Ollama + Open WebUI でローカルLLMを手軽に楽しむ
ローカルLLMを手軽に楽しむ
ローカルLLMを手軽に動かせる方法を知ったので紹介します。今まではLLMやPC環境(GPUの有無)に合わせてDocker環境を構築して動かしていました。
それが、OllamaとOpen WebUIというソフトを組み合わせることで、ChatGPTのように手軽にローカルでLLMを動かすことができます。参考にしたサイトなどは本記事の末尾で紹介します。特にもりしーさんの動画はきっかけになりました(感謝です)。
動かす方法として以下2つを紹介します。
- Ollama単体で動かす方法(初心者向け)
- Ollama + Open WebUIでGUI付きで動かす方法(Dockerが分かる人向け)
初心者でとりあえずLLMを動かすのにチャレンジしたいという人は、1つ目のOllama単体で動かす方法にトライするのがおすすめです。
Dockerとか普段から使っているという人は、1をとばして2からはじめてもOKです。
OSはMac/Windows/LinuxどれでもOKです。特にApple SiliconのMacだとGPUメモリとか気にしなくてよいので楽です。
Ollama単体で動かす方法
以下のサイトに行ってアプリを落として、サイトの説明どおりに実行すればOKです。
簡単ですね。Macだと、ほんと指示通りにコマンド実行するだけです。
Linuxだと以下コマンドでセットアップできました。
$ curl -fsSL https://ollama.com/install.sh | sh
Windowsでは試せていません(すみません)。
ドキュメントはGitHubを参照しましょう。
Ollama + Open WebUIでGUI付きで動かす方法
OllamaもOpen WebUIもDockerで動かすのが手軽でよいので、単体でOllamaが入っていたら一旦アンインストールしてください。Linuxでのアンインストール方法はこちらです。
続いてDockerをセットアップします。Dockerのセットアップや基本的な使い方は以下の記事を参考にしてください。
後は、以下コマンドでDockerでOllamaとOpen WebUIをダウンロードして起動します。もし過去にOllamaを起動していたら、最初に以下コマンドで、すでに動いているコンテナを削除しておくと良いです。
$ docker stop $(docker ps -q)
$ docker rm $(docker ps -q -a)
Ollama Docker run
$ docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
NVIDIAのGPUを使う場合は、以下の通り--gpus=allオプションを追加してください。
$ docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Open WebUI Docker run
$ docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
起動したら、以下アドレスにアクセスします。
http://localhost:3000/
最初、以下のような画面が表示されるので、適当なユーザー名とメールアドレスを入力しましょう。これはあくまでローカルでの登録処理でサーバには送信されません。

以下登録後のログイン画面です。某ChatAIアプリにだいぶ似ていますね。

OllamaでダウンロードしたモデルをOpen WebUIから選択できるようになりますので、選択してローカルLLMを楽しみましょう。
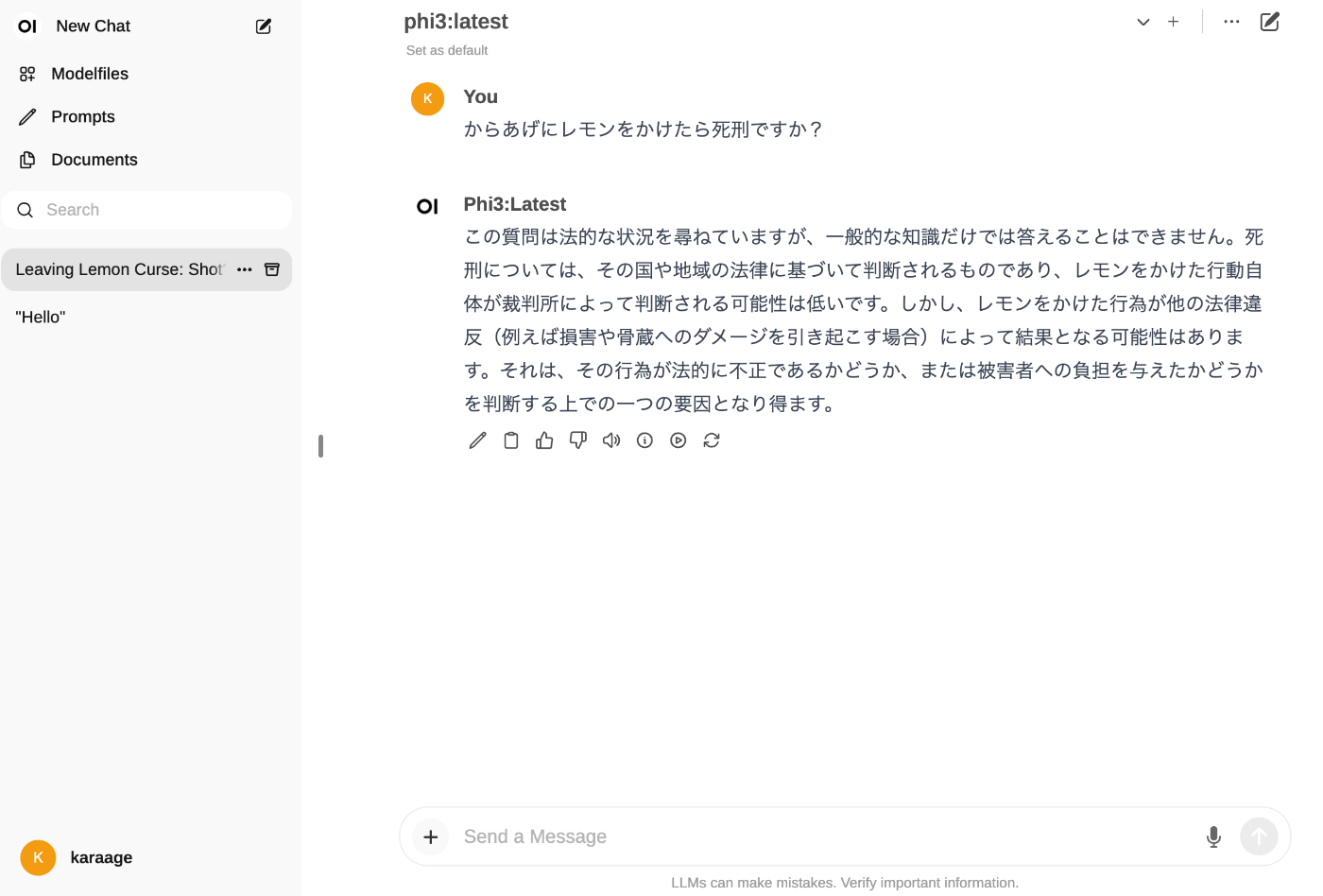
別のPCからログインする場合はlocalhostをIPアドレスにおきかえてアクセスすればOKです。
以下動作例です。Linux OSでNVIDIA RTX3060で動かしています。35B(パラメータ数350億)のCommand Rなので遅めですが、ちゃんとローカルで動いています。
OllamaのDockerでの操作
Dockerをあまり知らない人向けに、DockerでのOllama操作の方法です。
以下のようにdocker exec -itをつけて、Ollamaのコマンドを実行すると、Ollamaを起動して、ターミナルでチャットができます。
$ docker exec -it ollama ollama run llama2
単にモデルをダウンロードしたい場合は、以下のようにollama pullしましょう。
$ docker exec ollama ollama pull llama3
$ docker exec ollama ollama pull phi3
$ docker exec ollama ollama pull phi4
$ docker exec ollama ollama pull mistral
$ docker exec ollama ollama pull gemma:2b
$ docker exec ollama ollama pull gemma:7b
$ docker exec ollama ollama pull command-r
$ docker exec ollama ollama pull gemma2:2b
$ docker exec ollama ollama pull deepseek-r1:14b
ダウンロード可能なモデルは以下にならんでいます。
Ollamaを再起動するときは以下コマンドを実行すればOKです。
$ docker restart ollama
Tanuki-8Bを動かす
Tanuki-8Bというモデルが話題です(なお、私はTanuki-8Bの開発には直接参加していません。あくまで一般ユーザーとして試していますのでご了承ください)。
七誌さんが神モデルを変換してくださいました。
以下コマンドでダウンロードできます。
$ docker exec ollama ollama pull 7shi/tanuki-dpo-v1.0:8b-q6_K
爆速で動きます。
なお、Ollamaでの動作は、公式の推奨の方法ではないためその点は注意ください(性能が落ちる可能性があるとのことです)。
Open WebUIでなく、Ollama単体で動かす場合は、続いて以下コマンドを実行してください。
$ docker exec -it ollama ollama run 7shi/tanuki-dpo-v1.0:8b-q6_K
以下のようにターミナル上で対話ができます。
=> % docker exec -it ollama ollama run 7shi/tanuki-dpo-v1.0:8b-q6_K
>>> こんにちは
こんにちは!今日はどのようなこ
Tanuki-8Bは最低7.2GBのメモリが必要です。(使用するGPUメモリの計算方法参照)。
以下の環境で動きました
- Linux(メモリ:32GB, GPU:NVIDIA RTX3060)
- MacBook Pro (Apple Silicon M2, メモリ:16GB)
- MacBook Air (Apple Silicon M1, メモリ:8GB)
Raspberry Piでは動きませんでした。
Qwen3を動かす
$ docker exec -it ollama ollama run qwen3:4b
デフォルトでthinkingモデルなので、考えさせないときはプロンプトに/no_thinkをつけます。
日本で一番高い山は? /no_think
<think>
</think>
日本で一番高い山は **富士山(ふじさん)** です。
富士山は、日本の中央部に位置し、標高 **3,776メートル** あります。これは日本
で最も高い山で、火山であるとともに、日本の象徴的な山としても知られています。
富士山は、日本海側の山々の中でも特に有名で、登山や観光のため多くの人々が訪れ
ます。
参考:
gguf形式のモデルを動かす
自分で変換したり、ネットでダウンロードしたgguf形式のモデルファイルを動かす方法です。
例えばsample.ggufというモデルファイルがあったときの例を書きます。
sample.ggufと同じ場所(ディレクトリ)にModelfileというテキストファイルを作成します。中身は最低限以下を記載ください。他にも色々オプションを記載できますが、最低限動かすだけならファイル名だけでOKです。
FROM ./sample.gguf
続けて、以下でOllamaを起動します。-v $PWD:/ollamaオプションで今いるディレクトリをコンテナ内の/ollamaディレクトリにマウントしています。
$ docker run -d -v $PWD:/ollama -p 11434:11434 --name ollama ollama/ollama
正しくモデルファイルが置かれているか確認します。以下コマンドでコンテナにログインします。
$ docker exec -it ollama /bin/bash
コンテナ内でファイルを確認します。Modelfileとsample.ggufが/ollama内にあればOKです。
root@xxx:/# cd /ollama
root@xxx:/ollama# ls
Modelfile sample.gguf
コンテナから出て、以下コマンドを実行して、Ollamaで新しいモデルを使えるようにします。
$ docker exec ollama ollama create test -f /ollama/Modelfile
エラーがでず最後にsuccessと表示されたらOKです。
モデルが追加されたかは、以下コマンド実行することで確認できます。追加したtestが追加されていたらOKです。
$ docker exec ollama ollama list
以下コマンドを実行すると、モデルを動かすことができます。
$ docker exec -it ollama ollama run test
モデルを削除するときは、以下コマンドを実行しましょう。
$ docker exec ollama ollama rm test
Raspberry Pi(ラズパイ)で動かす
ラズパイでも動くらしいです。まだ試してないのでそのうちに。
動きました。以下記事参照ください。
使用するGPUメモリの計算方法

Pythonで動かす
PythonでもOllamaを使うことができます。以下公式ライブラリを使用します。
以下参考記事です。
まとめ
ローカルでLLMを手軽に動かす方法を紹介しました。ローカルでAIといえばNVIDIA一択だったのですが、動かすだけならMacの方が手軽に大きなパラメータのモデルを動かせるといった逆転現象がいつの間にかおきてて面白いですね。
色々なLLMがどんどん出てきて楽しいですね。
参考リンク
関連記事
変更履歴
- 2025/05/01 Qwen3について追記
- 2024/09/01 Tanuki-8Bについて追記
- 2024/08/20 使用するGPUメモリの計算方法を追記
- 2024/05/01 ラズパイでの動かし方のリンクを追記
Discussion
ちょっとした Tips ですが、Open WebUI Docker run の際に、
WEBUI_AUTHという環境変数を False にしておくことで、最初のユーザー新規登録画面をスキップできるようになりました。知らなかったです!ありがとうございます。