はじめに
東京工業大学の藤井です。
今回は、GENIACにてNII 国立情報学研究所が現在(2024/7/1)も学習している172Bモデルに関連した事前学習パートに特化した学習知見について共有させていただきます。
この成果は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の助成事業(JPNP20017)の結果得られたものです。
GENIACプロジェクトにおける分散学習環境の整備に関しても同様に記事を作成しています。
ぜひご覧ください。
LLMの学習
大まかにLLMを作成するための手順を下記に記しました。
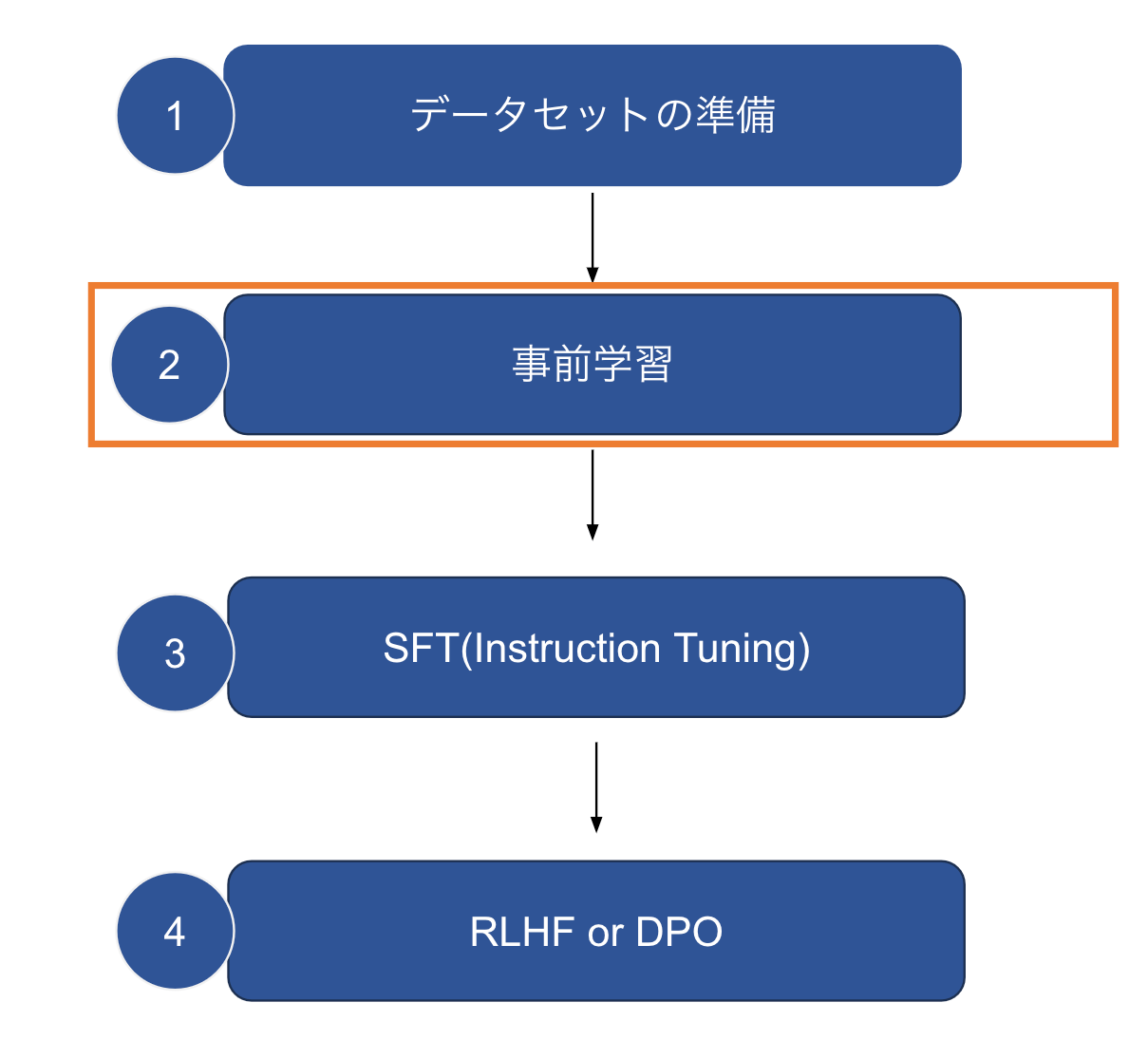
今回は、これらの中でも特に"事前学習"に焦点を絞って知見の共有を行います。
現在の学習状況
まず、GENIACで学習しているモデルの現在の学習状況についてです。
2024/06/30現在、約1.45 T Token(1.45兆トークン)を事前学習にて学習済みです。
以下がそのtraining lossです。(wandbより)(wandbとは学習のログを取るツールです)
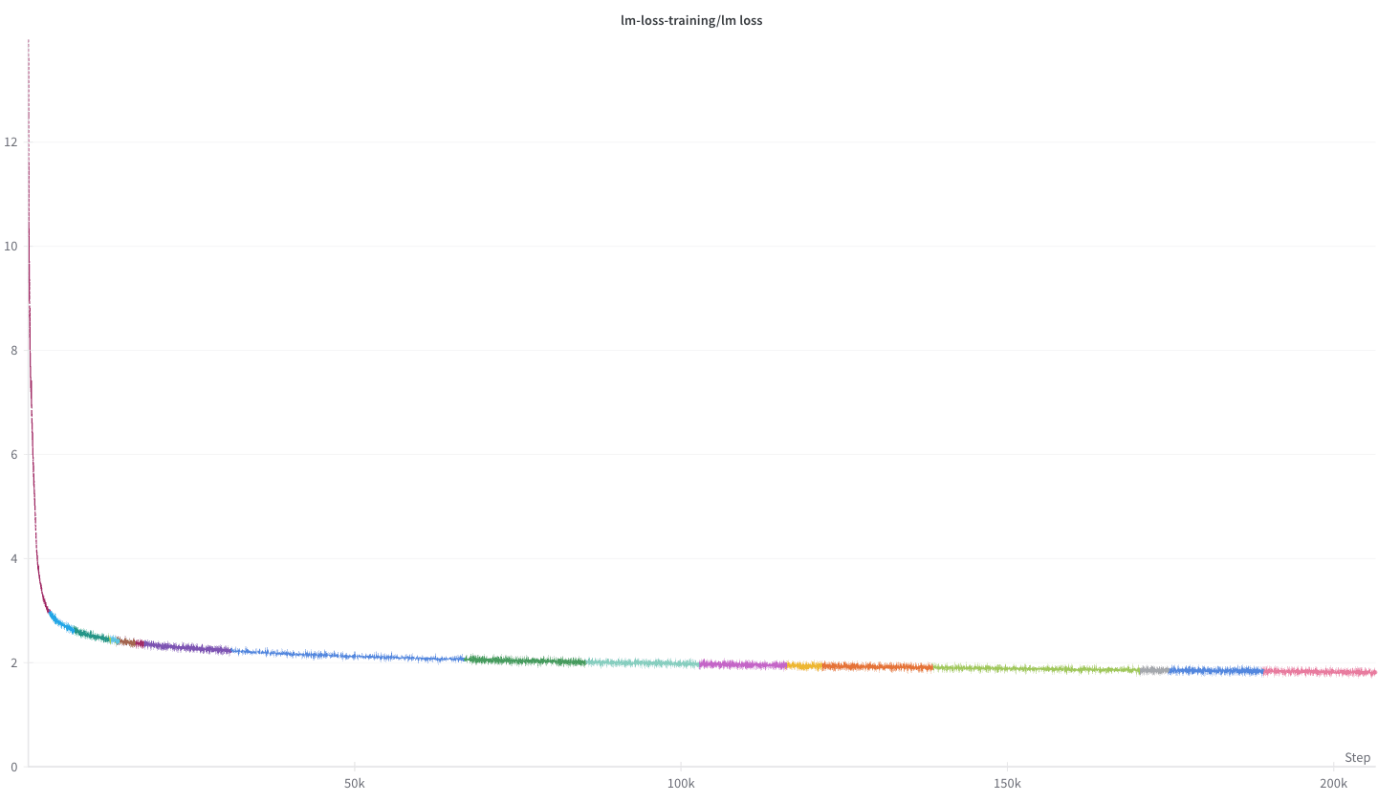
NIIでは、GPT-3の175B相当のサイズのパラメーター数である172Bのモデルをfrom scratchから学習しています。
こちらの学習は、Llama-3、Mistralなどの学習済みモデルからの継続事前学習ではなく、from scratchからの事前学習を行っています。Swallow Projectなどが用いている継続事前学習等の手法は日本語に強いLLMを作成する上で、有効な手法ですが、Llama-2の場合は、事前学習時にMeta社がどのようなデータを使用したかが不明であるなど、LLMを制御、分析する上で一定の制限を受けます。しかし、今回学習を行っているモデルは、最初から(from scratch)事前学習を行っていますので、そのような不明点がなく透明性がより高い日本語に強いLLMを構築することができます。
学習ライブラリについて
次に事前学習を行う上で使用している学習ライブラリについて説明します。
今回の学習では、Megatron-LMを利用しています。LLM-jpでは、2023年度後半から、Megatron-LMの利用を本格開始しており、llm-jp-13b-v2.0の学習にも利用されるなど実績があります。そのため、今回もMegatron-LMを利用して事前学習を行うことにしました。
Megatron-LMは、3D Parallelismなどの分散学習手法をサポートしており、huggingface Trainerなどよりも高速に学習することができます。また、大規模なモデルの学習においてgpt-neoxなどよりも高速かつ、信頼性のおけるコードを提供しています。以上の理由から、今回の学習においてもMegatron-LMを利用することにしました。
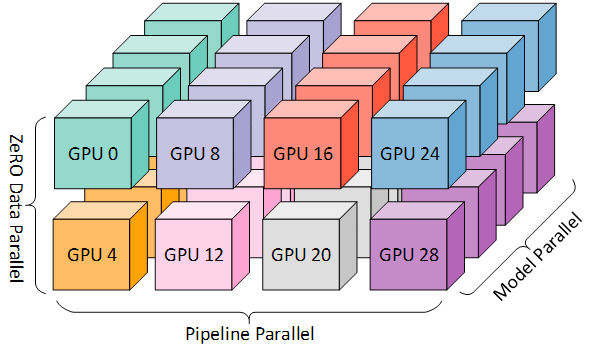
(3D parallelism Microsoft Research blogより)
学習環境の構築
実際に、学習ライブラリのセットアップを行う方法について次に説明します。
Megatron-DeepSpeedで学習環境を整える方法については、過去に私が、以下の記事で書いているのですが、1年ほど経ち、変わっている点もありますし、Megatron-LMとMegatron-DeepSpeedで異なる点があるため、今回は1から解説を行います。
Megatron-DeepSpeedの使用方法に関する記事
- https://zenn.dev/turing_motors/articles/04c1328bf6095a (Part1)
- https://zenn.dev/turing_motors/articles/da7fa101ecb9a1 (Part2)
またMegatron-LMに関する知見の獲得の大部分は、Swallow Projectでの研究開発の中で行われました。
Python環境の用意
まずPython環境を整備しましょう。Python3.10, 3.11系での動作を確認しています。
pyenv automatic installer等を利用して、お好みのversionをインストールしてください。(pyenvを利用する必要はありませんので、別の方法でも問題ありません)
curl https://pyenv.run | bash
pyenvをinstallできたら.bashrcや.zshrcに以下を書き込みます。
export PYENV_ROOT="$HOME/.pyenv"
command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
source ~/.bashrcなどで再度読み込むと以下のようにpyenvが無事にinstallできたことが確認できるかと思います。
> pyenv --version
pyenv 2.3.21
次にpythonをinstallします。Python3.10系、3.11系であれば、特段問題ないと思いますが、今回は、3.11.9を利用します。
pyenv install 3.11.9
pyenv global 3.11.9
CUDA Toolkit、cuDNN、ncclの環境の用意
今回は以下のversionを利用します。
- CUDA Toolkit: 12.1
- cuDNN: 8.9.7
- NCCL: 2.20.5
Environment Modulesからloadする、または、ローカルに直接インストールするなどして環境を作成してください。(Docker Containerなどでも可です。ただContainerを利用する場合は、NGC Containerを利用する方が楽なように思えます)
pip install
requirements.txtを以下のように用意してください。
pybind11
--find-links https://download.pytorch.org/whl/torch_stable.html
torch==2.3.1+cu121
torchvision==0.18.1+cu121
six
regex
numpy
deepspeed
wandb
tensorboard
# mpirun
mpi4py
# tokenizer v2
sentencepiece
# tokenize
nltk
# flash-attn
ninja
packaging
wheel
# checkpoint convert
transformers
accelerate
safetensors
# transformer
einops
用意ができましたら、以下の手順で環境を構築してください。
まず、pythonの仮想環境を作成します。
python -m venv .env
source .env/bin/activate
Environment Modules等を利用されている方は忘れないうちに、module loadをしてしまいましょう。
module load cuda/12.1
module load cudnn/8.9.7
module load nccl/2.20.5
module load hpcx/2.17.1
準備ができたのでインストールしていきましょう。
以下のコマンドでインストールしてください。
pip install --upgrade pip
pip install --upgrade wheel cmake ninja
pip install -r requirements.txt
pip install zarr tensorstore
NVIDIA apex の install
次にNVIDIAが開発している混合精度(mixed precision)、分散学習の効率化をサポートするPyTorch拡張であるApexをインストールします。
このとき、仮想環境にインストールされているPyTorchが依存しているCUDA Toolkitのversionと、ローカルにinstallされているCUDA Toolkit(またはmodule loadしているCUDA Toolkit version)が同一である必要があります。
上記の手順でインストールを進めてきた場合は、特に気にする必要はありませんが、そうではない場合は確認してください。
installはSource Installにて行いますので、まずgit cloneを行います。
git clone https://github.com/NVIDIA/apex
次に、以下のコマンドでインストールを行います。
10〜20分程度installには時間がかかりますので、気長にお待ち下さい。
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
TransformerEngineのinstall
次にTransformerEngineをインストールします。
TransformerEngineはNVIDIA社が開発しているNVIDIA GPU上でTransformerモデルを高速に学習するためのライブラリです。
今回は、CUDA Toolkit 12.1, cuDNN 8.9.7を想定しているので問題ないですが、CUDA Toolkit 11.7以前や、cuDNN 8.1より前を利用されている場合は、インストールすることができませんのでご注意ください。(インストールに失敗します)
また、FP8/FP16/BF16 fused attentionを利用するには、CUDA Toolkit 12.1以降、cuDNN 8.9.1以降が必要です。(今回の記事にて想定しているバージョンはこれらの条件をすべて満たしています)
十分なCPUメモリがある環境で、以下のコマンドを実行してください。
pip install git+https://github.com/NVIDIA/TransformerEngine.git@v1.4
flash attention の install
このまま学習を行うと高確率でAttributeError: module 'transformer_engine' has no attribute 'pytorch'エラーに遭遇します。(詳細: GitHub Issue: https://github.com/NVIDIA/Megatron-LM/issues/696)
そのため以下のようにflash attentionを再installします。
pip uninstall flash-attn
git clone git@github.com:Dao-AILab/flash-attention.git
cd flash-attention
git checkout v2.4.2
pip install -e .
手動make
すべてのinstallが完了しましたが、まだ学習を始めることはできません。
以下を行い、helpers.cpython-311-x86_64-linux-gnu.soを作成してください。
cd megatron/core/datasets
make
上手く、.soファイルが作成されない場合は以下のようにMakefileを書き換えてください。
CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
CPPFLAGS += $(shell python3 -m pybind11 --includes)
LIBNAME = helpers
LIBEXT = $(shell ${PYENV_ROOT}/versions/3.11.9/bin/python3-config --extension-suffix)
default: $(LIBNAME)$(LIBEXT)
%$(LIBEXT): %.cpp
$(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
以上で環境構築は終了です。
NGC Containerを利用した方法
上記のリンクから取得できるNGCコンテナを利用することで環境構築の大部分を簡略化することも可能です。ここでは詳細に説明することはしませんが、1つの方法として紹介しておきます。
学習知見
学習環境の構築方法について解説したので、次に、172Bの学習について解説します。
モデルアーキテクチャ
モデルアーキテクチャは以下の通りです。
Llama-2のモデルアーキテクチャを踏襲しました。
| Parameter | Value |
|---|---|
| Hidden size | 12288 |
| Intermediate size | 38464 |
| Number of layers | 96 |
| Number of attention heads | 96 |
| Number of query groups | 16 |
| Activation function | SwiGLU |
| Position embedding | RoPE |
| Normalization | RMSNorm |
ハイパーパラメータ
172Bモデルの学習に用いたハイパーパラメータを下記に記します。
| LR | min LR | LR WARMUP iters | Weight Decay | Grad Clip | global batch size | context length |
|---|---|---|---|---|---|---|
| 1E-4 | 1E-5 | 2000 | 0.1 | 1.0 | 1728 | 4096 |
またOptimizerにはAdamWを利用し、
加えて、学習速度向上のためにFlashAttention、TransformerEngineを利用しました。
分散学習設定
以下の設定で、172Bモデルの学習を行っています。
| モデル名 | node数 | DP | TP | PP | SP | Distributed Optimizer |
|---|---|---|---|---|---|---|
| NII 172B | (非公開) | (非公開) | 4 | 16 | ✔ | ✔ |
Data Parallel + Tensor Parallel + Pipeline Parallelを組み合わせた3D Parallelismを利用しています。
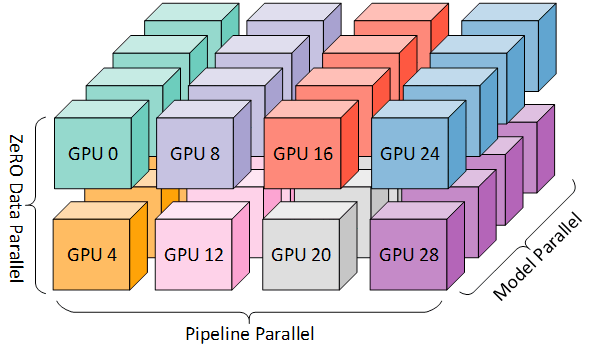
(3D parallelism Microsoft Research blogより)
トポロジーを考慮したMapping
3D Parallelismにおいて、TransformerブロックはPipeline Parallelismにより複数のGPUに分散配置され、さらにTensor Parallelismにより層内のパラメーターも分散配置されます。
この際、 通信を多く必要とする分散手法のワーカー(Tensor Parallelワーカー)はノード内に配置するようにMegatron-LMのデフォルトではなっているため、今回もそれを利用しました。このようにする理由は、ノード内の通信はNVLinkにより、ノード間通信よりも高速であるためです。また、Data Parallelの勾配平均化のための通信を考慮して、Data Parallelワーカーも可能な限りノード内に配置するMegatron-LMデフォルトの挙動を利用しました。
Pipeline Parallelismは他の並列化手法と比較して通信量が少ないP2P(Point-to-Point)通信であるため、パイプラインステージはノード間で配置するようにしました。これも、Megatron-LMデフォルトの挙動です。
Distributed Optimizer
通常のデータ並列は、モデルとOptimizer statesをすべてのData Parallel workerの間で複製しています。しかしながら、この方法はメモリ効率上、非効率です。DeepSpeed ZeRO 1のようにOptimizer Statesを分散して保有することで、この問題を解決できます。今回は、Megatron-LMに実装されているDistributed Optimizerを利用することでメモリの効率的な利用を実現しました。
Sequence Parallel
今回の学習では、Sequence Parallelも採用しました。これによりメモリ効率化が実現でき、より効率的な学習が可能になりました。以下では、採用したSequence Parallelに関して説明します。
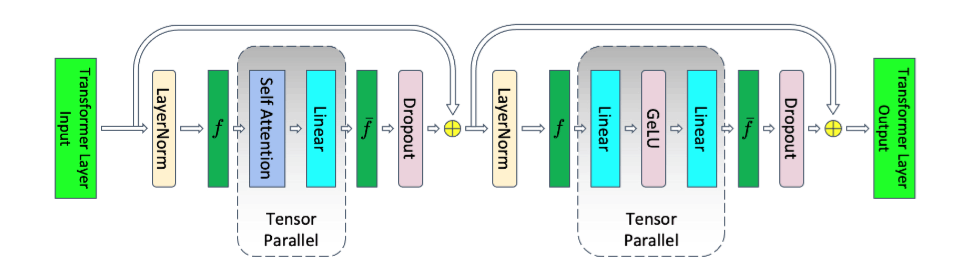
Reducing Activation Recomputation in Large Transformer Models Figure 4 より
上記に示すように、Tensor ParallelでSelf Attention, MLPを並列化できるため、計算効率の面でも、メモリ効率化の点でもTensor Parallelの恩恵は大きいです。しかし、今回の学習では、これに加えてSequence Parallelについても導入しました。
Tensor ParallelによりSelf-Attention, MLPなどは並列化できていましたが、Dropout, LayerNormについては並列化出来ていませんでした。これはすなわち、各Tensor Parallelプロセスが冗長に演算を行っていることに他なりません。幸いなことに、Dropout, LayerNormは比較的軽い演算しか行わないため、計算効率の観点からはこのままでも問題ありません。
しかし、Dropout, LayerNormはActivation memoryをかなり消費するため、メモリ効率化の観点からは並列化出来ていることが望ましいです。
このとき、tensor parallelで並列化されていないtransformer layerの一部分については、系列次元(sequence dimension)において演算が独立であり、系列次元にそって並列化できます。これにより、tensor parallelにおいて並列化されていなかった、Dropout, LayerNormについても並列化することができ、activationのために必要になるメモリ量を削減することができます。
しかし、系列次元に分割を行いGPU間で並列化するには、余分な通信が必要になります。
これは、sequence parallel領域とtensor parallel領域を変換するための処理です。追加的な通信が発生すると、学習全体が遅くなってしまいます。メモリ効率化が実現できても、学習速度が低下してしまっては、あまり嬉しくありません。そのため、Megatron-LMが採用するsequence parallelでは工夫を行っています。
その工夫について一言で説明しますと、追加的な通信を避けるために、tensor parallelにおいて発生していた通信

Reducing Activation Recomputation in Large Transformer Models Figure 5 より
モデルの学習安定化策
z-loss
今回の学習では、昨年度(2023年度) 10月に学習されたllm-jp 175Bモデルの学習が途中で発散してしまい、学習に失敗してしまったことを受け、学習安定化のためにPaLMで採用されているz-lossを取り入れました。
以下がz-lossに関する該当箇所です。

(PaLM: Scaling Language Modeling with Pathwaysより)
batch skipping
PaLMなどの先行研究から、大規模モデルの学習中にgradinet clippingを行っていても発生するLoss Spikeを緩和するには、問題が発生した付近のデータをskipするbatch skippingが有効であることが示されています。
スパイクが始まった約100ステップ前のcheckpointまで戻り、200-500 iteration ほどのデータをスキップすることで、スパイクが発生する前とスパイクが発生していた間のバッチを学習しないようにすることが可能であり、同じ地点でスパイクすることを回避することができると報告されています。こちらについても採用しました。
もしも回復が難しい、またはスパイクの影響が継続するような事態が発生した際に、問題を乗り越えられるようにbatch skippingを導入した形です。
学習高速化
今回の172Bの学習では、以下のようなGPUを効率的に使うための工夫を取り入れました。
TransformerEngine
Transformerブロックを高速に学習するためのライブラリであるTransformerEngineを採用しました。Megatron-LMでは、 --transformer-impl "transformer_engine"というオプションを付けるだけで利用可能であり、非常に簡単に機能をON/OFFすることができます。
FP8を利用した学習の高速化が目立ちますが、TransformerEngineはBF16において利用しても、使用していないよりも高速な学習が可能です。この理由はTransformerモデルのためのfused kernelsなどの最適化によるものです。
今回の学習では、最初の約50B Token学習時点まではBF16 + TransformerEngineを利用した学習を行い、その後、さらなる学習の高速化のためにFP8を利用したFP8 hybrid + TransformerEngineにて学習を行いました。
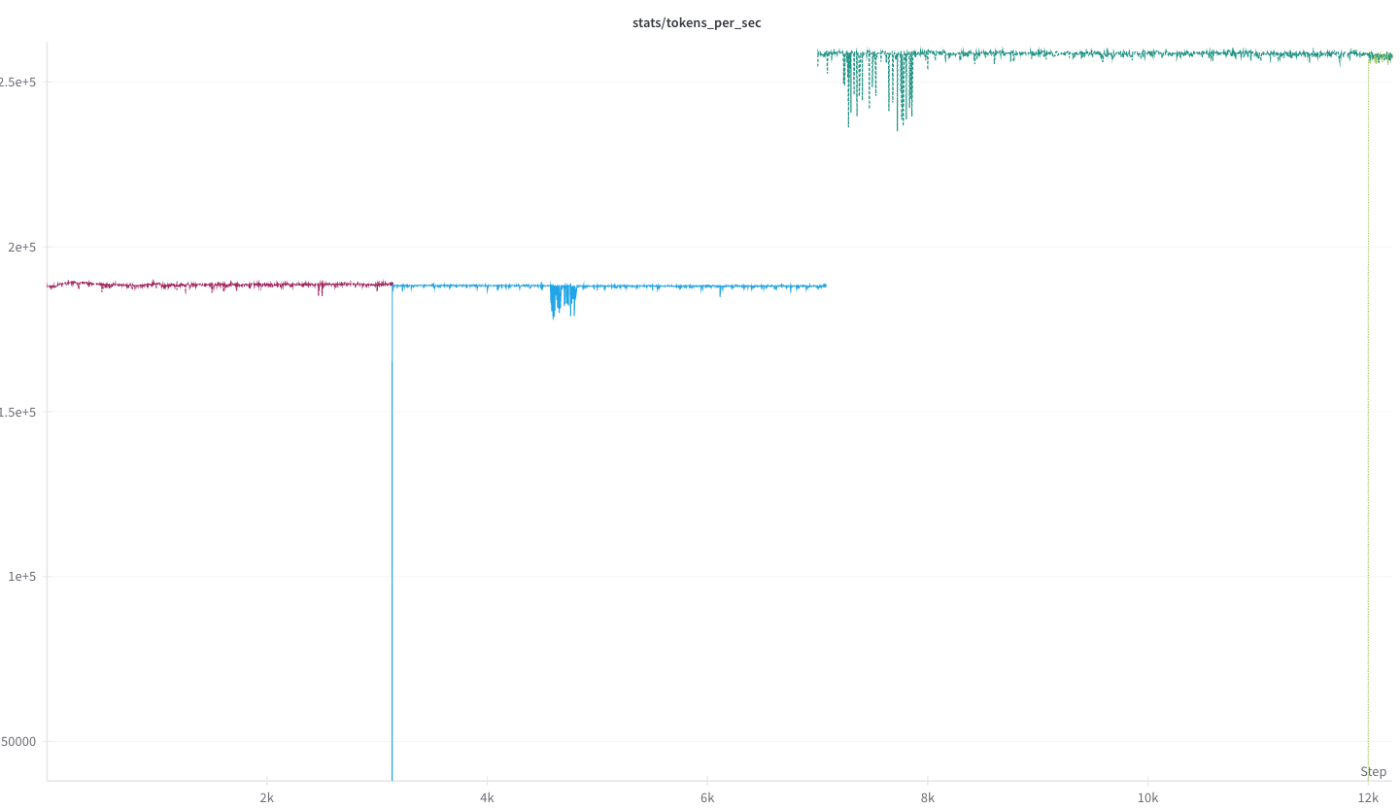
7000iteration以降、急速に tokens/sec が上昇する様子
(TransformerEngine FP8 hybrid の利用によるもの)
FP8のフォーマットには、FP8 E4M3とFP8 E5M2がありますが、FP8 hybridとはforwardとbackwardでこれらのフォーマットを使い分ける手法です。
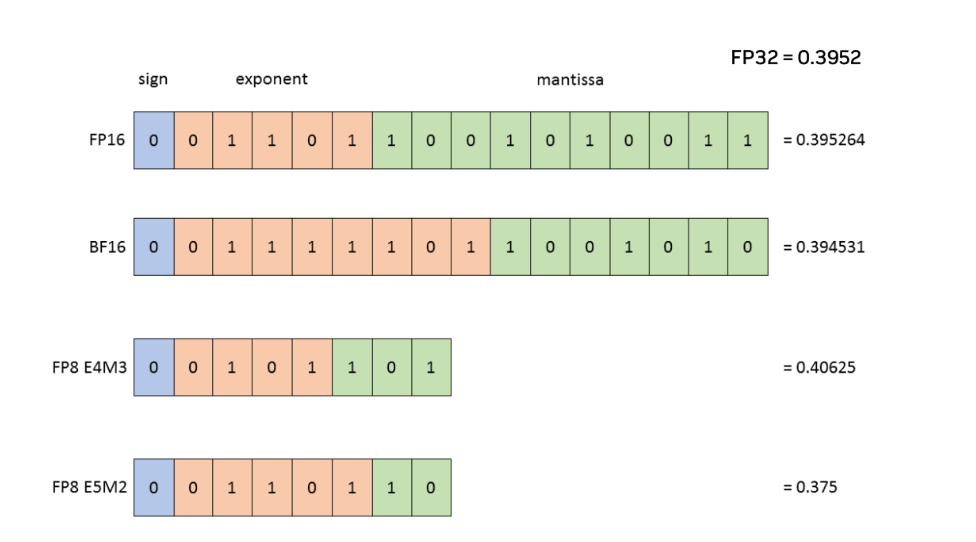
(NVIDIA TransformerEngine docsより)
- E4M3: その名前の通り4つの指数ビット(Exponent bits)と3つの仮数ビット(Mantissa bits)をもちます
- E5M2: その名前の通り5つの指数ビット(Exponent bits)と2つの仮数ビット(Mantissa bits)をもちます
このようにE4M3、E5M2それぞれに特徴があります。一般にニューラルネットワークの学習では、forward activationとweightsには高い精度が必要であるため、仮数ビット数が多いE4M3をforwardに利用します。逆に、backwardでは、gradinet(勾配)については精度の影響を受けにくいと言われており、大きな数値範囲がある方が良いとされています。そのため指数ビットが多いE5M2を利用します。このように2つのformatを利用することで、FP8にした弊害を最小化しつつ学習を行いました。この設定についてもMegatron-LMは --fp8-format 'hybrid'というoptionだけで設定可能なようになっています。
GPUDirect TCPX
今回利用したGoogle Cloud A3 Instanceにて、GPU間通信をトータルで800Gbpsで行うためにGPUDirect-TCPXと呼ばれる仕組みを利用しました。
GPUDirect-TCPXとは、Google Cloud独自のRDMAネットワークスタックであり、NVIDIAのGPUDirect RDMAのようにCPUとシステムメモリを経由せずに、データをGPUメモリからネットワークインターフェースに直接転送できます。これにより、A3 Instanceを利用して複数ノードを利用した学習を行う際のネットワークパフォーマンスが上昇します。詳細についてはGoogle Cloud Docsをご覧ください。
GPUDirect RDMA
NVIDIAのGPUDirect RDMAについても簡単に説明します。
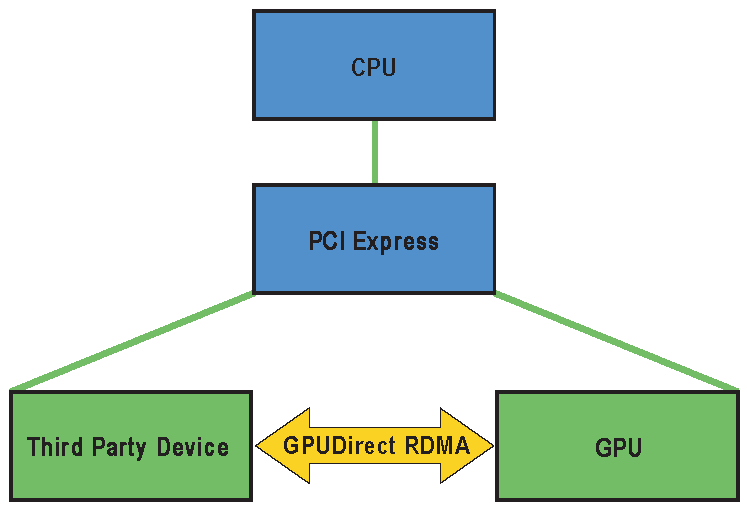
(NVIDIA docs GPU Direct RDMAより)
通常、GPUDirect RDMAを利用しない場合は、GPUのメモリからCPUのメモリにデータをコピーし、そのデータをCPUからNICにコピーすることでデータの転送を行います。このときPCI Express(PCIe)をGPU -> PCIe -> CPU, CPU -> PCIe -> NICという形で通過します。対して、GPUDirect RDMAでは、CPUをバイパスし、GPUメモリからPCIeを通過して直接NICにデータを転送することができます。
これにより、データが複数回コピーされることによって生じるレイテンシの増加を削減したり、PCIeパスを複数回利用することによって生じうる帯域幅の制限、データ転送プロセスのためにCPUリソースが利用されることによるCPU負荷の増加を回避することができます。
このようにGPUDirect RDMAは、大規模分散並列学習を行う際に、ノード間通信を最適化する上で重要な技術です。
Google Cloud A3 GPUDirect-TCPX
構築したA3インスタンスからなるクラスター内で GPUDirect-TCPXを利用するには以下のような環境変数を設定する必要がありました。こちらですが、使用しているインスタンスのimageによって変化するかと思いますので、ご注意ください。
UDS_PATH="/run/tcpx-${SLURM_JOB_ID}"
export NCCL_NET=GPUDirectTCPX_v7
export NCCL_SOCKET_IFNAME=enp0s12
export NCCL_GPUDIRECTTCPX_CTRL_DEV=enp0s12
export NCCL_GPUDIRECTTCPX_SOCKET_IFNAME=enp6s0,enp12s0,enp134s0,enp140s0
export NCCL_CROSS_NIC=0
export NCCL_ALGO=Ring
export NCCL_PROTO=Simple
export NCCL_NSOCKS_PERTHREAD=4
export NCCL_SOCKET_NTHREADS=1
export NCCL_DYNAMIC_CHUNK_SIZE=524288
export NCCL_P2P_NET_CHUNKSIZE=524288
export NCCL_P2P_PCI_CHUNKSIZE=524288
export NCCL_P2P_NVL_CHUNKSIZE=1048576
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export NCCL_NET_GDR_LEVEL=PIX
export NCCL_P2P_PXN_LEVEL=0
export NCCL_GPUDIRECTTCPX_UNIX_CLIENT_PREFIX=${UDS_PATH}
export NCCL_GPUDIRECTTCPX_PROGRAM_FLOW_STEERING_WAIT_MICROS=500000
export NCCL_GPUDIRECTTCPX_TX_BINDINGS="enp6s0:8-21,112-125;enp12s0:8-21,112-125;enp134s0:60-73,164-177;enp140s0:60-73,164-177"
export NCCL_GPUDIRECTTCPX_RX_BINDINGS="enp6s0:22-35,126-139;enp12s0:22-35,126-139;enp134s0:74-87,178-191;enp140s0:74-87,178-191"
export LD_LIBRARY_PATH=/var/lib/tcpx/lib64:${LD_LIBRARY_PATH}
dynamic checkpoint
今回学習に使用しているGoogle CloudのA3 Instance(H100搭載インスタンス)は、メンテンナンスイベントが通常2週間に1度発生します。(参考: Google Cloud)
また、稀に2週間よりも短いスパンでメンテンナンスが入ることがあります。いつ発生するか分からないGPUメンテンナンスですが、何も対策をしないと、学習中のjobが停止してしまい、直前に取ったcheckpointまで巻き戻って学習を再開する必要があります。
今回のように大規模な実験では、わずかなiteration数のロスであっても、GPU時間に換算すると、かなりのロスになります。これを最小化するため、今回の学習ではdynamic checkpointと呼ばれる機構を実装し、採用しました。
動作としては、Google Cloudが事前通知するメンテンナンスイベントを常に監視し、学習に使用しているGPUインスタンスのうち1台でも、メンテンナンス等が発生することになった場合は、メンテンナンス開始30分前にcheckpointをあらかじめ設定した周期とは異なるタイミングでも保存するというものです。これにより、無駄になるGPU時間の最小化を実現し、効率的なGPUの利用を実現しました。
さいごに
本記事では、大規模言語モデルを学習する際の事前学習パートに焦点を当てて、知見の共有を目的に解説を行いました。LLMを開発される企業、団体が、これらの情報を元に、各々の目的にあった高い性能のモデルを作る一助になれば幸いです。
謝辞
この成果は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の助成事業(JPNP20017)の結果得られたものです。
また、DDNのAkimotoさん、Iharaさんには学習環境のセットアップやcheckpointの高速化などについて助言をいただきました。感謝致します。
また、LLM-jpをはじめ関係者の皆様に感謝致します。

Discussion