はじめに
東京工業大学の藤井です。
今回は、GENIACでも採用されているGoogle Cloudにて、H100搭載ノードであるA3 Instanceを利用して大規模学習を行うための環境構築を行う中で得られた知見を紹介させていただきます。
この成果は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の助成事業(JPNP20017)の結果得られたものです。
本記事では、Google CloudにてHPC Toolkitと呼ばれるツールを利用してマルチノード学習環境を整備する方法と、Environment moduleを利用してABCI、TSUBAMEのようなスパコン環境に類似した環境を再現する方法について解説します。
HPC Toolkit とは
Google CloudがOSSで開発しているGoogle Cloud上にHPC環境を簡単に整備できるようにするデプロイツールです。以下のリポジトリにて開発が行われています。
H100が8枚搭載されているA3 Instanceですが、これらが数十台あってもノード間通信を行うための設定やジョブスケジューラなどの設定をユーザーが1からしないと、大規模学習をするための環境は作成できません。HPC Toolkitはblueprintと呼ばれるYAMLファイルを変更し、所定のコマンドを打つだけでスパコンに類する環境を作ることができる非常に便利なツールです。
HPC-Toolkit デプロイ環境構築
HPC ToolkitにてH100クラスターのデプロイを行う前に、まずデプロイをするための環境構築が必要です。Macなどのローカルデバイスからデプロイすることもできますが、今回はGoogle Cloud上でCPUインスタンスを一時的に確保し、そこからデプロイを行うことにします。
GCP ComputeEngineにてCPU Nodeを確保し、デプロイ環境を整備します。今回は以下のような構成のCPUインスタンスを作成しました。
- マシンタイプ: e2-standard-4
- OS:Ubuntu20.04
- ディスク:バランス永続ディスク 100GB
ネットワーク
NAT Routerがないと、CPU Instance内部から外部に疎通ができないため、以下のように作成しましょう。(すでにある場合や、他の方法にて疎通できる場合はここは飛ばして問題ありません)
検索バーから"NAT"と検索して、Cloud NATを選択
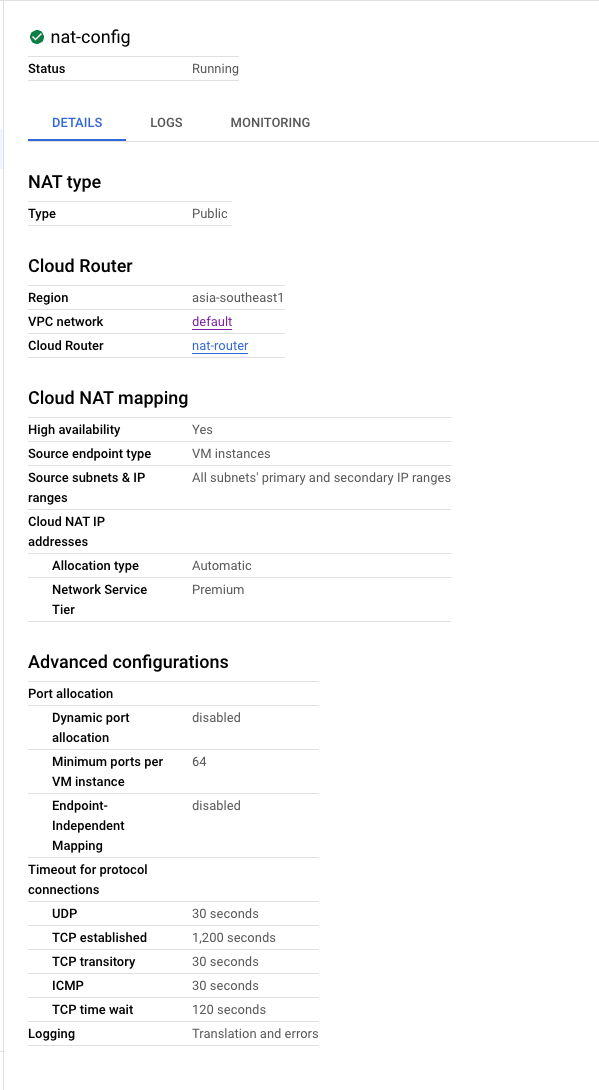
監査ログが欲しい場合は、Logging設定を Traslation adn errorsに設定してください。
環境構築
デプロイ用 CPU Instanceのセットアップ
gcloud compute sshによりCPU nodeにSSHしてください。
gcloud compute ssh <対象のCPU Instance名>でsshできたかと思います。
そこで以下の手順でOSLoginをONにします。(デフォルトではOSLoginがOFFになっているのですがONにします。)
gcloud compute project-info add-metadata --metadata enable-oslogin=TRUE
次に、以下のコマンドを打って、CPU Nodeからgcloud commandが使えるようにします。
上述のネットワーク設定をちゃんとしていないとgcloud initコマンドで無限に停止してしまうので、もしも、そのような症状になった方は、ネットワーク設定を今一度確認してください。
sudo apt update && sudo apt upgrade -y
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key --keyring /usr/share/keyrings/cloud.google.gpg add -
sudo apt-get update
sudo apt-get install -y google-cloud-sdk
gcloud --version
gcloud init
gcloud auth application-default login
gcloud config set <project-name>
ghpc command install
次に、HPC-Toolkitにてデプロイする際に利用されるghpcコマンドをインストールします。
最初にHPC Toolkitのインストールに必要なdependenciesであるterraformとgoのinstallを行います。
まずTerraform, packerのインストールです。
wget -O- https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list
sudo apt update && sudo apt install terraform packer
特に問題なくインストールできるはずです。次にgo のインストールです。
https://go.dev/dl/go1.22.0.linux-amd64.tar.gz
sudo rm -rf /usr/local/go && sudo tar -C /usr/local -xzf go1.22.0.linux-amd64.tar.gz
echo "export PATH=$PATH:/usr/local/go/bin" >> ~/.bashrc
source ~/.bashrc
go version
依存関係がインストールできたので、次はghpcコマンド本体をインストールします。
sudo apt install -y build-essential
git clone https://github.com/GoogleCloudPlatform/hpc-toolkit
cd hpc-toolkit
make
./ghpc --version
vi ~/.bashrc
# export PATH=$PATH:/usr/local/go/bin:/home/ubuntu/hpc-toolkit
source .bashrc
上記では、./ghpc となるのは使い勝手が悪いのでPATHを通していますが、別に通さなくても問題ありません。(適時/home/ubuntu/hpc-toolkitのパスは変更してください)
python 仮想環境
ghpc commandを利用するには、pythonの仮想環境に特定のパッケージがinstallされている必要があるため、環境を作成します。
以下はLinux(Ubuntu 20.04)での環境構築方法であるため、Mac、Windowsでは上手くいかない可能性があることに注意してください。
cd <preffered place>
sudo apt install -y python3-dev python3-venv
python3 -m venv .env
source .env/bin/activate
pip3 install -r https://raw.githubusercontent.com/GoogleCloudPlatform/slurm-gcp/5.10.3/scripts/requirements.txt
以上のようにデプロイするための仮想環境を作成します。
以上で環境構築は終了です🎉
HPC-Toolkit デプロイ準備
IAM権限の確認
以下の権限を有しているか確認してください。
- Compute インスタンス管理者(v1)
- IAP で保護されたトンネル ユーザー
- Pub/Sub 管理者
- 編集者
- サービス アカウント ユーザー
- Compute OS 管理者ログイン
tfstateを保存するためのGCS Bucketの作成
以下のコマンドをローカルのマシンなどで打ち、GCSバケットを作成します。
(AWSに慣れている方向けに説明しますとS3のバケットを作成しているだけです)
export PROJECT_ID=<your-project-id>
export BUCKET=tf-state-bucket
export REGION=<your-region>
gcloud storage buckets create gs://${BUCKET} --project=${PROJECT_ID} \
--default-storage-class=STANDARD --location=${REGION} \
--uniform-bucket-level-access
gcloud storage buckets update gs://${BUCKET} --versioning
ghpc commandにてデプロイする際に作成されるtfstateが保存されるGCSバケットになりますので、できるだけ他の用途のバケットとは分離した方が良いかと思います。
YAMLファイルの変更
デプロイするための設計図になるYAMLファイルを変更していきます。
hpc-toolkitをgit cloneしてexamples/machine-learning/a3-highgpu-8gを確認してください。2024年6月28日現在 ml-slurm-a3-0-base.yaml, ml-slurm-a3-1-image.yaml, ml-slurm-a3-2-cluster.yamlの3つのblueprint YAMLファイルがあります、これらを変更してデプロイを行っていきます。
まずは、ml-slurm-a3-0-base.yamlを変更していきましょう。
20行目〜28行目を修正していきます。
<your-tf-state-bucket>には、上記で作成したtfstateを保存するためのGCSバケット名を指定してください。また<your-project-ID>には利用するプロジェクトIDを指定してください。
(以下では東京リージョンasia-northeast1を利用する形になっていますが、それぞれの状況に応じて変更してください。Google Cloudの担当者等にH100インスタンスが空いているリージョン、ゾーンについて問い合わせる等を行ってください)
- bucket: customer-tf-state-bucket
+ bucket: <your-tf-state-buket>
vars:
- project_id: ## Set GCP Project ID Here ##
+ project_id: <your-project-ID>
deployment_name: slurm-a3-base
- region: customer-region
- zone: customer-zone
+ region: asia-northeast1
+ zone: asia-northeast1-b
sys_net_range: 172.16.0.0/16
- filestore_ip_range: 192.168.0.0/29
# ref: https://github.com/GoogleCloudPlatform/hpc-toolkit/tree/main/modules/file-system/filestore
# Reserved IP range for Filestore instance. Users are encouraged to set to null
+ # filestore_ip_range: 192.168.0.0/29
HPC-Toolkitでは /homeにFilestoreによるNFSを構築するようになっています。
以下のようにml-slurm-a3-0-base.yamlを修正して、希望のストレージを確保してください。
また、filestore_tierに何を指定するかで、ストレージへのアクセス速度が異なります。
以下のスペックシートを参考に、どの程度のRead/Write性能が欲しいのか検討してください。
以下に例として、そこそこの速度が出てほしく、30TBの容量が欲しい場合の例を貼ります。
- filestore_tier: BASIC_SSD
- size_gb: 2560
+ filestore_tier: ZONAL
+ size_gb: 30720
local_mount: /home
- reserved_ip_range: $(vars.filestore_ip_range)
+ # reserved_ip_range: $(vars.filestore_ip_range)
これでexamples/machine-learning/a3-highgpu-8g/ml-slurm-a3-0-base.yamlの変更は終了です。次に、examples/machine-learning/a3-highgpu-8g/ml-slurm-a3-1-image.yamlの変更に移ります。
21行目から34行目をまず変更します。
基本的には、先ほどと同様にtfstateのためのバケット、region、zoneなどを変更しています。
注意するべきはsource_image_project_idとsource_imageです。こちらはGoogle Cloudの担当者に問い合わせて、使用するimageを決めてください。LLMやVLMなどの学習に利用する場合はdeeplearning-latform系統かと思いますが、確認をオススメします。
- bucket: customer-tf-state-bucket
+ bucket: <your-tf-state-buket>
vars:
- project_id: ## Set GCP Project ID Here ##
+ project_id: <your-project-ID> ## Set GCP Project ID Here ##
deployment_name: slurm-a3-image
- region: customer-region
- zone: customer-zone
+ region: asia-northeast1
+ zone: asia-northeast1-b
disk_size: 200
final_image_family: slurm-dlvm
- network_name_system: slurm-sys-net
- subnetwork_name_system: slurm-sys-subnet
+ network_name_system: slurm-a3-base-sysnet
+ subnetwork_name_system: slurm-a3-base-sysnet-subnet
slurm_cluster_name: slurm0
- source_image_project_id: source-image-project-id # use value supplied by Google Cloud staff
- source_image: source-image-name # use value supplied by Google Cloud staff
+ source_image_project_id: deeplearning-platform # use value supplied by Google Cloud staff
+ source_image: dlvm-tcpd-cu120-xxxx-1800-rc0-ubuntu-2004-py310
次にデプロイする環境によってはmachine_typeを変更する必要があります。
( examples/machine-learning/a3-highgpu-8g/ml-slurm-a3-1-image.yaml 256行目)
- machine_type: c2d-standard-32
+ machine_type: c2-standard-30
シンガポールリージョンなどにはc2d-standard-32インスタンスがあるのですが、東京リージョンなどにはc2d-standard-32インスタンスがないので、c2-standard-30に切り替える必要があります。
以上で、examples/machine-learning/a3-highgpu-8g/ml-slurm-a3-1-image.yamlの変更は終了です。最後に、examples/machine-learning/a3-highgpu-8g/ml-slurm-a3-2-cluster.yamlを変更します。
まず、24行目から28行目を変更しましょう。以下のように変更します。
- project_id: ## Set GCP Project ID Here ##
+ project_id: <your-project_ID> ## Set GCP Project ID Here ##
deployment_name: slurm-a3-cluster
- region: customer-region
- zone: customer-zone
- server_ip_homefs: 0.0.0.0 ## MUST set to IP address of Filestore instance from base deployment!
+ region: asia-northeast1
+ zone: asia-northeast1-b
+ server_ip_homefs: 10.76.0.xxx ## MUST set to IP address of Filestore instance from base deployment!
project_idは前述のとおりです。region, zoneについても先ほどと同様に変更してください。server_ip_homefsですが、こちらはexamples/machine-learning/a3-highgpu-8g/ml-slurm-a3-0-base.yamlをデプロイしたときに分かる値を挿入するため、いったん空白にするか仮の値を入れておきましょう。
次に reservation nameを変更します。
- a3_reservation_name: a3-reservation-0
+ # a3_reservation_name: a3-reservation-0
こちらは、プロジェクトによって指定するべきかどうかが変わるため一概には言えないのですが、今回のプロジェクトではコメントアウトしました。
大規模なノード予約の場合は、Google Cloudの担当者が予約を行い、そのreservation nameを担当者から伝えられるというフローを取る場合があるかと思いますので、状況に応じて対応を変更してください。
次も場合によって対応が分かれるので、Google Cloudの担当者などと確認することをオススメします。今回はServiceAccountを作成せずに既存のServiceAccountを利用する形にしています。
まず76-84行目をコメントアウトします。(以下のようにしてください)
- - id: compute_sa
- source: community/modules/project/service-account
- settings:
- name: compute
- project_roles:
- - logging.logWriter
- - monitoring.metricWriter
- - pubsub.subscriber
- - storage.objectAdmin
+ # - id: compute_sa
+ # source: community/modules/project/service-account
+ # settings:
+ # name: compute
+ # project_roles:
+ # - logging.logWriter
+ # - monitoring.metricWriter
+ # - pubsub.subscriber
+ # - storage.objectAdmin
次に新しく作成したServiceAccountではなく、既存のServiceAccountを使用するように設定するため130行目を以下のように修正します。(上述の通り、Service Accountを今回のために作成して運用する場合もあると思いますので、その場合はこの措置はいりません)
- email: $(compute_sa.service_account_email)
+ email: 92xxxxxxxx-compute@developer.gserviceaccount.com
最後に、クラスターで使用するH100のノード数とログインノードのスペックを変更していきましょう。
40行目の以下を使用するH100ノードの数に合わせて変更してください。以下は16node使用する場合です。
- a3_static_cluster_size: 32
+ a3_static_cluster_size: 16
では最後にログインノードのスペックの変更を行います。206行目を以下のように変更してください。
- machine_type: c2-standard-4
+ machine_type: c2-standard-16
ログインノードにvscodeのRemote SSH等で多数のユーザーが接続することを想定して、かなり余裕をもった設定に上記ではしていますが、状況に応じて修正してください。
以上で、デプロイするために必要な修正は終了です。
問題がないようでしたら、次の節で紹介するデプロイコマンドに従ってクラスターをデプロイしていきましょう。
デプロイ
準備ができたので、早速デプロイしていきましょう。
hpc-toolkit/examples/machine-learning/a3-highgpu-8gまで移動してから以下のコマンドにて、まずml-slurm-a3-0-base.yamlの設定をデプロイしましょう。
(約5〜10分ほどかかります)
ghpc deploy ml-slurm-a3-0-base.yaml --auto-approve
デプロイできると、以下のような記述が出てくるかと思います。(多少細部は異なります)
network_name_sysnet = "sys-net"
network_storage_homefs = {
"client_install_runner" = {
"destination" = "install-nfs_home.sh"
"source" = "modules/embedded/modules/file-system/filestore/scripts/install-nfs-client.sh"
"type" = "shell"
}
"fs_type" = "nfs"
"local_mount" = "/home"
"mount_options" = "defaults,_netdev"
"mount_runner" = {
"args" = "\"10.224.153.226\" \"/nfsshare\" \"/home\" \"nfs\" \"defaults,_netdev\""
"destination" = "mount_home.sh"
"source" = "modules/embedded/modules/file-system/filestore/scripts/mount.sh"
"type" = "shell"
}
"remote_mount" = "/nfsshare"
"server_ip" = "10.224.153.226"
}
subnetwork_name_sysnet = "sys-subnet"
こちらのserver_ipはFilestoreのIPになります。先程、examples/machine-learning/a3-highgpu-8g/ml-slurm-a3-2-cluster.yamlを変更する際に、いったん空白または仮の値を入れていた箇所に、この数値(上記では10.224.153.226)を入れてください。
これでml-slurm-a3-0-base.yamlのデプロイは完了しました。
次にml-slurm-a3-1-image.yamlをデプロイしていきましょう。
以下のコマンドでデプロイ可能です。
ghpc deploy ml-slurm-a3-1-image.yaml --auto-approve
30〜45分ほどかかりますので、少々時間がかかりますが気長に待ちましょう。
もしエラーが発生した場合は、利用する予定のimageにアクセス権がない、またはmachine_typeが不適切などが原因として考えられます。再度確認することをオススメします。
問題なくデプロイできた場合は、最後にml-slurm-a3-2-cluster.yamlをデプロイしていきましょう。以下のコマンドでデプロイ可能です。(10分ほどかかります)
ghpc deploy ml-slurm-a3-2-cluster.yaml --auto-approve
以上でデプロイは終了です。お疲れ様でした🎉
デプロイ後の諸設定
上述の手順通りに行っていれば、OS Loginが有効化されているはずなので、問題ないと思われますが、上手くログインできない場合は、roles/compute.osLogin、roles/compute.osLoginExternalUserの権限が足らない可能性が考えれられます。
今一度、以下のIAM権限があるか確認してください。
- Compute インスタンス管理者(v1)
- IAP で保護されたトンネル ユーザー
- Pub/Sub 管理者
- 編集者
- サービス アカウント ユーザー
- Compute OS 管理者ログイン
vscode の設定
Visual Studio CodeのRemote SSH機能を利用してLoginノードにつなぎたくなることがあるかと思います。そのようなときに、どのようにつなげばよいのかを解説します。
まず、以下のコマンドを打ちます。
gcloud compute ssh <instance-name> --dry-run
--dry-runオプションをつけて、ssh するためのコマンドを取得します。
取得したコマンドを整形して以下のようにssh configを作成します。
~/.ssh/configを編集して以下のようなものを追加してください。
User名はgcloud compute sshにてログインしたときに表示されるものにしてください。
(= kazuki_fujiiとなっているところを修正してください)
<host_name>にはこのクラスターであると識別できるお好きな名前を指定してください。
Host <host_name>
HostName compute.856xxxxxxxxxxxxx
User kazuki_fujii
IdentityFile /Users/kazuki/.ssh/google_compute_engine
CheckHostIP no
HashKnownHosts no
HostKeyAlias compute.856xxxxxxxxxxxxx
IdentitiesOnly yes
StrictHostKeyChecking yes
UserKnownHostsFile /Users/kazuki/.ssh/google_compute_known_hosts
ProxyCommand /Users/kazuki/.pyenv/versions/3.10.10/bin/python3 /Users/kazuki/google-cloud-sdk/lib/gcloud.py compute start-iap-tunnel 'slurm0-login-1luzjsp5-001' '%p' --listen-on-stdin --project <project> --zone=asia-southeast1-c --verbosity=warning
ProxyUseFdpass no
これで通常のvscodeのRemote SSH機能を利用してRemote SSH接続ができるかと思います。
.bashrc
HPC Toolkitにて作成された環境のbashrcを見ると、場合によってはcondaが勝手にactivateされるようになっている場合があります。また、user名が非常に長く出力されてしまうことがあります。
以下のような記述を.bashrcの最下部に追加してください。
conda deactivate
PS1='\[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\[\033[01;32m\]$(echo "\u" | sed -r "s/ext_([^_]*)_([^_]*).*/\1_\2/")@$(hostname | sed -n "s/.*\(slurm0-login\).*/\1/p;T;h;g")\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ '
Environment moduleの整備
次にスパコン環境と同様にユーザーが異なるソフトウェアバージョンを切り替えられるようにEnvironment Modulesを導入します。以下では、CUDA Toolkit、cuDNN、nccl、hpcxのツールをEnvironemt modules管理下に置くための方法について解説しています。
Environemt Modulesについて詳しく知りたい方は以下のリンクをご覧ください。
簡単に使い方を理解したい場合は、以下のABCIのドキュメントが分かりやすいかと思います。
CUDA Toolkit
最新版は、以下のリンクからDownloadできます。
以下のスクリーンショットのように選択していきます。
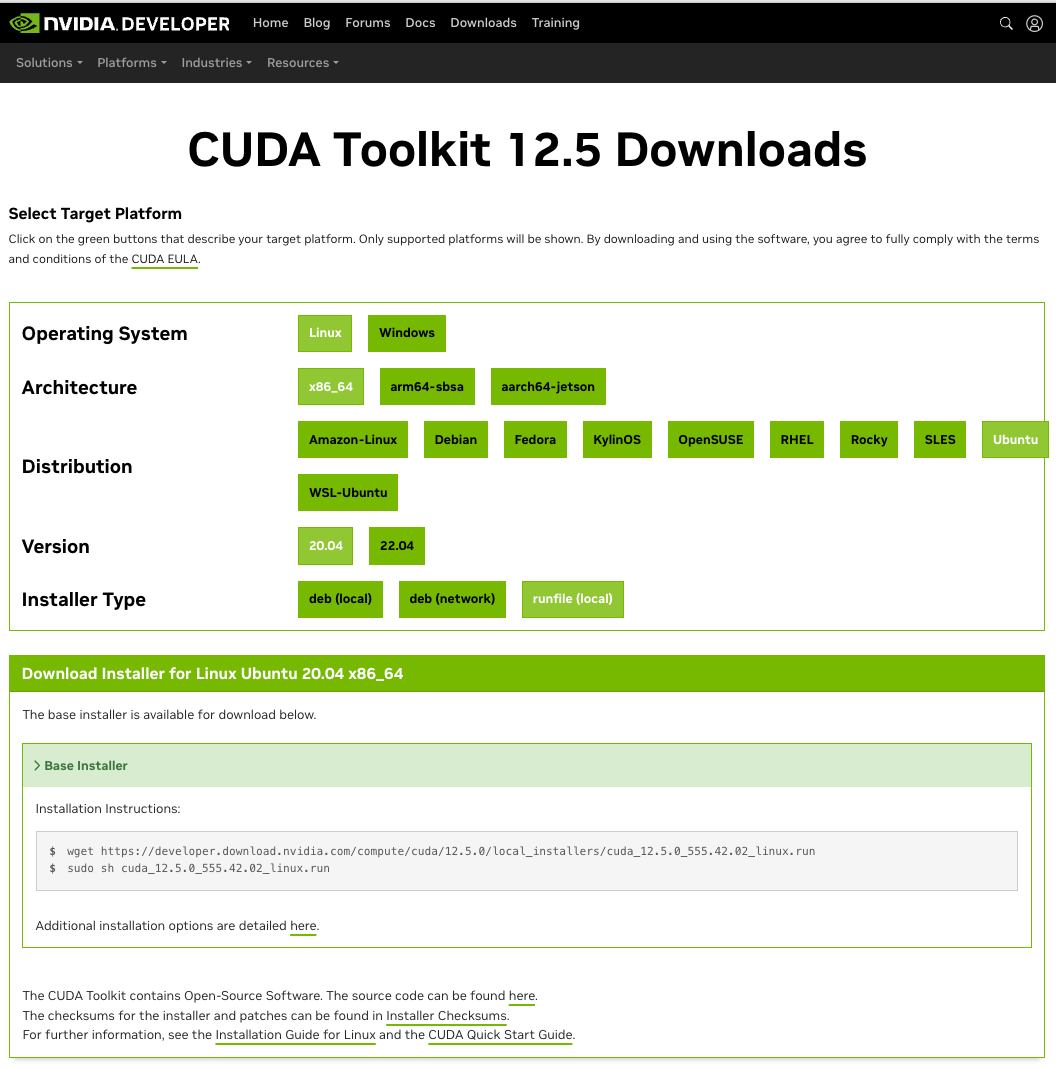
Operating System, Architecture, Distribution, Versionなどを選び、Installer Type runfile(local)を選択すると以下のようなコマンドが出ます。
wget https://developer.download.nvidia.com/compute/cuda/12.5.0/local_installers/cuda_12.5.0_555.42.02_linux.run
sudo sh cuda_12.5.0_555.42.02_linux.run
上記のコマンドを利用しても良いのですが、sudoが利用できないスパコン環境(ABCI、TSUBAMEなど)では利用できないため、CUDA Toolkitだけをインストールする以下のコマンドに変更します。
sh cuda_12.5.0_555.42.02_linux.run --silent --toolkit --toolkitpath=<install path>
インストールできると<install path>に指定したパスに以下が入ります。(下記はCUDA-12.1の例)
> ls
bin DOCS extras gds-12.1 lib64 nsight-compute-2023.1.0 nsight-systems-2023.1.2 nvvm share targets version.json
compute-sanitizer EULA.txt gds include libnvvp nsightee_plugins nvml README src tools
これで、Environment Modulesで管理する対象のCUDA Toolkitのインストールができました。
最新版ではなく古いCUDA Toolkitをインストールしたい場合は以下のリンクから探してください。
次に、module availで認識できるようにModulefileを作成します。
#%Module1.0
##
## CUDA 12.1 modulefile
##
proc ModulesHelp { } {
puts stderr "This module adds CUDA 12.1 to your environment variables."
}
module-whatis "Sets up CUDA 12.1 in your environment"
set version 12.1
set cuda_home /path/to/install/modules/cuda/cuda-$version
prepend-path PATH $cuda_home/bin
prepend-path LD_LIBRARY_PATH $cuda_home/lib64
prepend-path MANPATH $cuda_home/doc/man
setenv CUDA_HOME $cuda_home
こちらを$MODULEPATHで設定されているパス配下に置くことでmodule availで参照できるようになります。
cuDNN
最新版については、以下のリンクからDownloadしてください。
ログインしていない場合はログインして、Download cuDNN Libraryをクリックしてください。
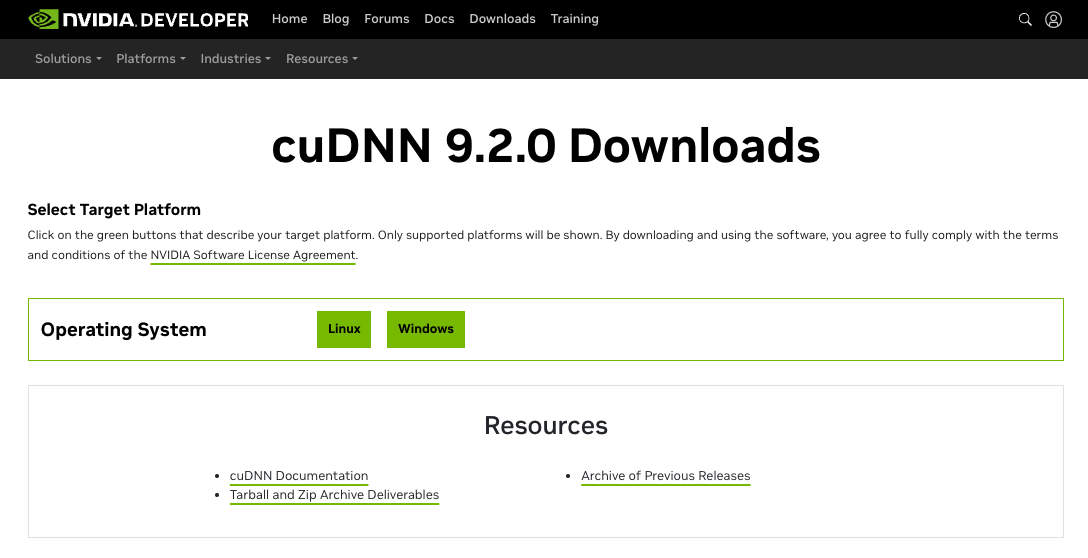
Operationg Systemを選んで (今回はLinux)、Architectureを選んで(x86_64)、DistributionはTarballを選択して、対応するCUDA Toolkit versionを選んで(今回は12系用なので12)ください。
すると以下のようになります。
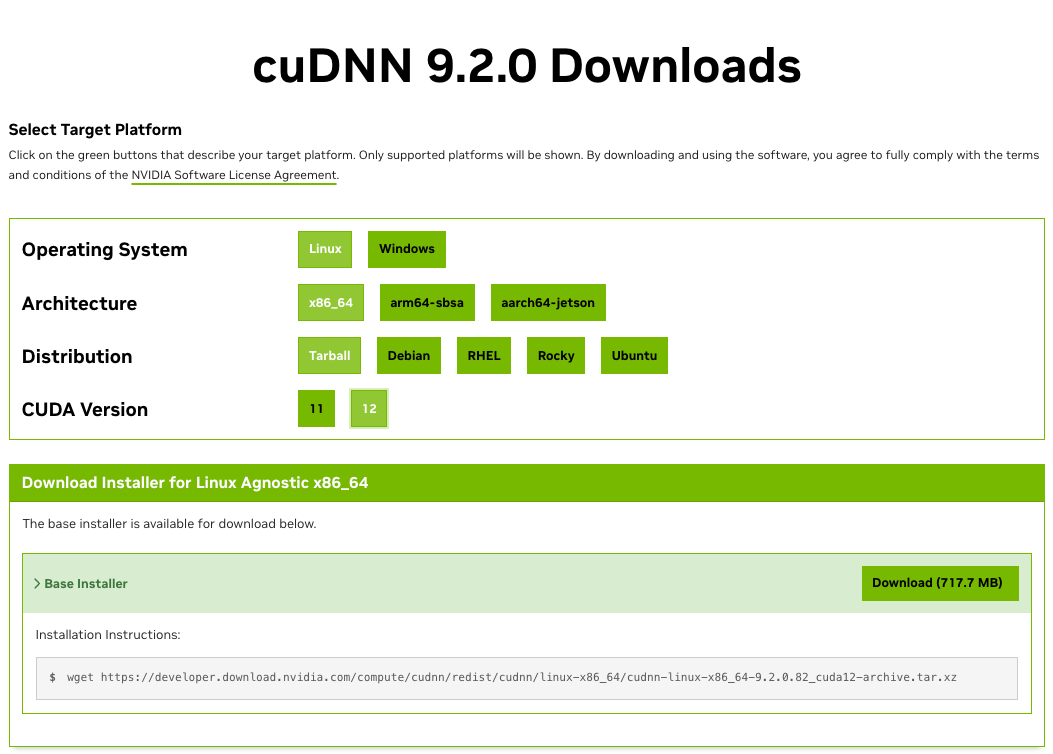
ローカルのマシンに落としたいときは、Downloadを押してください。今回は、クラスターにdownloadしたいので、以下のコマンドをコピーします。
wget https://developer.download.nvidia.com/compute/cudnn/redist/cudnn/linux-x86_64/cudnn-linux-x86_64-9.2.0.82_cuda12-archive.tar.xz
実際に実行すると以下のようになり、cudnn-linux-x86_64-9.2.0.82_cuda12-archive.tar.xzがdownloadされます。
> wget https://developer.download.nvidia.com/compute/cudnn/redist/cudnn/linux-x86_64/cudnn-linux-x86_64-9.2.0.82_cuda12-archive.tar.xz
--2024-06-26 13:02:13-- https://developer.download.nvidia.com/compute/cudnn/redist/cudnn/linux-x86_64/cudnn-linux-x86_64-9.2.0.82_cuda12-archive.tar.xz
Resolving developer.download.nvidia.com (developer.download.nvidia.com)... 152.199.39.144
Connecting to developer.download.nvidia.com (developer.download.nvidia.com)|152.199.39.144|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 752511848 (718M) [application/octet-stream]
Saving to: ‘cudnn-linux-x86_64-9.2.0.82_cuda12-archive.tar.xz’
cudnn-linux-x86_64-9.2.0.82_cuda12-archive.ta 100%[==============================================================================================>] 717.65M 191MB/s in 3.7s
2024-06-26 13:02:19 (191 MB/s) - ‘cudnn-linux-x86_64-9.2.0.82_cuda12-archive.tar.xz’ saved [752511848/752511848]
あとは tar xvfで解凍するだけです。
`tar xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz`
> tar xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_infer_static.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_infer_static_v8.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_train_static.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_train_static_v8.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_infer_static.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_infer_static_v8.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_train_static.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_train_static_v8.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_infer_static.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_infer_static_v8.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_train_static.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_train_static_v8.a
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn.so.8
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn.so.8.9.7
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn.so
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_infer.so.8.9.7
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_infer.so
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_infer.so.8
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_train.so
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_train.so.8
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_adv_train.so.8.9.7
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_infer.so.8.9.7
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_infer.so
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_infer.so.8
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_train.so
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_train.so.8.9.7
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_cnn_train.so.8
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_infer.so.8.9.7
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_infer.so
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_infer.so.8
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_train.so.8.9.7
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_train.so
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn_ops_train.so.8
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_adv_infer_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_adv_train_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_backend_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_cnn_infer_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_cnn_train_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_ops_infer_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_ops_train_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_version_v8.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_adv_infer.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_adv_train.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_backend.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_cnn_infer.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_cnn_train.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_ops_infer.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_ops_train.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn_version.h
cudnn-linux-x86_64-8.9.7.29_cuda12-archive/LICENSE
解凍が終わったら、所定の場所に移動してください。
(全ノードから参照可能な場所であれば、どこでも問題はありません)
modulefileを以下のように書きます。
#%Module1.0
##
## cuDNN 8.9.7 modulefile
##
proc ModulesHelp { } {
puts stderr "This module adds cuDNN 8.9.7 to your environment variables."
}
module-whatis "Sets up cuDNN 8.9.7 in your environment"
set version 8.9.7
set cudnn_root /path/to/cudnn-linux-x86_64-8.9.7.29_cuda12-archive
prepend-path LD_LIBRARY_PATH $cudnn_root/lib
prepend-path LIBRARY_PATH $cudnn_root/lib
prepend-path CPATH $cudnn_root/include
setenv CUDNN_PATH $cudnn_root
setenv CUDNN_INCLUDE_DIR $cudnn_root/include
setenv CUDNN_LIBRARY_DIR $cudnn_root/lib
setenv CUDNN_ROOT_DIR $cudnn_root/
これでcuDNNをEnvironement Modulesで管理できるようになりました。
nccl
以下のリンクから最新以外のncclをdownloadすることができます。
仮にNCCL 2.20.5 for CUDA 12.4 をdownloadする場合は、以下のようにLocal Installers (x86) から O/S agnostic local installer を選択して、txzファイルをdownloadします。

downloadしたファイルの解凍は以下のようにしてください。
> tar -xvf nccl_2.20.5-1+cuda12.2_x86_64.txz
nccl_2.20.5-1+cuda12.2_x86_64/include/
nccl_2.20.5-1+cuda12.2_x86_64/include/nccl.h
nccl_2.20.5-1+cuda12.2_x86_64/include/nccl_net.h
nccl_2.20.5-1+cuda12.2_x86_64/lib/
nccl_2.20.5-1+cuda12.2_x86_64/lib/libnccl_static.a
nccl_2.20.5-1+cuda12.2_x86_64/lib/libnccl.so.2.20.5
nccl_2.20.5-1+cuda12.2_x86_64/lib/libnccl.so
nccl_2.20.5-1+cuda12.2_x86_64/lib/pkgconfig/
nccl_2.20.5-1+cuda12.2_x86_64/lib/pkgconfig/nccl.pc
nccl_2.20.5-1+cuda12.2_x86_64/lib/libnccl.so.2
nccl_2.20.5-1+cuda12.2_x86_64/LICENSE.txt
以下のように、解凍したフォルダごと全ノードから参照可能なディレクトリに移動します。
(/lustre/share/modules/nccl/は、それぞれの環境ごとに変えてください。)
sudo mv nccl_2.18.3-1+cuda12.1_x86_64 /lustre/share/modules/nccl/
ncclはCUDA Toolkit versionに依存しているため、キレイに管理したい場合は以下のようにするとよいかと思います。
/path/to/modules/nccl/cuda-12.1/2.18.3
Modulefileは以下のように書いてください。
#%Module1.0
## NCCL 2.18.3 modulefile
proc ModulesHelp { } {
puts stderr "NCCL 2.18.3"
}
module-whatis "Sets up NCCL 2.18.3 in your environment"
set version 2.18.3
set nccl_root /path/to/modules/nccl/nccl_2.18.3-1+cuda12.1_x86_64
prepend-path LD_LIBRARY_PATH $nccl_root/lib
prepend-path LIBRARY_PATH $nccl_root/lib
prepend-path CPATH $nccl_root/include
setenv NCCL_HOME $nccl_root
setenv NCCL_INCLUDE_DIR $nccl_root/include
setenv NCCL_LIBRARY_DIR $nccl_root/lib
setenv NCCL_VERSION $version
hpcx
以下のリンクからdownloadすることができます。
画面を下にスクロールして、Resourcesセクションを見つけます。
その後、Downloadを選択して、downloadしたいversionを選択します。
適切に環境を選択するとそれに応じたtbzファイルをdownloadできるようになるのでdownloadしましょう。


downloadしたファイルは以下のように解凍します。
tar -xvf hpcx-v2.19-gcc-inbox-ubuntu20.04-cuda12-x86_64.tbz
Modulefileは以下のように設定してください。(一部設定を省いていますので、お好みの形でカスタマイズしてください。)
#%Module
set fn $ModulesCurrentModulefile
set fn [file normalize $ModulesCurrentModulefile]
if {[file type $fn] eq "link"} {
set fn [ exec readlink -f $fn]
}
set hpcx_dir /path/to/modules/hpcx/hpcx-v2.17.1-gcc-inbox-redhat9-cuda12-x86_64
set hpcx_mpi_dir $hpcx_dir/ompi
module-whatis NVIDIA HPC-X toolkit
setenv HPCX_DIR $hpcx_dir
setenv HPCX_HOME $hpcx_dir
setenv HPCX_MPI_DIR $hpcx_mpi_dir
setenv HPCX_OSHMEM_DIR $hpcx_mpi_dir
setenv HPCX_MPI_TESTS_DIR $hpcx_mpi_dir/tests
setenv HPCX_OSU_DIR $hpcx_mpi_dir/tests/osu-micro-benchmarks-7.2
setenv HPCX_OSU_CUDA_DIR $hpcx_mpi_dir/tests/osu-micro-benchmarks-7.2-cuda
prepend-path PATH $hpcx_mpi_dir/tests/imb
prepend-path CPATH $hpcx_mpi_dir/include
prepend-path PKG_CONFIG_PATH $hpcx_dir/ompi/lib/pkgconfig
prepend-path MANPATH $hpcx_mpi_dir/share/man
# Adding MPI runtime
setenv OPAL_PREFIX $hpcx_mpi_dir
setenv PMIX_INSTALL_PREFIX $hpcx_mpi_dir
setenv OMPI_HOME $hpcx_mpi_dir
setenv MPI_HOME $hpcx_mpi_dir
setenv OSHMEM_HOME $hpcx_mpi_dir
setenv SHMEM_HOME $hpcx_mpi_dir
prepend-path PATH $hpcx_mpi_dir/bin
prepend-path LD_LIBRARY_PATH $hpcx_mpi_dir/lib
prepend-path LIBRARY_PATH $hpcx_mpi_dir/lib
複数のGCP環境を利用しているときのTips
gcloud config configurations activate <config-name>
上記のコマンドで別プロジェクトに切り替えることが可能です。
複数の組織に所属しており、切り替える必要があるときなどに重宝します。
最後に
以上でHPC-Toolkitを利用して、大規模学習を行うための環境作成方法と、その環境を充実させるためにEnvironment Modulesをどのように設定すれば良いのかについて説明してきました。
これらの知見が何かしらの形で役に立つことを願っています。
謝辞
この成果は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の助成事業(JPNP20017)の結果得られたものです。
また、Google Cloudをはじめ関係者の皆様のご協力感謝致します。

Discussion