はじめに
こんにちは、ナウキャストで LLM エンジニアをしている Ryotaro です。
サンフランシスコで開催された Snowflake Summit 2025 にナウキャストのメンバーで参加しました!
本日 Snowflake Summit 2025 の 3 日目は Platform Keynote で新しく発表された Snowflake Cortex AISQL についてまとめたいと思います!
関連記事
day 1 の記事はこちらです!
day 2 の記事はこちらです!
day 4 の記事はこちらです!
セッションの基本情報
Snowflake Cortex AISQL に関する what's new セッションに参加してきました!
-
What's New: Advanced Analytics with Cortex AISQL, Native Semantic Views, and More, WN213B
- リンク: https://reg.snowflake.com/flow/snowflake/summit25/agenda/page/main#:~:text=What's New%3A Advanced Analytics with Cortex AISQL%2C Native Semantic Views%2C and More%2C WN213B
- スピーカー:
- Josh Klahr(Director of Product Management, Snowflake)
- Renee Huang(Senior Product Manager, Snowflake)
- 概要
- Master AI-powered analytics in Snowflake. Learn how to leverage Snowflake's powerful AI SQL functions for advanced analytics on unstructured, time-series, and geospatial data. We'll also demonstrate how to use Semantic Views to bridge the gap between data and business understanding.
データ分析の変遷
これまでのデータ分析では構造化データや時系列データのような半構造化データが中心に分析が行われてきましたが、その枠がどんどん広がっていっており画像・PDF などの非構造化データの分析も需要が高まっています。
特に、SQL のパワーを活用しつつ、新しい AI 機能や技術を統合することで、アナリストがより効率的に、より多くの種類のデータからインサイトを引き出せるようになります。
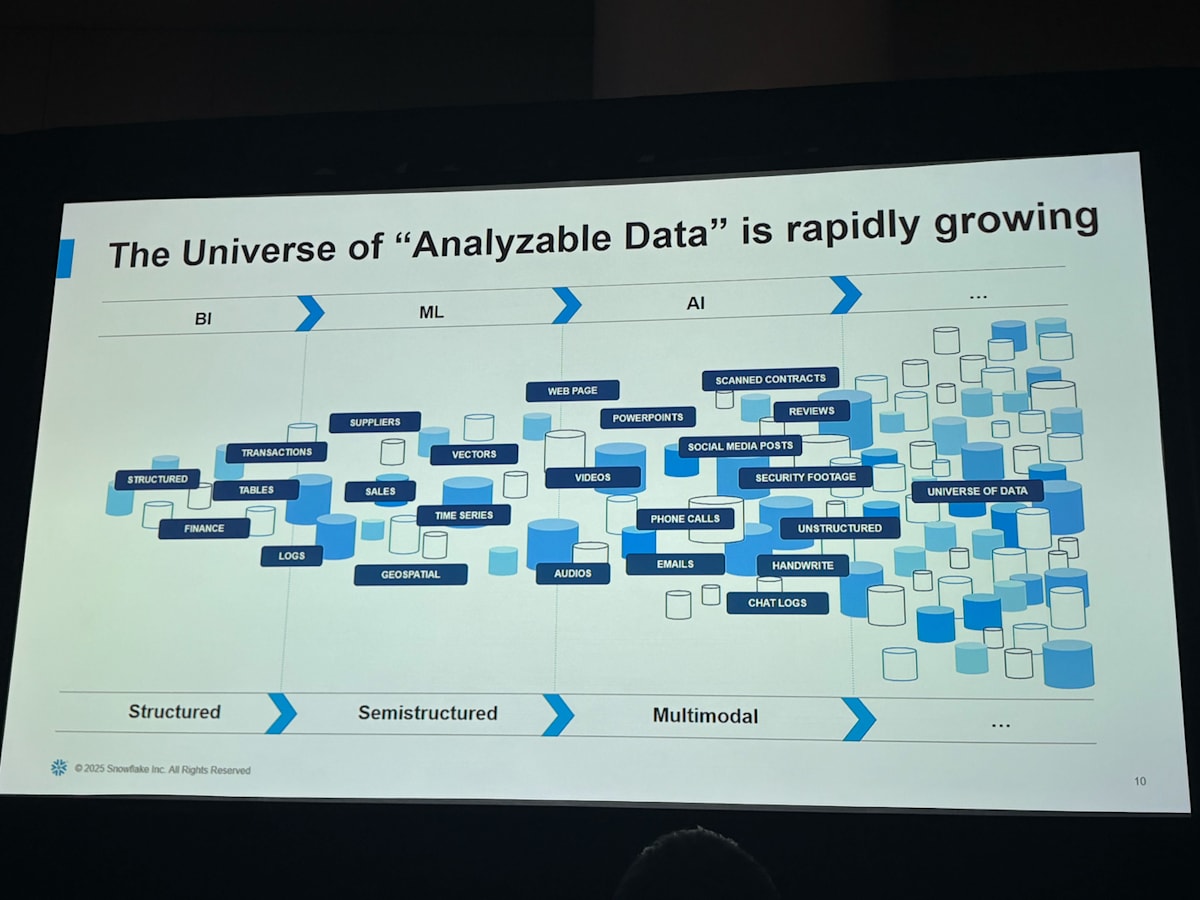
Snowflake Cortex AISQL
そこで Snowflake から Cortex AISQL という SQL の様式で構造化データと非構造化データの処理ができる機能が発表されました。
たとえばある review の文章が入っているカラムに対して、箇条書きでまとめた文章を生成するということが AISQL 関数を使って簡単にできます。
SELECT AI_COMPLETE(
'openai-gpt4.1',
CONCAT('Critique this review in bullet points: <review>', content, '</review>')
) FROM reviews LIMIT 10;
通常こういった AI による処理は AI の呼び出しができる実行環境に DB の情報を持っていき、処理をかけたあとに再度 DB に登録し直すという手順が必要になります。AI を呼び出すのも API を利用するうえで接続情報などを読み込むなど準備が必要なので手間なのですが、Snowflake Cortext AISQL の場合そういった手順を一切なしに、通常の SQL の関数と同じ感覚で使えるので非常に使いやすいです。
AISQL 関数としては以下の 9 種類が現在 preview となっています。
| 関数 | 説明 (要約) | Text | MultiModal |
|---|---|---|---|
AI_COMPLETE |
指定入力(プロンプトや画像)に対して LLM で生成補完を行う汎用エンジン | Public Preview | Public Preview |
AI_FILTER |
入力が条件を満たすかを True / False で返し、WHERE 句などに利用 |
Public Preview | Public Preview |
AI_FILTER Performance Optimization |
AI_FILTER の高速化オプション(スループット重視) |
Private Preview | ― |
AI_AGG |
テキスト列を集約し、プロンプトに沿った洞察を返す | Public Preview | ― |
AI_SUMMARIZE_AGG |
テキスト列を集約して要約を生成 | Public Preview | Public Preview |
AI_CLASSIFY |
入力をユーザー定義カテゴリに分類 | Public Preview | Public Preview |
AI_SIMILARITY |
2 つの入力の埋め込み類似度を計算 | Public Preview | Public Preview Coming Soon |
AI_EMBED |
入力のベクトル埋め込みを生成 | Public Preview Coming Soon | Public Preview Coming Soon |
AI_TRANSCRIBE |
音声/動画の音声を文字起こし | ― | Public Preview |
AI_EXTRACT |
ドキュメントや非構造データから必要情報を抽出 | Private Preview | Private Preview |
それぞれの使い分けはこのようになっています。
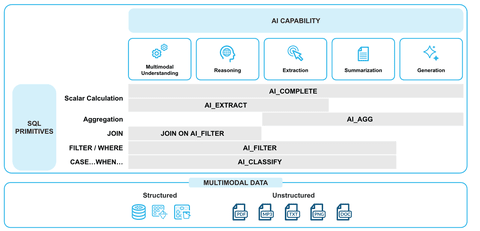
なかでも今回の what's new で強調されていたいくつかの関数をピックアップして説明します。
AI_FILTER
AI_FILTER 関数は where 句で使用でき、prompt で条件を書くことで実行できます。例ではある画像が指定した画像に似ているかどうかという条件を書いています。
WITH filtered_ads AS (
SELECT
id,
img
FROM ad_images
WHERE AI_FILTER(
PROMPT('{ad_images} look like {0}', <sample_ad_image>)
)
)
条件としてかなり直感的ながらも、いままででは実行し得なかった「〜みたいな感じ」を条件にできるようになっていることに驚きを隠せません!

ここで AI_FILTER の引数として指定できる
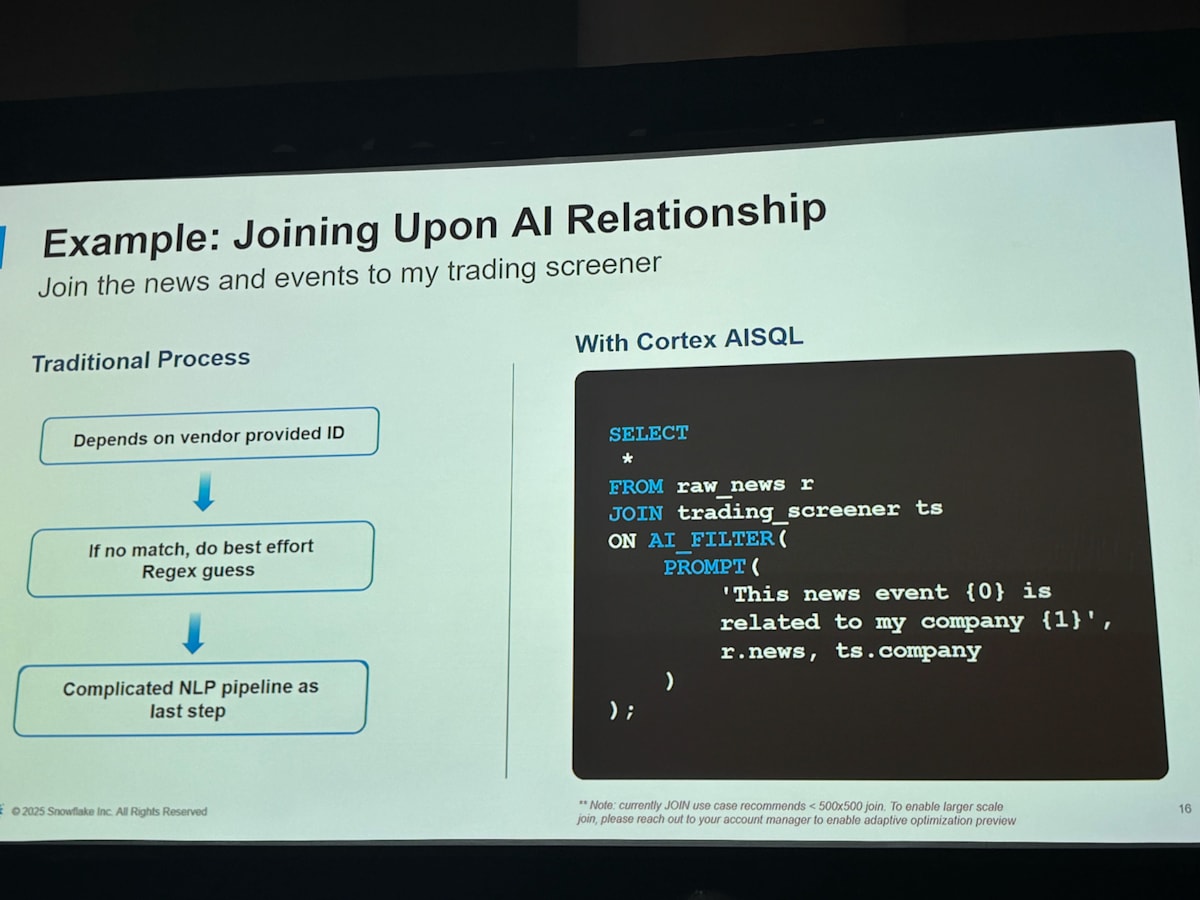
Join on AI_FILTER
さらに AI_FILTER は join 句の on 条件に使うこともできます。
この例では、ニュース記事を格納しているテーブルと、銘柄リストのテーブルを join する際に条件として「ニュースの記事本文が会社名と関連している」を指定しています。通常であればニュース記事の中に会社名が入っていたり、メタデータとして関連する情報が入っていないと付き合わせることはできません。それをたった数行のクエリで実現できてしまいます。
SELECT *
FROM raw_news r
JOIN trading_screener ts
ON AI_FILTER(
PROMPT(
'This news event {0} is related to my company {1}',
r.news, -- {0}: 記事本文
ts.company -- {1}: 会社名
)
)
AI_AGG
AI_AGG 関数は group テーブルに対して、AI による要約や、評価を行うことができる関数です。今まででは平均や合計などの定量的な集計しかできなかったところが、定性的にも集計できるようになったということを意味しています。 人間にとっては当たり前の行為ですが、これが DB に対して直感的に指示できるというのはすごいですね。
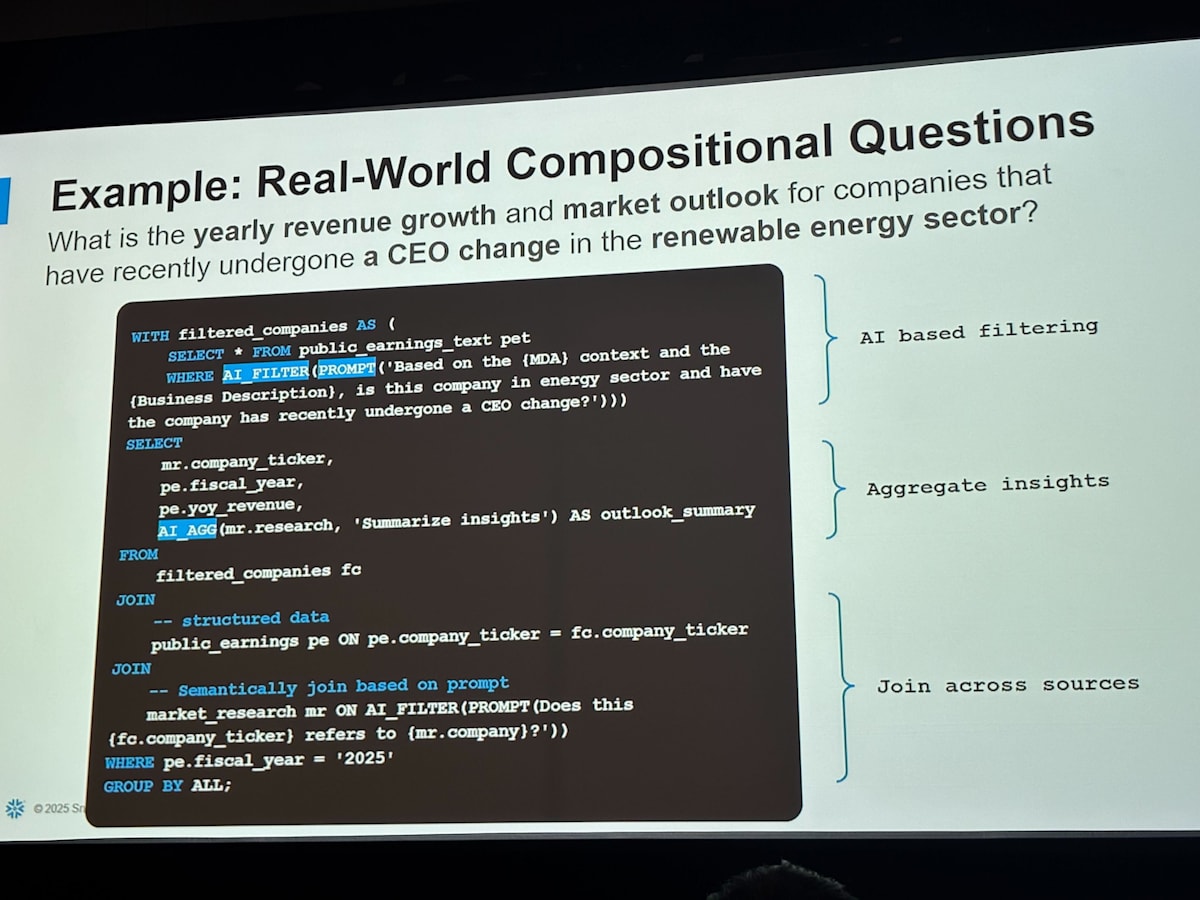
AI_AGG 関数の公式ドキュメントでは最適な回答を得るための tips をいくつか紹介されています。
- タスクの説明には平易な英語のテキストを使用します。
- タスクの説明に記載されているテキストを詳しく説明します。例えば、「要約する」というタスクの説明ではなく、「電話の通話記録を要約する」という説明を使用します。
- 想定されるユースケースを説明してください。例えば、「最高のレビューを見つける」ではなく、「レストランのウェブサイトで強調表示する、最も肯定的でよく書かれたレストランレビューを見つける」などと表現してください。
- タスクの説明を複数のステップに分割することを検討してください。例えば、「新しい記事を要約する」ではなく、「様々な出版社から、様々な視点から出来事を紹介するニュース記事が提供されます。重要な情報を見逃さず、簡潔かつ詳細に原文を要約してください。」と記述しましょう。
参考:https://docs.snowflake.com/en/sql-reference/functions/ai_agg#usage-notes
その他追加予定の SQL 関数
さらに追加される予定の SQL 関数がちらっと紹介されました。具体的なことは言っていなかったので確定ではないですが、次に実装されると思われます。
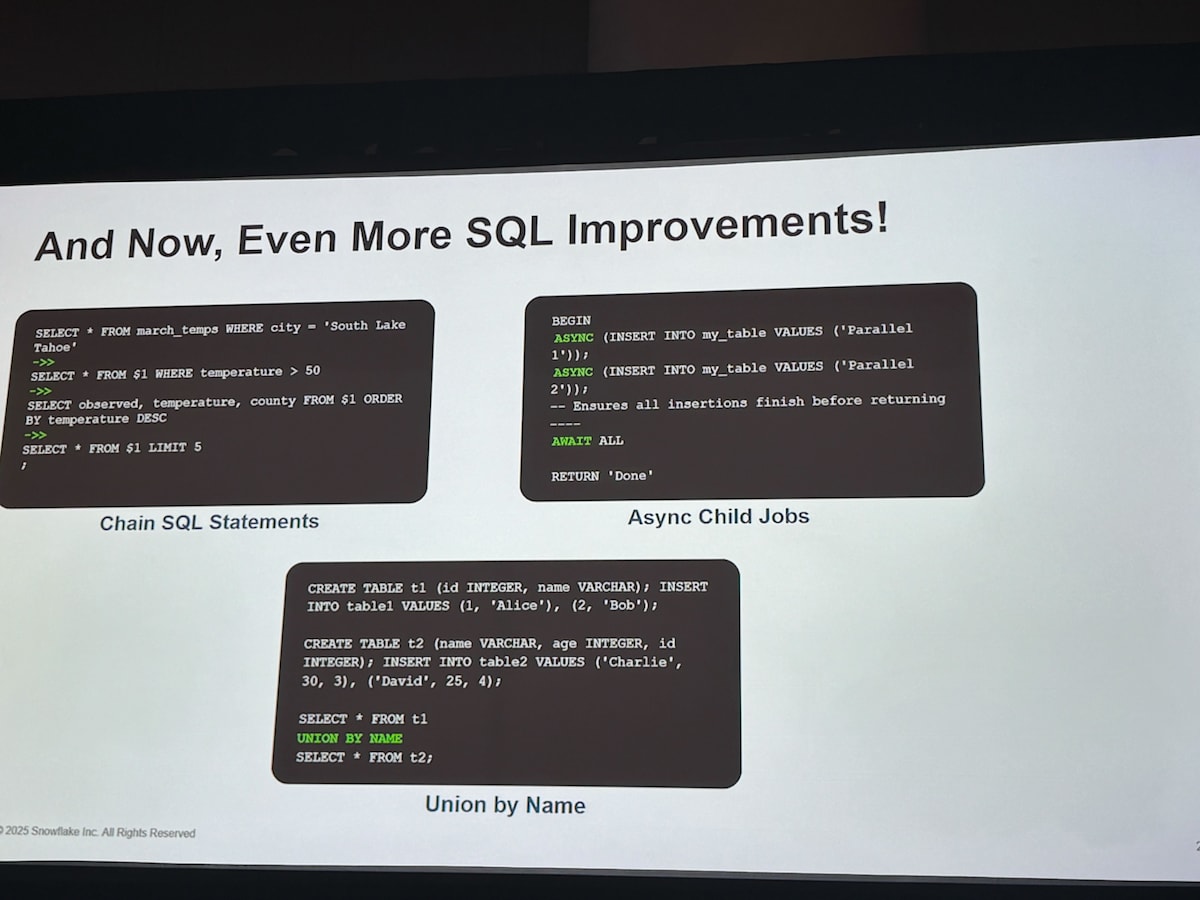
Chain SQL Statement
逐次処理を、一時テーブルなしでサクッと書くための機能のようです。分析作業をするとき毎回同じ sql を書いていると面倒なのでこの機能が実装されると嬉しいですね。
-- 3 月の気温データを多段フィルタ+並べ替えして
-- 最終的に上位 5 行を取得するパイプライン
SELECT * FROM march_temps WHERE city = 'South Lake Tahoe'
->>
SELECT * FROM $1 WHERE temperature > 50
->>
SELECT observed, temperature, county FROM $1 ORDER BY temperature DESC
->>
SELECT * FROM $1 LIMIT 5;
Async Child Jobs
AISQL のような時間のかかる処理を非同期で実行するための機能のようです。python の async と同じようなものですね。
BEGIN
-- 並列に 2 件 INSERT
ASYNC (INSERT INTO my_table VALUES ('Parallel 1'));
ASYNC (INSERT INTO my_table VALUES ('Parallel 2'));
-- すべて終わるまでブロック
AWAIT ALL;
RETURN 'Done';
Union by Name
Union by Name は、列順・追加列が異なるテーブルを union するための機能のようです。カラムの順番などを意識しなくても union できるようになりそうです。
-- テーブル A
CREATE TABLE t1 (id INTEGER, name VARCHAR);
INSERT INTO t1 VALUES
(1, 'Alice'), (2, 'Bob');
-- テーブル B:列順・追加列が異なる
CREATE TABLE t2 (name VARCHAR, age INTEGER, id INTEGER);
INSERT INTO t2 VALUES
('Charlie', 30, 3), ('David', 25, 4);
-- name/id をマッピング、欠損列(age)は NULL 補完
SELECT * FROM t1
UNION BY NAME
SELECT * FROM t2;
Adaptive LLM Optimization(Private Preview)
いくつか AISQL をご紹介していますが、これらのクエリはそのまま実装しているとコストも latency もよくないということが通常よく起きます。そこでこのクエリパフォーマンスを支える技術が Adaptive LLM Optimizationです。
Cortex AISQL を利用するとき裏側ではまず安価な LLM が呼び出され、その結果を評価し、あっていそうなら出力、不十分であればより高価な LLM を利用して再度出力を行うという処理が組み込まれています。これによりコストを出来る限り抑えながら、高性能な出力が生成されるようになります。
実際に利用されているモデルは Snowflake 側で用意されたベンチマークに基づいて最適な LLM が選択される仕組みになっており、ユーザーはどの LLM を利用すべきか意識しなくても利用できるようになっています。逆にブラックボックス化しているので LLM エンジニアとしては option で選択できれば嬉しいなと思うところです。

気になった点
モデルは何が利用できるのか?
現状 AISQL 関数に内 AI_COMPLETE で利用できるモデルは、
- snowflake-arctic
- OpenAI
- Anthropic
- DeepSeek
- Llama
- Mistral
などがあります。会場の参加者からの質問で Gemini が利用できるのはいつか?という質問がありましたが、回答としては Gemini はまだ利用できないが Google との提携は前向きに検討しているとのことでした。
それ以外の AI_FILTER や AI_CLASSIFY などの関数ではモデルの指定はできません。Snowflake は用途ごとに最適なモデル群を選定しており、大きさ(能力)によって Large / Medium / Small モデルに分類しているなかから Adaptive LLM Optimization によって最適なモデルを選択されるようです。
コストはどの単位でいくらかかるのか?
Cortex AISQL の AI 関数は処理したトークン数に応じてクレジット課金されます。トークンとはモデルが処理する最小単位のテキストで、約 4 文字に相当します。入力テキストおよび生成された出力テキストの双方のトークンが課金対象(AI_COMPLETE や AI_SUMMARIZE など生成系関数)であり、True/False やカテゴリを返す関数(AI_FILTER や AI_CLASSIFY など)は入力トークンのみがカウントされるようになっています。
Snowflake の公式レートによれば、例えば AI_FILTER や AI_CLASSIFY は 100 万トークンあたり約 1.39 クレジット、AI_AGG(生成的集約)は約 1.60 クレジットといった具合で、関数ごとに単価が定められています。一方、汎用的なテキスト生成関数である AI_COMPLETE では使用するモデルによって料金が異なり、モデルごとのレートが詳細に定められています。
例えば:
- 小型で高速なモデル(例: Llama4-Scout)は 0.14 クレジット/100 万トークンと非常に低コスト
- Meta のオープンソース系モデル (Llama3.1-70B など) では 約 1.2 クレジット/100 万トークン
- OpenAI GPT-4.1 でも 1.40 クレジット/100 万トークンと比較的割安に提供されています
- Anthropic Claude の大規模版 (Claude 4 Opus) など一部の最高性能モデルでは 12 クレジット/100 万トークンと高めです
より詳細な料金は以下のページで確認できます。
まとめ
AISQL を駆使することで、SQL のパワーを活用しつつ、新しい AI 機能や技術を統合することで、アナリストがより効率的に、より多くの種類のデータからインサイトを引き出せるようになります。所感としては 定量 のみではなく 定性 の分析もできるようになったということかなと思います。今までどうしても感覚的な分析・集計ができなかったところが AI の力で解決できるようになり、より分析の幅が広がりましたね。
以上 3 日目の AI/ML 系参加レポートでした!ナウキャストメンバーの他の記事もたくさん出ているのでぜひ見てみてください!

Discussion