is not
## used, there are more tokens per step. Thus we need to increase warmup tokens
## to make sure there are enough warmup steps, which is important for training
## stability.
lr_warmup_tokens_in_million=3000
lr_warmup_tokens=$((${lr_warmup_tokens_in_million} * 1000000))
## Here we changed the LR decay tokens to align with total train tokens, since
## related works (e.g., https://arxiv.org/abs/2203.15556) find that setting the
## learning rate schedule to match the number of training tokens results in the
## best final model quality
lr_decay_tokens_in_billion=${train_tokens_in_billion}
lr_decay_tokens=$((${lr_decay_tokens_in_billion} * 1000000000))
lr_decay_style="cosine"
###############################################################################
### Parallelism configs
## Model parallelism, 1 is no MP
mp_size=2 # tensor model parallel size
## Pipeline parallelism. To disable PP, set pp_size to 1 and no_pp to true.
## Note that currently both curriculum learning and random-LTD are NOT
## compatible with pipeline parallelism.
pp_size=2
no_pp="false"
## ZeRO-based data parallelism, stage=0 will disable ZeRO
zero_stage=1
## Total number of GPUs
num_gpus_pernode=8
num_node=2
num_gpus=$((${num_gpus_pernode} * ${num_node}))
## Data parallel size.
dp_size=$((${num_gpus} / ${pp_size} / ${mp_size}))
## Micro batch size per GPU
## Make sure that batch_size <= global_batch_size*pp_size*mp_size/num_gpus
## Reduce it manually if GPU OOM
# batch_size=$(( ${global_batch_size} / ${dp_size} ))
batch_size=2
###############################################################################
### Misc configs
log_interval=1
eval_iters=10
eval_interval=100
# num_save controls how frequent to save checkpoint. num_save=20 means that a
# checkpoint will be saved every 5% of training. For longer training you would
# want larger num_save to save more frequently, and vice versa.
num_save=100
estimated_train_iter=$((${train_tokens} / ${sequence_length} / ${global_batch_size}))
# save_interval=$((${estimated_train_iter} / ${num_save}))
save_interval=100
## Activation checkpointing saves GPU memory, but reduces training speed
# activation_checkpoint="true"
activation_checkpoint="false"
## Whether or not log optimizer states (norms, max abs values) to tensorboard.
## This is not required for training and might save GPU memory when turned off.
log_optimizer_state="true"
###############################################################################
### Output and data configs
current_time=$(date "+%Y.%m.%d_%H.%M.%S")
host="${HOSTNAME}"
seed=1234
num_workers=0
## Public the Pile dataset, can be downloaded at
## https://mystic.the-eye.eu/public/AI/pile_neox/ or
## https://the-eye.eu/public/AI/pile_neox/ Change data_home to where you
## store the pile_text_document.bin and pile_text_document.idx.
data_path="dataset/BookCorpusDataset_text_document"
vocab_path="dataset/gpt2-vocab.json"
merge_path="dataset/gpt2-merges.txt"
prescale_grad="true"
jobname="gpt_${model_size}B_tok${train_tokens_in_billion}B"
jobname="${jobname}_lr${lr}_min${min_lr}_w${lr_warmup_tokens_in_million}M_d${lr_decay_tokens_in_billion}B_${lr_decay_style}"
jobname="${jobname}_gbs${global_batch_size}_mbs${batch_size}_g${num_gpus}"
if [[ $zero_stage -gt 0 ]]; then
jobname="${jobname}_z${zero_stage}"
prescale_grad="false"
fi
if [[ $mp_size -gt 1 ]]; then
jobname="${jobname}_mp${mp_size}"
fi
if [ "${no_pp}" = "false" ]; then
jobname="${jobname}_pp${pp_size}"
fi
jobname="${jobname}_seed${seed}_rebase"
output_home="outputs"
log_path="${output_home}/log/"
checkpoint_path="${output_home}/checkpoint/${jobname}"
## Microsoft internal constraint: because tensorboard is logged by last rank,
## it's better to put the path in NFS instead of Blob.
tensorboard_dir="${output_home}/tensorboard/"
tensorboard_path="${tensorboard_dir}${jobname}_${host}_${current_time}"
mkdir -p ${log_path}
mkdir -p ${checkpoint_path}
mkdir -p ${tensorboard_path}
###############################################################################
data_options=" \
--vocab-file ${vocab_path} \
--merge-file ${merge_path} \
--data-path ${data_path} \
--data-impl mmap"
## If CL is used, make sure to set "--split" the same as what you used during
## offline data analysis&indexing.
megatron_options=" \
--override-opt_param-scheduler \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--tensor-model-parallel-size ${mp_size} \
--init-method-std ${init_std} \
--lr-decay-tokens ${lr_decay_tokens} \
--lr-warmup-tokens ${lr_warmup_tokens} \
--micro-batch-size ${batch_size} \
--exit-duration-in-mins ${exit_duration} \
--global-batch-size ${global_batch_size} \
--num-layers ${num_layers} \
--hidden-size ${hidden_size} \
--num-attention-heads ${num_attn_heads} \
--seq-length ${sequence_length} \
--max-position-embeddings ${sequence_length} \
--train-tokens ${train_tokens} \
--train-samples ${train_samples} \
--lr ${lr} \
--min-lr ${min_lr} \
--lr-decay-style ${lr_decay_style} \
--split 949,50,1 \
--log-interval ${log_interval} \
--eval-interval ${eval_interval} \
--eval-iters ${eval_iters} \
--save-interval ${save_interval} \
--weight-decay 0.1 \
--clip-grad 1.0 \
--hysteresis 2 \
--num-workers ${num_workers} \
--distributed-backend nccl \
--fp16 \
--seed ${seed} \
--load ${checkpoint_path} \
--save ${checkpoint_path} \
--no-async-tensor-model-parallel-allreduce \
--tensorboard-queue-size 1 \
--log-timers-to-tensorboard \
--log-batch-size-to-tensorboard \
--log-validation-ppl-to-tensorboard \
--tensorboard-dir ${tensorboard_path}"
if [ "${activation_checkpoint}" = "true" ]; then
megatron_options="${megatron_options} \
--checkpoint-activations"
fi
if [ "${log_optimizer_state}" = "true" ]; then
megatron_options="${megatron_options} \
--log-optimizer-states-to-tensorboard"
fi
# DeepSpeed Config
config_json="scripts/deepspeed/config/ds_config_gbs${global_batch_size}_mbs${batch_size}_log${log_interval}_zero${zero_stage}.json"
template_json="examples_deepspeed/rebase/ds_config_gpt_TEMPLATE.json"
sed "s/GBSIZE/${global_batch_size}/" ${template_json} |
sed "s/MBSIZE/${batch_size}/" |
sed "s/LOG_INTERVAL/${log_interval}/" |
sed "s/ZERO_STAGE/${zero_stage}/" |
sed "s/PRESCALE_GRAD/${prescale_grad}/" \
>${config_json}
deepspeed_options=" \
--deepspeed \
--deepspeed_config ${config_json} \
--zero-stage ${zero_stage} \
--pipeline-model-parallel-size ${pp_size}"
if [[ "${no_pp}" = "true" ]]; then
deepspeed_options="${deepspeed_options} \
--no-pipeline-parallel"
fi
if [ "${activation_checkpoint}" = "true" ]; then
deepspeed_options="${deepspeed_options} \
--deepspeed-activation-checkpointing"
fi
## When saving checkpoint to a storage with cache, their could be consistency
## issue of the pointer to latest checkpoint. Here we find the correct pointer
## and broadcast it to all nodes.
iteration_file="$checkpoint_path/latest_checkpointed_iteration.txt"
iteration_file_2="$checkpoint_path/latest"
iteration=0
for ((node = 0; node <= num_node - 1; node++)); do
if $(ssh -q worker-"$node" "test -f \"$iteration_file\""); then
local_iteration=$(ssh -q worker-"$node" cat $iteration_file)
iteration=$((${local_iteration} > ${iteration} ? ${local_iteration} : ${iteration}))
fi
done
if [[ $iteration -gt 0 ]]; then
iteration_2="global_step${iteration}"
ds_ssh "echo $iteration > $iteration_file"
ds_ssh "echo $iteration_2 > $iteration_file_2"
fi
source .env/bin/activate
mpirun -np $num_gpus \
--npernode $num_gpus_pernode \
-H 10.2.72.135:8,10.2.72.136:8 \
-x MASTER_ADDR=10.2.72.135 \
-x MASTER_PORT=16500 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x PATH \
-mca pml ob1 -mca btl ^openib \
python pretrain_gpt.py \
${megatron_options} \
--use-mpi \
--wandb-name "mpirun-${jobname}" \
${data_options} \
${deepspeed_options} \
&> ${log_path}/${jobname}_${host}_${current_time}.log
実際に学習を行ってみましょう。
上手く学習が行えている場合は、以下のようなLossの推移が得られるはずです。

Flash Attention
Megatron-DeepSpeedはFlash Attentionをサポートしています。
Transoformerにおいてself-attention moduleはsequence lengthの2乗で時間、空間計算量を要する部分であり、効率向上を考える上で極めて重要な部分です。そのため、Attentionアルゴリズムを変更し、どうにかして高速かつ、メモリをあまり食わないAttentionを実現することは非常に価値があります。
Flash-Attentionは計算時間とメモリ使用量の両方を削減する技術であり、実測において効率性能向上が確認されている効率的なAttention技術の1つです。
SetUp
実際にMegatron-DeepSpeedの中で使用できるように環境をSetUpしていきましょう。
FlashAttention 1.x
公式のセットアップ方法通りにすれば、問題なくセットアップ可能です。
同じ手順を以下に示します。
Megatron-DeepSpeed/にて以下を実行します。
pip install packaging cmake
# install triton
git clone -b legacy-backend https://github.com/openai/triton
cd triton/python/
pip install -e .
cd ../..
git clone -b v1.0.4 https://github.com/HazyResearch/flash-attention
cd flash-attention
Megatron-DeepSpeed/flash-attention/flash_attn/flash_attn_triton.pyを以下のように変更します。(Microsoftの方の変更例です)
変更ができたら、以下を実行します。
python setup.py install
installには多少の時間がかかります。
terminal上に表示される文字を眺めながら気楽に待ちましょう。
Using /home/kazuki/Megatron-DeepSpeed/.env/lib/python3.11/site-packages
Finished processing dependencies for flash-attn==1.0.4
のような表示が出れば install 成功です。🎉
FlashAttention 2
公式のinstall方法通りにinstallを行えば問題ありません。
pytorch, ninjaはinstall済みなはずですが、確認しましょう。
> pip list | grep torch
torch 2.0.1+cu118
> pip list | grep ninja
ninja 1.11.1
次にpackagingをinstallします。(手順通りに行っている場合はinstallされているはずです)
> pip install packaging
ninjaが正しく動作しているかどうか確認します。
> ninja --version
> echo $?
0
0ではない値が返ってきた場合は、ninjaが正しく動作していない可能性が濃厚です。
pip uninstall -y ninja && pip install ninja
を行い、再installしましょう。
pip installによりinstallする場合は
pip install flash-attn --no-build-isolation
によりinstallを行ってください。
この記事ではflash-attn==2.0.0.post1にて動作確認を行っています。
現在のflash-attnのversion一覧を確認したい場合はこちらを確認してください。
source から install を行う場合は、
git clone git@github.com:Dao-AILab/flash-attention.git
cd flash-attention
python setup.py install
としてください。
使用方法
job scriptに --use-flash-attnを追加するだけです。
以下に具体例を示します。
性能評価
ABCI A100(40GB) x 16 (2node)の環境にて GPT-3 1.3B のモデルをDP=16, TP=1, PP=1, ZeRO Stage1にて学習した際の比較値を示します。(micro-batch-size=1)
-
FlashAttentionなしの場合

上記のようになり 118 TFLOPsほどの性能になりました。
-
FlashAttention 2を用いた場合

上記のようなTFLOPsの推移となり148TFLOPsが安定的に出ていました。
あくまで一例ですが、FlashAttentionによる性能の向上が確認できるかと思います。
実装部分
megatron/model/transformer.pyで利用されています。
flash_attention 1.x, 2両方が動作するような工夫が以下のようにされています。
try:
# FlashAttention (1.x)
from flash_attn.flash_attn_interface import flash_attn_unpadded_func
except ImportError:
flash_attn_unpadded_func = None
try:
# FlashAttention-2
from flash_attn.flash_attn_interface import flash_attn_varlen_func
except ImportError:
flash_attn_varlen_func = None
# Use FlashAttention-2 when available
self.flash_attn_func = flash_attn_unpadded_func if flash_attn_varlen_func is None else flash_attn_varlen_func
Appendix
Wisteria 上での実験
Turingのリサーチチームで第8回 GPUミニキャンプに参加してきました。
その際に、東京大学のWisteria/BDEC-01を利用させていただきました。
wisteria上でもMegatron-DeepSpeedを用いた多ノード分散学習実験を行いましたので、そこで得られた環境構築の知見についても紹介します。
環境構築
module loadを行い、CUDA11.8用のrequirements.txtを用いてinstallを行います。
interactiveジョブによりGPU環境を確保してからinstallを行います。
pjsub --interact -L node=1 -L elapse=02:00:00 -L rscgrp=tut1-interactive-a -g gt01
module load nvidia/22.11 cuda/11.8
module use /work/share/modulefiles/nvidia/22.11
module load ompi-cuda/4.1.5-11.8
source .env/bin/activate
which python
pip install --upgrade pip
pip --version
CUDA11.8用のrequirements.txtを利用
pip install -r requirements.txt
NVIDIA/apexのinstall
module unload nvidia/22.11
module load gcc-toolset/9
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
ABCI 上での実験
ABCI(AI Briding Cloud Infrastructure: AI橋渡しクラウド)という産業技術総合研究所(産総研)が構築、運用する計算インフラストラクチャが存在します。学生の研究目的や、国、企業の研究所などの研究開発目的でしばしば利用されます。
この記事で紹介した実験をABCI上で実行できるように、環境構築方法、具体的なJob Scriptの作成方法などについて解説します。(基本的には、上述の方法と変わりありませんが、細部は異なります)
Python のセットアップ
> pyenv install 3.11
Downloading Python-3.11.4.tar.xz...
-> https://www.python.org/ftp/python/3.11.4/Python-3.11.4.tar.xz
Installing Python-3.11.4...
Installed Python-3.11.4 to /home/acf15649kv/.pyenv/versions/3.11.4
> pyenv shell 3.11.4
> python --version
Python 3.11.4
python -m venv .env
source .env/bin/activate
pip install --upgrade pip
Python3.11での動作が確認できています。大規模言語モデル(LLM)の作り方 Megatron-DeepSpeed編 Part1ではPython3.10.10を用いた環境構築を行っていますが、Python3.11の高速化の恩恵を多少であっても受けたいため、今回はPython3.11での環境構築を行いました。
なお、pyenvをinstallしなくともmodule load python/3.11/3.11.2でPython3.11.2をABCI上で利用することができます。
pip install
GPUを確保している環境でないとpip installに失敗するライブラリがあるため、計算資源を確保しましょう。(以下ではV100ノードを使用していますが、A100でも構いません)
qrsh -g <group-name> -l rt_F=1 -l h_rt=3:00:00
source /etc/profile.d/modules.sh
module load cuda/11.8/11.8.0
module load cudnn/8.6/8.6.0
module load nccl/2.16/2.16.2-1
module load hpcx/2.12
cd <working-directory>
source .env/bin/activate
pip install -r requirements.txt
NVIDIA/apex の install
NVIDIA/apexをinstallします。
頻繁に変更がpushされているため、install方法をInstallation/From Source/Linuxから確認してください。
下記のコマンドは2023/7/23現在のinstall方法です。
git clone git@github.com:NVIDIA/apex.git
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
上手くinstallができると以下のような表示が出ます。
Building wheel for apex (pyproject.toml) ... done
Created wheel for apex: filename=apex-0.1-cp311-cp311-linux_x86_64.whl size=40404813 sha256=b34c8f80588564fe734836a484a36dd51c44debce07dfd3ed888e026efa45067
Stored in directory: /tmp/40214194.1.gpu/pip-ephem-wheel-cache-0jxe53ec/wheels/7a/ee/24/d4ca3d6dc74ad8b5c5a42951f226ed88dcff09777b19c38e68
Successfully built apex
Installing collected packages: apex
Successfully installed apex-0.1
apexのinstall時に以下のようなものが出るはずです。
出ていない場合は、installに失敗しているはずです。
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/2] c++ -MMD -MF /home/acf15649kv/llm-jp/Megatron-DeepSpeed/apex/build/temp.linux-x86_64-cpython-311/csrc/megatron/scaled_softmax.o.d -pthread -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -fPIC -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/apex/csrc -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include/torch/csrc/api/include -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include/TH -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include/THC -I/apps/cuda/11.8.0/include -I/apps/cudnn/8.6.0/cuda11.8/include -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/include -I/home/acf15649kv/.pyenv/versions/3.11.4/include/python3.11 -c -c /home/acf15649kv/llm-jp/Megatron-DeepSpeed/apex/csrc/megatron/scaled_softmax.cpp -o /home/acf15649kv/llm-jp/Megatron-DeepSpeed/apex/build/temp.linux-x86_64-cpython-311/csrc/megatron/scaled_softmax.o -O3 -DVERSION_GE_1_1 -DVERSION_GE_1_3 -DVERSION_GE_1_5 -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=scaled_softmax_cuda -D_GLIBCXX_USE_CXX11_ABI=0 -std=c++17
[2/2] /apps/cuda/11.8.0/bin/nvcc -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/apex/csrc -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include/torch/csrc/api/include -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include/TH -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include/THC -I/apps/cuda/11.8.0/include -I/apps/cudnn/8.6.0/cuda11.8/include -I/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/include -I/home/acf15649kv/.pyenv/versions/3.11.4/include/python3.11 -c -c /home/acf15649kv/llm-jp/Megatron-DeepSpeed/apex/csrc/megatron/scaled_softmax_cuda.cu -o /home/acf15649kv/llm-jp/Megatron-DeepSpeed/apex/build/temp.linux-x86_64-cpython-311/csrc/megatron/scaled_softmax_cuda.o -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr --compiler-options ''"'"'-fPIC'"'"'' -O3 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ --expt-relaxed-constexpr --expt-extended-lambda -DVERSION_GE_1_1 -DVERSION_GE_1_3 -DVERSION_GE_1_5 -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=scaled_softmax_cuda -D_GLIBCXX_USE_CXX11_ABI=0 -gencode=arch=compute_70,code=compute_70 -gencode=arch=compute_70,code=sm_70 -std=c++17
/home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages/torch/include/c10/util/irange.h(54): warning #186-D: pointless comparison of unsigned integer with zero
detected during:
もし、このような出力が出ず、Successfully installed apex-0.1と表示されてしまった場合は、git checkout <commit-id>にて前のコミットに遡ると良いでしょう。
上手くinstallできていないのにも関わらずSuccessfully installed apex-0.1と出力される事例は過去に何度か観測されています。
FlashAttention の install (Optional)
flash-attentionを使う場合は、flash-attnをinstallする必要があります。
下記の方法では、sourceからinstallしています。(2023/7/21時点は、abciの環境上ではpip installで上手くinstallすることができませんでした)
interactive jobで環境構築を行います。
qrsh -g <group-name> -l rt_F=1 -l h_rt=3:00:00
cd Megatron-DeepSpeed
source .env/bin/activate
source /etc/profile.d/modules.sh
module load cuda/11.8/11.8.0
module load cudnn/8.9/8.9.2
module load nccl/2.16/2.16.2-1
module load hpcx/2.12
git clone git@github.com:Dao-AILab/flash-attention.git
cd flash-attention
python setup.py install
sourceからのinstall 時には時間がかかります。
気長に待ちましょう。
Using /home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages
Searching for cmake==3.27.0
Best match: cmake 3.27.0
Adding cmake 3.27.0 to easy-install.pth file
Installing cmake script to /home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/bin
Installing cpack script to /home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/bin
Installing ctest script to /home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/bin
Using /home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages
Searching for MarkupSafe==2.1.3
Best match: MarkupSafe 2.1.3
Adding MarkupSafe 2.1.3 to easy-install.pth file
Using /home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages
Searching for mpmath==1.3.0
Best match: mpmath 1.3.0
Adding mpmath 1.3.0 to easy-install.pth file
Using /home/acf15649kv/llm-jp/Megatron-DeepSpeed/.env/lib/python3.11/site-packages
Finished processing dependencies for flash-attn==2.0.0.post1
無事installできました。
dataset, vocab fileのdownload
データセット、vocab fileをdownloadしましょう。
cd dataset
bash download_vocab.sh
bash download_books.sh
実験
実際にABCIのAノード(A100 40GB)にて動作確認を行ったJob ScriptとLossの推移、TFLOPsの推移, 1秒あたり処理したToken数を記します。micro-batch-sizeを限界まで増やしている訳ではないので、もう少しTFLOPsを改善することができるかと思います。
ZeRO Stage 1 DP=16 (A100(40GB)x8 x 2 node)
GPT-3 1.3B
DP=16, TP=1, PP=1, ZeRO Stage1
GitHub
Lossの推移
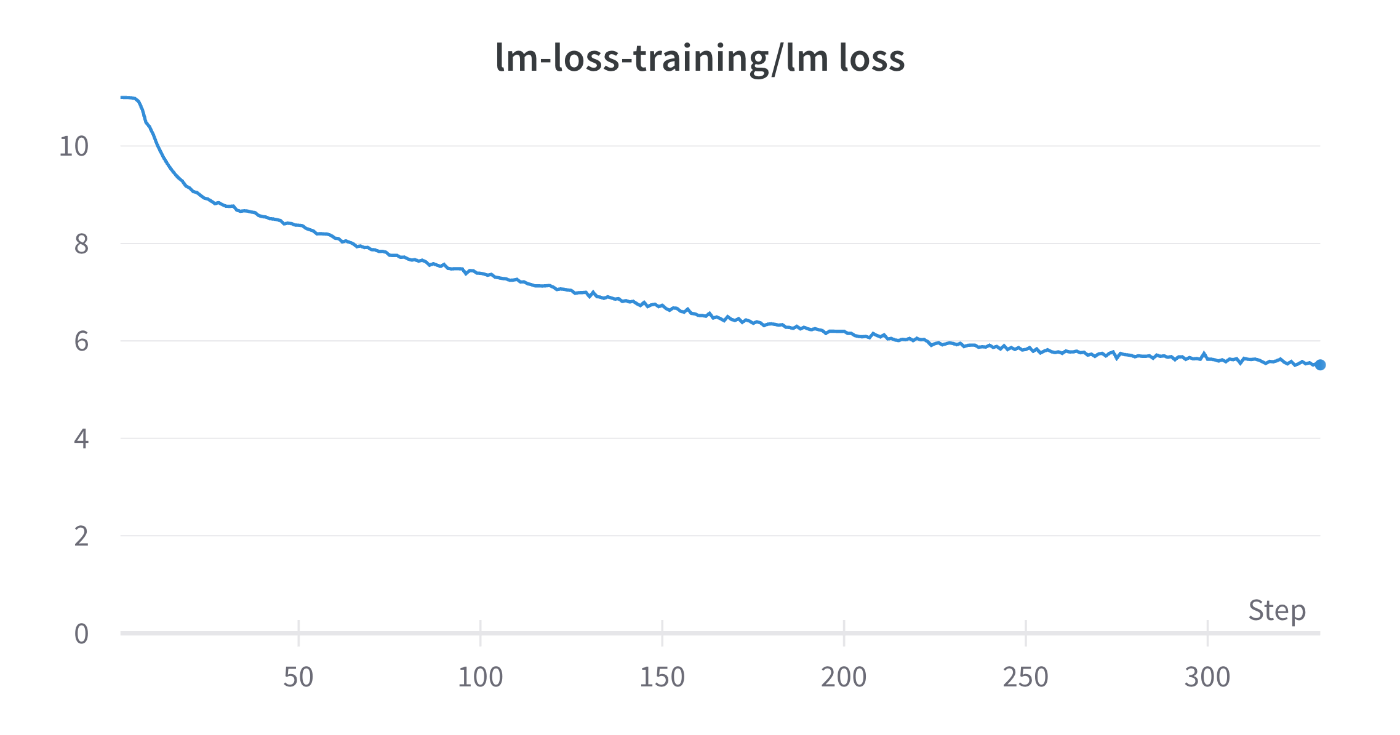
TFLOPs: 118

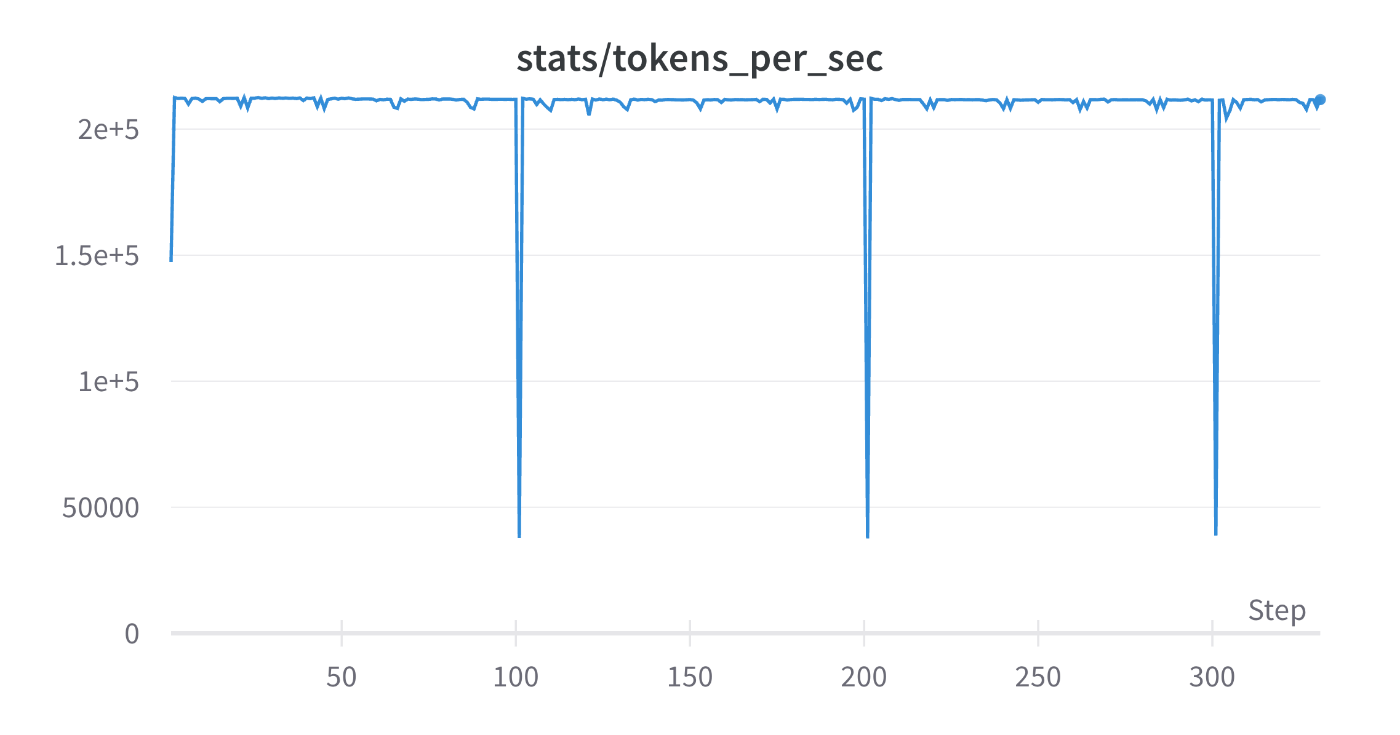
tokens_per_sec: 2.1e5
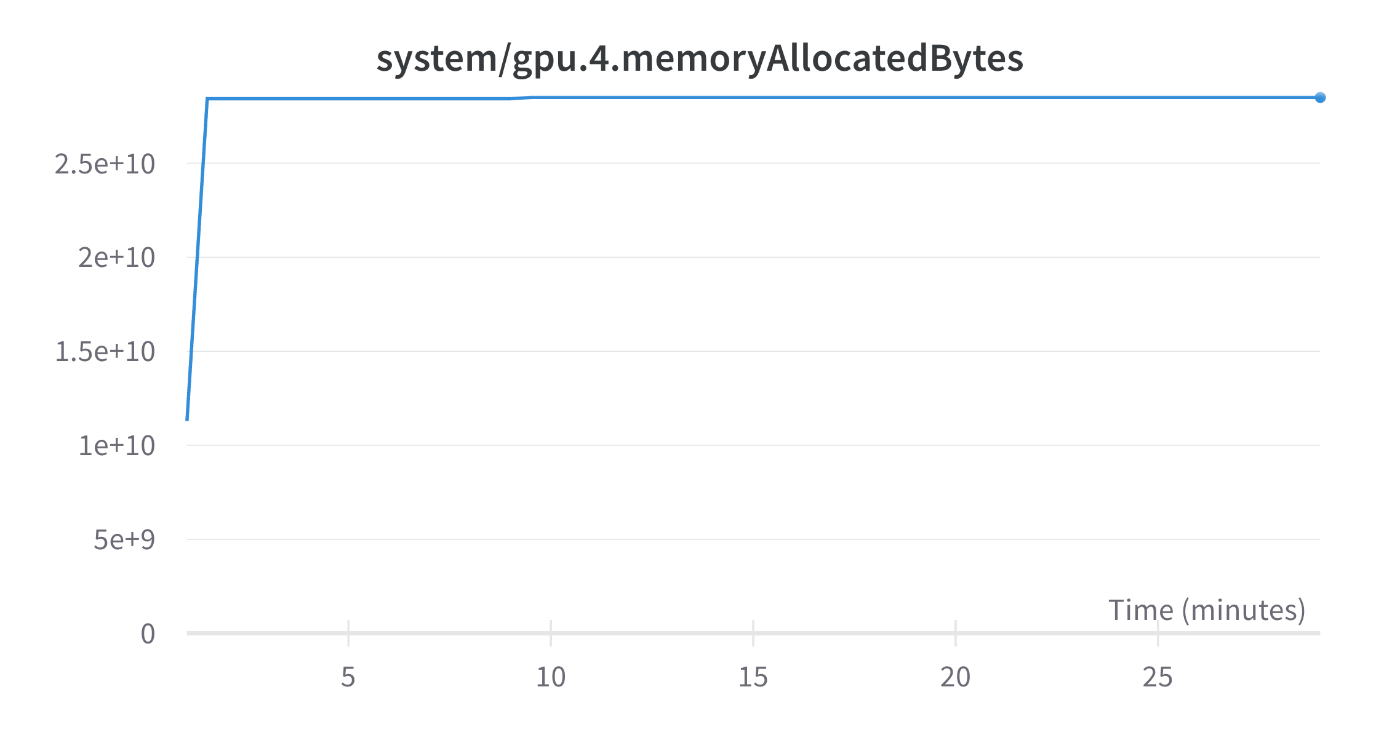
memoryAllocatedBytes: 2.85e10
ZeRO Stage 1 DP=16 (A100(40GB)x8 x 2 node) with Flash Attention
GPT-3 1.3B
DP=16, TP=1, PP=1, ZeRO Stage1, Flash Attention 2
GitHub
Lossの推移

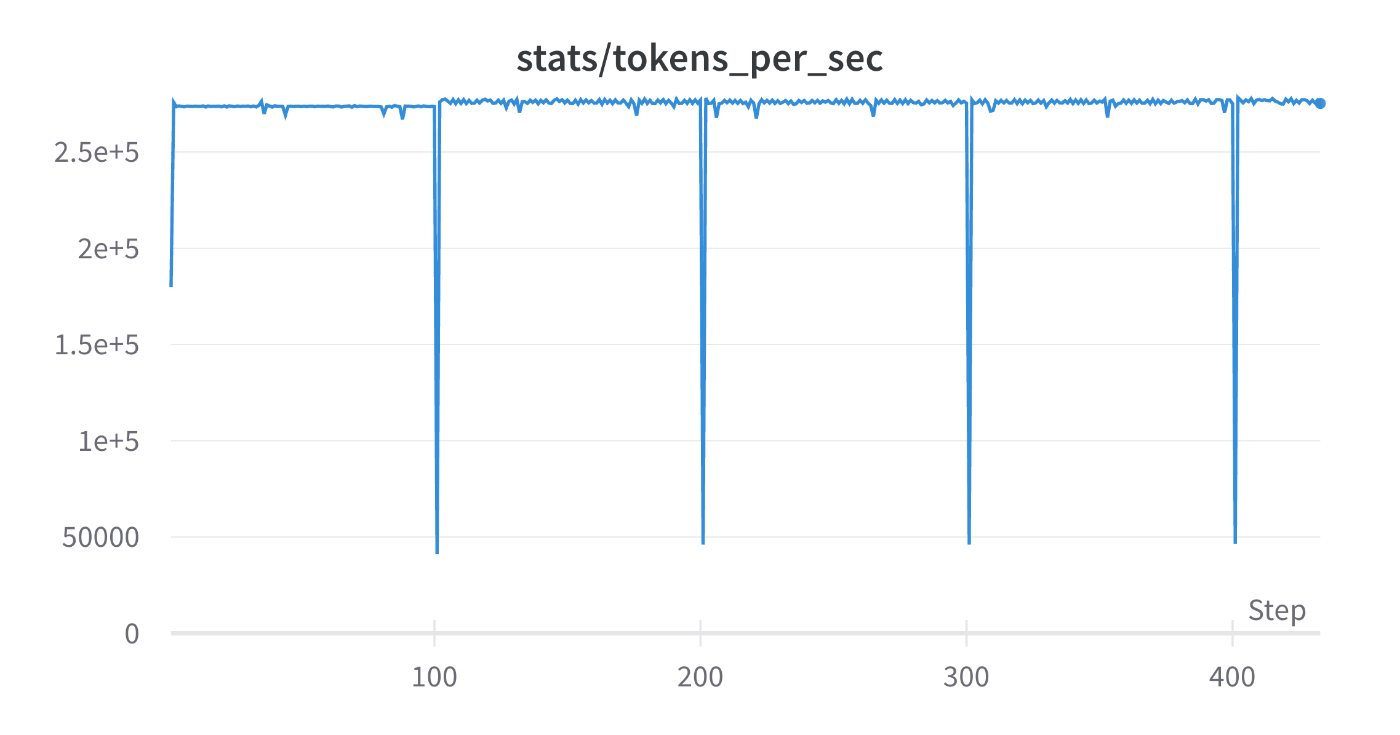
TFLOPs: 152

tokens_per_sec: 2.75e5
memoryAllocatedBytes: 2.52e10

TFLOPs, tokens_per_secからFlash Attentionによるスループットの向上が確認できます。
また、memoryAllocatedBytesからFlash Attentionによるメモリ使用量の削減効果も確認できます。
ZeRO Stage 2 DP=16 (A100 (40GB)x8 x 2node)
GPT-3 1.3B
DP=16, TP=1, PP=1, ZeRO Stage2
GitHub
Lossの推移
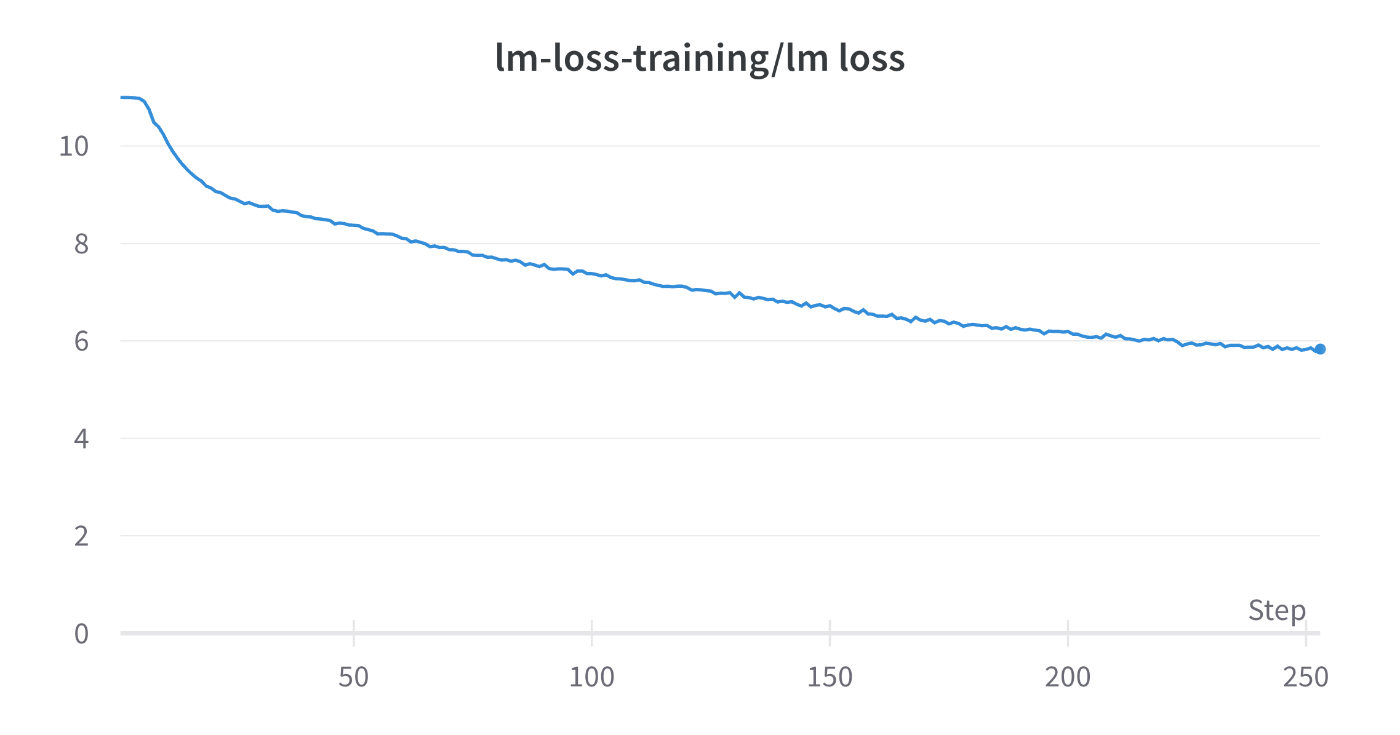
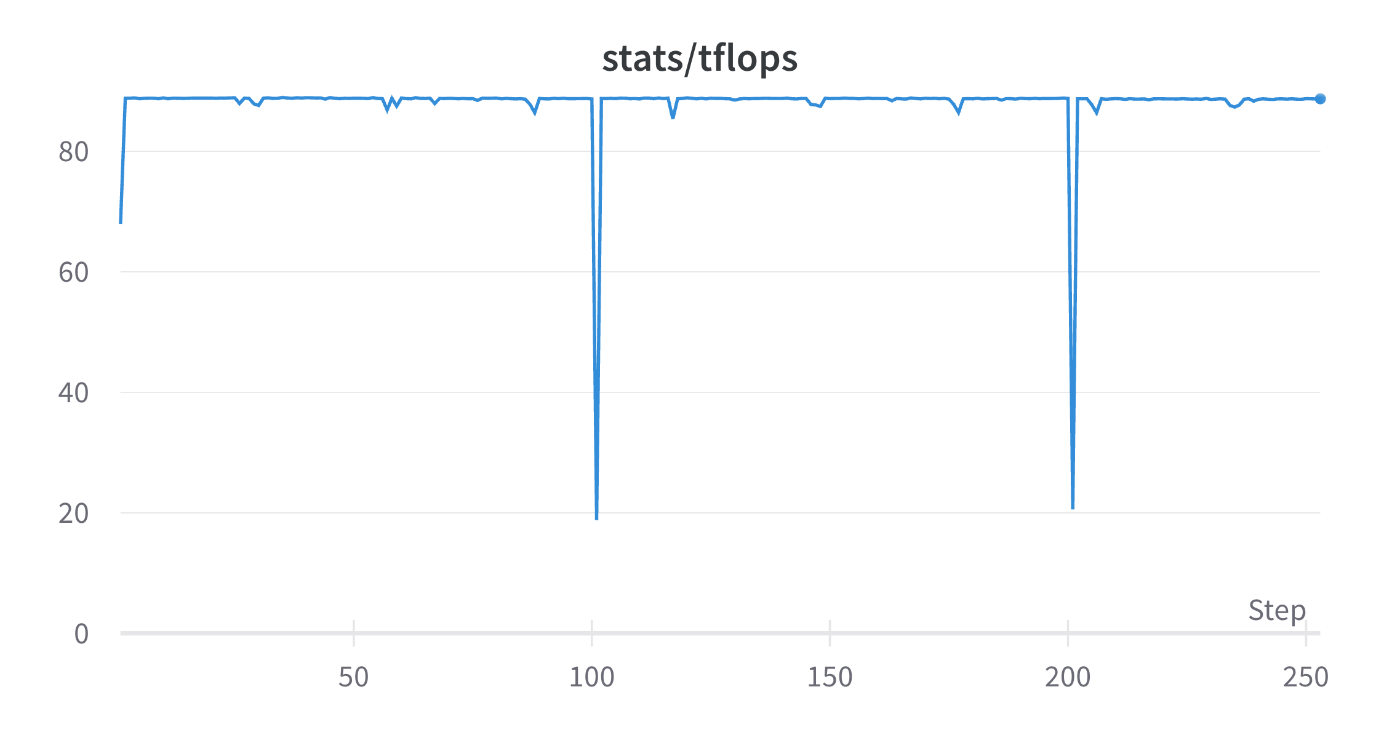
TFLOPs: 89
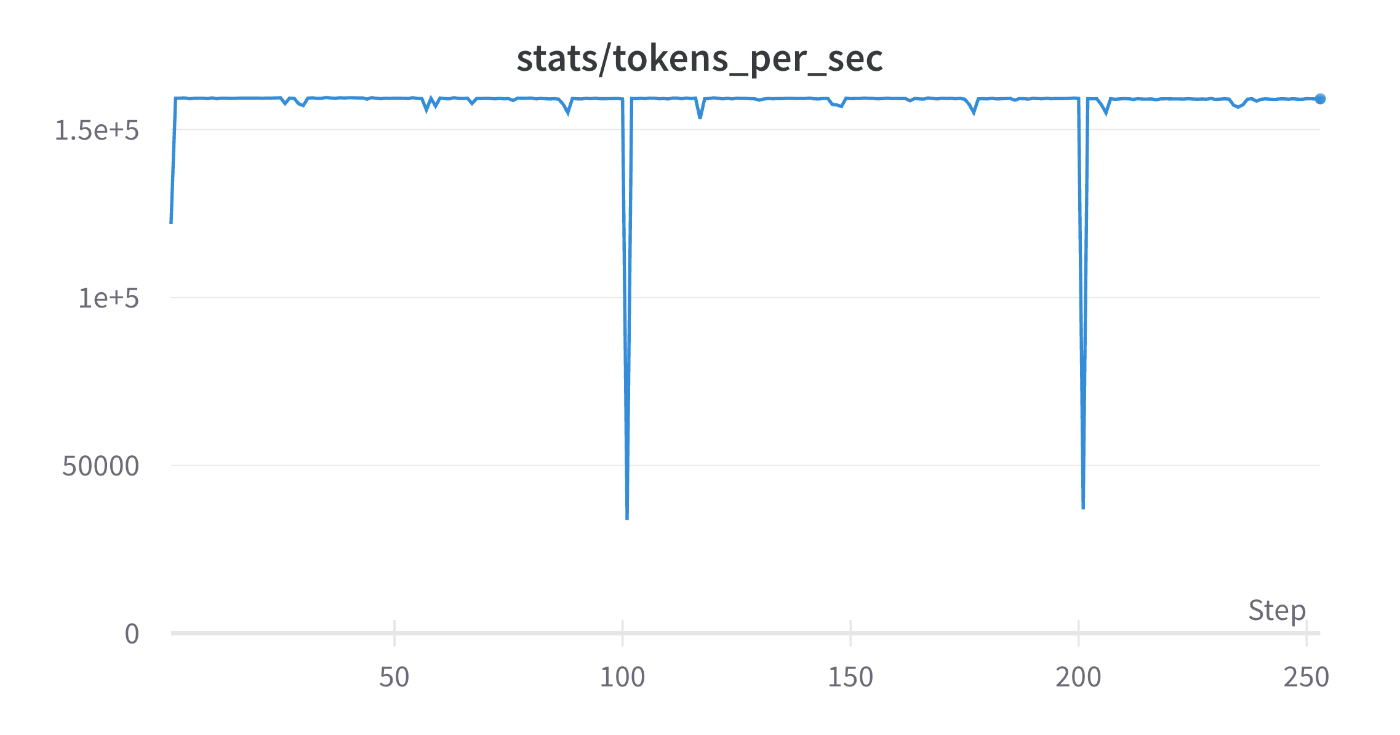
tokens_per_sec: 1.59e5
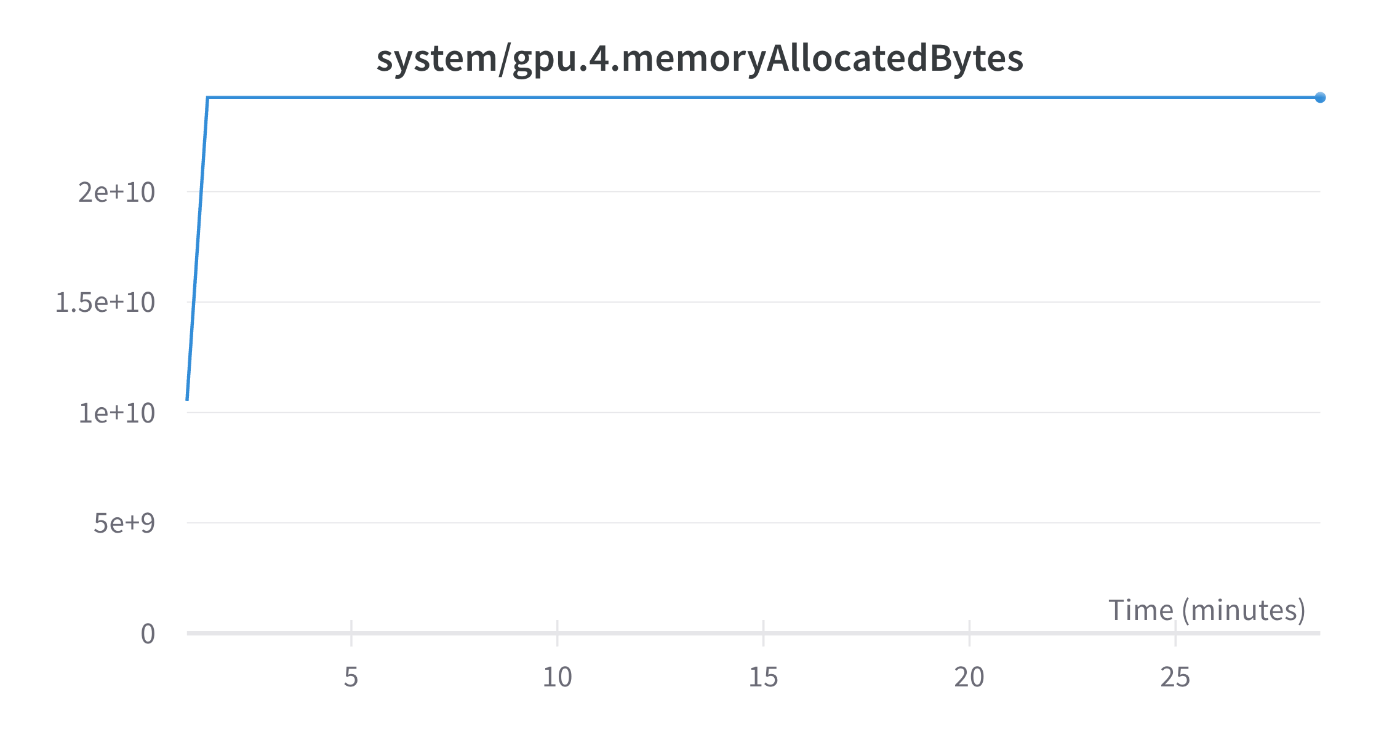
memoryAllocatedBytes: 2.4e10
micro-batch-size=1に固定している状態だと、ZeRO Stage1 -> ZeRO Stage2とすることによりTFLOPsが低下しています。
しかし、このデータからZeRO Stage1の方がスループットが出やすいと結論づけることは早計です。
ZeRO Stage2ではmemoryAllocatedBytesが低下しているため、ZeRO Stage1のときよりmicro-batch-sizeを増やすことができ、結果として限界のTFLOPsにおいては性能に変化がでない可能性もあります。
(続編の記事にて、このあたりの調査やさらなるサーベイを行い理論的な背景を補足できればと思います。)
ZeRO DP=16 Stage3 (A100 (40GB)x8 x 2node)
GPT-3 1.3B
DP=16, TP=1, PP=1, ZeRO Stage2
GitHub
Loss:
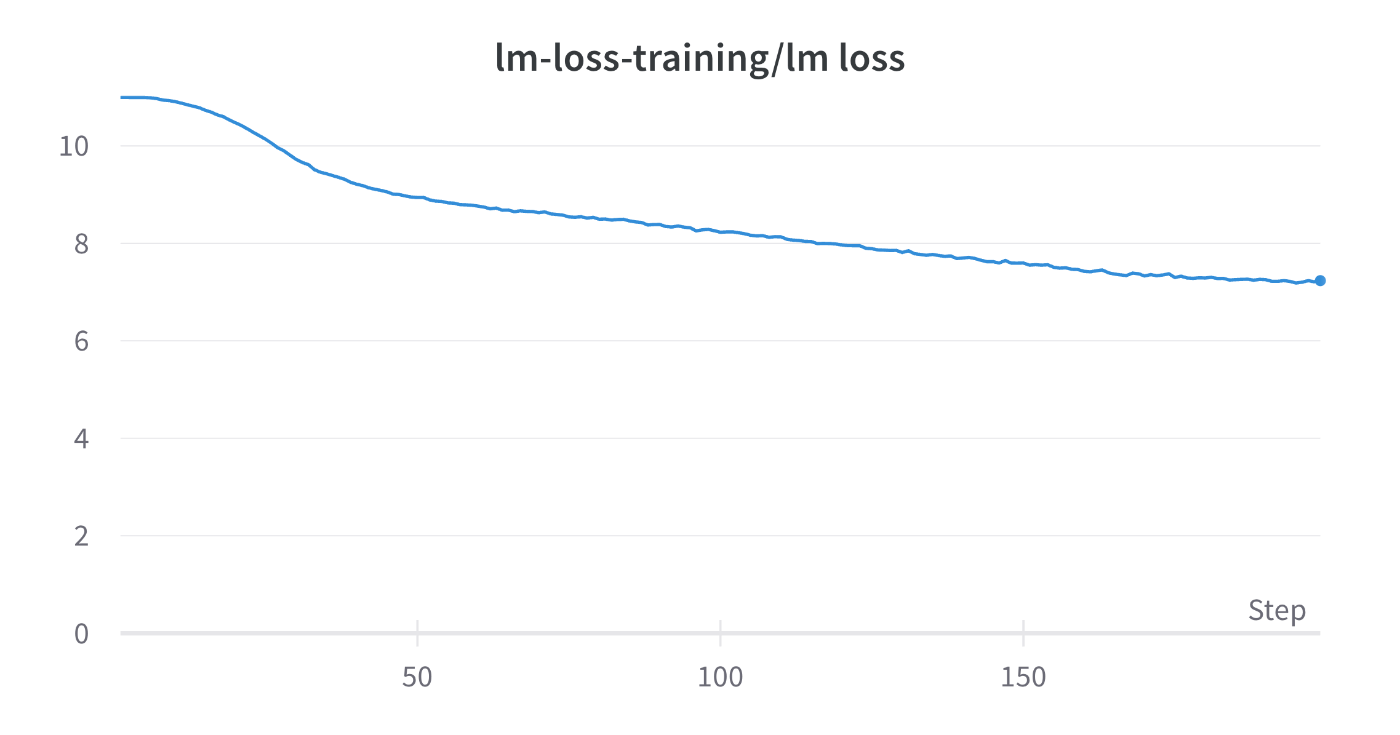
TFLOPs: 71
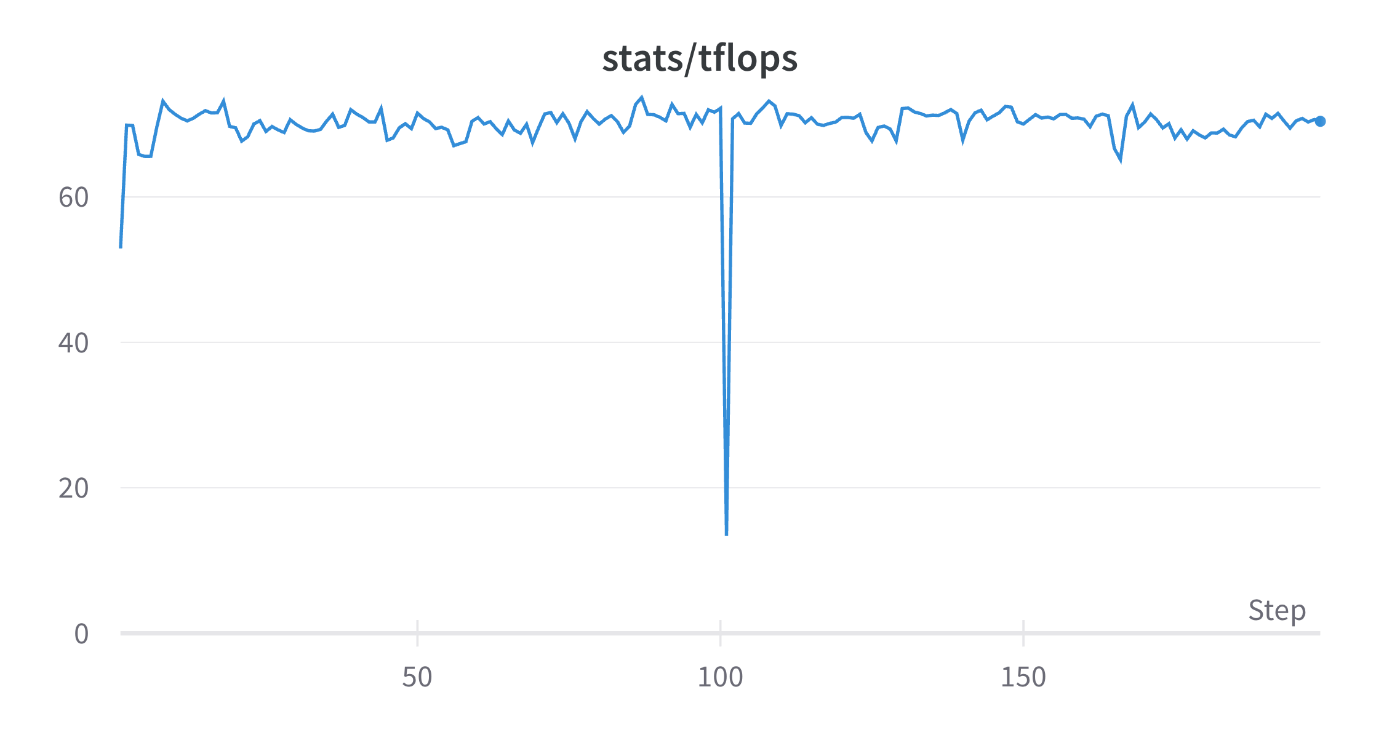
tokens_per_sec: 1.25e5
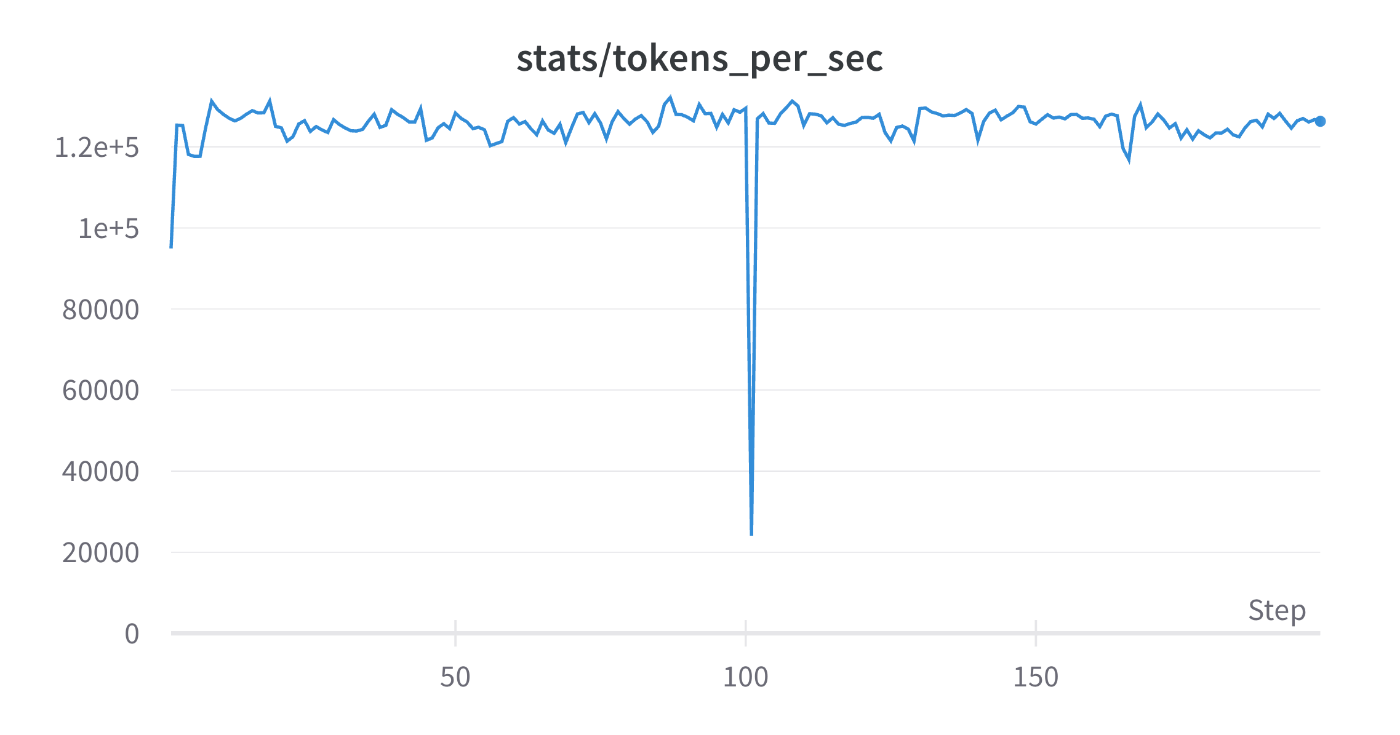
memoryAllocatedBytes: 2.61e10
ZeRO Stage 3にすることで、最低でも50%ほど通信コストが増加するためTFLOPsが低下している結果は想定通りです。
しかし、memoryAllocatedBytesがwandbのloggingにおいては増加してしまっています。
本来は
ZeRO Stage 1 DP=8 TP=1, PP=2 (A100 (40GB)x8 x 2node)
GPT-3 2.7B
DP=8, TP=1, PP=2, ZeRO Stage1
GitHub
Loss:
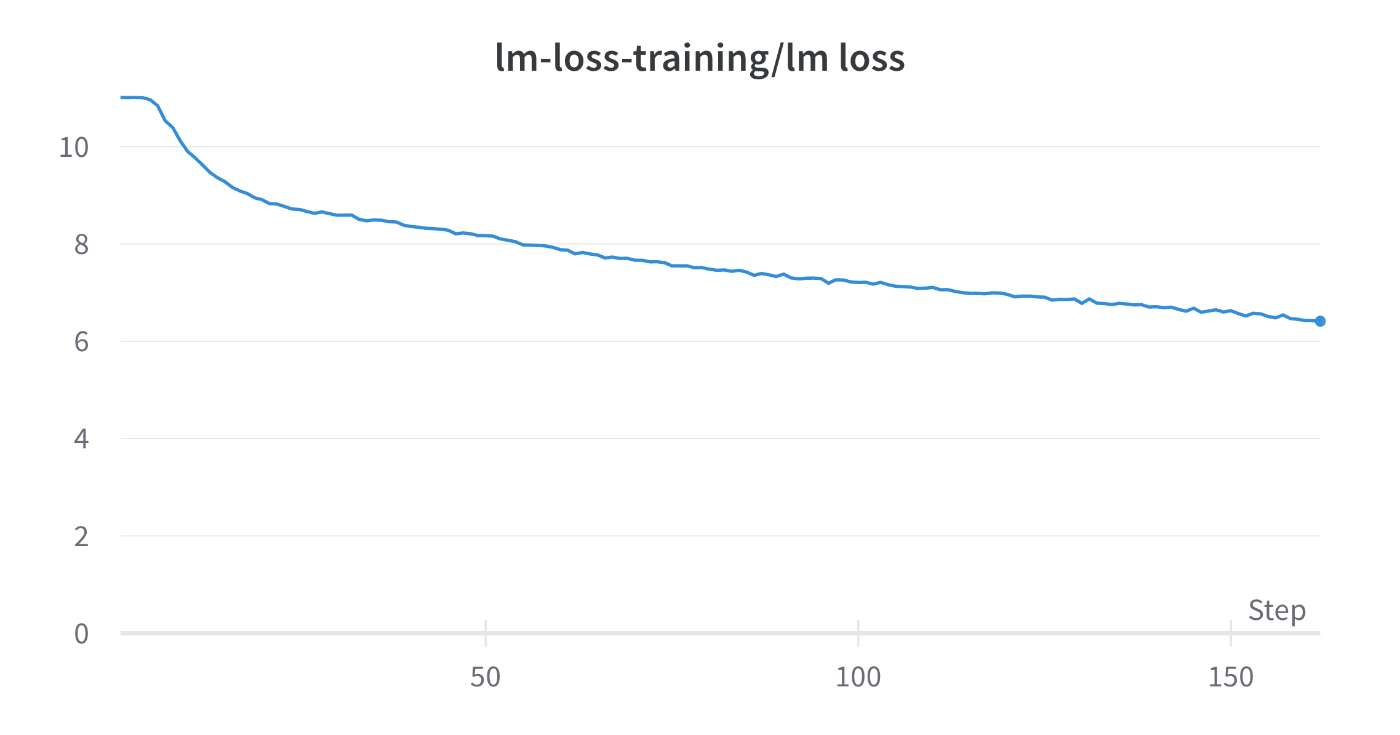
TFLOPs: 112

tokens_per_sec: 1.01e5

memoryAllocatedBytes: 3.31e10

memoryAllocatedBytesの値を見る限り、まだまだmicro-batch-sizeを増加させることができそうです。TFLOPsを向上させる余地は十分にありそうです。
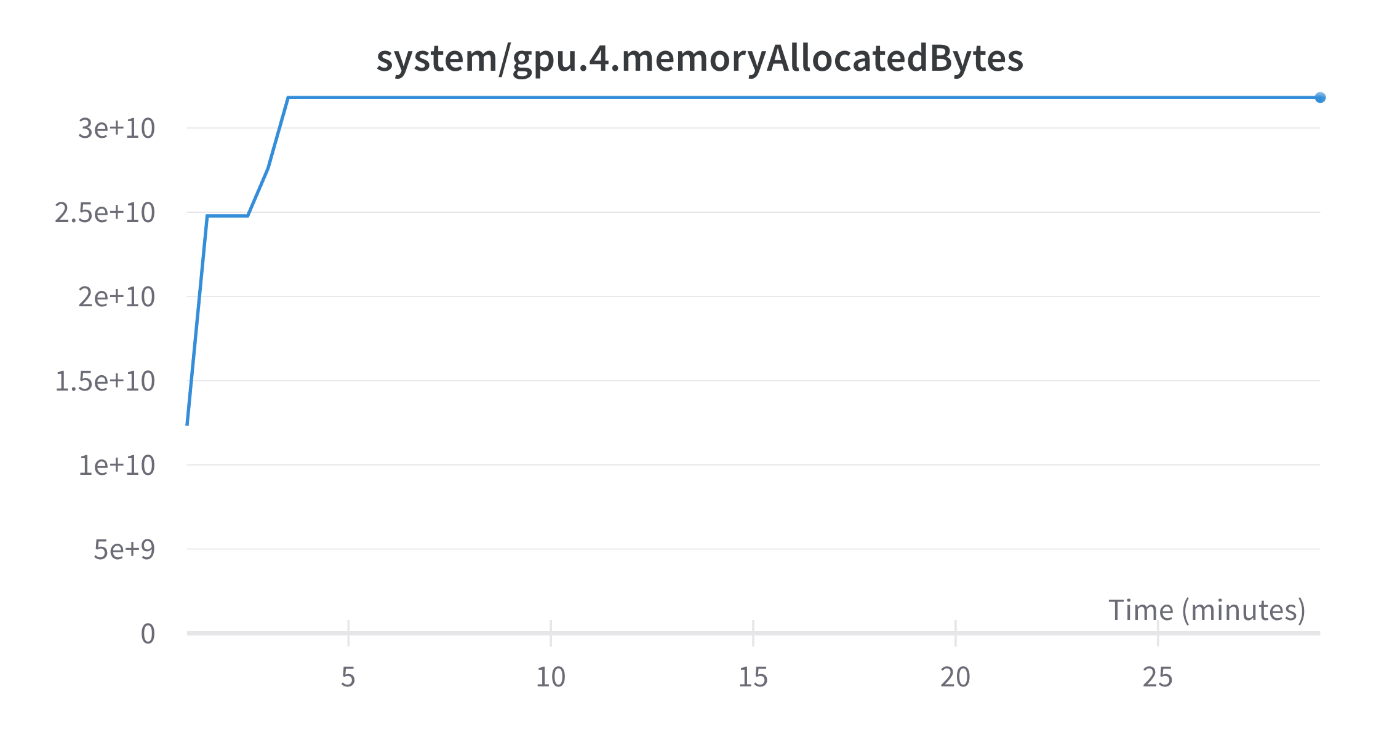
ZeRO Stage 1 DP=1, TP=4, PP=4 (A100 (40GB)x8 x 2node)
GPT-3 13B
DP=1, TP=4, PP=4, ZeRO Stage 1
GitHub
Loss:

TFLOPs: 88

tokens_per_sec: 0.173e5

急激にtokens_per_secが小さくなった理由の1つはDP=1であるからです。
モデルサイズが大きくなるに従い、TPやPPなどに割く割合が多くなり、同じGPU数ではDP degreeが小さくならざるを得ない状態になっています。
memoryAllocatedBytes: 3.18e10
ZeRO Stage 1 DP=1, TP=8, PP=4 (A100 (40GB)x8 x 4node) with Flash Attention
GPT-3 30B
DP=1, TP=8, PP=4, ZeRO Stage1, Flash Attention 2
これまでは2nodeで学習を行っていましたが、30Bの学習には4nodeを用いました。
GitHub
Loss:
TFLOPs: 118

tokens_per_sec: 0.201e5

memoryAllocatedBytes: 3.13e10

つづく
この記事ではMegatron-DeepSpeedを用いて事前学習を行う具体的な方法について説明しました。
今回の記事で分散並列学習に興味が湧いた方は、「大規模モデルを支える分散並列学習のしくみ Part 1」 をご覧ください。
また今回の記事における実験で使用したdeepspeedのZeROというメモリ削減技術については 「大規模モデルを支える分散並列学習のしくみ Part 2」 にて解説する予定です。
また、「大規模言語モデル(LLM)の作り方 GPT-NeoX編」では、今回と同様にGPT-NeoXで学習を行う方法について説明しています。
Turing では自動運転モデルの学習や、自動運転を支えるための基盤モデルの作成のために分散並列学習の知見を取り入れた研究開発を行っています。興味がある方は、Turing の公式 Web サイト、採用情報などをご覧ください。話を聞きたいという方は私や AI チームのディレクターの山口さん, CTOの青木さんの Twitter DM からでもお気軽にご連絡ください。

Discussion
Part2の記事、ありがとうございます!
参考にさせていただきます!