はじめに
こんにちは、ナウキャストで LLM エンジニアをしている Ryotaro です。
サンフランシスコで開催された Snowflake Summit 2025 にナウキャストのメンバーで参加しました!
LLM エンジニアとして AI/ML 系のセッションをメインに参加しました!
合計 4 日間あるので、1 日ごとに面白かったセッションを記事にまとめていこうと思います!本日は 1 日目を投稿します!
↓ ナウキャストの他メンバーも記事を投稿しているので、ぜひご覧ください!
関連記事
day 2 の記事はこちらです!
day 3 の記事はこちらです!
day 4 の記事はこちらです!
Snowflake Summit の概要

snowflake summit 2025 会場
Snowflake Summit は、Snowflake Inc.が毎年主催するフラッグシップ・カンファレンスで、世界中のデータ/AI プロフェッショナルが一堂に会し、最新プロダクト発表や実践的な学習機会、業界横断のネットワーキングを通じて"Snowflake AI Data Cloud"の現在と未来を体感する場です。2025 年の第 7 回目は 6/2~6/5 にサンフランシスコの Moscone Center で開催され、4 日間・15 トラック・500 超のセッションと 190 社以上のパートナー出展が予定されるなど、過去最大規模に拡大しています。
| 項目 | 内容 |
|---|---|
| 開催日 | 2025 年 6 月 2 日(月)–5 日(木) |
| 会場 | Moscone Center(サンフランシスコ) |
| 規模 | 15 トラック / 500+セッション / 190+パートナー |
| 参加形態 | 対面+基調講演のライブ配信 |
| 目玉キーノート | Snowflake CEO Sridhar Ramaswamy × OpenAI CEO Sam Altman 対談 |
業界別ユースケースと Snowflake ネイティブの LLM サービスが多数披露予定なので、LLM エンジニアとしてはこの辺りに注目してセッションを予約しました。

1 日目
Fostering Operational Resilience by Using Snowflake Cortex AI (13:30~13:50)
セッション説明文
Snowflake Cortex AI を活用し、潜在的なリスクを早期に特定し、導入前およびインシデント発生後の RCA(リスクアセスメント)において適切な緩和戦略を確実に実施するためのユースケースを開発しました。これにより、予防策が失敗したのか、それとも外部要因が問題の原因となったのかを特定し、変更リスクを管理するためのクローズドループプロセスを構築できます。この二重のアプローチにより、リスクをプロアクティブに管理しながら、インシデントドリブンなインサイトに基づく継続的な改善を推進することで、運用のレジリエンス(回復力)が向上します。
感想
セッションの内容としては、プロダクション環境のインシデント履歴を大規模言語モデル(LLM)に渡して要約・分析し、再発防止策と運用改善を図った約 2 か月間の PoC とその後のスケールアップの知見を共有する内容でした。
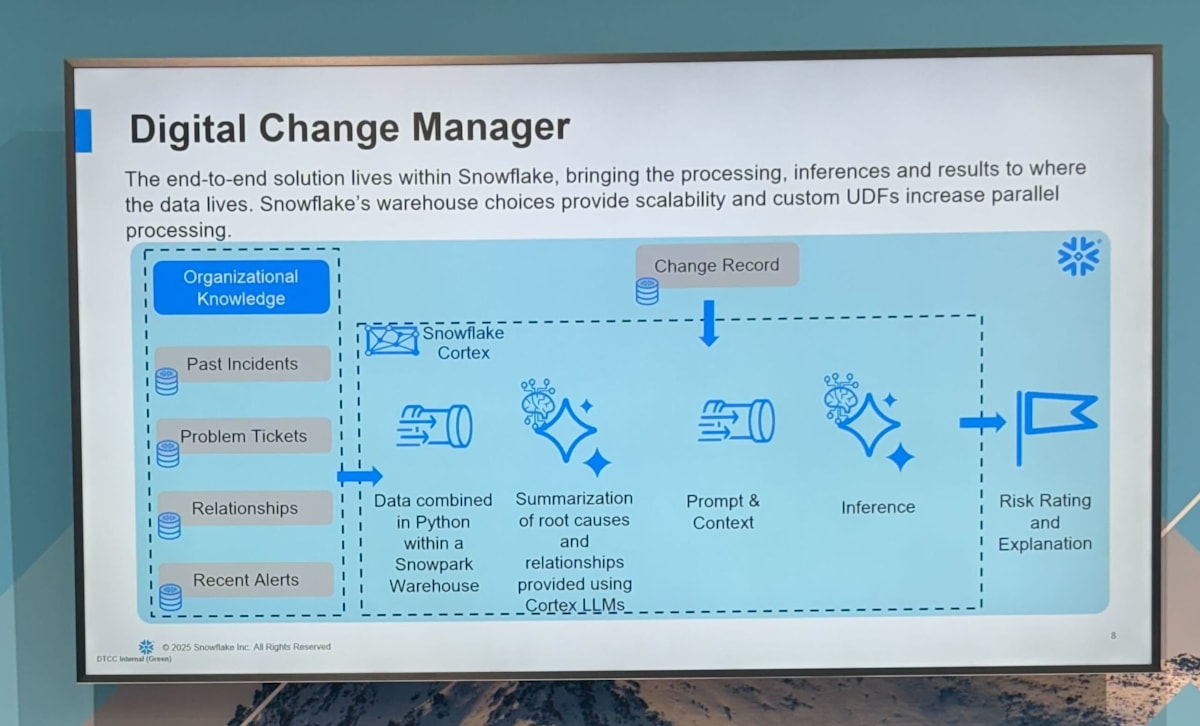
過去の incident や 最新の alert を knowledge として cortex に連携して、 インフラ変更ログから障害を検知するシステムにおいて snowflake で完結するところが良いと感じました。
PoC の結果としては正答率 88 % で誤検知を大幅削減し、障害後レビュー工数を削減したとのことでしっかり業務効率化も図れていました。
個人的には古いインシデントをどこまで残すかが精度とコストに直結するので気になりました。多く残しすぎてもノイズになったり最新の障害に fit しなかったりするのでこのあたりは実際の検知結果から不要なものを削除していくといった運用が考えられそうです。
Ohio Bureau of Workers' Compensation: Scalable RAG-based Policy Assistant (14:00~14:45)
セッション説明文
RAG ポリシーアシスタントにより、従業員サービスグル ープはオハイオ州のポリシーと規制に基づき、客観的で透明性が高く、タイムリーで一貫性があり、再現可能なガイダンスを提供できます。このソリューションは、Snowflake Vector データ型、Snowflake Cortex AI、Cortex Guard、Streamlit をスケーラブルな生成 AI フレームワークの一部として活用しています。自動ユーザーフィードバック、LLM による判断、人間参加型検証、LLM 構成テスト、インフラ最適化ダッシュボードなどの機能が組み込まれています。
感想
Ohio 州労働者補償局(BWC)が、Snowflake + Streamlit ベースで構築した「ポリシー専用生成 AI チャット」第 1 号ソリューションを紹介していました。
QA 作成の LLM を入れて、1 次データをさらに拡張し、その QA を streamlit 上から専門家がチェックして、再度 DB に格納という仕組み。検索方式としては 2 段階で、QA リストに近いものがあればそのまま回答、なければ DB にベクトル検索 さらに cortex guard で不適切な出力を抑制。
ユーザーの FB をログとして蓄積し、定量評価し、週次パフォーマンス分析で改善するというサイクルも用意しており、日々改善しているとのこと。シンプルながら汎用的な構成で、FAQ システムのベーシックな感じがしました。
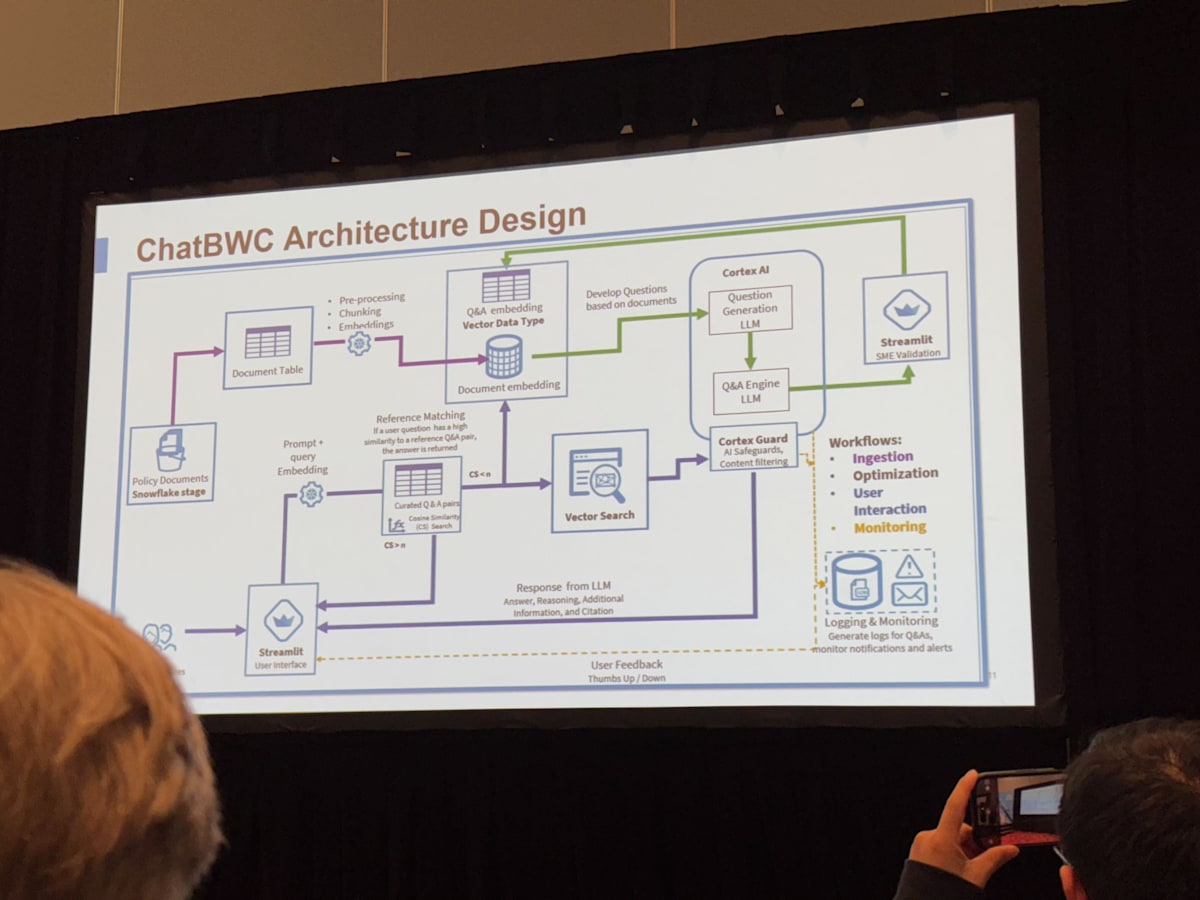
さらに、実際の chat では引用箇所+“Chain of Thought”を可視化することで、ハルシネーション対策を講じていました。LLM をなにかしらの判定をさせる際にこのテクニックはよくある手法で、CoT の内容自体を LLM に出力させることで精度が上がることもあります。
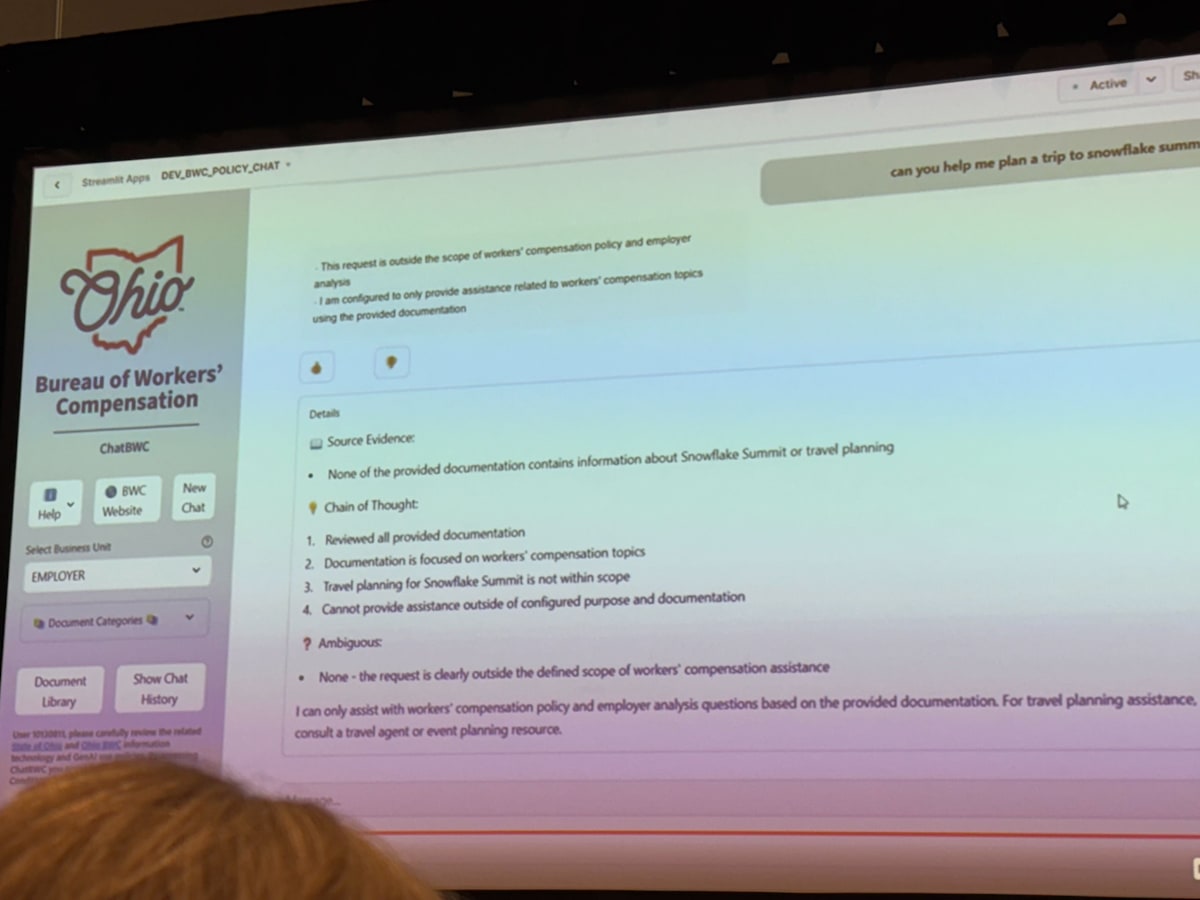
この application もストレージ・ベクトル化・LLM 推論・UI(Streamlit)まで snowflake で完結しており、かつ非常に実用的なユースケースとなっているので、かなり構築コストが低く、他にも転用できそうな良い事例だなと思いました。
[Hands-on] Build and Deploy Data Agents with Snowflake Cortex AI (15:00~16:30)
セッション説明文
このハンズオンラボでは、Snowflake Cortex エージェントを用いて、AI を活用したデータエージェントを構築・導入します。Cortex Analyst と Cortex Search を用いて構造化データと非構造化データの取得をオーケストレーションすることで、複雑で多段階的な操作を自動化するエージェントの作成方法を習得します。AI をエンタープライズワークフローに統合し、ガバナンスを管理し、リアルタイムのインサイトによって意思決定を改善するためのベストプラクティスを探求します。セッション終了時には、リクエストの処理、関連データの取得、インテリジェントなレスポンスの生成をすべて Snowflake 内で安全に実行できる、完全に機能するエージェントが完成します。
ハンズオン内容
Snowflake Cortex の Cortex Search と Cortex Analyst を組み合わせた Agent を作成するというハンズオンでした。それぞれ構造化・非構造化データを扱うので組み合わせることでどちらにも対応できる Agent を構築することができます。
以下の github の readme に沿ってやっていきます。詳細な手順は記載されているので以降重要な部分をピックアップして解説します。
Cortex LLM の機能一つ目は PARSE_DOCUMENT (SNOWFLAKE.CORTEX) で、これにより非構造化データである PDF や image などを text に変換することができます。OCR と Layout モードの 2 種類があり、Layout モードだと表構造やタイトルなどの階層構造までを考慮して出力してくれるそうです(Layout モードは現在 preview version)
CREATE OR REPLACE TEMPORARY TABLE RAW_TEXT AS
SELECT
RELATIVE_PATH,
TO_VARCHAR (
SNOWFLAKE.CORTEX.PARSE_DOCUMENT (
'@DOCS',
RELATIVE_PATH,
{'mode': 'LAYOUT'} ):content
) AS EXTRACTED_LAYOUT
FROM
DIRECTORY('@DOCS')
WHERE
RELATIVE_PATH LIKE '%.pdf';
SELECT * FROM RAW_TEXT;
二つ目は、COMPLETE (SNOWFLAKE.CORTEX)で、LLM に直接レコードごとのデータを投げることができます。input としては画像データも読み込むことができ、セッションでは image の description を生成させていました。
insert into DOCS_CHUNKS_TABLE (relative_path, chunk, chunk_index, category)
SELECT
RELATIVE_PATH,
CONCAT('This is a picture describing the bike: '|| RELATIVE_PATH ||
'THIS IS THE DESCRIPTION: ' ||
SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
'DESCRIBE THIS IMAGE: ',
TO_FILE('@DOCS', RELATIVE_PATH))) as chunk,
0,
SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
'Classify this image, respond only with Bike or Snow: ',
TO_FILE('@DOCS', RELATIVE_PATH)) as category,
FROM
DIRECTORY('@DOCS')
WHERE
RELATIVE_PATH LIKE '%.jpeg';
以上で作成したデータをもとに Cortex Search を有効化します
create or replace CORTEX SEARCH SERVICE DOCUMENTATION_TOOL
ON chunk
ATTRIBUTES relative_path, category
warehouse = COMPUTE_WH
TARGET_LAG = '1 hour'
EMBEDDING_MODEL = 'snowflake-arctic-embed-l-v2.0'
as (
select chunk,
chunk_index,
relative_path,
category
from docs_chunks_table
);
以上により非構造化データを構造化データに変換し、Cortex Search によるベクトル検索ができるようになります。
さらに Cortex Analyst が使えるように準備された構造化データを用意し semantic.yaml を作成します。(どちらも github repository に用意済み)
つぎに 「AI & ML」 > 「Studio」>「Cortex Analyst(preview)」から analyst の構築に必須な semantic model をテストする機能を開きます。
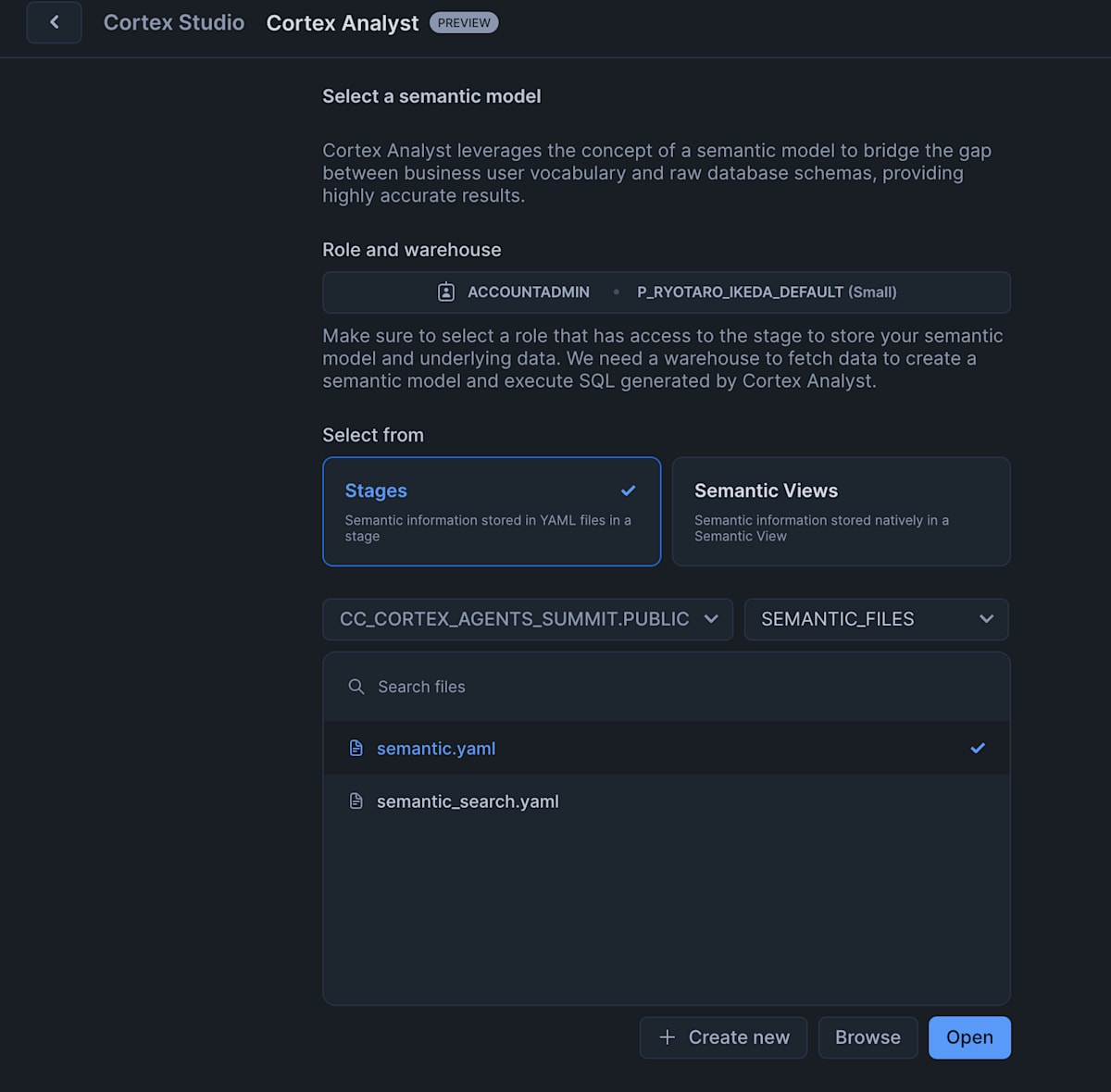
既存のものがある場合は選ぶことができ、そこから編集が可能です。
すると dimension の編集画面にて search service を追加することができます。
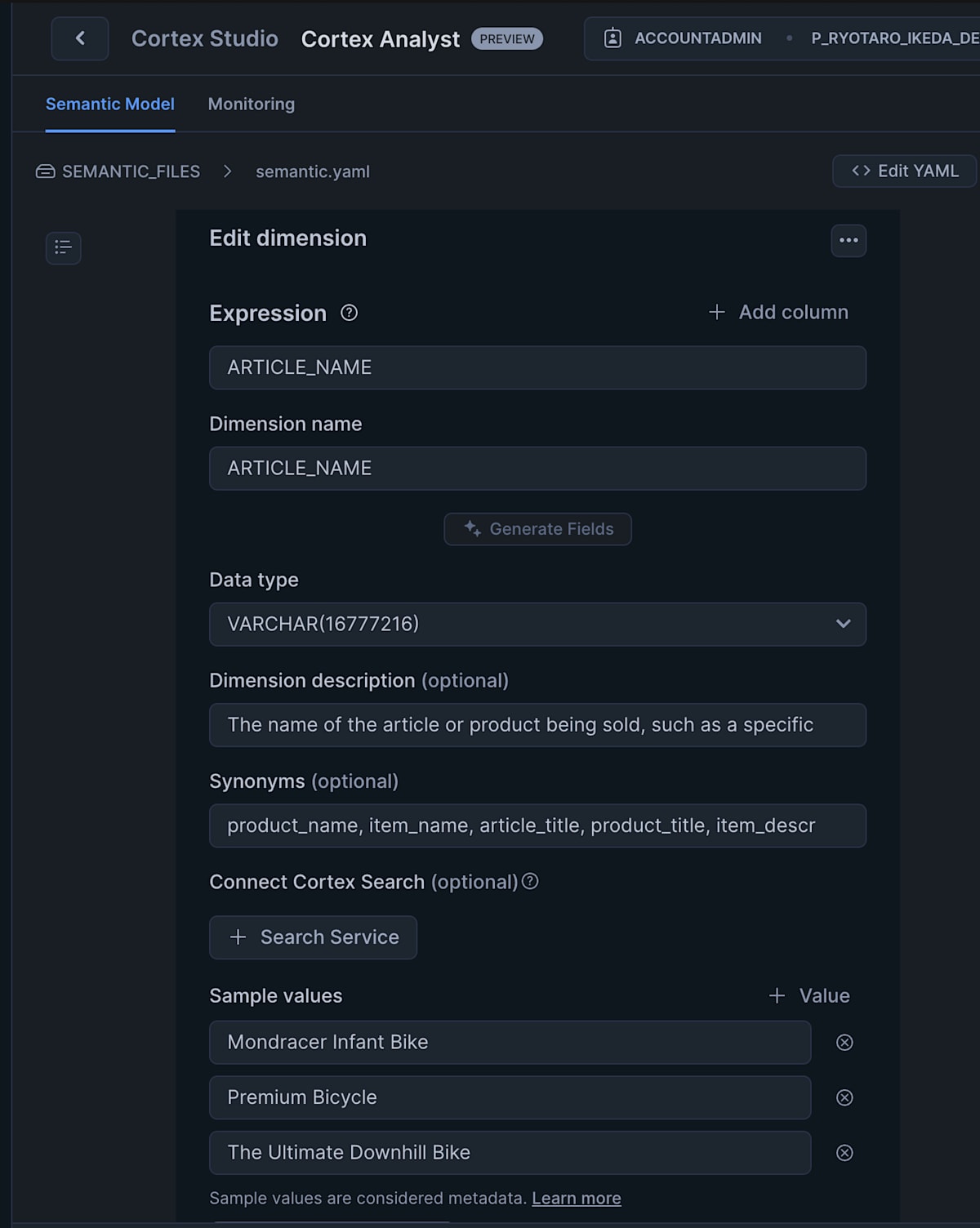
yaml を編集する場合は cortex_search_service というセクションを追加します。
optional なので使わない場合は記載せずでいけます。
tables:
- name: DIM_ARTICLE
base_table:
database: CC_CORTEX_AGENTS_SUMMIT
schema: PUBLIC
table: DIM_ARTICLE
dimensions:
- name: ARTICLE_NAME
expr: ARTICLE_NAME
data_type: VARCHAR(16777216)
sample_values:
- Mondracer Infant Bike
- Premium Bicycle
- The Ultimate Downhill Bike
description: The name of the article or product being sold, such as a specific type of bicycle.
synonyms:
- product_name
- item_name
- article_title
- product_title
- item_description
- product_description
+ cortex_search_service:
+ database: CC_CORTEX_AGENTS_SUMMIT
+ schema: PUBLIC
+ service: _ARTICLE_NAME_SEARCH
これにより Cortex Analyst に Cortex Search を組み込むことができました。
最後に Cortex Agents を構築します。
payload の設定にて今までに構築した Cortex Search と Cortex Analyst を tool として登録し、説明を加えます。
この payload をもとに Agent の API を叩くことで、Cortex Search と Cortex Analyst の機能を持ち合わせた Agent の構築が完成します。

ちなみに tools には cortex_analyst_text_to_sqlと cortex_searchに加え、 data_exec と data_to_chartも選択可能で、同じ type のものも追加可能です。(参考:https://docs.snowflake.com/en/user-guide/snowflake-cortex/cortex-agents-rest-api#sample-request)
{
"tools":
[
{ "tool_spec": { "type": "sql_exec", "name": "sql_exec" } },
{ "tool_spec": { "type": "data_to_chart", "name": "data_to_chart" } },
],
}
感想
今回 Cortex Agents の構築ハンズオンセッションを受けましたが、もともとこの機能の存在を知らなかったので、かなり衝撃を受けました。2025/2/12 に public preview で公開はされていたようです。
Cortex Search と Analyst との区別としては明確に分かれており、二つはあくまでも対象となる一つの 非構造化・構造化のデータに対して検索ができる機能であることに対し、その機能を統合した検索が可能となる機能です。
検証ポイントととしては Agents が Cortex Search と Analyst をどう使い分けるかという点かと思います。そのためのヒントとしての tool の description を書く場所がないので、今のところ black box です。response_instruction に使い分けの指示を書くのか、description の項目が今後増えるのか検証とキャッチアップが必須ですね。
こちらに Cortex Agent のチュートリアルがあるので、あわせて見ておくと良いと思います!

Discussion