Open16
RAG


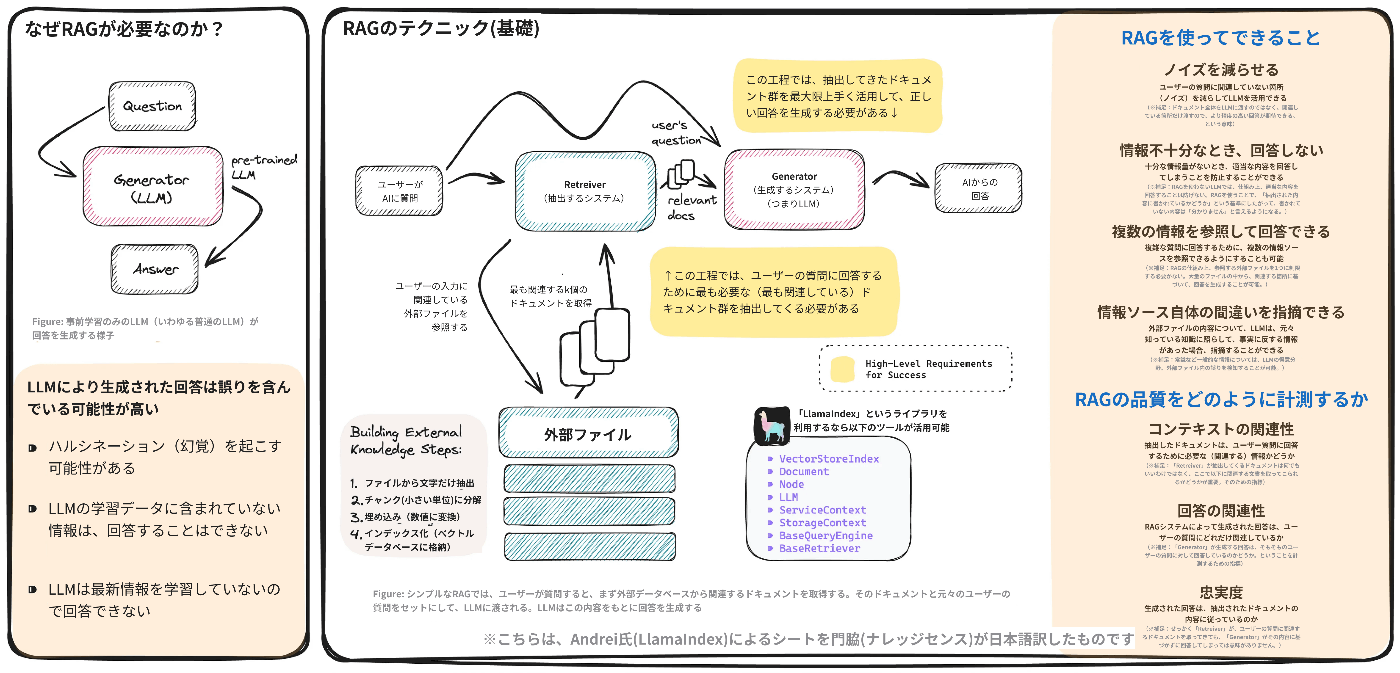
- RAGの必要性は、現在のLLMにおける基本的な制約から生じている
- 事前に訓練されたインターネットテキストのみから知識を得ており、実世界を認識する能力に欠ける
- RAGは、動的な外部知識を注入し、知識集約型のプロンプトに対するLLMの応答精度を高めるのに役立っている
- Speeding up Attention Mechanisms
- Yarn、GPT-4-Turbo、Claude 2.1のようなLLMは、最大200kトークンのコンテキストサイズをサポート
- コンテキストサイズの拡大により、LLMはより広範な知識ベースを同化できるようになり、おそらくRAGの外部知識検索が冗長になる可能性がある
- Beyond Transformers
- マンバやRWKVのような新しいアーキテクチャは、トランスフォーマーのパラダイムに挑戦している
- RAG: Necessity to Niche?
- LLMの限界を補強するためのベクトル・データベースの必要性は、これらのモデルが本質的にコンテキストの長さを無制限に拡張するものである以上、薄れていくだろう
- The Future of LLMs and RAG
- LLMは、ベクター・データベースやテキスト・チャンキングといったRAGアーキテクチャ全体が不要になるほど、知識リポジトリが膨大になる現実に向かって着実に進んでいる
- 何らかの形の検索システムは、コンテキストに入力するために不可欠なままかもしれない
- RAGの登場は一時的な制限に対する創造的な解決策であった
- LLMがより大きなコンテクスト容量とより効率的なアーキテクチャで進化するのを目の当たりにするにつれ、RAGへの依存度はおそらく低下し、最終的には陳腐化するだろう
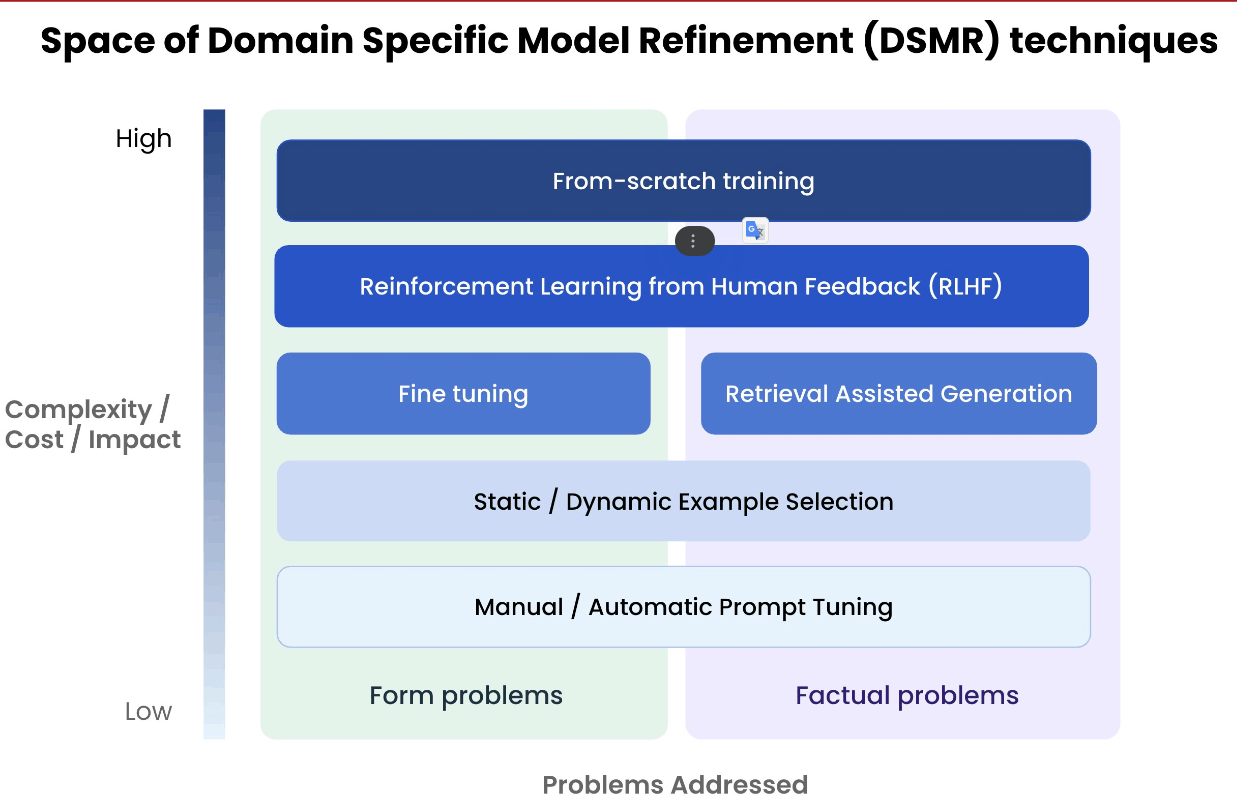
Fine tuningは出力形式の最適化、RAGは事実問題/知識の最適化。