ollamaで LLM-jp-13B v2.0 を動かす
最近 ollama の名前をよく聞くようになったので、自分でも試してみることにしました。
結論として、とてもお手軽に CPU 環境でローカル LLM を動かすことができたので、今後は ollama も積極的に使っていきたいなと思います。
ollama とは?
ローカル LLM を動かすためのライブラリです。
LLM-jp-13B とは?
NII主催の団体 LLM-jp が開発している、日本語に特化したローカル LLM です。
日本では、まだ数の少ない、フルスクラッチで学習された日本語LLM[1]で、寛容な Apache-2.0 で提供されています。
ollama で LLM-jp-13B v2.0 を動かす
ではさっそく始めていきましょう。
準備: ollama をインストールする
以下のインストーラに従ってアプリケーションを入手できます。
アプリケーションの指示に従って、CLI 上でも ollama コマンドを使えるようにしておきます。
ステップ1: LLM-jp-13B v2.0 のモデルファイルをダウンロードする
ollama では、著名な英語 LLM (Llama 3 等)はモデルライブラリとして公式にサポートされています。
なので、そういったモデルを動かしたいだけであれば、ollama run llama3 とするだけでOKです。
一方で、LLM-jp-13B は残念ながらそこまで知名度が高いわけではないので、自分でなんとかする必要があります。ollama は GGUF と呼ばれる形式のファイルであれば受け付けるので、GGUF フォーマットのものを探すことになります。
日本では、mmnga さんという素晴らしい方が、著名な日本語LLMを全て GGUF フォーマットに変換してくれています。感謝🙏
LLM-jp-13B v2.0 についても、以下のリポジトリに GGUF フォーマットのファイル群がまとめられています。
このリポジトリには、異なるレベルの量子化が施されたファイルがいくつかアップロードされています。なので、お好みのものを選べばよいということになります。
量子化については私も全く知識がないので、ひとまず推奨とされる「Q4_K_M」というレベルの量子化が施されたモデルを選択します。
このページにある download ボタンを押すと、モデルファイル(8GB程度)のダウンロードが始まります。
ステップ2: Modelfile の作成
モデルファイルのダウンロードが終わったら、同じディレクトリに、Modelfile という名前で以下の中身のファイルを別に作成してください。
FROM ./llm-jp-13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0-Q4_K_M.gguf
PARAMETER temperature 0.7
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.05
PARAMETER stop "<EOD|LLM-jp>"
TEMPLATE """{{ if .System }}{{ .System }}{{ end }}{{ if .Prompt }}
### 指示:
{{ .Prompt }}{{ end }}
### 応答:
{{ .Response }}<EOD|LLM-jp>"""
SYSTEM """以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。"""
Modelfile の書き方は、ドキュメントを参考に行います。
TEMPLATE の部分だけ注意が必要で、モデルのtokenizerのchat_templateを凝視しながら、適切に設定してあげる必要があります。
ステップ3: いざ、LLM-jp-13B v2.0 を動かす!🤗
ここまでくれば、あとは Modelfile からモデルの情報を作成して...
ollama create llm-jp-13b-v2 -f ./Modelfile
動かすだけです!
ollama run llm-jp-13b-v2
参考までに、自分の環境 (Apple M2 Pro) での動作例を張っておきます(GIF変換の問題で遅く見えますが、実際にはもう少し速い速度で出力できました)。

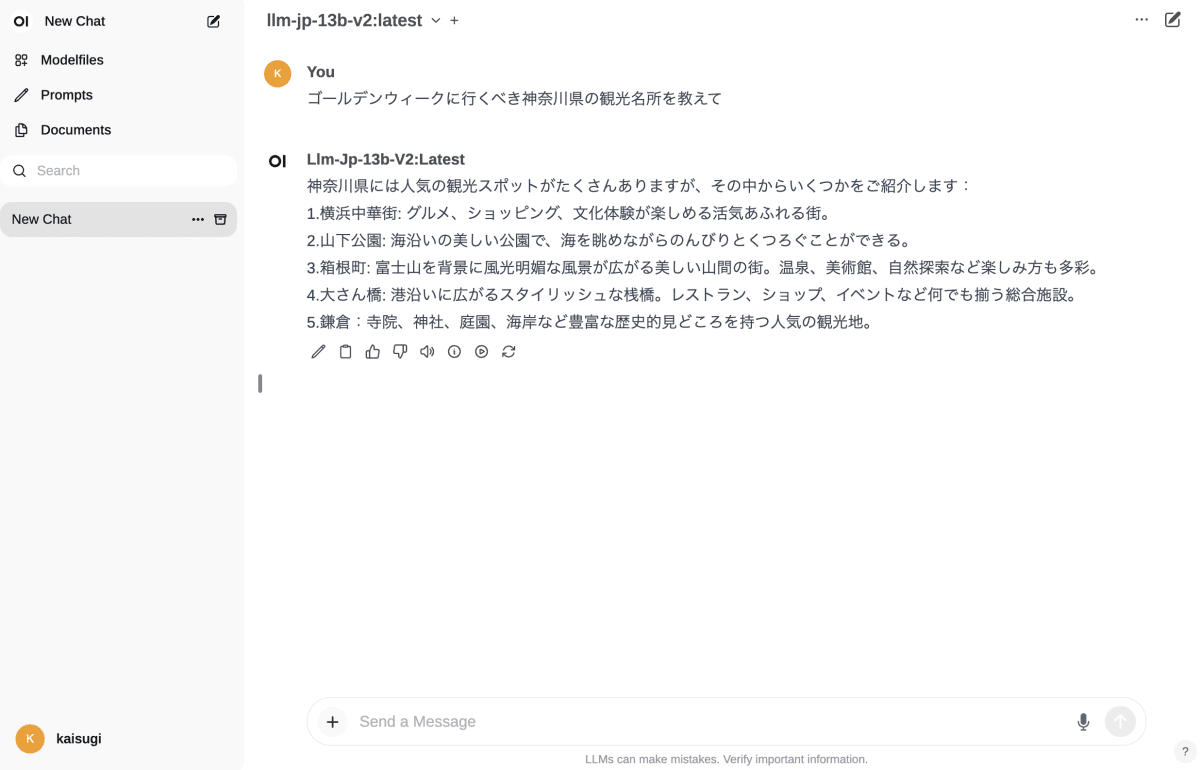
ステップ4: ブラウザ上でチャットを楽しむ
ollama と Open WebUI を組み合わせて、ブラウザ上でチャットを楽しむこともできます。
やり方は karaage さんの記事に書かれているとおりです。
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker run -d -p 3000:8080 --env WEBUI_AUTH=False --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
これで、http://localhost:3000 にアクセスすれば、さきほど ollama create で作成した llm-jp-13b-v2 をブラウザ上で動かせるようになります。
参考
その他のローカル LLM の Tips については、以下の記事に網羅的にまとめられています!
Discussion
どうすれば、
TEMPLATE をモデルのtokenizerのchat_templateを元に、適切に設定することができるのですか?
そこを「よしなに」と提示されても再現性がないのですが。
例えば、tokyotech-llm-Llama-3.1-Swallow-8B-Instruct-v0.3-ggufのは下記のとおりです。これをどのように書き下すのでしょうか?