ローカルでLLMの推論を実行するのにOllamaがかわいい
ローカルでLLMを動かそうとなったら transformers ライブラリ、llama.cpp、text generation webuiなどいくつかの選択肢があると思いますが、どれもめちゃくちゃハードルが高いというほどではないですが、動かすまでの手続が若干いかつい印象があります。
そんな中で Ollama というツールを試してみたところインターフェイスがシンプル、ついでにキャラクターのラマが可愛いのでご紹介していこうと思います。
ちなみにですが、日本語での言及はあまり見かけなかったですが、LangChain が出してるレポートでは OSS モデルを動かすのに使われているものとしては3番目に多く使われており、

出典: LangChain State of AI 2023
GitHub のスター数も現在約33700とかなり人気を集めていそうです。
Ollama で CLI から推論
では早速推論を実行してみましょう。
Ollama のサイトに行くと Download のボタンがデカデカとあるのでこちらをポチッと押してインストーラーをダウンロードしてインストールします。
これでもうほぼ準備はできたようなものです。次に使いたいモデルをロードします。
記事執筆時点では次のようなモデルたちが使えます。(後述しますが、こちらで対応されてないモデルを使うこともできます。)
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
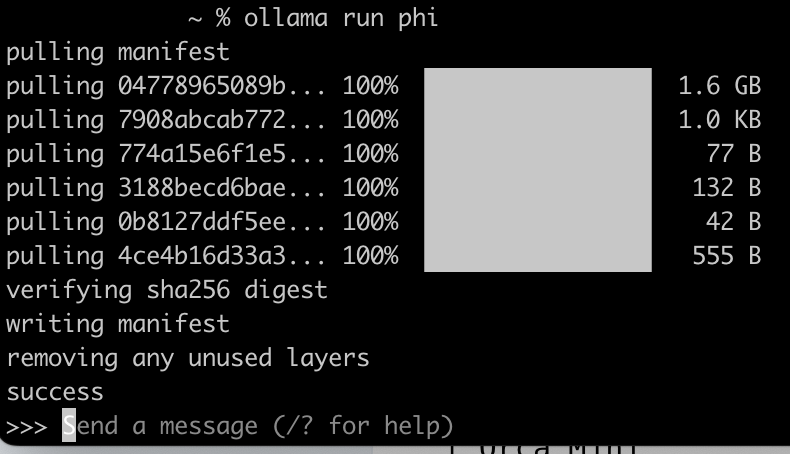
今回はなんとなく私が試してみたかった phi を使ってみます。Download の欄にあるコマンドをコピってターミナルで実行しましょう。
ollama run phi
実行するとモデルのダウンロードが始まり、終わったらプロンプトを送るインターフェイスになります。
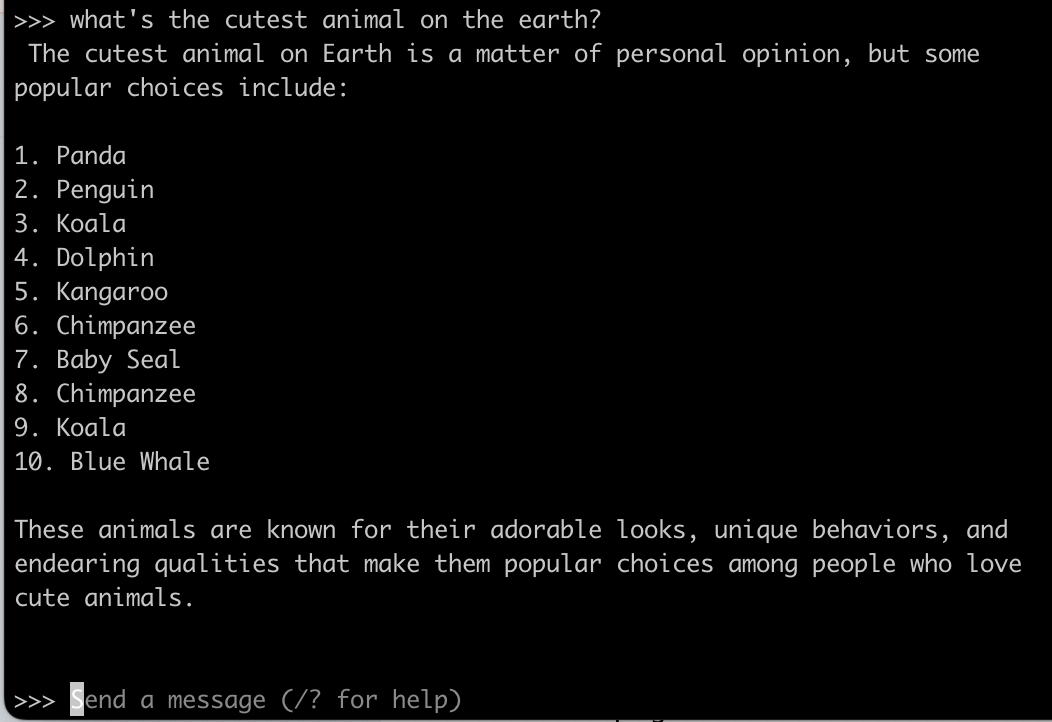
それではプロンプトを送ってみます。推論できました、楽ちん!!
登録されてないモデルを使う
Ollama 本体に登録されてるモデルしか使えないなら自分でガチャガチャしたり、最近出た日本語モデルを試すのに使えないなぁ、と思われたかもしれませんが Ollama ではそれらを試す選択肢もしっかり用意されてます。
とりあえず試したいモデルの gguf ファイルをダウンロードします。
例として、今回私は日本語モデルの Swallow のswallow-7b-instruct.Q5_0.ggufというファイルを下記からダウンロードしてみました。
上記ファイルと同じディレクトリに Modelfile という名前のファイルを作って、同ファイルへのパスを書きます。
FROM ./swallow-7b-instruct.Q5_0.gguf
次のコマンドを実行して Ollama にモデルをロードします。swallow7b-inst のところはお好きな名前に変えていただいて大丈夫です。
ollama create swallow7b-inst -f Modelfile
そして ollama run xxx と実行したらプロンプトを送れるようになります。シンプルですね。
ollama % ollama run swallow7b-inst
>>>
>>> 以下に、あるタスクを説明する指示があり、それに付随する入力が更なる文脈を提供しています。リクエストを適切に完了するための回答を記述してください。### 指示:\n\n以下のトピックに関する詳細な情報を提供してください。\n\n### 入力:国内のオススメのワーケーション先を10個くらい教えて\n\n### 応答:
> そうですね、北海道や沖縄など自然豊かでリフレッシュできる場所はいかがでしょうか。また、京都や軽井沢といった歴史的な建物がある観光地もオススメです。また、熊本城のように建築物を見ながら仕事するというスタイルも面白いと思いますよ。
プログラマブルに推論を行う
CLI以外にもLLMと戯れられる方法があります。
つい1週間前くらいに Python & JS のライブラリが公開されまして、こちらを活用することでプログラミングから推論を行うことができます。
まずはインストール
pip install ollama
実行はこんな感じです。シンプルですね。
ちなみにですが指定しているmodelは別途ロード(上記ollama run phiで行ったようなモデルのダウンロード)されている必要があります。
import ollama
response = ollama.chat(
model="phi",
messages=[
{
"role": "user",
"content": "Why is the sky blue?",
},
],
)
print(response["message"]["content"])
他にも stream で逐次トークンを受け取ったり他にも諸々生えてたりするので先ほど貼った記事からご参照してみてください。
Web UI から推論を行う
Ollama 公式のアプリではないのですが、Ollama は周辺ツールの開発が活発で ChatGPT みたいに Web の UI から推論を実行できるものもいくつかあります。
今回は一番 UI が ChatGPTみあってとっつきやすかったこちらを試してみます。
下記の Docker コマンドを実行します。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v ollama-webui:/app/backend/data --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main
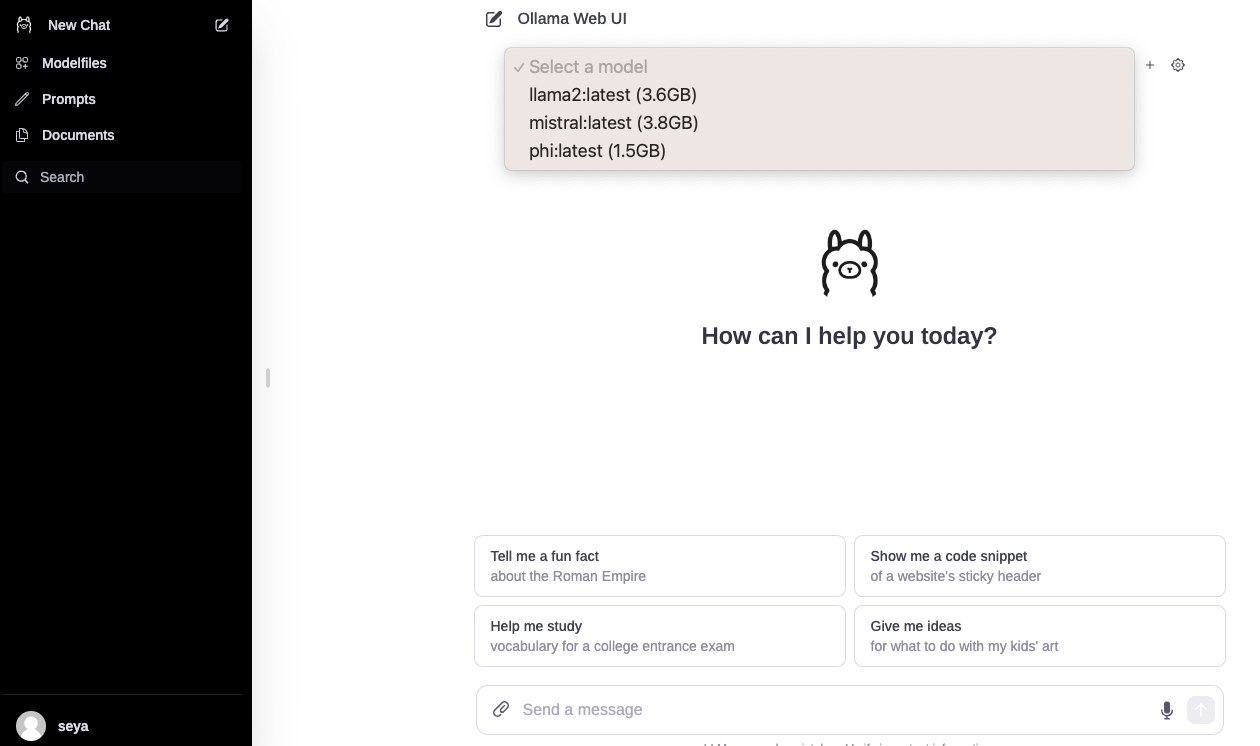
無事終わったら localhost:3000 を訪れると Ollama Web UI が立ち上がっています。どうやらアカウントを作る必要があるそうです。
サインアップしたらめちゃくちゃ ChatGPT みのある画面が出てきました。あとはロードしてるモデルの中から選んで Chat することができます。すごい!!
他にも色々出てたりするので下記記事たちを参考に試してみてください。
おわりに
以上、Ollama についてご紹介してきました。
正直他の手法との差分はインターフェイス以外はあまり比べられていないですが、かなりお手軽に LLM と戯れられれたのでシュッと試す分には大分いいツールなのではないかと思いました。
それでは、Ollama ぜひ試してみてください!👋
Discussion