この記事を3行でまとめると..
- Turingでは1年以上前から完全自動運転に自然言語処理が必要と考えてきた
- 自動運転におけるロングテールなデータに対して、LLMの一般常識に基づく判断能力が必要
- Chat-GPTをきっかけにLLMを自動運転に利用する研究が盛り上がってきている
TuringのBrain Researchチームの棚橋です。Brain Researchチームでは、中長期的に自動運転においてキーとなるコア技術の開発を行っています。最近ではVision LanguageモデルのフレームワークとしてHeronをリリースしました。なぜ自動車を製造する会社が、LLMの開発を行っているのでしょうか。
Turingでは1年以上前から自動運転における複雑な文脈理解には自然言語が必要であると主張してきました。今年の7月にはLLMで実際の車を動かしてみるプロジェクトをデモとして公開しました。このデモでは、カメラから入ってきた情報と音声のプロンプトがLLMに与えられ、その出力に従って車が走行するという新感覚自動運転が体験できるというものです。自分もLLM周辺の実装に関わり、LLMのプロンプト調整や運転操作部分との繋ぎこみなど苦労する部分が多かったですが、LLMがブツブツと音声で説明しながら自律的に車を運転している様子は不思議な感覚でした。
このデモを通して、LLMの役割について改めて気が付くことができました。 1つが「運転判断について説明できること」、もう一つが「初めて見る状況や指示に対しても一般常識を使って柔軟に対応できること」です。一般的な機械学習ベースの自動運転モデルの欠点の一つとして、モデルがブラックボックスとなり説明可能性が低い点という挙げられます。一方、LLMは判断した理由について説明を行うことができるため、デバッグやシステムの改善に役立つだけでなく、ユーザにとってもAIが何を考えているのかが分かるため安心して利用することが可能となります。(ただし、LLMにはハルシネーションなど、多くの問題がまだまだあります!)
また、LLMが初めて見る状況に強いというのは、自動運転においては非常に強力な武器となります。自動運転の走行データはロングテールな分布(レアイベントが多い分布)をしているという特徴があります。すなわち、実際の走行シーンにおいて、学習データに含まれていないようなシーンに出会う可能性がまぁまぁ高いということです。

例えば最近、タイのバスに立って乗っている人をテスラの自動運転システムが歩行者と勘違いしたという動画がSNSで話題になっていました。従来の画像認識システムは一つ一つのオブジェクトを「歩行者」や「車」と認識する仕組みであるため、人がバスに立って乗っているという状況に対して適切に処理することができなくなっています。このように従来のシステムにおいては、新しい未知の状況が現れると、それに対するルールの追加や学習データの追加が必要となるため、ルールベースや学習ベースの方法では対処が難しくなる状況が発生します。

一方で、Turingが開発しているVision Languageモデルである「Heron」に対して、試しに上の画像について説明するように質問をすると、以下のように「バスに大勢の人が乗っている」という回答を出力することができました。
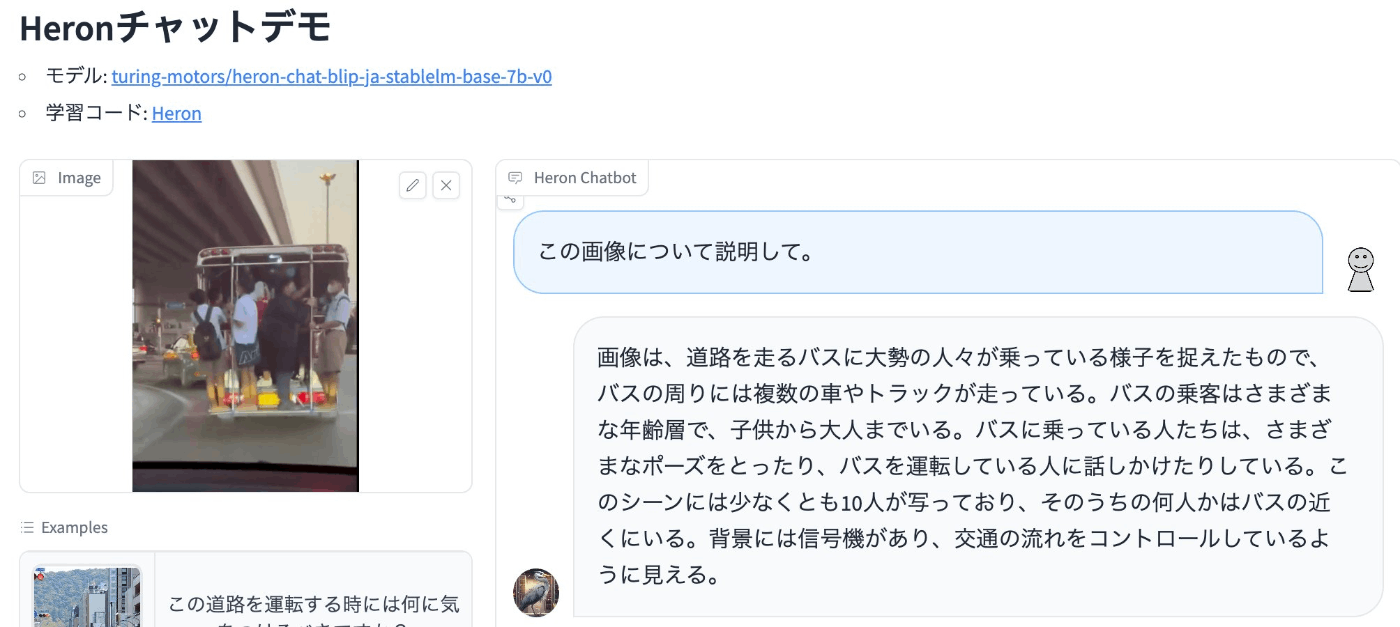
Vision Languageモデルでは画像エンコーダに入力された画像情報がLLMに送られて、LLMでテキストを出力する仕組みになっており、入力された画像に対して一般常識や知識などを考慮して解釈を与えることができるようになっています。LLMに学習された一般常識を用いることで、未知のシーンに対してもある一定の理解や推論を行うことができるのではないかと期待しています。
ここまでは、LLMがあると何が嬉しいのかフワッと説明を行いましたが、すでに実際にLLMを活用した自動運転手法を提案し既存手法とベンチマークで比較しているような研究が多数登場しています。百聞は一見にしかずということで、出たばかりのLLMの自動運転活用研究を見ていきましょう。LLM活用研究を大きく分けると以下のようになります。
- 交通状況をテキストのpromptとしてLLMに入力する方法
- Vision Languageモデルを用いて画像をLLMに入力する方法
以下では、この分類に合わせてLLMを用いた自動運転研究を紹介していきたいと思います。
1. 交通状況をテキストのpromptとしてLLMに入力し、その状況分析や判断をLLMに行わせる
LLMに交通状況(周囲の車の状況)をテキストプロンプトとして渡して自動運転を行う試みが登場しています。現在の自車の速度ベクトルや他車の座標位置、道路の情報などを直接LLMにテキスト情報として渡します。すると、LLMは座標情報などから立体空間を理解するかのように運転判断や操作を出力することができます。
Drive like Humans
カメラベースのEnd-to-endな自動運転認識モデルの開発においても業界をリードしている上海AI Labが「Drive like Humans」という研究を発表しています。この研究では、Chat-GPTを用いて車線変更を行う方法を提案し、強化学習やサンプリングベースの手法と比較して自然な走行が実現できたと報告しています。強化学習による手法では衝突を恐れて、他の車が通り過ぎるまで不自然に遅く走行するような挙動が見られたり、サンプリングベースの手法では不自然に車線変更が行われることがあったのに対して、Chat-GPTを用いると、人間に近い行動を行うことができたという結果が得られています。

LanguageMPC
Chat-GPTをより複雑な運転状況に適用できるようにしたこの研究では、Chat-GPTを用いて、「注目すべき他の車」、「起こりうるシチュエーション」「取りうる行動」を推論させ、それらの出力を用いてMPC(Motion Predictive Control)により運転を行うフレームワークを提案しています。この方法を用いることで交差点やラウンドアバウトなどの複雑な状況において、従来の強化学習やMPCによる方法と比べて、大幅に衝突率が減ったと報告しています。

GPT-Driver: Learning to Drive with GPT
こちらの研究がすごいのは、LLMが直接自車の進む道(trajectory)を数値で出力することができるということです。上記の2つの研究では、LLMは中間的な役割として状況判断などを行っていましたが、GPT-DriverではEnd-to-endな自動運転モデルのように、ルールベース手法を使わずに車の経路プランニングを行うことができます。実際に、nuScenesという有名な自動運転のデータセットを用いたベンチマークでは、UniADなどの従来ベスト手法と同等程度の結果が出ているようです。(前提とする認識情報はUniADの出力を用いるか、Ground Truthを利用しています)

さらにこの手法はChat-GPTのAPIを用いて実験が行われており、OpenAIが提供するFine-tuning機能を使った場合とそうでないを比較すると、Fine-tuningを行うことで高い精度が実現できることが確認されています。Chat-GPTの機能だけで本格的な自動運転の経路計画の研究ができることを示したという意味でも興味深い研究と言えます。

2. Vision Languageモデルを用いて走行画像をLLMに説明させる
前述の方法では、車の情報や道路の情報をテキストデータとしてLLMに入力する方法でしたが、Vision Languageモデルなどを利用することで、画像や車の操作情報を直接LLMに入力することが可能となります。必要な情報を一旦テキストにしてLLMに処理させることは可能ですが、画像情報として渡すことで、LLMが必要な情報を直接取得して推論を行うことが可能になります。
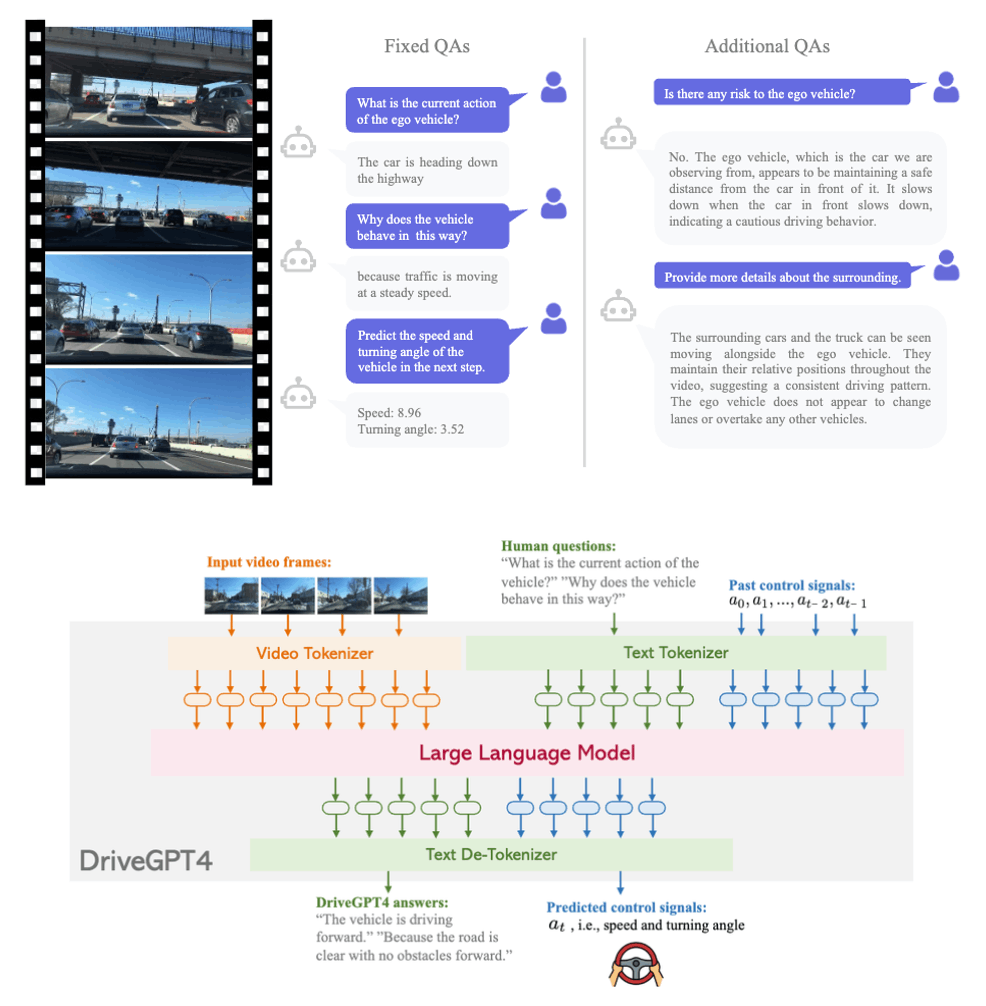
DriveGPT4
Vision Languageモデルを学習するためには、画像とそれに対するテキストのペアが必要となります。走行動画に説明テキストを付与したデータとしては、BDD-Xというデータセットが有名です。このデータセットのテキストは、運転操作(action description)と、それに対する理由の説明(justification)で構成されていますが、質問に対して回答を行うようなVision Languageモデルの学習に利用するには、文章の多様性が少ないという問題があります。

そこで、DriveGPT4では、Chat-GPTを利用してBDD-Xのテキストを拡張し以下の質問を生成しています。
- 現在の車の状態は何ですか?
- 現在の車の挙動の理由は何ですか?
- 次のフレームにおける車のスピードとステアリング角度を予測してください。
ただし、このような単純な質問のみを用いて学習を行うと単純な回答しか得られなくなるため、DriveGPT4では、さらにこれらの質問と別に推論させたオブジェクト認識結果を用いてChat-GPTで拡張した対話形式の学習データを用いて学習を行っています。その結果、以下のように一般的な対話に対しても回答できるようなモデルの作成が行えるようになっています。
LINGO-1
また、イギリスの自動運転スタートアップのWayveがLINGO-1というモデルを先月発表しました。Wayveは以前より完全自動運転にLLMが必要であると主張している企業で、積極的に自動運転にLLMを活用しようとしている自動運転開発企業です。今回、WayveがLINGO-1を作ったモチベーションとして、LLMの出力によって自動運転が行った操作を説明することができるようになるということと、LLMの高い推論能力によって経路計画の精度が向上することを挙げています。

Honda DRAMA
Vision Languageモデルを自動運転のデータで学習するためのデータセットも作成されています。例えば、Hondaリサーチが作成したデータセットDARAMAでは、走行動画に対してリスクのあるオブジェクトの位置とそのオブジェクトの説明のテキストを含むデータセットです。テキストの説明では、4W1H(何が、どれが、どこで、なぜ、どのように)という観点から詳細にリスクについて記載しています。最近Hondaリサーチはさらにリスクをランキング形式で順序付したRank2Tellという新しいデータセットも公開しており、このデータセットを使うことによってLLMによって走行動画からリスクを分析して説明するようなことが可能となっています。
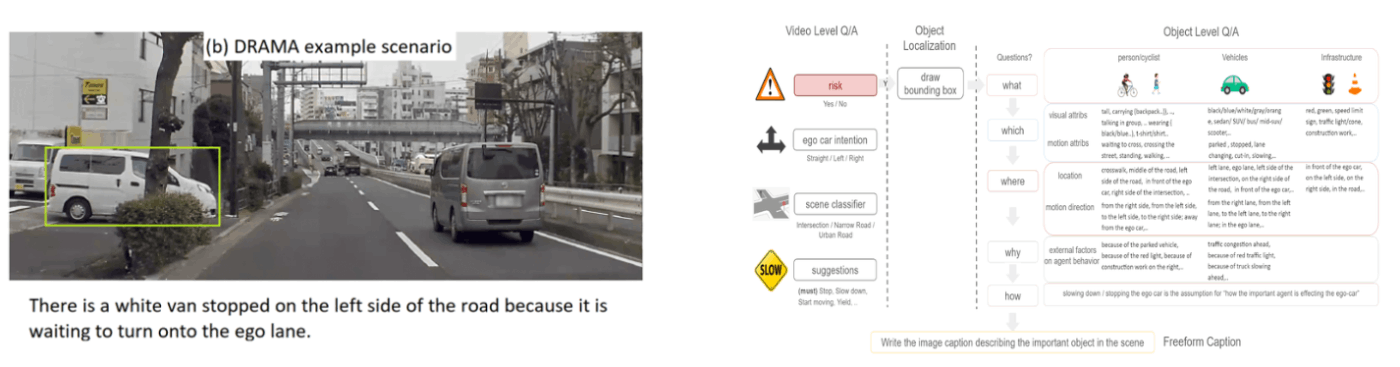
DriveLM
上海AIラボからプレリリースが発表されたDriveLMは、Turingが最も注目しているデータセットの一つで、nuScenesのオブジェクトに対して人力でテキストを付与したものです。テキストアノテーションは”Perception”と”Prediction&Planning”という2つの項目に分けられ、Perceptionでは他の車や歩行者がどこにいるかというような認識に関するQ&Aを扱っています。

このデータセットの面白い点としてはWhat-If 質問、つまり自車が別の運転操作した時にどのような結末になるかというQ&Aテキストも含んでおり、教習所で習う「かもしれない運転」をLLMができるように学習することを狙っていると考えられます。

自動運転データセットに付与されたテキストのデータセットは他にも次々に登場しており、DriveLMと同じくnuScenesにオブジェクトの位置情報をアノテーションしたNuScenes QAや、nuScenesの3次元オブジェクトとテキストアノテーションを紐づけた”Language Prompt for Autonomous Driving”といったデータセットも登場してきています。
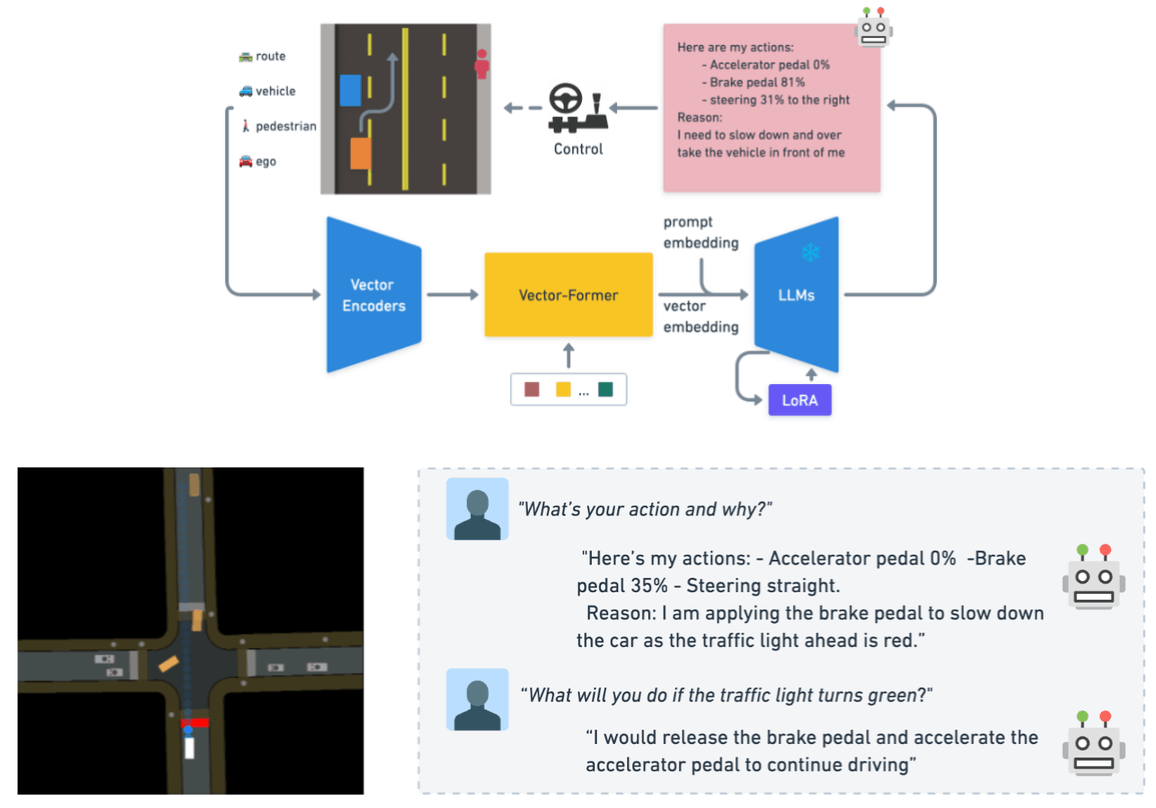
Driving with LLM
最後に紹介するのは、LINGO-1と同じくWayveの研究で、車の周囲の情報を数値としてLLMに直接入力する方法です。この研究では、シミュレータを用いて周囲の車やレーンの情報を座標情報としてLLMに数値として直接渡す方法を提案しています。トランスフォーマーベースのモデル構造を用いて、数値情報をLLMに渡しています。学習データは2段階に分けて行われ、1段階目ではLLM部分のみフリーズして、人工的に生成された10万Q&Aペアによって学習を行います。2段階目ではLLM部分も合わせて学習を行い、「このシーンでどのように運転をすれば良いですか?」のような運転操作に関するQ&Aを用いて学習を行います。一般的なVision Languageモデルの学習でも2段階に学習を分けることは一般的であり、最初に大量のデータで事前学習を行い、最後に高品質なデータでInstruction Tuningを行います。このような知見を用いることで効率的にテキストデータの作成を行うことができているということも注目すべき点です。
まとめと課題
これらの研究は最近arXivなどで出てきたもので、内容の信頼性については十分確認する必要がありますが、LLMを自動運転へ応用することの期待と注目度が高まっていることは間違いないと思います。「完全自動運転にLLMは必要か?」に対する答えは、これからこの分野の研究開発がどれくらい盛り上がって進んでいくのか、にかかっていると思います。Turingでは、Vision Languageモデルを中心に、自動運転の応用研究を進めています。世界的にこの分野の研究が急速に進行しているおかげで、研究開発の知識的基盤もしっかりと整ってきており、LLMを使った自動運転モデルの実現が急速に現実に近づいてきているように感じます。一方、LLMが自動運転に必要だった時に、「技術的に実現可能なのか」という別の問いも存在します。特に推論に巨大なGPUを必要とするLLMを車の上で動かすことができるのかという課題です。すでにllama.cppなど高速なLLM推論器の開発は活発に始まっていますが、TuringではLLM推論専用アクセラレータを開発していくことを検討しています!
また、リサーチチームではHeronをはじめとして、Vision Languageモデルの研究開発を行っています。
自動運転にもLLMにも興味があるという方は、ぜひTuringに来て、一緒に自動運転モデルの研究開発をやりましょう!
採用情報
Turing では自動運転モデルの学習や、自動運転を支えるための基盤モデルの作成のために分散並列学習の知見を取り入れた研究開発を行っています。興味がある方は、Turing の公式 Web サイト、採用情報などをご覧ください。話を聞きたいという方は私やAIチームのディレクターの山口さんの Twitter DM からでもお気軽にご連絡ください。

Discussion