はじめに
Turing 株式会社のリサーチチームでインターンをしている東京工業大学 B4 横田研究室の藤井(@okoge_kaz)です。
大規模言語モデル(Large Language Model: LLM)への注目がGPT-4のリリース以降高まっていますが、LLMを作るための知見は十分に共有されているとは言い難いと個人的に感じています。
Turingでは、Vision and Language, Video and Languageなどのマルチモーダルなモデルの研究開発を行っている一環として、Megatron-DeepSpeed, GPT-NeoXなどを用いて数十Bのモデルの学習を行う知見を蓄積しています。今回はLLMの事前学習を行う際に候補となるMegatron-DeepSpeedを用いてGPT-2-7B(6.6B)の学習をどのように行うのかについて解説します。
分散並列学習がどのように行われているかに興味がある方は、以下の記事をご覧ください。
Megatron-DeepSpeed とは
Megatron-DeepSpeedとは、NVIDIAのMegatron-LMにdeepspeedが組み込まれたものです。
DeepSpeedを開発しているMicrosoftが管理しており、Megatron-LMのexamples scriptに加えて、deepspeedを用いて学習するためのサンプルscriptが提供されています。
Megatron-LM とは ?
NVIDIA Applied Deep Learning Researchチーム(応用深層学習研究チーム)が開発した巨大なTransformerモデル郡です。大規模にTransformerモデルを学習するための基盤が整っており、GPT, BERT, T5などのモデルをマルチノード(多ノード)で学習するためのコードがそろっています。
DeepSpeed とは ?
Microsoft曰く「大規模かつ高速な深層学習を容易に実現する様々な機能をもったソフトウェア」
GPT-NeoXの裏でもdeepspeedが用いられていることから、現状では業界のデファクトスタンダードになっていると言えるでしょう。
モデルが大きすぎてGPUメモリに収まりきらない際に、ZeROを用いたり、数千GPUで学習を行うために3D Parallelismを用いたりと、大規模な学習を行う上で必須のツールと言えるでしょう。
環境構築
今回実験に使用する環境はDGX A100 40GB ✕ 8と A100 80GB ✕ 4です。
また最終的な実装結果をGitHub上で公開しています。適時参考にしてください。
手順
pyenv をインストールします。
curl https://pyenv.run | bash
以下のように出れば成功です。
# Load pyenv automatically by appending
# the following to
~/.bash_profile if it exists, otherwise ~/.profile (for login shells)
and ~/.bashrc (for interactive shells) :
export PYENV_ROOT="$HOME/.pyenv"
command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
# Restart your shell for the changes to take effect.
# Load pyenv-virtualenv automatically by adding
# the following to ~/.bashrc:
eval "$(pyenv virtualenv-init -)"
vimやvscodeを使って、~/.bashrc に以下を追加します。
# pyenv
export PYENV_ROOT="$HOME/.pyenv"
command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
pyenvがinstallできているか確かめます。
> source ~/.bashrc
> pyenv --version
pyenv 2.3.21
versionが出てきたので成功です。
pyenv にて 3.10.10 をインストールします。
pyenv install 3.10.10
git clone https://github.com/microsoft/Megatron-DeepSpeed
cd Megatron-DeepSpeed
により、Megatron-DeepSpeedをcloneしてきます。
Megatron-DeepSpeed/ で使う python version を設定します。
> pyenv local 3.10.10
> python --version
3.10.10
pyenv virutalenv などで仮想環境を作るのでも良いのですが、その場合はMegatron-DeepSpeed/megatron/data/Makefileを変更する必要が生じます。後ほど補足しますが、特別なこだわりがない方以外は、以下の手順で環境構築を進めることを強くオススメします。
仮想環境を作ります。.envという名前で仮想環境を構築していますが、特に意味はありません。お好きな名前でどうぞ
python -m venv .env
source .env/bin/activate
仮想環境に入ったので、pip installをしていきます。
その前に、お使いのCUDA versionを確認してください。nvcc --versionで確認できます。
requirements.txtに追記して以下のようにします。
pybind11
torch
six
regex
numpy
deepspeed
wandb
tensorboard
なお、この記事を見た方が環境を揃えやすいようにpip freezeしたものも載せておきます。
installed_packages.txt
absl-py==1.4.0
apex @ file:///home/kazuki/turing/Megatron-DeepSpeed/apex
appdirs==1.4.4
cachetools==5.3.1
certifi==2023.5.7
charset-normalizer==3.1.0
click==8.1.3
cmake==3.26.4
deepspeed==0.9.5
docker-pycreds==0.4.0
filelock==3.12.2
gitdb==4.0.10
GitPython==3.1.31
google-auth==2.21.0
google-auth-oauthlib==1.0.0
grpcio==1.56.0
hjson==3.1.0
idna==3.4
Jinja2==3.1.2
lit==16.0.6
Markdown==3.4.3
MarkupSafe==2.1.3
mpmath==1.3.0
networkx==3.1
ninja==1.11.1
numpy==1.25.0
nvidia-cublas-cu11==11.10.3.66
nvidia-cuda-cupti-cu11==11.7.101
nvidia-cuda-nvrtc-cu11==11.7.99
nvidia-cuda-runtime-cu11==11.7.99
nvidia-cudnn-cu11==8.5.0.96
nvidia-cufft-cu11==10.9.0.58
nvidia-curand-cu11==10.2.10.91
nvidia-cusolver-cu11==11.4.0.1
nvidia-cusparse-cu11==11.7.4.91
nvidia-nccl-cu11==2.14.3
nvidia-nvtx-cu11==11.7.91
oauthlib==3.2.2
packaging==23.1
pathtools==0.1.2
protobuf==4.23.3
psutil==5.9.5
py-cpuinfo==9.0.0
pyasn1==0.5.0
pyasn1-modules==0.3.0
pybind11==2.10.4
pydantic==1.10.9
PyYAML==6.0
regex==2023.6.3
requests==2.31.0
requests-oauthlib==1.3.1
rsa==4.9
sentry-sdk==1.26.0
setproctitle==1.3.2
six==1.16.0
smmap==5.0.0
sympy==1.12
tensorboard==2.13.0
tensorboard-data-server==0.7.1
torch==2.0.1
tqdm==4.65.0
triton==2.0.0
typing_extensions==4.6.3
urllib3==1.26.16
wandb==0.15.4
Werkzeug==2.3.6
以下のコマンドでpackageをインストールします。
pip install -r requirements.txt
次に NVIDIA/apex を install します。ソースからinstallする必要があるので以下の手順に従ってください。(最新の方法については apex#from-sourceを参照ください)
Megatron-DeepSpeed/にて以下を実行します。
git clone git@github.com:NVIDIA/apex.git
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext" ./
apexのインストール途中で、C++のwarningがたくさん表示されますが、気にせずに待ちましょう。
環境によっては10分ほどかかる可能性もあります。
以下のような表示が出れば成功です。
adding 'apex-0.1.dist-info/WHEEL'
adding 'apex-0.1.dist-info/top_level.txt'
adding 'apex-0.1.dist-info/RECORD'
removing build/bdist.linux-x86_64/wheel
Building wheel for apex (pyproject.toml) ... done
Created wheel for apex: filename=apex-0.1-cp310-cp310-linux_x86_64.whl size=40124546 sha256=c4e3b526433a030fa633ece2c5bb46063cc4dd492486a8229010cbc738b7878d
Stored in directory: /tmp/pip-ephem-wheel-cache-yvzg38l4/wheels/60/ff/f5/6ccc51c5b4d8546b8f8ae4290c9a7a54e16a046974f712a4bc
Successfully built apex
Installing collected packages: apex
Successfully installed apex-0.1
なお、正しくinstallできていない場合は
Compiling objects...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/1] c++ -MMD -MF ...
のような表示がないはずです。
apex install 失敗でよくあるケース
nvcc: NVIDIA Cuda Compiler が CUDA 11.6を対象にしており, installしたPyTorch binaryがCUDA11.7 依存であると以下のようなエラーが生じます。
RuntimeError: Cuda extensions are being compiled with a version of Cuda that does not match the version used to compile Pytorch binaries. Pytorch binaries were compiled with Cuda 11.7.
In some cases, a minor-version mismatch will not cause later errors: https://github.com/NVIDIA/apex/pull/323#discussion_r287021798. You can try commenting out this check (at your own risk).
error: subprocess-exited-with-error
× Building wheel for apex (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
full command: /home/ubuntu/Megatron-DeepSpeed/.env/bin/python /home/ubuntu/Megatron-DeepSpeed/.env/lib/python3.10/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py build_wheel /tmp/tmpc5mthro6
cwd: /home/ubuntu/Megatron-DeepSpeed/apex
Building wheel for apex (pyproject.toml) ... error
このエラーの前に
torch.__version__ = 2.0.1+cu117
Compiling cuda extensions with
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_Mar__8_18:18:20_PST_2022
Cuda compilation tools, release 11.6, V11.6.124
Build cuda_11.6.r11.6/compiler.31057947_0
from /usr/bin
と書いてある箇所があるので、そこで何がおかしいのか判断してください。
上記の例では、PyTorchのバイナリがcuda11.7でコンパイルされたのに、nvccはcuda11.6に対応しているということで怒られています。
正しくapexをインストールするには nvcc --version の結果が以下のようである必要があります。
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_18:49:52_PDT_2022
Cuda compilation tools, release 11.7, V11.7.64
Build cuda_11.7.r11.7/compiler.31294372_0
学習用データの用意
cd dataset
bash download_books.sh
bash download_vocab.sh
以上を行うと dataset/gpt2-merges.txt, dataset/gpt2-vocab.json, dataset/BookCorpusDataset_text_document.bin, dataset/BookCorpusDataset_text_document.idxがダウンロードされます。
gpt2-merges.txt, gpt2-vocab.jsonはGPT2BPETokenizerに使われ、BookCorpusDataset_text_document.bin, BookCorpusDataset_text_document.idxはデータセットとして使われます。
動作確認
1 GPU 実験
まずは、1node 1GPUで動作するかをチェックします。
examples/pretrain_gpt.shの内容を以下のように修正します。
#!/bin/bash
# Runs the "345M" parameter model
source .env/bin/activate
RANK=0
WORLD_SIZE=1
DATA_PATH=dataset/BookCorpusDataset_text_document
CHECKPOINT_PATH=checkpoints/gpt2_345m/1gpu
mkdir -p $CHECKPOINT_PATH
export LOCAL_RANK=$RANK
python pretrain_gpt.py \
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--micro-batch-size 4 \
--global-batch-size 8 \
--seq-length 1024 \
--max-position-embeddings 1024 \
--train-iters 500000 \
--lr-decay-iters 320000 \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
--vocab-file dataset/gpt2-vocab.json \
--merge-file dataset/gpt2-merges.txt \
--data-impl mmap \
--split 949,50,1 \
--distributed-backend nccl \
--lr 0.00015 \
--min-lr 1.0e-5 \
--lr-decay-style cosine \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--checkpoint-activations \
--log-interval 100 \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters 10 \
--fp16
Megatron-DeepSpeed/にて bash examples/pretrain_gpt.shで実行します。
以下のようなoutputが得られるはずです。
出力結果
[before the start of training step] datetime: 2023-06-28 18:44:38
iteration 100/ 500000 | consumed samples: 800 | consumed tokens: 819200 | elapsed time per iteration (ms): 2994.9 | learning rate: 3.984E-06 | global batch size: 8 | lm loss: 9.500946E+00 | loss scale: 262144.0 | grad norm: 3.752 | actual seqlen: 1024 | number of skipped iterations: 15 | number of nan iterations: 0 | samples per second: 2.671 | TFLOPs: 8.56 |
[Rank 0] (after 100 iterations) memory (MB) | allocated: 6785.88818359375 | max allocated: 8857.02587890625 | reserved: 10054.0 | max reserved: 10054.0
time (ms) | forward-compute: 2727.57 | backward-compute: 225.82 | backward-params-all-reduce: 8.06 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.34 | optimizer-unscale-and-check-inf: 8.20 | optimizer-clip-main-grad: 7.57 | optimizer-copy-main-to-model-params: 3.15 | optimizer: 32.61 | batch-generator: 595.45
iteration 200/ 500000 | consumed samples: 1600 | consumed tokens: 1638400 | elapsed time per iteration (ms): 834.6 | learning rate: 8.672E-06 | global batch size: 8 | lm loss: 8.293657E+00 | loss scale: 262144.0 | grad norm: 5.126 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 9.585 | TFLOPs: 30.70 |
time (ms) | forward-compute: 588.48 | backward-compute: 213.51 | backward-params-all-reduce: 7.67 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.34 | optimizer-unscale-and-check-inf: 2.82 | optimizer-clip-main-grad: 5.54 | optimizer-copy-main-to-model-params: 3.74 | optimizer: 24.10 | batch-generator: 496.04
iteration 300/ 500000 | consumed samples: 2400 | consumed tokens: 2457600 | elapsed time per iteration (ms): 646.3 | learning rate: 1.336E-05 | global batch size: 8 | lm loss: 7.484882E+00 | loss scale: 262144.0 | grad norm: 3.398 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 12.378 | TFLOPs: 39.64 |
time (ms) | forward-compute: 400.52 | backward-compute: 213.19 | backward-params-all-reduce: 7.64 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.36 | optimizer-unscale-and-check-inf: 2.82 | optimizer-clip-main-grad: 5.55 | optimizer-copy-main-to-model-params: 3.72 | optimizer: 24.12 | batch-generator: 308.24
outputの結果からLossがきちんと下がっていることが、確認できると思います。
8 GPU 実験
1 node 1 GPUでの実験がうまくできたので、次は 1 node 8 GPU での実験を行います。
まず、megatron/arguments,pyに変更を加える必要があります。
- group.add_argument('--local_rank', type=int, default=None,
- help='local rank passed from distributed launcher.')
+ group.add_argument('--local-rank', type=int, default=None,
+ help='local rank passed from distributed launcher.')
次にexamples/pretrain_gpt_distributed.shを以下のように書き換えます。
#!/bin/bash
source .env/bin/activate
# Runs the "345M" parameter model
GPUS_PER_NODE=8
# Change for multinode config
MASTER_ADDR=localhost
MASTER_PORT=6000
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DATA_PATH=dataset/BookCorpusDataset_text_document
CHECKPOINT_PATH=checkpoints/gpt2_345m/8gpu
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
python -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--micro-batch-size 8 \
--global-batch-size 64 \
--seq-length 1024 \
--max-position-embeddings 1024 \
--train-iters 500000 \
--lr-decay-iters 320000 \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
--vocab-file dataset/gpt2-vocab.json \
--merge-file dataset/gpt2-merges.txt \
--data-impl mmap \
--split 949,50,1 \
--distributed-backend nccl \
--lr 0.00015 \
--lr-decay-style cosine \
--min-lr 1.0e-5 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--checkpoint-activations \
--log-interval 100 \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters 10 \
--fp16
今回はノード内並列を行っているので、MASTER_PORTはlocalhostで構いません。
なお複数ノードにまたがる場合は、hostfileなどが必要です。
先程と同様にMegatron-DeepSpeed/にて bash examples/pretrain_gpt_distributed.shを実行します。
以下のような結果が得られるはずです。
出力結果
[after dataloaders are built] datetime: 2023-06-28 19:22:05
done with setup ...
time (ms) | model-and-optimizer-setup: 3599.46 | train/valid/test-data-iterators-setup: 11542.53
training ...
[before the start of training step] datetime: 2023-06-28 19:22:05
iteration 100/ 500000 | consumed samples: 6400 | consumed tokens: 6553600 | elapsed time per iteration (ms): 9757.9 | learning rate: 3.984E-06 | global batch size: 64 | lm loss: 9.441295E+00 | loss scale: 262144.0 | grad norm: 2.246 | actual seqlen: 1024 | number of skipped iterations: 15 | number of nan iterations: 0 | samples per second: 6.559 | TFLOPs: 2.63 |
[Rank 0] (after 100 iterations) memory (MB) | allocated: 6787.13818359375 | max allocated: 9572.91552734375 | reserved: 12262.0 | max reserved: 12262.0
time (ms) | forward-compute: 9425.33 | backward-compute: 213.92 | backward-params-all-reduce: 21.27 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.33 | optimizer-unscale-and-check-inf: 12.24 | optimizer-clip-main-grad: 38.36 | optimizer-copy-main-to-model-params: 3.15 | optimizer: 96.64 | batch-generator: 5400.81
iteration 200/ 500000 | consumed samples: 12800 | consumed tokens: 13107200 | elapsed time per iteration (ms): 3343.0 | learning rate: 8.672E-06 | global batch size: 64 | lm loss: 8.081694E+00 | loss scale: 262144.0 | grad norm: 2.010 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 19.145 | TFLOPs: 7.66 |
time (ms) | forward-compute: 3095.83 | backward-compute: 192.60 | backward-params-all-reduce: 21.94 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.37 | optimizer-unscale-and-check-inf: 2.86 | optimizer-clip-main-grad: 5.63 | optimizer-copy-main-to-model-params: 3.73 | optimizer: 24.30 | batch-generator: 715.57
iteration 300/ 500000 | consumed samples: 19200 | consumed tokens: 19660800 | elapsed time per iteration (ms): 2925.6 | learning rate: 1.336E-05 | global batch size: 64 | lm loss: 7.159136E+00 | loss scale: 262144.0 | grad norm: 1.763 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 21.876 | TFLOPs: 8.76 |
time (ms) | forward-compute: 2686.59 | backward-compute: 193.28 | backward-params-all-reduce: 19.67 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.32 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 5.61 | optimizer-copy-main-to-model-params: 3.70 | optimizer: 24.16 | batch-generator: 684.25
iteration 400/ 500000 | consumed samples: 25600 | consumed tokens: 26214400 | elapsed time per iteration (ms): 2044.4 | learning rate: 1.805E-05 | global batch size: 64 | lm loss: 6.449404E+00 | loss scale: 262144.0 | grad norm: 2.043 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 31.305 | TFLOPs: 12.53 |
time (ms) | forward-compute: 1805.24 | backward-compute: 192.73 | backward-params-all-reduce: 19.21 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.32 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 5.60 | optimizer-copy-main-to-model-params: 3.70 | optimizer: 24.12 | batch-generator: 108.36
iteration 500/ 500000 | consumed samples: 32000 | consumed tokens: 32768000 | elapsed time per iteration (ms): 1220.1 | learning rate: 2.273E-05 | global batch size: 64 | lm loss: 6.104833E+00 | loss scale: 262144.0 | grad norm: 1.536 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 52.455 | TFLOPs: 21.00 |
time (ms) | forward-compute: 973.82 | backward-compute: 192.71 | backward-params-all-reduce: 15.98 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.34 | optimizer-unscale-and-check-inf: 2.84 | optimizer-clip-main-grad: 5.60 | optimizer-copy-main-to-model-params: 3.70 | optimizer: 24.14 | batch-generator: 86.29
iteration 600/ 500000 | consumed samples: 38400 | consumed tokens: 39321600 | elapsed time per iteration (ms): 816.5 | learning rate: 2.733E-05 | global batch size: 64 | lm loss: 5.855302E+00 | loss scale: 65536.0 | grad norm: 1.392 | actual seqlen: 1024 | number of skipped iterations: 2 | number of nan iterations: 0 | samples per second: 78.383 | TFLOPs: 31.38 |
time (ms) | forward-compute: 579.86 | backward-compute: 193.21 | backward-params-all-reduce: 14.08 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.34 | optimizer-unscale-and-check-inf: 2.84 | optimizer-clip-main-grad: 5.48 | optimizer-copy-main-to-model-params: 3.63 | optimizer: 23.76 | batch-generator: 160.66
iteration 700/ 500000 | consumed samples: 44800 | consumed tokens: 45875200 | elapsed time per iteration (ms): 509.3 | learning rate: 3.202E-05 | global batch size: 64 | lm loss: 5.717134E+00 | loss scale: 65536.0 | grad norm: 2.511 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 125.661 | TFLOPs: 50.31 |
time (ms) | forward-compute: 276.57 | backward-compute: 194.08 | backward-params-all-reduce: 13.86 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.34 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 5.59 | optimizer-copy-main-to-model-params: 3.72 | optimizer: 24.16 | batch-generator: 18.64
iteration 800/ 500000 | consumed samples: 51200 | consumed tokens: 52428800 | elapsed time per iteration (ms): 529.3 | learning rate: 3.670E-05 | global batch size: 64 | lm loss: 5.591023E+00 | loss scale: 65536.0 | grad norm: 1.970 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 120.924 | TFLOPs: 48.41 |
time (ms) | forward-compute: 296.44 | backward-compute: 194.67 | backward-params-all-reduce: 13.40 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.35 | optimizer-unscale-and-check-inf: 2.84 | optimizer-clip-main-grad: 5.59 | optimizer-copy-main-to-model-params: 3.72 | optimizer: 24.14 | batch-generator: 86.39
iteration 900/ 500000 | consumed samples: 57600 | consumed tokens: 58982400 | elapsed time per iteration (ms): 516.1 | learning rate: 4.139E-05 | global batch size: 64 | lm loss: 5.464304E+00 | loss scale: 65536.0 | grad norm: 1.938 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 123.996 | TFLOPs: 49.64 |
time (ms) | forward-compute: 283.08 | backward-compute: 194.95 | backward-params-all-reduce: 13.35 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.37 | optimizer-unscale-and-check-inf: 2.84 | optimizer-clip-main-grad: 5.58 | optimizer-copy-main-to-model-params: 3.72 | optimizer: 24.16 | batch-generator: 36.53
iteration 1000/ 500000 | consumed samples: 64000 | consumed tokens: 65536000 | elapsed time per iteration (ms): 579.0 | learning rate: 4.608E-05 | global batch size: 64 | lm loss: 5.321861E+00 | loss scale: 65536.0 | grad norm: 1.470 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 110.540 | TFLOPs: 44.25 |
time (ms) | forward-compute: 344.77 | backward-compute: 195.70 | backward-params-all-reduce: 13.65 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.37 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 5.58 | optimizer-copy-main-to-model-params: 3.73 | optimizer: 24.19 | batch-generator: 88.94
------------------------------------------------------------------------------------------------
validation loss at iteration 1000 | lm loss value: 5.299672E+00 | lm loss PPL: 2.002711E+02 |
------------------------------------------------------------------------------------------------
iteration 1100/ 500000 | consumed samples: 70400 | consumed tokens: 72089600 | elapsed time per iteration (ms): 754.2 | learning rate: 5.077E-05 | global batch size: 64 | lm loss: 5.193630E+00 | loss scale: 65536.0 | grad norm: 1.597 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 84.862 | TFLOPs: 33.97 |
time (ms) | forward-compute: 521.54 | backward-compute: 194.54 | backward-params-all-reduce: 13.32 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.35 | optimizer-unscale-and-check-inf: 2.83 | optimizer-clip-main-grad: 5.57 | optimizer-copy-main-to-model-params: 3.71 | optimizer: 24.09 | batch-generator: 247.71
iteration 1200/ 500000 | consumed samples: 76800 | consumed tokens: 78643200 | elapsed time per iteration (ms): 334.4 | learning rate: 5.545E-05 | global batch size: 64 | lm loss: 5.088095E+00 | loss scale: 65536.0 | grad norm: 1.167 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 191.388 | TFLOPs: 76.62 |
time (ms) | forward-compute: 94.85 | backward-compute: 200.54 | backward-params-all-reduce: 14.13 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.47 | optimizer-unscale-and-check-inf: 2.83 | optimizer-clip-main-grad: 5.57 | optimizer-copy-main-to-model-params: 3.77 | optimizer: 24.27 | batch-generator: 0.73
iteration 1300/ 500000 | consumed samples: 83200 | consumed tokens: 85196800 | elapsed time per iteration (ms): 346.4 | learning rate: 6.014E-05 | global batch size: 64 | lm loss: 4.980182E+00 | loss scale: 65536.0 | grad norm: 1.358 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 184.759 | TFLOPs: 73.97 |
time (ms) | forward-compute: 91.78 | backward-compute: 210.70 | backward-params-all-reduce: 18.84 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.63 | optimizer-unscale-and-check-inf: 2.84 | optimizer-clip-main-grad: 5.59 | optimizer-copy-main-to-model-params: 3.84 | optimizer: 24.51 | batch-generator: 0.71
iteration 1400/ 500000 | consumed samples: 89600 | consumed tokens: 91750400 | elapsed time per iteration (ms): 352.6 | learning rate: 6.483E-05 | global batch size: 64 | lm loss: 4.881152E+00 | loss scale: 65536.0 | grad norm: 1.069 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 181.490 | TFLOPs: 72.66 |
time (ms) | forward-compute: 96.46 | backward-compute: 213.64 | backward-params-all-reduce: 17.45 | backward-embedding-all-reduce: 0.02 | optimizer-copy-to-main-grad: 3.69 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 5.55 | optimizer-copy-main-to-model-params: 3.87 | optimizer: 24.58 | batch-generator: 0.73
iteration 1500/ 500000 | consumed samples: 96000 | consumed tokens: 98304000 | elapsed time per iteration (ms): 353.7 | learning rate: 6.952E-05 | global batch size: 64 | lm loss: 4.802428E+00 | loss scale: 65536.0 | grad norm: 1.294 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 180.935 | TFLOPs: 72.44 |
time (ms) | forward-compute: 93.59 | backward-compute: 215.16 | backward-params-all-reduce: 19.94 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.72 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 5.46 | optimizer-copy-main-to-model-params: 3.88 | optimizer: 24.53 | batch-generator: 0.73
iteration 1600/ 500000 | consumed samples: 102400 | consumed tokens: 104857600 | elapsed time per iteration (ms): 357.1 | learning rate: 7.420E-05 | global batch size: 64 | lm loss: 4.715454E+00 | loss scale: 131072.0 | grad norm: 2.074 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 179.205 | TFLOPs: 71.74 |
time (ms) | forward-compute: 94.40 | backward-compute: 217.97 | backward-params-all-reduce: 19.92 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.76 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 5.16 | optimizer-copy-main-to-model-params: 3.92 | optimizer: 24.32 | batch-generator: 0.73
iteration 1700/ 500000 | consumed samples: 108800 | consumed tokens: 111411200 | elapsed time per iteration (ms): 361.5 | learning rate: 7.889E-05 | global batch size: 64 | lm loss: 4.630479E+00 | loss scale: 131072.0 | grad norm: 0.983 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 177.061 | TFLOPs: 70.88 |
time (ms) | forward-compute: 95.23 | backward-compute: 224.00 | backward-params-all-reduce: 17.81 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.84 | optimizer-unscale-and-check-inf: 2.86 | optimizer-clip-main-grad: 4.49 | optimizer-copy-main-to-model-params: 3.97 | optimizer: 23.81 | batch-generator: 0.75
iteration 1800/ 500000 | consumed samples: 115200 | consumed tokens: 117964800 | elapsed time per iteration (ms): 368.2 | learning rate: 8.358E-05 | global batch size: 64 | lm loss: 4.548766E+00 | loss scale: 131072.0 | grad norm: 1.155 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 173.812 | TFLOPs: 69.58 |
time (ms) | forward-compute: 96.98 | backward-compute: 222.44 | backward-params-all-reduce: 25.08 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.77 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.92 | optimizer-copy-main-to-model-params: 3.92 | optimizer: 23.09 | batch-generator: 0.75
iteration 1900/ 500000 | consumed samples: 121600 | consumed tokens: 124518400 | elapsed time per iteration (ms): 379.0 | learning rate: 8.827E-05 | global batch size: 64 | lm loss: 4.505708E+00 | loss scale: 131072.0 | grad norm: 0.889 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 168.860 | TFLOPs: 67.60 |
time (ms) | forward-compute: 100.08 | backward-compute: 224.94 | backward-params-all-reduce: 30.04 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.80 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 4.11 | optimizer-copy-main-to-model-params: 3.95 | optimizer: 23.34 | batch-generator: 0.75
iteration 2000/ 500000 | consumed samples: 128000 | consumed tokens: 131072000 | elapsed time per iteration (ms): 377.0 | learning rate: 9.295E-05 | global batch size: 64 | lm loss: 4.421601E+00 | loss scale: 131072.0 | grad norm: 0.896 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 169.781 | TFLOPs: 67.97 |
time (ms) | forward-compute: 99.50 | backward-compute: 219.97 | backward-params-all-reduce: 33.78 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.73 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.99 | optimizer-copy-main-to-model-params: 3.92 | optimizer: 23.10 | batch-generator: 0.75
------------------------------------------------------------------------------------------------
validation loss at iteration 2000 | lm loss value: 4.409870E+00 | lm loss PPL: 8.225874E+01 |
------------------------------------------------------------------------------------------------
iteration 2100/ 500000 | consumed samples: 134400 | consumed tokens: 137625600 | elapsed time per iteration (ms): 733.4 | learning rate: 9.764E-05 | global batch size: 64 | lm loss: 4.357585E+00 | loss scale: 131072.0 | grad norm: 0.846 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 87.267 | TFLOPs: 34.94 |
time (ms) | forward-compute: 497.82 | backward-compute: 198.59 | backward-params-all-reduce: 14.05 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.42 | optimizer-unscale-and-check-inf: 2.84 | optimizer-clip-main-grad: 3.64 | optimizer-copy-main-to-model-params: 3.76 | optimizer: 22.27 | batch-generator: 125.88
iteration 2200/ 500000 | consumed samples: 140800 | consumed tokens: 144179200 | elapsed time per iteration (ms): 342.8 | learning rate: 1.023E-04 | global batch size: 64 | lm loss: 4.304667E+00 | loss scale: 131072.0 | grad norm: 0.864 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 186.711 | TFLOPs: 74.75 |
time (ms) | forward-compute: 93.55 | backward-compute: 209.19 | backward-params-all-reduce: 17.18 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.63 | optimizer-unscale-and-check-inf: 2.84 | optimizer-clip-main-grad: 3.42 | optimizer-copy-main-to-model-params: 3.85 | optimizer: 22.34 | batch-generator: 0.73
iteration 2300/ 500000 | consumed samples: 147200 | consumed tokens: 150732800 | elapsed time per iteration (ms): 349.5 | learning rate: 1.070E-04 | global batch size: 64 | lm loss: 4.261599E+00 | loss scale: 131072.0 | grad norm: 0.774 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 183.128 | TFLOPs: 73.31 |
time (ms) | forward-compute: 93.04 | backward-compute: 215.86 | backward-params-all-reduce: 17.52 | backward-embedding-all-reduce: 0.02 | optimizer-copy-to-main-grad: 3.74 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.42 | optimizer-copy-main-to-model-params: 3.92 | optimizer: 22.54 | batch-generator: 0.72
iteration 2400/ 500000 | consumed samples: 153600 | consumed tokens: 157286400 | elapsed time per iteration (ms): 362.9 | learning rate: 1.117E-04 | global batch size: 64 | lm loss: 4.198406E+00 | loss scale: 131072.0 | grad norm: 0.845 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 176.374 | TFLOPs: 70.61 |
time (ms) | forward-compute: 96.51 | backward-compute: 222.59 | backward-params-all-reduce: 20.65 | backward-embedding-all-reduce: 0.02 | optimizer-copy-to-main-grad: 3.81 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.36 | optimizer-copy-main-to-model-params: 3.95 | optimizer: 22.60 | batch-generator: 0.73
iteration 2500/ 500000 | consumed samples: 160000 | consumed tokens: 163840000 | elapsed time per iteration (ms): 372.2 | learning rate: 1.164E-04 | global batch size: 64 | lm loss: 4.160635E+00 | loss scale: 131072.0 | grad norm: 0.779 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 171.961 | TFLOPs: 68.84 |
time (ms) | forward-compute: 97.75 | backward-compute: 232.38 | backward-params-all-reduce: 18.65 | backward-embedding-all-reduce: 0.02 | optimizer-copy-to-main-grad: 3.93 | optimizer-unscale-and-check-inf: 2.86 | optimizer-clip-main-grad: 3.42 | optimizer-copy-main-to-model-params: 4.02 | optimizer: 22.88 | batch-generator: 0.72
iteration 2600/ 500000 | consumed samples: 166400 | consumed tokens: 170393600 | elapsed time per iteration (ms): 358.7 | learning rate: 1.211E-04 | global batch size: 64 | lm loss: 4.114688E+00 | loss scale: 262144.0 | grad norm: 0.682 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 178.423 | TFLOPs: 71.43 |
time (ms) | forward-compute: 94.96 | backward-compute: 219.59 | backward-params-all-reduce: 21.04 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.76 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.42 | optimizer-copy-main-to-model-params: 3.93 | optimizer: 22.58 | batch-generator: 0.73
iteration 2700/ 500000 | consumed samples: 172800 | consumed tokens: 176947200 | elapsed time per iteration (ms): 371.1 | learning rate: 1.258E-04 | global batch size: 64 | lm loss: 4.082523E+00 | loss scale: 262144.0 | grad norm: 0.693 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 172.469 | TFLOPs: 69.05 |
time (ms) | forward-compute: 98.02 | backward-compute: 222.14 | backward-params-all-reduce: 27.85 | backward-embedding-all-reduce: 0.02 | optimizer-copy-to-main-grad: 3.77 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.36 | optimizer-copy-main-to-model-params: 3.94 | optimizer: 22.55 | batch-generator: 0.72
iteration 2800/ 500000 | consumed samples: 179200 | consumed tokens: 183500800 | elapsed time per iteration (ms): 356.5 | learning rate: 1.304E-04 | global batch size: 64 | lm loss: 4.027845E+00 | loss scale: 131072.0 | grad norm: 0.726 | actual seqlen: 1024 | number of skipped iterations: 2 | number of nan iterations: 0 | samples per second: 179.508 | TFLOPs: 71.86 |
time (ms) | forward-compute: 94.58 | backward-compute: 220.40 | backward-params-all-reduce: 18.76 | backward-embedding-all-reduce: 0.02 | optimizer-copy-to-main-grad: 3.81 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.29 | optimizer-copy-main-to-model-params: 3.88 | optimizer: 22.28 | batch-generator: 0.73
iteration 2900/ 500000 | consumed samples: 185600 | consumed tokens: 190054400 | elapsed time per iteration (ms): 360.8 | learning rate: 1.350E-04 | global batch size: 64 | lm loss: 3.999500E+00 | loss scale: 131072.0 | grad norm: 0.699 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 177.362 | TFLOPs: 71.00 |
time (ms) | forward-compute: 95.50 | backward-compute: 224.82 | backward-params-all-reduce: 17.18 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.87 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.43 | optimizer-copy-main-to-model-params: 4.00 | optimizer: 22.79 | batch-generator: 0.76
iteration 3000/ 500000 | consumed samples: 192000 | consumed tokens: 196608000 | elapsed time per iteration (ms): 392.6 | learning rate: 1.397E-04 | global batch size: 64 | lm loss: 3.979980E+00 | loss scale: 131072.0 | grad norm: 0.663 | actual seqlen: 1024 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 163.034 | TFLOPs: 65.27 |
time (ms) | forward-compute: 103.77 | backward-compute: 229.13 | backward-params-all-reduce: 36.45 | backward-embedding-all-reduce: 0.03 | optimizer-copy-to-main-grad: 3.84 | optimizer-unscale-and-check-inf: 2.85 | optimizer-clip-main-grad: 3.36 | optimizer-copy-main-to-model-params: 3.97 | optimizer: 22.65 | batch-generator: 0.77
------------------------------------------------------------------------------------------------
validation loss at iteration 3000 | lm loss value: 3.999852E+00 | lm loss PPL: 5.459007E+01 |
------------------------------------------------------------------------------------------------
DeepSpeedを用いた学習
これまでに行っていた実験は、Megatron-LMにも存在する実験スクリプトでdeepspeedを用いていませんでした。以下ではdeepspeedを用いた学習方法を説明します。
GPT-2 345M A100 80GB ✕ 4
8GPUでの動作確認の際に変更したmegatron/arguments,pyをもとに戻します。
次に、モデルサイズ、データ並列(DP), パイプライン並列(PP), テンソル並列(PP)などの設定を記したスクリプトを作成します。
今回は以下のようなスクリプトをscripts/ds_gpt2_345m.shとして作成します。
source .env/bin/activate
MASTER_NODE=$(/usr/sbin/ip a show | grep inet | grep 192.168.205 | head -1 | cut -d " " -f 6 | cut -d "/" -f 1)
MASTER_PORT=$((10000 + ($SLURM_JOBID % 50000)))
# Dataset path & checkpoint path
DATASET_PATH=dataset/BookCorpusDataset_text_document
CHECKPOINT_PATH=checkpoints/gpt2_345m/ds_8gpu
mkdir -p ${CHECKPOINT_PATH}
VOCAB_PATH=dataset/gpt2-vocab.json
MERGE_PATH=dataset/gpt2-merges.txt
# GPT-2 345M (24-layer, 1024-hidden, 16-heads, 345M parameters)
NUM_LAYERS=24
HIDDEN_SIZE=1024
NUM_ATTN_HEADS=16
# GPU resources
NUM_NODES=1
NUM_GPUS_PER_NODE=4
NUM_GPUS=$((${NUM_NODES} * ${NUM_GPUS_PER_NODE}))
# Parellel parameters
PP_SIZE=1
TP_SIZE=1
DP_SIZE=$((${NUM_GPUS} / (${PP_SIZE} * ${TP_SIZE})))
# Training parameters
GRAD_ACCUMULATION_STEPS=1
MICRO_BATCHSIZE=8
GLOBAL_BATCH_SIZE=$((MICRO_BATCHSIZE * DP_SIZE))
SEQ_LENGTH=1024
MAX_POSITION_EMBEDDINGS=1024
TRAINING_ITERATIONS=500000
SAVE_INTERVAL=10000
LR_DECAY_ITERATIONS=320000
LR=0.00015
LR_WARMUP_ITER=32000
SEED=1234
# deepspeed configuration
CONFIG_FILE=scripts/ds_config_gpt2_345m_${NUM_GPUS}.json
ZERO_STAGE=1
# for debug
export CUDA_LAUNCH_BLOCKING=1
# Run Command
deepspeed --num_nodes ${NUM_NODES} \
--num_gpus ${NUM_GPUS_PER_NODE} \
pretrain_gpt.py \
--tensor-model-parallel-size ${TP_SIZE} \
--pipeline-model-parallel-size ${PP_SIZE} \
--num-layers ${NUM_LAYERS} \
--hidden-size ${HIDDEN_SIZE} \
--num-attention-heads ${NUM_ATTN_HEADS} \
--micro-batch-size ${MICRO_BATCHSIZE} \
--global-batch-size ${GLOBAL_BATCH_SIZE} \
--seq-length ${SEQ_LENGTH} \
--max-position-embeddings ${MAX_POSITION_EMBEDDINGS} \
--train-iters ${TRAINING_ITERATIONS} \
--save-interval ${SAVE_INTERVAL} \
--lr-decay-iters ${LR_DECAY_ITERATIONS} \
--data-path ${DATASET_PATH} \
--vocab-file ${VOCAB_PATH} \
--merge-file ${MERGE_PATH} \
--data-impl mmap \
--split 949,50,1 \
--save ${CHECKPOINT_PATH} \
--load ${CHECKPOINT_PATH} \
--distributed-backend nccl \
--override-lr-scheduler \
--lr $LR \
--lr-decay-style cosine \
--min-lr 1.0e-5 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-iters $LR_WARMUP_ITER \
--checkpoint-activations \
--log-interval 100 \
--eval-interval 100 \
--eval-iters 10 \
--fp16 \
--seed $SEED \
--no-masked-softmax-fusion \
--deepspeed \
--deepspeed_config ${CONFIG_FILE} \
--zero-stage ${ZERO_STAGE} \
--deepspeed-activation-checkpointing
次に deepspeedの設定ファイルを作成します。
以下の内容を scripts/ds_config_gpt2_345m_4.jsonとして作成します。
{
"train_batch_size": 32,
"gradient_accumulation_steps": 1,
"steps_per_print": 1,
"wandb": {
"enabled": true,
"project": "megatron-deepspeed"
},
"zero_optimization": {
"stage": 1
},
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.00015,
"max_grad_norm": 1.0,
"betas": [
0.9,
0.95
]
}
},
"gradient_clipping": 1.0,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"wall_clock_breakdown": false,
"zero_allow_untested_optimizer": false
}
実際に実行してみましょう。
bash scripits/ds_gpt2_345m.sh で実行できます。
wandbで自動的にloggingされるように設定しているので、以下のようなlossの推移が得られるはずです。

GPT-2 7B A100 80GB ✕ 4
345Mで上手くできたので、7Bにも挑戦してみましょう。
(正確には6.658Bです)
先程と同じ要領で、scripts/ds_gpt2_7b.shを以下のように作成します。
source .env/bin/activate
MASTER_NODE=$(/usr/sbin/ip a show | grep inet | grep 192.168.205 | head -1 | cut -d " " -f 6 | cut -d "/" -f 1)
MASTER_PORT=$((10000 + ($SLURM_JOBID % 50000)))
# Dataset path & checkpoint path
DATASET_PATH=dataset/BookCorpusDataset_text_document
CHECKPOINT_PATH=checkpoints/gpt2_7b/ds_4gpu
mkdir -p ${CHECKPOINT_PATH}
VOCAB_PATH=dataset/gpt2-vocab.json
MERGE_PATH=dataset/gpt2-merges.txt
# GPT-2 7B (32-layer, 4096-hidden, 32-heads, 7B parameters)
NUM_LAYERS=32
HIDDEN_SIZE=4096
NUM_ATTN_HEADS=32
# GPU resources
NUM_NODES=1
NUM_GPUS_PER_NODE=4
NUM_GPUS=$((${NUM_NODES} * ${NUM_GPUS_PER_NODE}))
# Parellel parameters
PP_SIZE=1
TP_SIZE=1
DP_SIZE=$((${NUM_GPUS} / (${PP_SIZE} * ${TP_SIZE})))
# Training parameters
GRAD_ACCUMULATION_STEPS=1
MICRO_BATCHSIZE=4
GLOBAL_BATCH_SIZE=$((MICRO_BATCHSIZE * DP_SIZE))
SEQ_LENGTH=2024
MAX_POSITION_EMBEDDINGS=2024
TRAINING_ITERATIONS=500000
SAVE_INTERVAL=10000
LR_DECAY_ITERATIONS=320000
LR=0.00015
LR_WARMUP_ITER=32000
SEED=1234
# deepspeed configuration
CONFIG_FILE=scripts/ds_config_gpt2_7b_${NUM_GPUS}.json
ZERO_STAGE=1
# for debug
export CUDA_LAUNCH_BLOCKING=1
# Run Command
deepspeed --num_nodes ${NUM_NODES} \
--num_gpus ${NUM_GPUS_PER_NODE} \
pretrain_gpt.py \
--tensor-model-parallel-size ${TP_SIZE} \
--pipeline-model-parallel-size ${PP_SIZE} \
--num-layers ${NUM_LAYERS} \
--hidden-size ${HIDDEN_SIZE} \
--num-attention-heads ${NUM_ATTN_HEADS} \
--micro-batch-size ${MICRO_BATCHSIZE} \
--global-batch-size ${GLOBAL_BATCH_SIZE} \
--seq-length ${SEQ_LENGTH} \
--max-position-embeddings ${MAX_POSITION_EMBEDDINGS} \
--train-iters ${TRAINING_ITERATIONS} \
--save-interval ${SAVE_INTERVAL} \
--lr-decay-iters ${LR_DECAY_ITERATIONS} \
--data-path ${DATASET_PATH} \
--vocab-file ${VOCAB_PATH} \
--merge-file ${MERGE_PATH} \
--data-impl mmap \
--split 949,50,1 \
--save ${CHECKPOINT_PATH} \
--load ${CHECKPOINT_PATH} \
--distributed-backend nccl \
--override-lr-scheduler \
--lr $LR \
--lr-decay-style cosine \
--min-lr 1.0e-5 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-iters $LR_WARMUP_ITER \
--checkpoint-activations \
--log-interval 100 \
--eval-interval 100 \
--eval-iters 10 \
--fp16 \
--seed $SEED \
--no-masked-softmax-fusion \
--deepspeed \
--deepspeed_config ${CONFIG_FILE} \
--zero-stage ${ZERO_STAGE} \
--deepspeed-activation-checkpointing
configファイルも先程と同様に、scripts/ds_config_gpt2_7b_4.jsonと作成しましょう。
{
"train_batch_size": 16,
"gradient_accumulation_steps": 1,
"steps_per_print": 1,
"wandb": {
"enabled": true,
"project": "megatron-deepspeed"
},
"zero_optimization": {
"stage": 1
},
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.00015,
"max_grad_norm": 1.0,
"betas": [
0.9,
0.95
]
}
},
"gradient_clipping": 1.0,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"wall_clock_breakdown": false,
"zero_allow_untested_optimizer": false
}
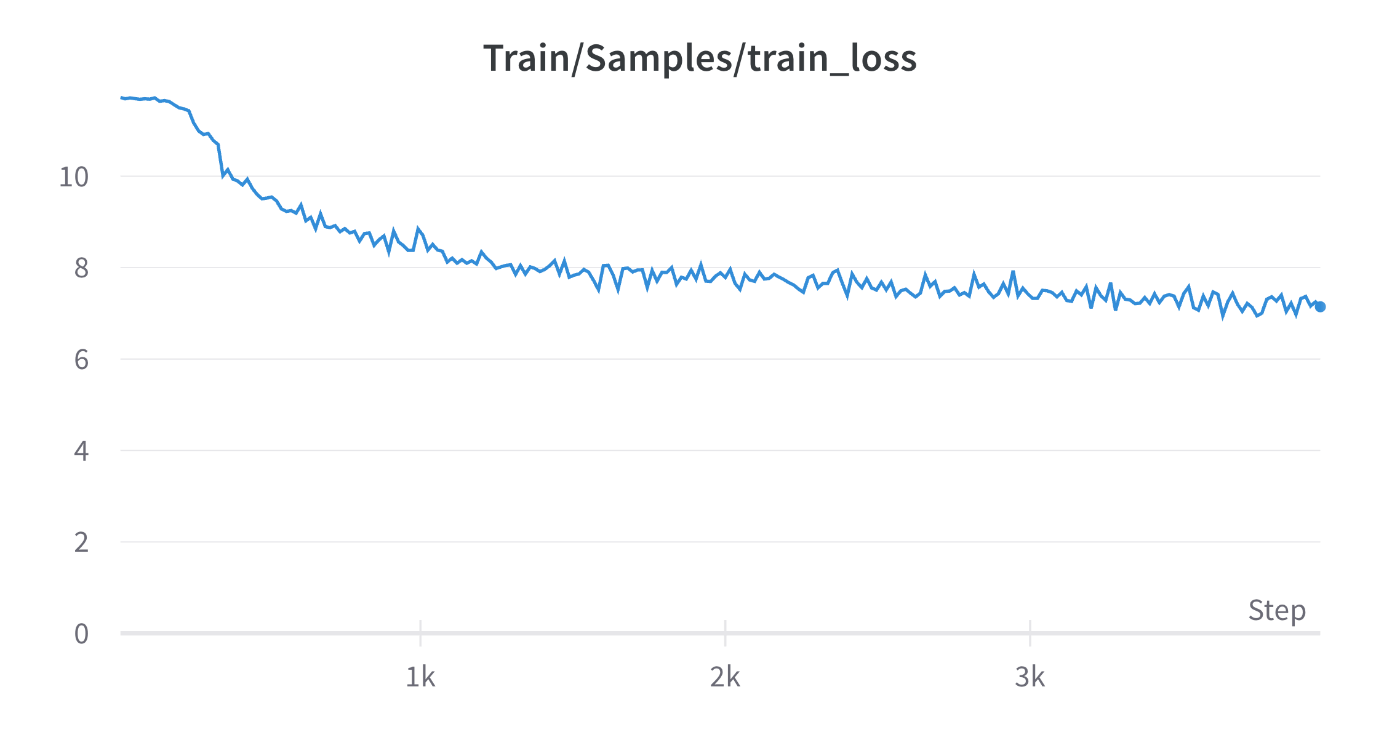
7Bについても、実際に実行してみましょう。
bash scripts/ds_gpt2_7b.shで実行できます。
今回もwandbにてloggingするようになっているので、上手くいけば以下のようなLossの推移が得られるはずです。
補足
CUDA 11.6, 11.8 での環境構築方法
こちらからインストールしたいPyTorchのバージョンと自分の環境のCUDAを探します。
以下に具体例として、PyTorch 2.0.1, CUDA11.8の場合のrequirements.txtの変更例を示します。
pybind11
--find-links https://download.pytorch.org/whl/torch_stable.html
torch==2.0.1+cu118
six
regex
numpy
deepspeed
wandb
tensorboard
上記の例では、nvcc --versionがcuda11.8であれば正しく環境構築することができます。
CUDA11.6の場合も同様です。
pyenv virtualenv を使うと必要になる処理
pyenv virtualenv を用いて環境構築を行うと動作チェックの際に
File "/home/<user>/<path>/Megatron-DeepSpeed/megatron/data/gpt_dataset.py", line 289, in _build_index_mappings
from megatron.data import helpers
ImportError: cannot import name 'helpers' from 'megatron.data'
のようなエラーが発生するかと思います。
これは、python3-configが現状使用しているpythonバージョンと合致していないことに起因するエラーです。以下の方法で解決可能です。
megatorn/data/Makefileを書き換えます。
python3-configを/home/<user>/.pyenv/versions/3.10.10/bin/python3-configのようなフルパスにします。
その後、megatron/dataにてmakeを実行します。
するとmegatron/data/helpers.cpython-310-x86_64-linux-gnu.soのように、お使いのpython versionに合致した.soファイルが生成されるはずです。
RuntimeError: Ninja is required to load C++ extensions
Lambda Cloud上で環境構築した際に遭遇したエラーです。
解決策としては、ninjaからpip install でインストールしたninjaのversionに合致するninjaをインストールことです。
以下の手順でインストールしてください。
wget https://github.com/ninja-build/ninja/releases/download/v1.11.1/ninja-linux.zip
sudo unzip ninja-linux.zip -d /usr/local/bin/
sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force
/usr/bin/ninja --version
つづく
この記事ではMegatron-DeepSpeedを用いて事前学習を行う具体的な方法について説明しました。
今回の記事で分散並列学習に興味が湧いた方は、「大規模モデルを支える分散並列学習のしくみ Part 1」 をご覧ください。
また今回の記事において使用したdeepspeedではZeRO Stage1というメモリ削減技術が使われています。この仕組みについては 「大規模モデルを支える分散並列学習のしくみ Part 2」 にて解説する予定です。
さらに「大規模言語モデル(LLM)の作り方 GPT-NeoX編」では、今回と同様にGPT-NeoXで学習を行う方法について説明します。
Turing では自動運転モデルの学習や、自動運転を支えるための基盤モデルの作成のために分散並列学習の知見を取り入れた研究開発を行っています。興味がある方は、Turing の公式 Web サイト、採用情報などをご覧ください。話を聞きたいという方は私や AI チームのディレクターの山口さんの Twitter DM からでもお気軽にご連絡ください。

Discussion