はじめに
こんにちは、ナウキャストで LLM エンジニアをしている Ryotaro です。
サンフランシスコで開催された Snowflake Summit 2025 にナウキャストのメンバーで参加しました!
本日 Snowflake Summit 2025 の 4 日目は What's New: Snowflake AI Research で話された Snowflake AI の研究内容についてまとめたいと思います!
関連記事
day 1 の記事はこちらです!
day 2 の記事はこちらです!
day 3 の記事はこちらです!
セッションの基本情報
Snowflake AI Research に関する what's new セッションに参加してきました!
-
What’s New: Snowflake AI Research, AI321
- リンク: https://reg.summit.snowflake.com/flow/snowflake/summit25/sessions/page/catalog/session/1747761855272001IIC2
- スピーカー:
- Yuxiong He (Distinguished Scientist, AI Research, Snowflake)
- Samyam Rajbhandari (AI Systems Lead | Principal Engineer, Snowflake)
- 概要
- Discover the latest innovations from Snowflake AI Research across foundation models, agentic technologies and inference systems. Learn how Arctic Text2SQL reasoning models set a new standard in accuracy with best-in-class benchmark performance. See how we’re building intelligent enterprise agents that reason over structured and unstructured data, orchestrate tools and operate with trust. Finally, get a first look at our novel inference and training optimizations and next-generation open-source engine — designed to achieve the elusive trifecta: optimal latency, throughput and cost. Together, these advances enable capable, adaptive and efficient AI systems and applications for enterprise use.
TL;DR
- Arctic Text2SQL-R1 が BIRD ベンチマーク総合 1 位を獲得し、自然言語 →SQL 変換の精度で頭ひとつ抜ける。
- ReFoRCE エージェント により、数千テーブル規模でもスキーマ探索+自己修正を自律実行し、巨大・未整備 DB でも高い回答率を実現。
- Shift Parallelism を核とした Arctic Inference が推論初動を 3.4× 高速化、同時にスループットも向上し “速さとコスト” を両立。
Snowflake AI の Mission と Values
Snowflake AI Research のミッションは、最先端かつ実際のエンタープライズにとってインパクトのある基礎研究および応用研究を行うことであり、そしてエンタープライズ AI におけるコアバリューとして、以下を重視しています。
-
Accuracy(精度): 現実世界の難しい問題を正確に解決する能力 -
Accessibility(アクセシビリティ): さまざまなシステムで容易に適用、使用、統合できること -
Efficient(効率性): スケーラブルで費用対効果の高いインフラストラクチャを構築すること -
Trust(信頼性): 進捗と出力を観測可能で検証可能にすること -
Open(オープン): モデル・論文・ツールを OSS として公開し、AI コミュニティ全体の発展に寄与すること
ここで Open といっているように、Snowflake はモデルや論文、ツールを OSS として公開しています。
そして Snowflake がエンタープライズで AI を機能させるために、密接に関連する 3 つの領域にフォーカスして研究を行っています。
-
Foundation Models(エンタープライズ特化型基盤モデル): 埋め込み、SQL 生成、文書理解のためのモデルを開発。精度だけでなく、コストやレイテンシといったエンタープライズの制約に合わせて最適化されています。 -
Agentic Technologies(エージェント技術): 基盤モデルの上に構築され、エンタープライズのワークフローで計画、推論、実行できるエージェント。これは、Snowflake Intelligence、Contact Analyst、Contact Search といった主要 AI アプリケーションを強化しています。 -
Inference & Training Systems Optimization(推論とトレーニングシステム): モデルやエージェントを高速かつ手頃な価格にするためのインフラストラクチャ最適化。推論とトレーニングの最適化を通じて、現実世界の SLA 要件を満たします。
それぞれ詳しく解説していきます。
Snowflake Foundation Models
Snowflake の基盤モデルは、主要な 3 つのモデルファミリーがあり、汎用目的の基盤モデルではなく、重要なエンタープライズシナリオに特化したモデルを構築しています。
-
Arctic Embedded: Embedding for Retrieval -
Arctic TILT Extract: Document Intelligence -
Arctic Text2SQL: Structured Reasoning for Enterprise Analytics
今回のセッションでは Text2SQL のモデルについて詳しく解説されました。
Text2SQL とは?
Text2SQL とは、ユーザーが SQL を一切書かずに複雑なデータベースを自在にクエリできるようにする自然言語 → SQL 変換モデルです。
Snowflake では Snowflake Copilot や Cortex Analyst で使用されている DB に対して LLM がアクセスする重要な機能です。
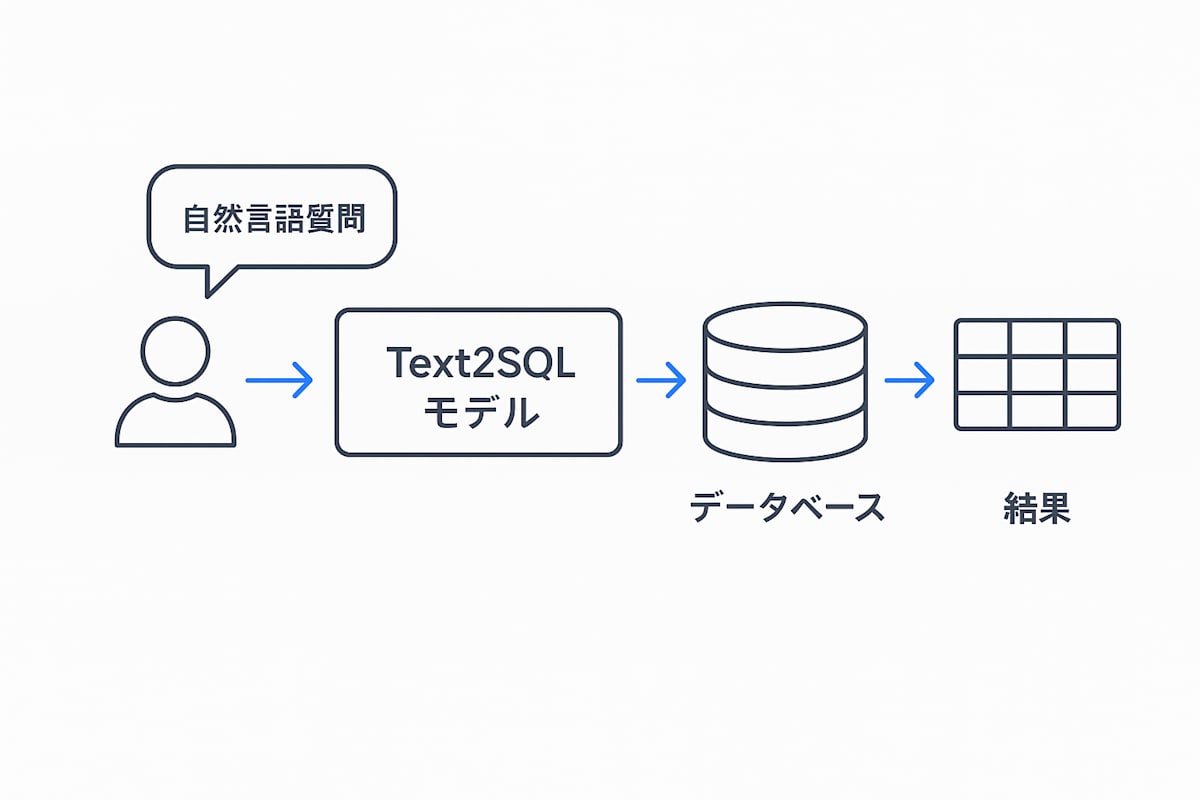
たとえば「2024 年 Q1 の売上トップ 3 社は?」という質問に対して、
SELECT company_name,
SUM(revenue) AS total_rev
FROM sales
WHERE fiscal_quarter = '2024-Q1'
GROUP BY company_name
ORDER BY total_rev DESC
LIMIT 3;
という SQL が生成され、実際にデータベースに実行すると、以下のような結果が得られます。
| 会社 | 売上高 |
|---|---|
| Acme | 120M USD |
| BizCorp | 110M USD |
| DataWorks | 105M USD |
このように、自然言語 → SQL → 実際の集計結果 までをワンストップで橋渡しするのが Text2SQL の流れです。
Text2SQL の学習が「想像以上に複雑で難しい」理由
自然言語インターフェースのおかげで、「データと対話する」ことがかつてないほど容易になりましたが、質問を実用的な SQL に変換するのは依然として驚くほど難しい問題です。SQL の強みはその構造と精度にありますが、その融通の利かなさが多くのユーザーにとって扱いにくいものとなっています。大規模言語モデル(LLM)は有望な橋渡しとなるものの、複数テーブルの結合、ネストされたロジック、曖昧な意図、複雑なスキーマなどが原因となり、現実世界の複雑な要求には対応できないことがよくあります。
| 課題 | 具体例・背景 | なぜ難易度が跳ね上がるのか |
|---|---|---|
|
複数テーブル結合 (Multi-table joins) |
* 顧客・注文・配送など 5 枚以上のテーブルを結合して LEFT / INNER / SELF JOIN を組み合わせるケース。 * 外部キーがスキーマに宣言されておらず、ER 図も古いといった「現場あるある」。 |
* エンティティ間のリレーションを 推論 しなければならない。 * JOIN 順序や結合条件を間違えると結果が大きくズレるため、モデルには論理的計画(query plan)の構築力が必須。 |
|
ネストされたロジック (Nested logic) |
* 「上位 10 % の売上を超える製品の、直近 6 か月での月次平均利益率」など、サブクエリの中でさらに集計を行うパターン。 | * SQL 文を 段階的に設計(外側 → 内側 or 内側 → 外側)する“思考の分割”が必要。 * LLM が一発生成すると、途中の CTE/Subquery が欠けたり型ズレしたりしやすい。 |
|
あいまい/不完全な入力 (Ambiguous input) |
* 「売上が高い顧客を教えて」“高い”とは?期間は?通貨は? * 社内略称(“FY23Q4” や “RevH”)が混在。 |
* モデルは 補足質問(clarification) を出さないと確定情報が不足。 * 質問せずに SQL を出力すると、実行は通っても意味のない集計になる危険が高い。 |
|
スキーマの乱雑さ (Messy schemas) |
* sales_fact, salesdetail, sales_fact_2020 のように一貫性のない命名。* コメント/ドキュメントがほぼ空欄。 |
* 列名だけでは意味が推測しづらく、列・テーブル探索の負荷が増大。 * 正しいテーブルを使っても、列の型や NULL 可否の違いで実行エラーが発生しやすい。 |
課題に共通する難しさの理由をまとめると、2 点に分けることができます。
-
流暢さ ≠ 実行可能性
LLM は自然言語の連続性を最優先で学習しているため、SQL を “らしく” 生成するが、SELECT ... WHERE DATE(order_date) >= '2023-01-01'のように一見正しく見えて インデックスが効かず激重、あるいは JOIN 条件を落として重複行を量産 といった“Broken SQL”を作りがちです。
-
教師ありファインチューニングの限界
多くの Text-to-SQL データセットは「正解 SQL」をペアで与えるだけです。形が合っていれば OK という学習になり、実行結果が正しいか を評価せず、未知スキーマやネストが深い問合せに弱く、“部分的に正しいが答えは間違い” というフラジャイルさが残ります。
Arctic R1 学習フレームワーク -- 「Simple Reward」×「Smarter Data」×「Systematic Training Exploration」で「動く SQL」を鍛え上げる
そこで Snowflake は Arctic Text2SQL-R1 という独自の Reinforcement Learning フレームワークを開発しました。
このフレームワークは、以下の 3 つの要素を組み合わせています。
- Execution-aligned Reward
- Smarter data, less noise
- Systematic Training Strategy Exploration
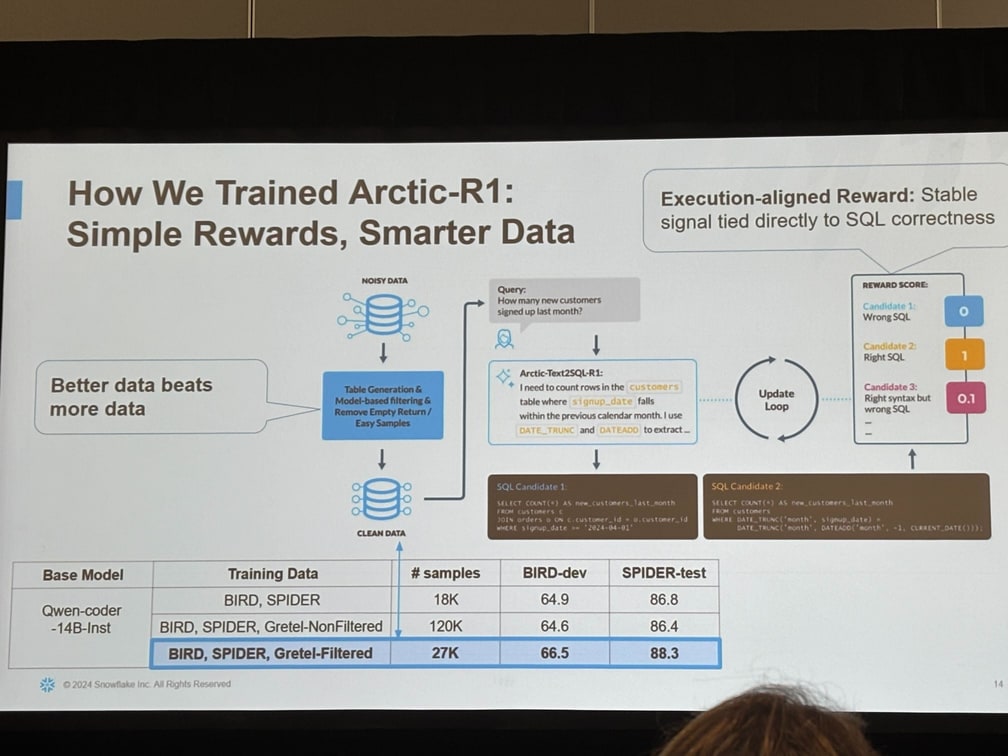
1. Execution-aligned Reward
まず注目したいのは 報酬設計 です。
多くの生成モデルは「正解 SQL との文字列類似度」を学習指標としますが、Arctic R1 ではこれを思い切って捨てました。
代わりに、シンプルで軽量な報酬設計を採用している点が大きな特徴です。具体的には
- 1: 実行結果が正解と完全に一致する場合。
- 0.1: 構文が正しく、SQL が実行可能であるが、実行結果は正解と一致しない場合。
- 0: 上記以外(構文エラーや実行不可能な場合など)。
といった実際に実行して結果を見て報酬を与えています。これによりモデルは「構文がきれいかどうか」ではなく「実運用のデータベースで動いて正しいか」だけを最適化します。一見スパースな信号ですが、実行という客観的基準に基づくため 安定して収束しやすい という利点があります。複雑な報酬関数による「報酬ハッキング」のリスクを回避しているともいえます。
2. Smarter data, less noise
Arctic R1 チームは Spider 2.0 などの大規模コーパスをそのまま投入するのではなく、難易度が高く情報量の多いクエリ に絞ってフィルタリングしています。
冗長なサンプルやノイズを徹底的に削ぎ落とし、
Less is more ― データは「多さ」ではなく「濃さ」
という方針で訓練を行いました。その結果、汎化性能が向上し、学習も高速化 しています。
| データ構成 | サンプル数 | BIRD-dev | SPIDER-test |
|---|---|---|---|
| 既存 (BIRD, SPIDER) | 18 K | 64.9 | 86.8 |
| 既存+合成 (無フィルタ) | 120 K | 64.6 | 86.4 |
| 既存+合成 (高品質フィルタ) | 27 K | 66.5 | 88.3 |
少量でも高品質サンプルに絞るほうが +1.9 pt / +1.5 pt 精度が向上し、学習も高速化しました。
まさに “Better data beats more data.” です。
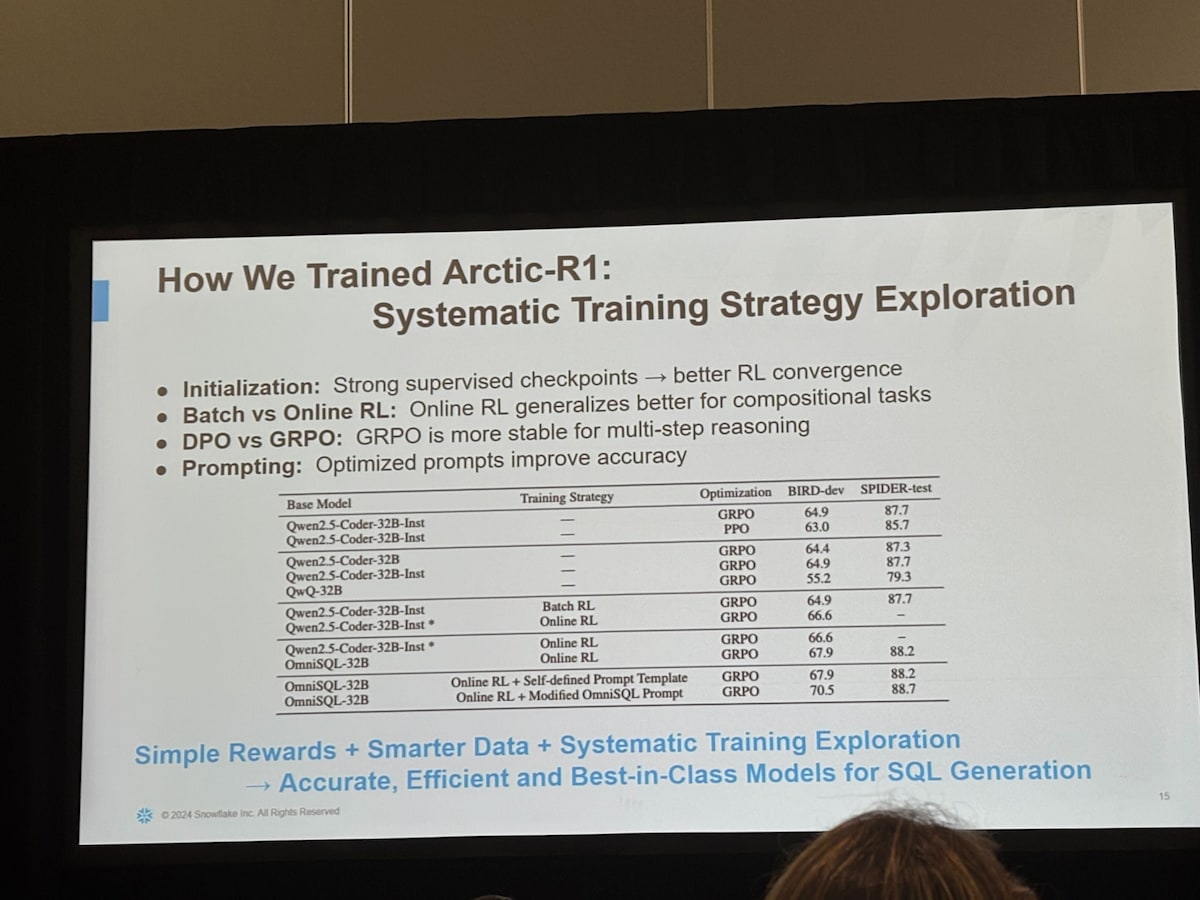
3. Systematic Training Strategy Exploration
Text-to-SQL モデルのトレーニング方法における様々な選択肢を評価し、実験を通じて最適な戦略を見つけ出すプロセスを指します。初期化方法、報酬 shaping、オンライン vs. バッチ RL、プロンプトチューニングなど、あらゆる選択肢をアブレーションで検証し、データに裏づけられた構成 だけを採用しています。たとえばマルチステップ推論においては JRPO が最も安定したといった具体的な知見も公表されています。
| 着目点 | 実験結果 | インサイト |
|---|---|---|
| Initialization | 強力な教師ありチェックポイントで初期化 | RL の収束が速く安定します。 |
| Batch vs. Online RL | Online RL が複合的タスクで高汎化 | 実運用シナリオに強いモデルになります。 |
| DPO vs. GRPO | GRPO の方がマルチステップ推論で安定 | “理由づけ” が複雑でも破綻しにくいです。 |
| Prompting | SQL テンプレートと自己定義プロンプトを比較 | 最適化プロンプトで BIRD-dev 70.5 / SPIDER-test 88.7 まで向上しました。 |
結論:GRPO + Online RL + 最適プロンプト が現状ベストという結果です。
これらの要素について、体系的に異なる選択肢を評価し、実験を行うことで、モデルのコンポーネントからあらゆるビットを絞り出す(最大限の性能を引き出す)助けになったと述べられています。
Arctic Text2SQL-R1 が BIRD ベンチマークを制覇
この学習フレームワークを用いて Snowflake AI Research が開発した Arctic Text2SQL-R1 は、Text-to-SQL 分野の代表的評価指標 BIRD(Benchmark for Intelligent Retrieval and Database question answering) で総合 1 位を獲得しました。

さらに、Arctic Text2SQL-R1 は 6 つのデータセットで一貫して SOTA を記録しています。
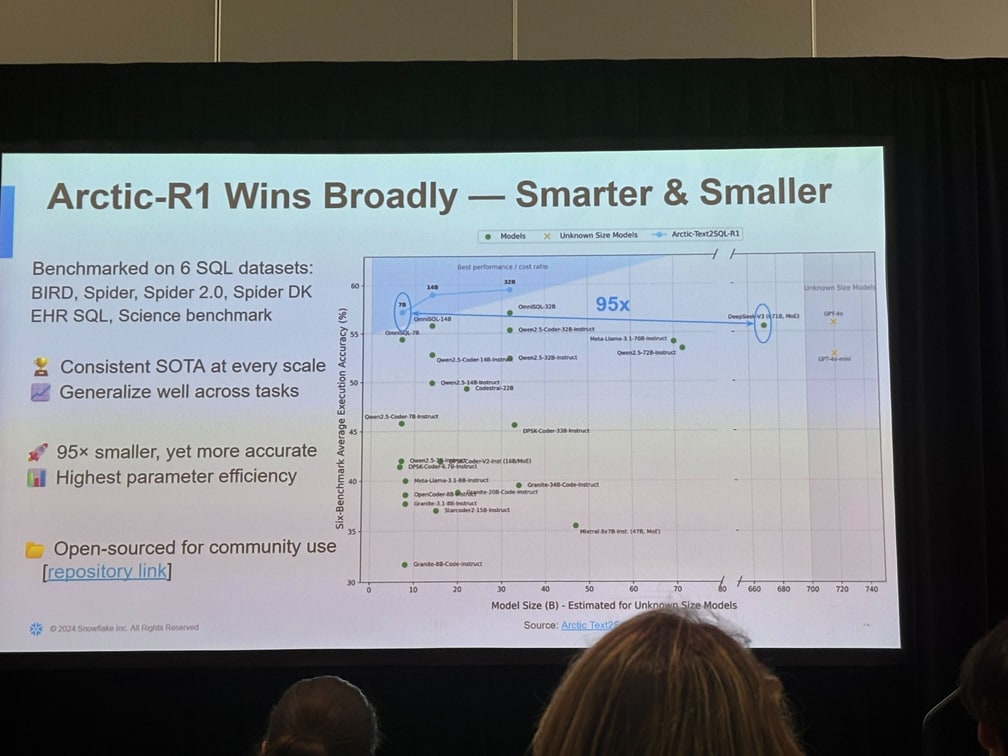
このように、Arctic Text2SQL-R1 は、オープンソースのモデルや独自モデルの中で最高の実行精度を実現しています。
From Reasoning Model to Agentic System
Arctic R1 のような推論特化型モデルは、与えられた自然言語の質問を高精度な SQL に落とし込み、実行結果まで正しいことを保証する――という点では極めて頼もしい基盤を提供します。複数テーブルの JOIN を適切に計画し、サブクエリを段階的に組み立て、実際に SQL を走らせて報酬を得る強化学習フレームワークによって「壊れず・正しい」クエリを返す力は折り紙付きです。
しかしエンタープライズの現場で直面する課題は、しばしばこの“単発クエリ生成”だけでは完結しません。たとえば――
- ビジネスユーザーの質問が曖昧で、そもそも期間や指標の前提が共有されていない
- データベースが部門ごとに増改築され、ドキュメント化されていない列やテーブルが大量に存在する
- 一つの問いに対し、途中で集計粒度を変えたり、外部 API を呼び出したりするステップが必要になる
- 得られた中間結果を確認しながら、追加の条件をかけ直すインタラクティブな分析フローが求められる
こうした“現実の BI ワークフロー”では、モデルがただ SQL を返すだけでなく、不足情報をユーザーに尋ね、スキーマを探り、複数の手順を編成し、外部ツールと連携し、途中で結果を評価して軌道修正するといった振る舞いが不可欠になります。要するに「考える」「聞く」「探す」「行動する」を行き来できるエージェントが必要なのです。
「agentic system」に関する研究は、エンタープライズ向けの AI エージェントを真に機能させるために Snowflake AI Research が注力している分野であり、その研究は5 つの相互に関連する柱 (five interconnected pillars) から成り立っていると説明されています。
Snowflake が Foundation Model(例えば Text-to-SQL の Arctic R1)を基盤としつつも、「reasoning models から agentic system へ」と研究の焦点を移しているのは、現実世界のエンタープライズタスクがしばしば単一モデルだけでは不十分であり、複数のシステム、複数ステップのワークフロー、複雑な推論、不完全なスキーマ知識への対応が必要だからです。これを解決するために、ユーザーからの質問をすべて受け付け、その場で応答できる「エージェント」が必要になります。
Agentic System の 5 つの柱
エンタープライズでエージェントを真に機能させるために、Snowflake は「agentic research」に焦点を当てており、これは以下の 5 つの柱 から構成されています:
- Agentic Orchestration (エージェントオーケストレーション)
- Structured Data Intelligence (構造化データインテリジェンス)
- Unstructured Data Intelligence (非構造化データインテリジェンス)
- Observability and Trust (可観測性と信頼性)
- System Organization (システム最適化)
これらの 5 つの柱は、知的で、構成可能で、信頼でき、効率的なエンタープライズ AI エージェントを提供するための研究の基盤となっています。
Pillar 1: Agentic Orchestration ―― “計画 → 実行 → 適応” をリアルタイムに回すしくみ
エンタープライズの疑問は、複数のシステム・データタイプ・ツールをまたぎながら何段も手順を踏まなければ答えに辿り着けません。そこで重要なのが Agentic Orchestrationです。要するに「LLM が司令塔になってツール群をその場で組み合わせ、途中の学びを反映しながら業務フローを完結させる枠組み」です。
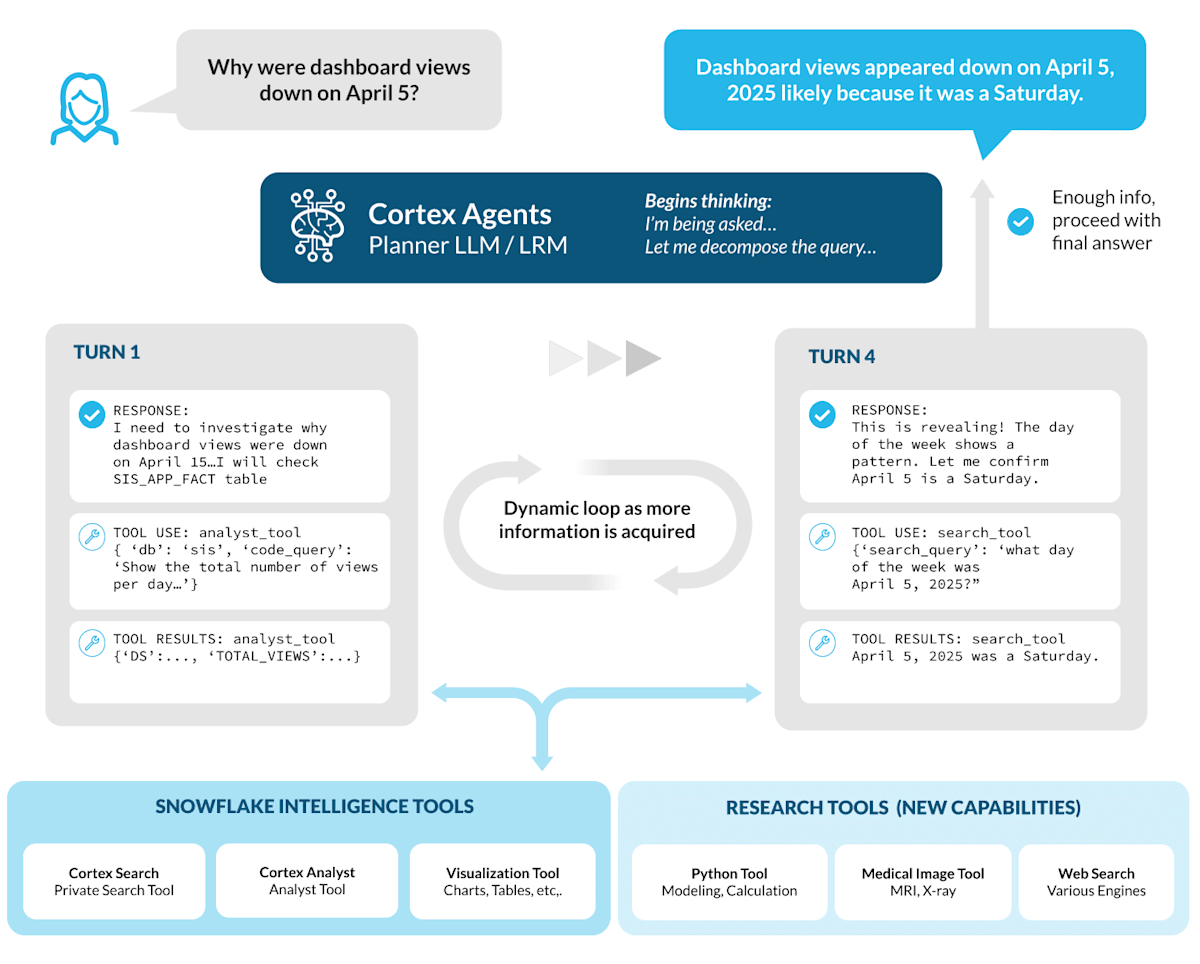
1. Planning(計画フェーズ)
まずエージェントはユーザーの問いを分解し、「何を・どの順で・どのツールで」行うかを策定します。
- ユーザーのクエリの曖昧さを解釈して解決する
- 適切なツールを選択し、実行順序を決定する
- クエリをツール固有のサブタスクに分解する
- 出力がどのように構成されて一貫した最終回答になるかを定義する
といった手段を並べ、作業順序を決定します。例えば、まず Cortex Search で背景コンテキストを取得し、次に Cortex Analyst にピボットして構造化分析を行い、その後、発見した内容に基づいて下流のアクションを調整します。この動的なマルチホップ推論により、変化する質問への柔軟な対応が可能になります。
2. Execution(実行フェーズ)
次に各ツールを呼び出しながらタスクを進めます。ポイントは コンテキスト保持。一度取得したビュー数やメタデータはメモリに残り、次のステップ(例:検索クエリのキーワード生成)に生かされます。これによりツールチェーン全体が“会話”をしながら動いているかのように情報を共有します。
3. Adaptation(適応フェーズ)
途中で新しい事実が判明したら、計画を即座に更新します。閲覧数急落が「土曜日だから」という仮説が得られたら、休日カレンダー照合に切り替え、不要になった分析をスキップするといった具合です。静的フローではなく動的ループとして回る点が従来型ワークフローエンジンとの決定的な違いです。
このオーケストレーションエンジンである Cortex Agents こそが、Snowflake Intelligence がリアルタイムで推論、行動、適応することを可能にしています。
Pillar 2: Structured Data Intelligence
推論モデル(Arctic R1 など)は高精度で SQL を生成できますが、現実のエンタープライズでは
- スキーマが巨大で未整備
- 質問が曖昧で前提が抜け落ちている
- 一発回答では済まない多段ステップが必要
という壁にぶつかります。ここを乗り越えるには、質問 → スキーマ探索 → クエリ生成 → 検証 → 追加探索 を自律的に繰り返せる「行動するエージェント」が欠かせません。
そこで Snowflake は ReFoRCE という以下の 6 つのステップを組み合わせて、スキーマ不明確な場合でも正しいクエリを生成可能とするエージェントシステムを開発しました。
-
Schema Compression
- 数千テーブル規模でも、意味的に近い列や不要要素を圧縮し “把握できるサイズ” へ縮約。
- スキーマは
Table Grouping・Description・Schema Linkingの 3 つの情報を組み合わせて圧縮。
Table full name: bigquery-public-data.noaa_hurricanes.hurricanes Column name: sid Type: STRING Description: Storm Identifier. Table full name: bigquery-public-data.geo_us_boundaries.zip_codes Column name: zip_code Type: STRING External knowledge that might be helpful: # BigQuery UDF Definitions: ... The table structure information is ({database name: {schema name: [table name]}}): ... [6] -
Candidate Generation
- 生成した SQL を即時実行し、結果をフィードバックにして自己修正。
-
Majority-Vote: Failed to Reach a Consensus
- 複数クエリ候補を並列生成し、多数決で最も信頼度が高いものを選定。
-
Column Exploration for 4 Threads
- スキーマが不明確なときだけ能動的にカラムサンプリングを走らせ、最小限の追加 I/O で曖昧さを解消。
-
Redo Candidates Generation Based on Exploration Results
- カラムサンプリングの結果を元に、クエリ候補を再生成。
-
Majority-Vote: Consensus Enforcement
- クエリ候補を多数決で選定。
このサイクルを繰り返すことで、スキーマ不明確な場合でも正しいクエリを生成可能とするエージェントシステムを開発しました。

これにより Snowflake は従来のアプローチよりも高い精度と効率でクエリ生成を行えるようになり、この ReFoRCE フレームワークの成果は具体的なベンチマーク結果にも表れています。
- +4.0 ポイント で Spider 2.0 Lite で 1 位を獲得
- 低コストモードで平均 1.7 コール/クエリという実用的な処理効率
- 現実世界のワークロードにも対応できる堅牢性と拡張性

Arctic Inference and Training
前章までで、Snowflake は推論モデル(Arctic R1)とエージェント層(ReFoRCE ほか)により構成可能で信頼できる AI エージェントのロジック面を固めました。しかし リアルユーザーがクリックした瞬間に応答が来る かどうかは、モデルの賢さではなく システム層の実装 に懸かっています。
| 従来の並列戦略 | 長所 | 短所 |
|---|---|---|
| Tensor Parallel | 低レイテンシ | 通信多 → スループット低 |
| Data Parallel | 高スループット | 初動遅い・レイテンシ高 |
Snowflake はこの二律背反を Shift Parallelism で解消することにより、
- 小バッチ=Tensor Parallel で瞬発力、
- 大バッチ=Arctic Sequence Parallel で持久力、
を自動でシフトし、レイテンシとスループット双方の頂点を同時に押さえることに成功しました。
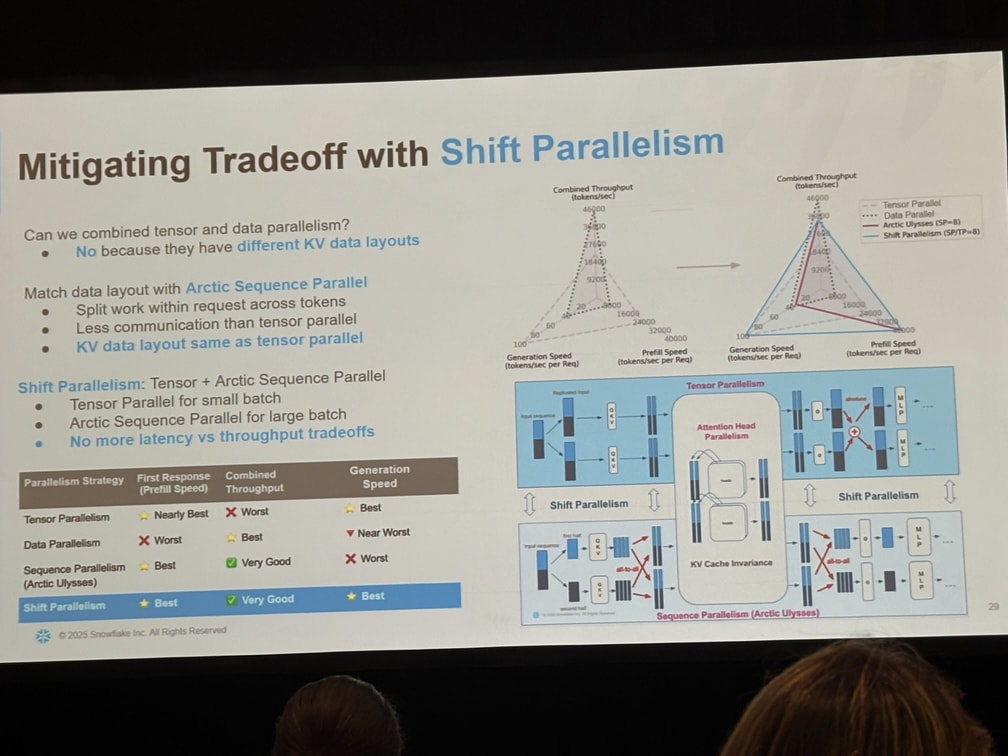
効果:リアルトラフィック下で初動 3.4× 速く、合成スループット 1.7× 高い(vLLM 最速設定比)
さらに SwiftKV, Speculative Decoding, Early Termination など SoTA 最適化を積み上げ、同等 GPU で最大 4×-16× の処理量を達成。これらはすべて オープンソース 化され、既に Cortex AI の本番推論基盤で稼働しています。
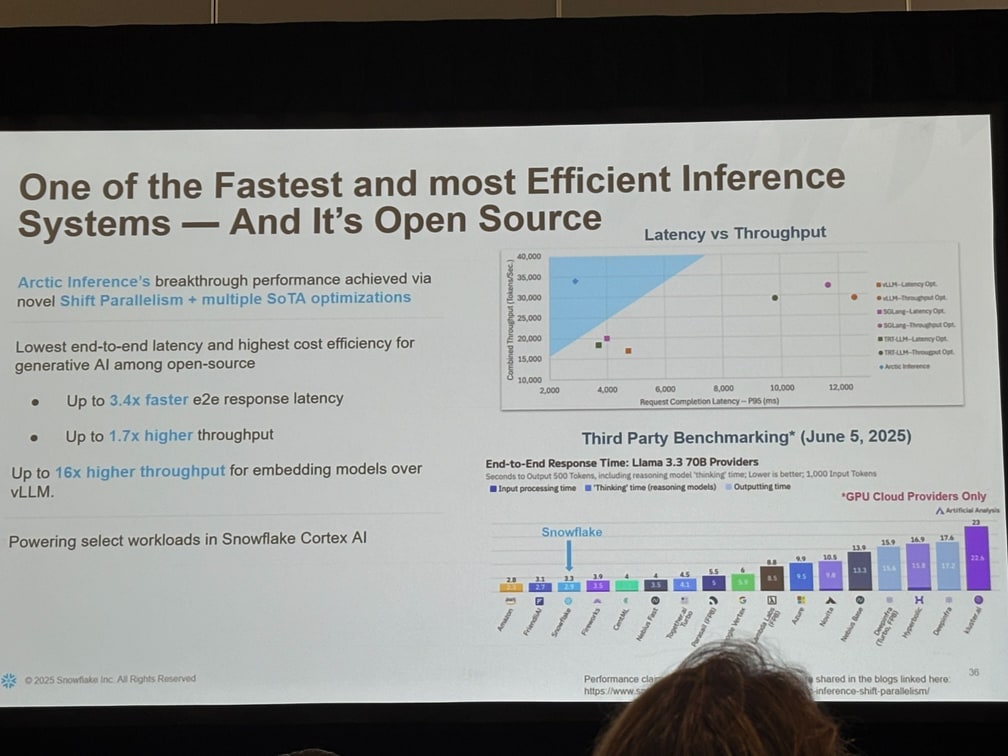
実際のデモでは、baseline と比較して、5.53 倍の速度で推論が実行されています。 token も 1/6 になっておりかなりの効率化が見られます。
Arctic Inference はオープンソースで公開されています。pip install arctic-inference でインストールでき、すぐに試すことができます。
所感・まとめ
Snowflake AI Research は、「精度・効率・信頼性・オープン」を同時に満たすエンタープライズ AI を実現するために、モデル、エージェント、システム最適化までを一気通貫で進化させていました。
-
Arctic Text2SQL-R1
- 実行結果に直結したシンプルな報酬設計と「質重視」のデータ選別で、BIRD ほか 6 つのベンチマークで SOTA を獲得。
- 「動く SQL」を前提に設計された学習フレームワークは、実運用で再現しやすい点が大きな強み。
→ Snowflake Copilot や Cortex Analyst の text2sql の精度が大幅に向上すると思われます。
-
Agentic Technologies
- 質問のあいまいさや巨大スキーマを乗り越え、計画 → 実行 → 適応 をループさせるエージェントが BI ワークフローを自律化。
- 5 本柱(オーケストレーション/構造化・非構造化データ知能/可観測性/システム最適化)が、現場導入に必要な“最後の 1 マイル”を埋める。
→ Snowflake Intelligence の Agentic System が要となる技術であり、Agent の精度に大きく寄与すると思われます。
-
Arctic Inference & Training
- Shift Parallelism を核に、初動レイテンシとバルクスループットのトレードオフを解消。
- SwiftKV・Speculative Decoding などを OSS で公開し、パフォーマンス最適化の知見をコミュニティへ還元。
→ これにより推論時間が大幅に短縮され、コスト面でも UX の観点でも大幅に改善すると思われます。
これらを総合すると、Snowflake は 「高精度モデル × エージェント自律性 × 高速インフラ」 の三位一体でエンタープライズ AI をプロダクションに乗せる“現実解”を提示したと言えると思います。
Snowflake が Summit で「Build the future of AI and Apps」というワードをここ最近強く打ち出している通り、名実共に AI 分野を重要視していることがわかりました。データクラウドとしてデータに対する独自の知見がある Snowflake だからこそ、このような研究成果を出すことができたと思います。
正直すでに公開されていた Snowflake Copilot や Cortex Analyst の text2sql の精度について、以前検証した時はまだまだ精度的に不十分な感触でした。しかし今回の研究によって大幅に進化し、精度面でも性能面でも大幅に改善したことがわかります。
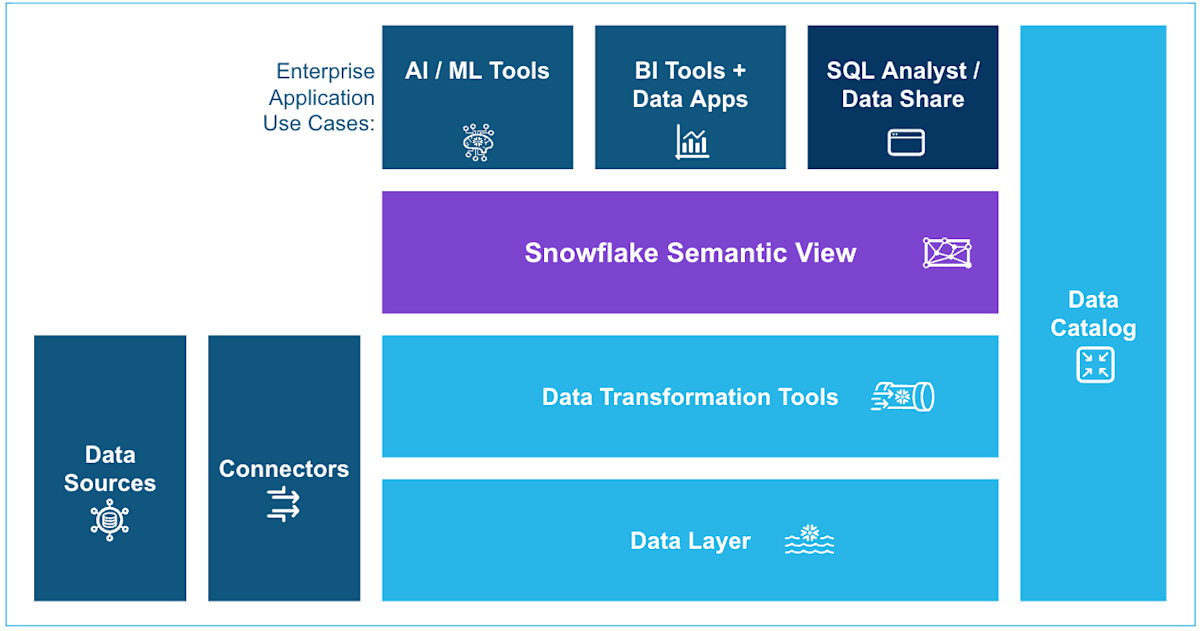
また新機能である Snowflake Semantic View もこれら AI と データベースの橋渡しを担っている重要な概念です。Arctic Text2SQL や Cortex Agent は Semantic View を参照して SQL を生成することとなるため、巨大で雑多なスキーマでも正確・再現性のある回答を返せるようになります。個々の機能ではなく Snowflake はこれらを統合してエンタープライズ AI を実現しているということがわかります。
あらためて Snowflake Copilot や Cortex Analyst の text2sql の精度について検証するとともに Snowflake の機能をフルに活用してどのようなことができるかを検証してみたいと思います。そして Agentic System が活用される Snowflake Intelligence の今後の動向についてもウォッチしていきたいと思います!
参考資料
Snowflake Blog
GitHub
Hugging Face
論文

Discussion