はじめまして。損害保険ジャパン株式会社 DX推進部の眞方です。普段はリードエンジニアとして、新しいサービスのアーキテクチャ検討からローンチまでの作業や、新規技術を用いたアプリのプロトタイプ実装などを行なっています。
弊社では、LLM(Large Language Models)を活用したアプリケーションの開発を積極的に検討し、既に社内でいくつかのプロトタイプをローンチしています。
本記事では、その最も一般的?なユースケースの一つとも言えるRAG(Retrieval Augmented Generative)の構築において、ドキュメント検索精度の向上にどのように取り組んだ内容の概要を紹介させていただきます。実際の詳細な手法および結果については、別記事(実践編)で解説予定です。
はじめに
RAGとは?
この記事を読まれている方の中にはご存知の方も多いでしょうが、RAGとはRetrieval Augmented Generativeのことです。その名前からも分かる通り、RAGは検索(Retrieval)と生成(Generative)の2つの機能を組み合わせることによって、構築されています。
検索(Retrieval)部分では、与えられたクエリ(質問文等)に基づいて大規模なテキストデータベースから関連情報を高速に抽出します。そして、その情報をもとに生成モデルが自然な文章を生成し、ユーザーに対して回答や説明を提供します。
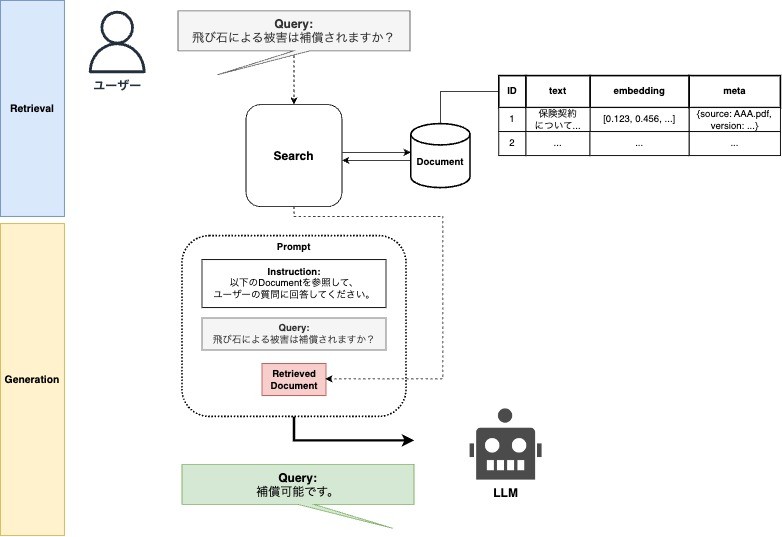
RAGの処理フロー
Information Retrieval
前述の通り、RAGの構築には質問文から関連ドキュメントを検索する仕組みが不可欠です。いくつかその代表的な手法をご紹介します。
-
BM25
BM25は、情報検索の分野で広く使用されているランキング関数の一つです。ネットに多くの解説記事があるため詳細は割愛しますが、簡単にいうとトークンベースで文書とクエリの関連性を評価し、その結果に基づいて関連ドキュメントをランク付けします。BM25は、一般的な情報検索のタスクにおいて高い性能を発揮するだけでなく、ドメインに特化していない領域においてもそこまで精度が劣化しないという特徴があります。コスト面やメンテナンス性等においても実用性が高いため、実用を考えて深層学習(Deep Learning)を用いた手法ではなくBM25を採用するというケースもめずらしくないと思います。 -
Deep Retrieval
Deep Retrievalは、情報検索のタスクに深層学習を活用するアプローチの一つです。文書やクエリなどの情報をモデルでベクトル化してあげて、ベクトル間の距離をconsine similarity等で数値化することで検索が可能となります。一般的には、一つのモデルで全てベクトル化をしてしまうのですが、後述するasymmetricなケースに対応する場合はtwo-towerモデル等を用いるケースもあります。Deep Retrievalを検討する際には、前述のBM25の性能を上回るかどうかが重要な検討ポイントとなります。
RAGで解きたい問題
RAGの一般的な前置きが終わったところで、弊社の取り組みにおける実データについて紹介します。以下は弊社におけるドキュメントや質問文の例です。
ドキュメントの例
当社においては保険商品の規約等がハンドブックとしてPDFで作成されています。下はその一例ですが、テキストだけでなく図や表、注釈等もふんだんに使われておりどのようにLLMにドキュメントを与えるかは工夫の余地があることが分かるかと思います。

自動車保険の契約条件に関するドキュメント
以下は比較的シンプルな図表の例です。中には表が入れ子構造になっているものや、矢羽で表現されている図等がありテキスト化に非常に苦労しました。
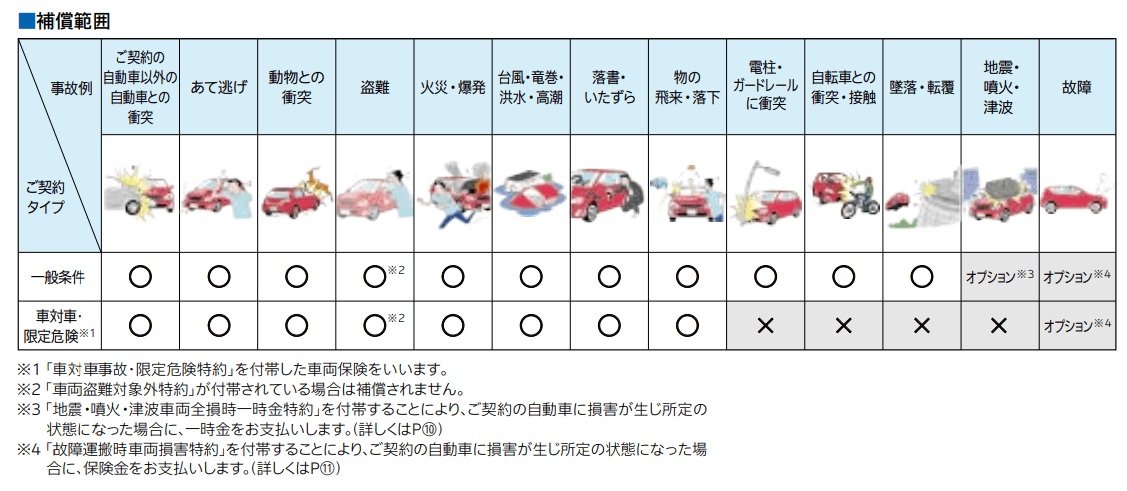
補償範囲に関する図表
質問/回答の例
以下は実際に投げられた質問と正解データの例です。「飛び石」、いわゆる走行中の飛来物による被害が補償可能かどうか?を聞いている質問文に対して、補償対象であるという回答を行っており正しく回答ができています。
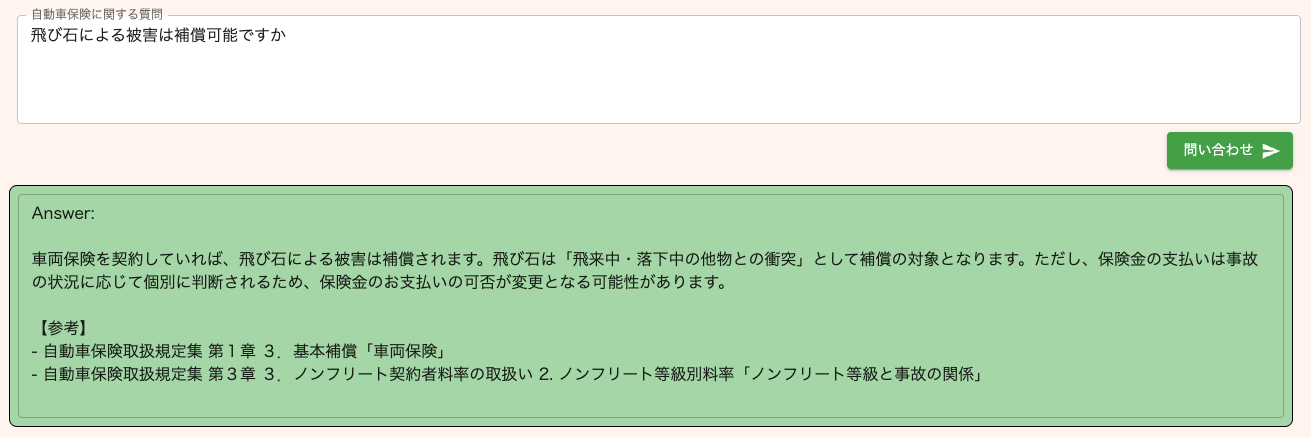
実際のアプリ画面
正しく回答を行うためには、
① この質問文が来た際に正しいドキュメント(上の補償範囲の図表)を取得できる。
② LLMが質問、およびドキュメントを正しく理解できる。
(上の例で言うとドキュメントにおける「物の飛来・落下」という項目が◯になっていることから補償の対象であると判断できる)
ことが必要となるわけですね。
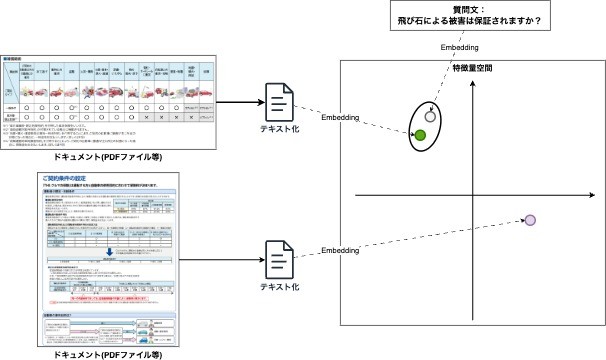
質問文と関連ドキュメントの特徴量(ベクトル)が近いと正しいドキュメントの取得が可能となる
検索精度向上
これまでに、RAGの基本的な仕組みやその応用について説明してきました。今度は、RAGの中でも特に重要なポイントである検索精度向上に焦点を当ててみたいと思います。
RAGを効果的に活用するためには、高い検索精度が不可欠です。なぜなら、検索部分における正確性が最終的な回答の品質に直結するからです。もし検索によって提供されるドキュメントが誤っている場合、正しい情報を生成することができないのは想像に難くないと思います。以下は、ドキュメントの検索精度が高ければ高いほど正答率が上がるという実験結果も示したものです。
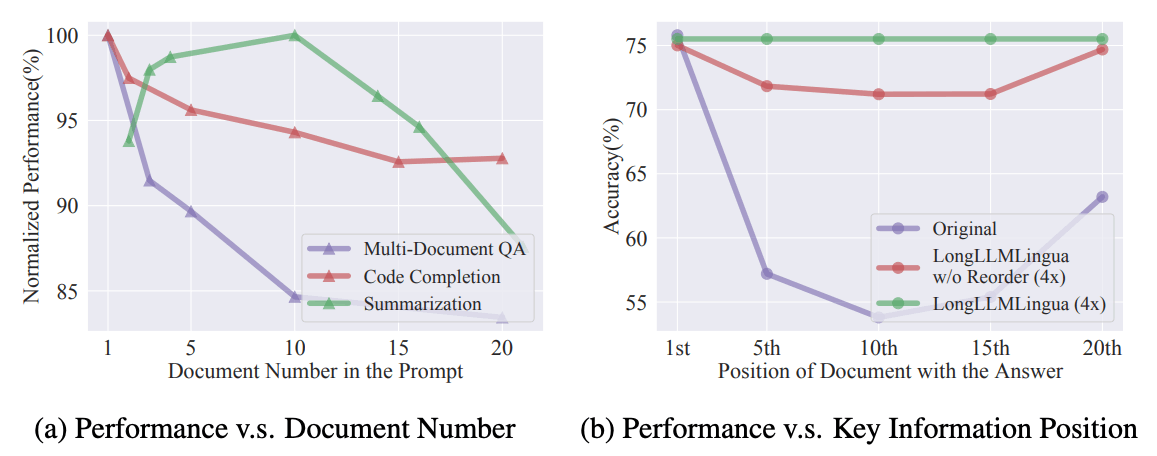
(a)Promptにおけるドキュメント数と(b)ドキュメントの順位による精度の変化[1]
また、現在の言語モデル(LLM)ではハルシネーション(誤った情報生成)の問題を完全に解決するのは難しいことも、検索部分の信頼性が必要な理由の一つと言えると思います。
ここからは、我々が検索精度向上のために試みた手法や、一般的に使用されている手法について詳しく説明します。
検索精度を向上させる手法としては大きく、
- ドキュメントに手を加える方法 と、
- 検索モデルに手を加える方法
があるので、その2点に関して解説したいと思います。
ドキュメントに手を加える
-
ドキュメント整形/chunking
PDFなどのドキュメントをそのままテキスト化すると、テキスト間に連続性が欠けたり、情報の欠落が発生することがあります。そのため、人手によるチェックとテキストの整形が不可欠です。また、ドキュメントをどの単位で区切るか(chunkingと呼ばれます)も検索精度に大きな影響を与えます。この調整に関しては現状自動的に最適な区切り方を見つけることが難しく、ドメイン知識(どういった質問がよく来るのか?どのドキュメントを参照すれば過不足なく答えられるのか?)を持った上での試行錯誤が必要となります。キーワードベースでの検索である程度のユースケースがカバーできるのであれば不要かもしれませんが、複雑な質問に対するsemantic searchを行うのであれば避けては通れないと思います。 -
要約生成
先ほどちらっと述べましたが情報検索におけるタスクは symmetric search / asymmetric search に分類することができます。大体のケースでドキュメントと質問文の形態が異なっていることをイメージしてもらえると分かりやすいと思います。ドキュメントは複数行に渡っていて中には図表を含んでいるものもありますが、質問文は1~2行の短文で済むことが殆どですよね。質問文→関連した質問文(FAQ等)の検索はsymmetric searchで、質問文→関連したドキュメントの検索はasymmetric searchと捉えられるわけですね。
モデルをどのように学習されたかにもよってしまうのですが、asymmetric searchの場合、ドキュメントと質問文のembeddingを直接比較するのではなく、ドキュメントのsummaryを一度生成しておいてから検索させることで精度向上できる可能性があります。 -
質問文の拡張
上と逆の考え方ですが、要約を生成する(ドキュメントを質問文に近づける)のではなく、質問文をドキュメントに近づけるという発想です。質問文から仮のドキュメントをLLMに生成させ、仮のドキュメントに近い本来のドキュメントを探すことで精度向上につながる可能性があります。実際に提案されている手法の例としてはHyDE(Hypothetical Document Embeddings)[2]と呼ばれているものがあります。ただし、検索のたびにLLMを動かす必要がある点がネックであり、今回は採用を見送りました。 -
Knowledge Graphの活用
Knowledge Graphを活用して検索の精度向上を図ることも選択肢の一つです。ドキュメントを何らかのKnowledge Graphにあらかじめ紐づけておき、グラフに対するQueryとsemantic searchを組み合わせるというものです。以下のブログの例では、まずグラフに対するQueryをかけることでドキュメントをフィルタリングし、その後ベクトル検索によりsemantic searchを行う例が書かれています。
ただしKnowledge Graphの作成のためには、そのデータモデルであるオントロジーの作成が必要になります。想像しただけでも骨の折れる作業ですね。オントロジーやKnowledge Graphの作成が自動化されかつ実用化に耐えるレベルになれば選択肢としてあり得ると思いますが、そこまでデータの整理ができていない場合は活用が難しいなという印象です。残念ながら採用は見送りました。
検索モデルに手を加える
-
検索モデルのfine-tune
もし学習用のデータが十分にある場合は、精度向上に一番寄与するアプローチとして検索モデルのfine-tuneが挙げられると思います。例えばSentence Transformers等の既存ライブラリを使えば、pre-trainedなモデルもたくさん使えますし、そのモデルのfine-tuneも非常に簡単に実施できます。我々のケースでは学習データが十分な量があったため、Sentence Transformersを使ってfine-tuneを実施することにしました。fine-tuneの具体的な手法については別記事で解説予定です。 -
Re-rankingモデルの活用
検索の問題に取り組まれてきた方であればRe-rankingモデルを使われたこともあるのではないでしょうか。Re-rankingモデルはその名の通り、ランキングを再度作成するモデルのことで、一般的にはSemantic Searchである程度関連度の高いドキュメントを絞り込んだ後に、その中で最も関連しているドキュメントを探す際に使われています。
Bi-Encoder形式のモデル(一般的なText Embeddingのモデル)よりは精度が高いことが多いのですが、推論の際に質問文とドキュメントのペアが必要となるので、1つの質問文を処理するのに全ドキュメント単位での探索が必要になります。ドキュメントが少ない場合は良いですが、1000以上にもなってくるとリアルタイムの処理で毎回全ドキュメント探索とはいかなくなります。対照的にBi-Encoder形式の場合はあらかじめドキュメントのembeddingは作成しておけるので、推論にかかる時間は質問文の一つのみで済むというわけです。
こういった推論時間のハードルがあるため、まずはBi-Encoderモデルである程度(~100)の数に絞り込んだ後、絞り込んだドキュメントから最も関連している文章をRe-rankingモデルで探す、という流れで使われることが一般的です。
また、Re-rankingモデルの蒸留(Knowledge Distillation)を行うことでBi-Encoderモデルの精度が向上するケースもあるようです。我々のケースではKnowledge Distillationによって精度向上が見られるかを検討しました。こちらの内容も実践編で解説予定です。
まとめ
今回はLLMの一般的な活用例であるRAGの構築において、検索精度向上にどのような手法があるのか、我々のケースでどう取り組んだのかについて紹介させていただきました。この辺りの領域は日々新しい手法やモデルが開発・報告されており、個人的にはDeep Learningが大々的に流行った2018年前後の雰囲気を思い出しています。それと同時に、どんなケースでも100%上手くいく所謂「銀の弾丸」はやはり存在しないので、いろいろな情報を取捨選択して自分たちに合った活用方法を考えるのが依然として大事なんだなあとも感じています。すごい効果的な手法が出た!と思ってよくよく検討してみると自分たちのケースには使えそうもなかった、みたいなのあるあるですよね。今回の検証を通してRAGの活用にある程度の実現性は見えてきているのですが、この後もさらなる精度向上やLLMOpsの構築、ガードレールの設定など課題はまだまだあるなという印象です。
最後に、損害保険ジャパン DX推進部ではエンジニア人材を募集しています。LLMの活用だけにとどまらず、業務アプリケーションの開発から新規技術のプロトタイプ実装などを内製開発チームで進めています。興味のある方はぜひご連絡ください。

Discussion