金融与信モデル(6)——実例:モデルの構築
金融与信モデル入門シリーズ
- スコアカードの由来
- 証拠の重さと情報価値(WOE and IV)
- グルーピングの方法(Grouping Method)
- 信頼できるAIの要素——PSI(Population Stability Index)
- スコアの計算
- 実例:モデルの構築
ソースコード:GitHub Repository
Tool explanation
Lapras Package Install
via pip
pip install lapras --upgrade -i https://pypi.org/simple
import lapras
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib as mpl
import matplotlib.pyplot as plt
pd.options.display.max_colwidth = 100
import math
%matplotlib inline
from IPython.display import display, HTML
display(HTML("<style>.container { width:90% !important; }</style>"))
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
Read in data file
Note:Data comes from:https://www.kaggle.com/competitions/GiveMeSomeCredit/data
df_training = pd.read_csv('data/cs-training.csv',encoding="utf-8", index_col=0)
df_testing = pd.read_csv('data/cs-test.csv',encoding="utf-8", index_col=0)
to_drop = [] # exclude the features which not being used, eg:id
target = 'SeriousDlqin2yrs' # Y label name
Simple EDA(Exploratory Data Analysis)
lapras.detect(df_training)
| type | size | missing | unique | mean_or_top1 | std_or_top2 | min_or_top3 | 1%_or_top4 | 10%_or_top5 | 50%_or_bottom5 | 75%_or_bottom4 | 90%_or_bottom3 | 99%_or_bottom2 | max_or_bottom1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| int64 | 150000 | 0 | 2 | 0.06684 | 0.249746 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| float64 | 150000 | 0 | 125728 | 6.04844 | 249.755 | 0 | 0 | 0.00296898 | 0.154181 | 0.559046 | 0.981278 | 1.09296 | 50708 |
| int64 | 150000 | 0 | 86 | 52.2952 | 14.7719 | 0 | 24 | 33 | 52 | 63 | 72 | 87 | 109 |
| int64 | 150000 | 0 | 16 | 0.421033 | 4.19278 | 0 | 0 | 0 | 0 | 0 | 1 | 4 | 98 |
| float64 | 150000 | 0 | 114194 | 353.005 | 2037.82 | 0 | 0 | 0.030874 | 0.366508 | 0.868254 | 1267 | 4979.04 | 329664 |
| float64 | 150000 | 0.1982 | 13594 | 6670.22 | 14384.7 | 0 | 0 | 2005 | 5400 | 8249 | 11666 | 25000 | 3.00875e+06 |
| int64 | 150000 | 0 | 58 | 8.45276 | 5.14595 | 0 | 0 | 3 | 8 | 11 | 15 | 24 | 58 |
| int64 | 150000 | 0 | 19 | 0.265973 | 4.1693 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 98 |
| int64 | 150000 | 0 | 28 | 1.01824 | 1.12977 | 0 | 0 | 0 | 1 | 2 | 2 | 4 | 54 |
| int64 | 150000 | 0 | 13 | 0.240387 | 4.15518 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 98 |
| float64 | 150000 | 0.0262 | 13 | 0.757222 | 1.11509 | 0 | 0 | 0 | 0 | 1 | 2 | 4 | 20 |
Calculate IV value of features(Calculate by default decision tree binning)
lapras.quality(df_training.drop(to_drop,axis=1),target = target)
| iv | unique |
|---|---|
| 1.16303 | 125728 |
| 0.880725 | 19 |
| 0.761485 | 16 |
| 0.601348 | 13 |
| 0.264446 | 86 |
| 0.111157 | 58 |
| 0.093006 | 13595 |
| 0.077739 | 114194 |
| 0.065721 | 28 |
| 0.036456 | 14 |
Calculate PSI of features between train and test dataset
All the PSIs are very small, that says the populations are stable.
cols = list(lapras.quality(df_training,target = target).reset_index()['index'])
for col in cols:
if col not in [target]:
print("%s: %.4f" % (col,lapras.PSI(df_training[col], df_testing[col])))
D:\anaconda3\lib\site-packages\lapras\stats.py:191: FutureWarning: iteritems is deprecated and will be removed in a future version. Use .items instead.
RevolvingUtilizationOfUnsecuredLines: 0.0001
NumberOfTimes90DaysLate: 0.0000
NumberOfTime30-59DaysPastDueNotWorse: 0.0000
NumberOfTime60-89DaysPastDueNotWorse: 0.0000
age: 0.0001
NumberOfOpenCreditLinesAndLoans: 0.0001
MonthlyIncome: 0.0005
DebtRatio: 0.0001
NumberRealEstateLoansOrLines: 0.0001
NumberOfDependents: 0.0001
Calculate VIF
There are some multi-correlations in the dataset.
lapras.VIF(df_training.drop(to_drop,axis=1))
lapras.VIF(df_testing.drop(to_drop,axis=1))
SeriousDlqin2yrs 1.033037
RevolvingUtilizationOfUnsecuredLines 1.000180
age 0.271682
NumberOfTime30-59DaysPastDueNotWorse 41.465993
DebtRatio 1.027033
MonthlyIncome 1.026314
NumberOfOpenCreditLinesAndLoans 1.231288
NumberOfTimes90DaysLate 73.738360
NumberRealEstateLoansOrLines 1.255707
NumberOfTime60-89DaysPastDueNotWorse 93.546744
NumberOfDependents 1.030817
dtype: float64
SeriousDlqin2yrs 0.000000
RevolvingUtilizationOfUnsecuredLines 1.000302
age 1.042585
NumberOfTime30-59DaysPastDueNotWorse 46.935924
DebtRatio 1.025020
MonthlyIncome 1.005398
NumberOfOpenCreditLinesAndLoans 1.286748
NumberOfTimes90DaysLate 88.667497
NumberRealEstateLoansOrLines 1.252250
NumberOfTime60-89DaysPastDueNotWorse 112.127576
NumberOfDependents 1.028935
dtype: float64
Dividing the training set into training and validating set
train_df, val_df, _, _ = train_test_split(df_training, df_training[[target]], test_size=0.2, random_state=42)
test_df = df_testing
Features selection
Automatically selecting features by IV, missing rate, corelations and VIF
train_selected, dropped = lapras.select(train_df.drop(to_drop,axis=1),target = target, empty = 0.95, \
iv = 0.05, corr = 0.9, vif = False, return_drop=True, exclude=[])
print(dropped)
print(train_selected.shape)
train_selected.head(10)
{'empty': array([], dtype=float64), 'iv': array(['NumberOfDependents'], dtype=object), 'corr': array(['NumberOfTime60-89DaysPastDueNotWorse',
'NumberOfTime30-59DaysPastDueNotWorse'], dtype=object)}
(120000, 8)
| SeriousDlqin2yrs | RevolvingUtilizationOfUnsecuredLines | age | DebtRatio | MonthlyIncome | NumberOfOpenCreditLinesAndLoans | NumberOfTimes90DaysLate | NumberRealEstateLoansOrLines |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 29 | 0.0115128 | 4342 | 5 | 0 | 0 |
| 0 | 0.595526 | 55 | 0.835333 | 1833 | 11 | 0 | 1 |
| 0 | 0 | 43 | 0.0434365 | 4166 | 2 | 0 | 0 |
| 0 | 0.39198 | 40 | 0.0597711 | 9000 | 2 | 0 | 0 |
| 0 | 0 | 35 | 0.133598 | 5800 | 12 | 0 | 1 |
| 0 | 0.442956 | 61 | 0.65852 | 7200 | 12 | 0 | 2 |
| 1 | 0.336976 | 27 | 0.275494 | 4500 | 9 | 0 | 0 |
| 0 | 0 | 49 | 0.230708 | 2500 | 5 | 0 | 0 |
| 0 | 0.322778 | 69 | 2754 | nan | 17 | 0 | 1 |
| 0 | 0.133706 | 57 | 0.122251 | 3500 | 7 | 0 | 0 |
Feature Binning
Following methods are supported: monotonous binning,decision tree binning, equal frequency binning,equal step size binning.
You can also adjust binnings by load the json.
c = lapras.Combiner()
c.fit(train_selected, y = target,method = 'dt', min_samples = 0.05,n_bins=8) #empty_separate = False
# c.load({'RevolvingUtilizationOfUnsecuredLines': [0.0001,
# 0.1318,
# 0.3009,
# 0.3963,
# 0.5003,
# 0.6987,
# 0.941],
# 'age': [35.5, 43.5, 52.5, 55.5, 59.5, 63.5, 67.5],
# 'DebtRatio': [0.0193, 0.1368, 0.4164, 0.5055, 0.7714, 2.9942, 995.5],
# 'MonthlyIncome': [930.0, 2000.5, 2649.5, 3456.5, 4833.5, 6596.5, 9930.5],
# 'NumberOfOpenCreditLinesAndLoans': [2.5, 3.5, 5.5, 7.5, 8.5, 13.5, 16.5],
# 'NumberOfTimes90DaysLate': [0.5],
# 'NumberRealEstateLoansOrLines': [0.5, 1.5, 2.5]})
c.export()
<lapras.transform.Combiner at 0x2745de778e0>
{'RevolvingUtilizationOfUnsecuredLines': [0.0001,
0.1318,
0.3009,
0.3963,
0.5003,
0.6987,
0.941],
'age': [35.5, 43.5, 52.5, 55.5, 59.5, 63.5, 67.5],
'DebtRatio': [0.0193, 0.1368, 0.4164, 0.5055, 0.7714, 2.9942, 995.5],
'MonthlyIncome': [930.0, 2000.5, 2649.5, 3456.5, 4833.5, 6596.5, 9930.5],
'NumberOfOpenCreditLinesAndLoans': [2.5, 3.5, 5.5, 7.5, 8.5, 13.5, 16.5],
'NumberOfTimes90DaysLate': [0.5],
'NumberRealEstateLoansOrLines': [0.5, 1.5, 2.5]}
c.transform(train_selected, labels=True).iloc[0:10,:]
| SeriousDlqin2yrs | RevolvingUtilizationOfUnsecuredLines | age | DebtRatio | MonthlyIncome | NumberOfOpenCreditLinesAndLoans | NumberOfTimes90DaysLate | NumberRealEstateLoansOrLines |
|---|---|---|---|---|---|---|---|
| 0 | 00.[-inf,0.0001) | 00.[-inf,35.5) | 00.[-inf,0.0193) | 04.[3456.5,4833.5) | 02.[3.5,5.5) | 00.[-inf,0.5) | 00.[-inf,0.5) |
| 0 | 05.[0.5003,0.6987) | 03.[52.5,55.5) | 05.[0.7714,2.9942) | 01.[930.0,2000.5) | 05.[8.5,13.5) | 00.[-inf,0.5) | 01.[0.5,1.5) |
| 0 | 00.[-inf,0.0001) | 01.[35.5,43.5) | 01.[0.0193,0.1368) | 04.[3456.5,4833.5) | 00.[-inf,2.5) | 00.[-inf,0.5) | 00.[-inf,0.5) |
| 0 | 03.[0.3009,0.3963) | 01.[35.5,43.5) | 01.[0.0193,0.1368) | 06.[6596.5,9930.5) | 00.[-inf,2.5) | 00.[-inf,0.5) | 00.[-inf,0.5) |
| 0 | 00.[-inf,0.0001) | 00.[-inf,35.5) | 01.[0.0193,0.1368) | 05.[4833.5,6596.5) | 05.[8.5,13.5) | 00.[-inf,0.5) | 01.[0.5,1.5) |
| 0 | 04.[0.3963,0.5003) | 05.[59.5,63.5) | 04.[0.5055,0.7714) | 06.[6596.5,9930.5) | 05.[8.5,13.5) | 00.[-inf,0.5) | 02.[1.5,2.5) |
| 1 | 03.[0.3009,0.3963) | 00.[-inf,35.5) | 02.[0.1368,0.4164) | 04.[3456.5,4833.5) | 05.[8.5,13.5) | 00.[-inf,0.5) | 00.[-inf,0.5) |
| 0 | 00.[-inf,0.0001) | 02.[43.5,52.5) | 02.[0.1368,0.4164) | 02.[2000.5,2649.5) | 02.[3.5,5.5) | 00.[-inf,0.5) | 00.[-inf,0.5) |
| 0 | 03.[0.3009,0.3963) | 07.[67.5,inf) | 07.[995.5,inf) | 00.[-inf,930.0) | 07.[16.5,inf) | 00.[-inf,0.5) | 01.[0.5,1.5) |
| 0 | 02.[0.1318,0.3009) | 04.[55.5,59.5) | 01.[0.0193,0.1368) | 04.[3456.5,4833.5) | 03.[5.5,7.5) | 00.[-inf,0.5) | 00.[-inf,0.5) |
cols = list(lapras.quality(train_selected,target = target).reset_index()['index'])
for col in cols:
if col != target:
print(lapras.bin_stats(c.transform(train_selected[[col, target]], labels=True), col=col, target=target))
lapras.bin_plot(c.transform(train_selected[[col,target]], labels=True), col=col, target=target)
for name, series in frame.iteritems():
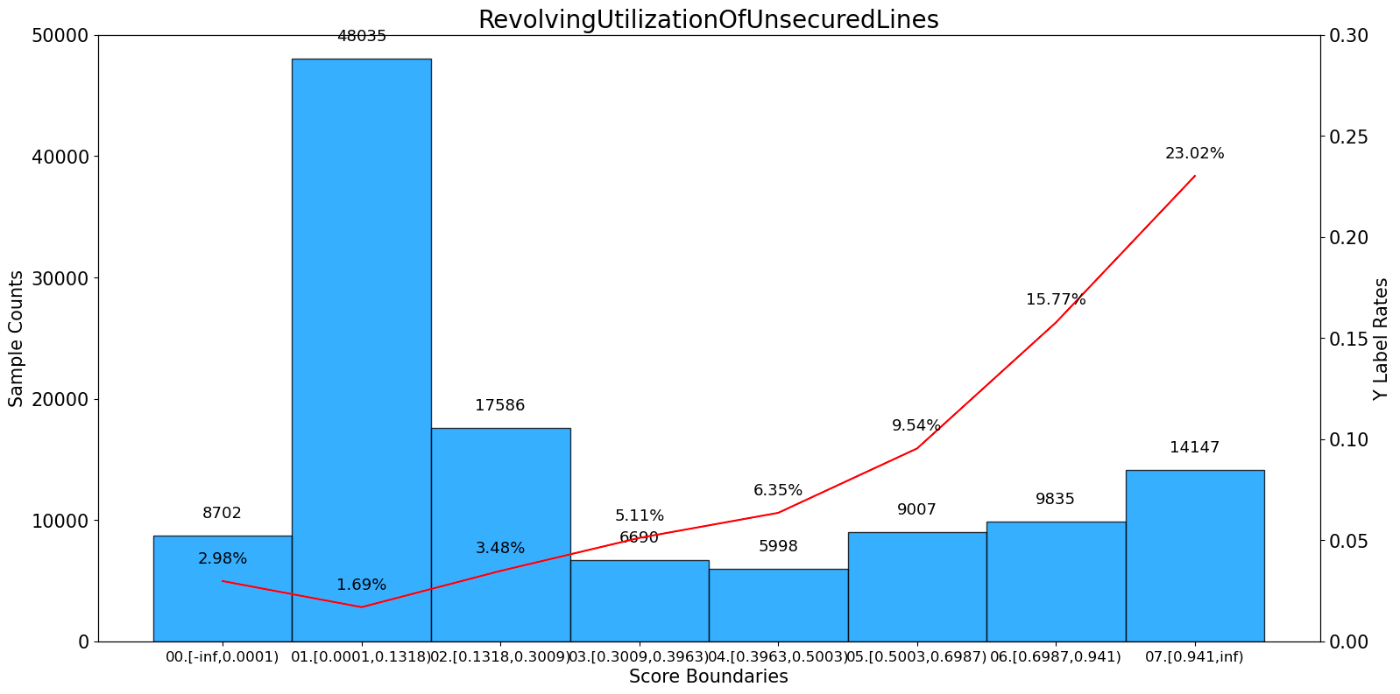
RevolvingUtilizationOfUnsecuredLines bad_count total_count bad_rate \
0 00.[-inf,0.0001) 259 8702 0.029763
1 01.[0.0001,0.1318) 810 48035 0.016863
2 02.[0.1318,0.3009) 612 17586 0.034800
3 03.[0.3009,0.3963) 342 6690 0.051121
4 04.[0.3963,0.5003) 381 5998 0.063521
5 05.[0.5003,0.6987) 859 9007 0.095370
6 06.[0.6987,0.941) 1551 9835 0.157702
7 07.[0.941,inf) 3256 14147 0.230155
ratio woe iv total_iv
0 0.072517 -0.854545 0.037033 1.116664
1 0.400292 -1.435924 0.461712 1.116664
2 0.146550 -0.692986 0.052537 1.116664
3 0.055750 -0.291364 0.004177 1.116664
4 0.049983 -0.061033 0.000181 1.116664
5 0.075058 0.379961 0.012785 1.116664
6 0.081958 0.954294 0.112781 1.116664
7 0.117892 1.422283 0.435457 1.116664
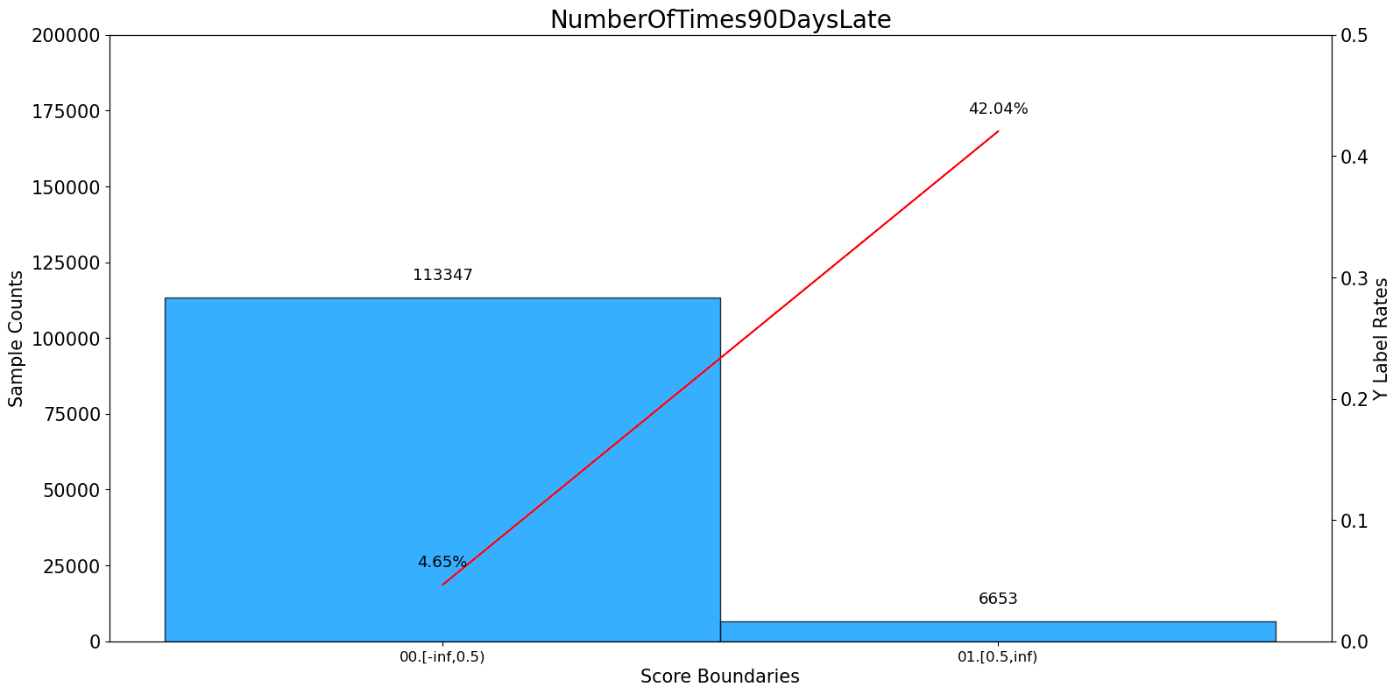
NumberOfTimes90DaysLate bad_count total_count bad_rate ratio \
0 00.[-inf,0.5) 5273 113347 0.046521 0.944558
1 01.[0.5,inf) 2797 6653 0.420412 0.055442
woe iv total_iv
0 -0.390497 0.121890 0.842514
1 2.308637 0.720623 0.842514
age bad_count total_count bad_rate ratio woe \
0 00.[-inf,35.5) 1945 17216 0.112976 0.143467 0.569027
1 01.[35.5,43.5) 1696 18470 0.091825 0.153917 0.338163
2 02.[43.5,52.5) 2071 26274 0.078823 0.218950 0.171275
3 03.[52.5,55.5) 582 8500 0.068471 0.070833 0.019297
4 04.[55.5,59.5) 570 10950 0.052055 0.091250 -0.272280
5 05.[59.5,63.5) 502 11233 0.044690 0.093608 -0.432572
6 06.[63.5,67.5) 278 8547 0.032526 0.071225 -0.762928
7 07.[67.5,inf) 426 18810 0.022648 0.156750 -1.135076
iv total_iv
0 0.059510 0.264022
1 0.020391 0.264022
2 0.006919 0.264022
3 0.000027 0.264022
4 0.006019 0.264022
5 0.014563 0.264022
6 0.030081 0.264022
7 0.126513 0.264022

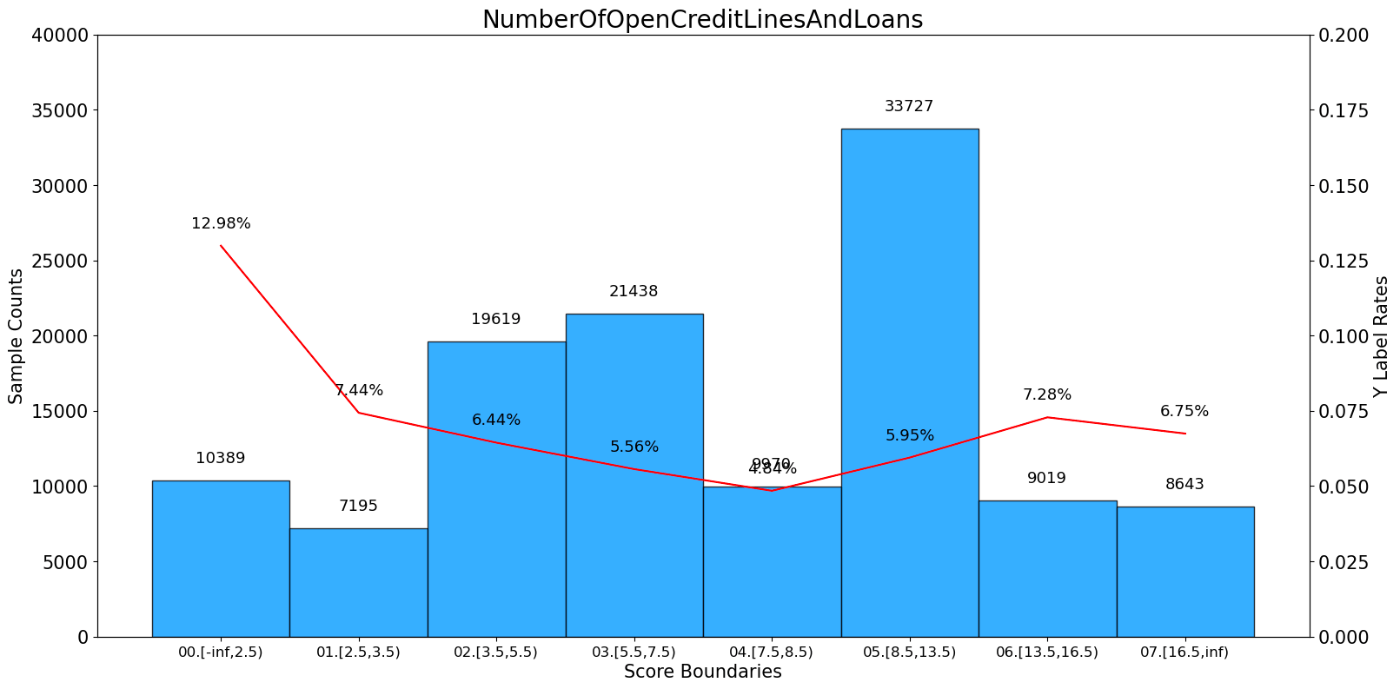
NumberOfOpenCreditLinesAndLoans bad_count total_count bad_rate ratio \
0 00.[-inf,2.5) 1349 10389 0.129849 0.086575
1 01.[2.5,3.5) 535 7195 0.074357 0.059958
2 02.[3.5,5.5) 1264 19619 0.064427 0.163492
3 03.[5.5,7.5) 1193 21438 0.055649 0.178650
4 04.[7.5,8.5) 483 9970 0.048445 0.083083
5 05.[8.5,13.5) 2006 33727 0.059478 0.281058
6 06.[13.5,16.5) 657 9019 0.072846 0.075158
7 07.[16.5,inf) 583 8643 0.067453 0.072025
woe iv total_iv
0 0.727425 6.284771e-02 0.084394
1 0.108112 7.344542e-04 0.084394
2 -0.045901 3.376869e-04 0.084394
3 -0.201717 6.664814e-03 0.084394
4 -0.347941 8.666174e-03 0.084394
5 -0.131116 4.566165e-03 0.084394
6 0.085951 5.763235e-04 0.084394
7 0.003239 7.564700e-07 0.084394
MonthlyIncome bad_count total_count bad_rate ratio woe \
0 00.[-inf,930.0) 1498 27129 0.055218 0.226075 -0.209951
1 01.[930.0,2000.5) 653 6189 0.105510 0.051575 0.492270
2 02.[2000.5,2649.5) 553 6006 0.092075 0.050050 0.341157
3 03.[2649.5,3456.5) 898 8973 0.100078 0.074775 0.433362
4 04.[3456.5,4833.5) 1406 16952 0.082940 0.141267 0.226666
5 05.[4833.5,6596.5) 1246 18452 0.067527 0.153767 0.004400
6 06.[6596.5,9930.5) 1117 20329 0.054946 0.169408 -0.215168
7 07.[9930.5,inf) 699 15970 0.043770 0.133083 -0.454340
iv total_iv
0 0.009105 0.086102
1 0.015486 0.086102
2 0.006757 0.086102
3 0.016959 0.086102
4 0.008009 0.086102
5 0.000003 0.086102
6 0.007150 0.086102
7 0.022634 0.086102

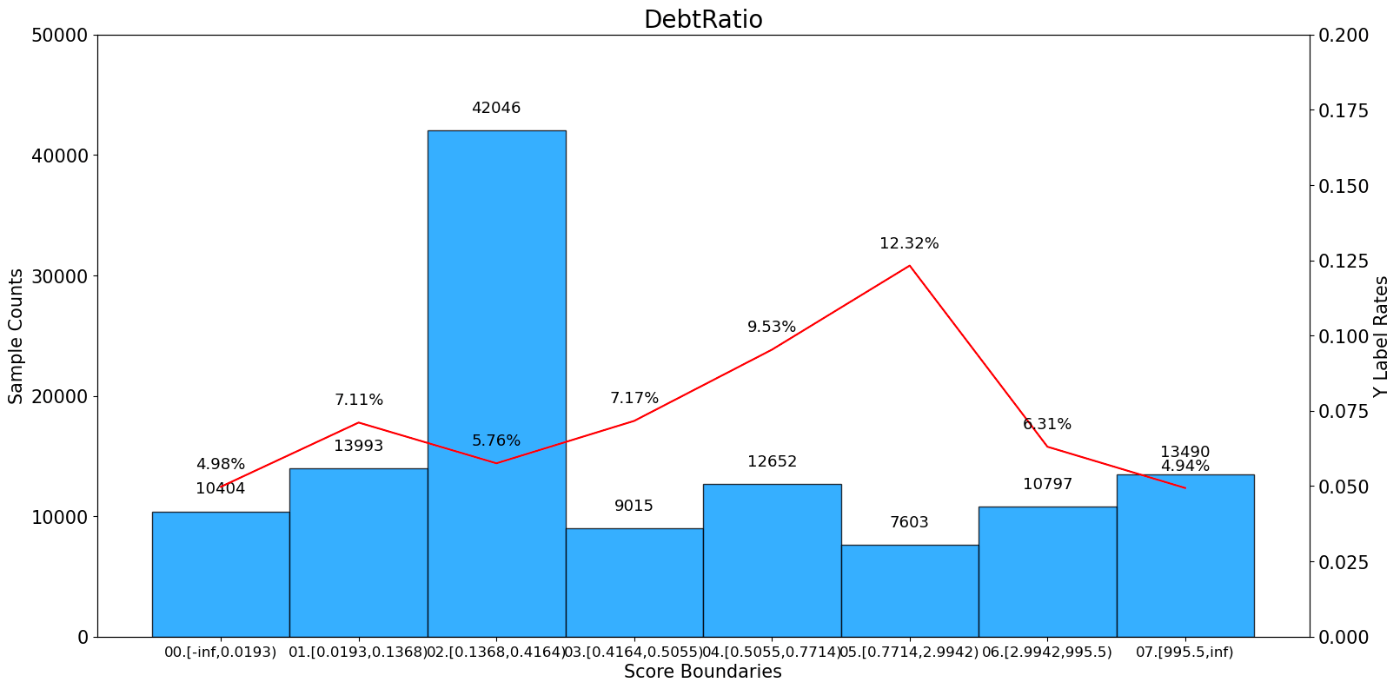
DebtRatio bad_count total_count bad_rate ratio woe \
0 00.[-inf,0.0193) 518 10404 0.049789 0.086700 -0.319179
1 01.[0.0193,0.1368) 995 13993 0.071107 0.116608 0.059912
2 02.[0.1368,0.4164) 2421 42046 0.057580 0.350383 -0.165559
3 03.[0.4164,0.5055) 646 9015 0.071658 0.075125 0.068230
4 04.[0.5055,0.7714) 1206 12652 0.095321 0.105433 0.379389
5 05.[0.7714,2.9942) 937 7603 0.123241 0.063358 0.667628
6 06.[2.9942,995.5) 681 10797 0.063073 0.089975 -0.068591
7 07.[995.5,inf) 666 13490 0.049370 0.112417 -0.328064
iv total_iv
0 0.007703 0.084017
1 0.000430 0.084017
2 0.008943 0.084017
3 0.000360 0.084017
4 0.017900 0.084017
5 0.037757 0.084017
6 0.000411 0.084017
7 0.010512 0.084017
NumberRealEstateLoansOrLines bad_count total_count bad_rate ratio \
0 00.[-inf,0.5) 3747 44916 0.083422 0.374300
1 01.[0.5,1.5) 2206 41884 0.052669 0.349033
2 02.[1.5,2.5) 1448 25161 0.057549 0.209675
3 03.[2.5,inf) 669 8039 0.083219 0.066992
woe iv total_iv
0 0.232990 0.022484 0.052885
1 -0.259896 0.021086 0.052885
2 -0.166120 0.005387 0.052885
3 0.230331 0.003928 0.052885
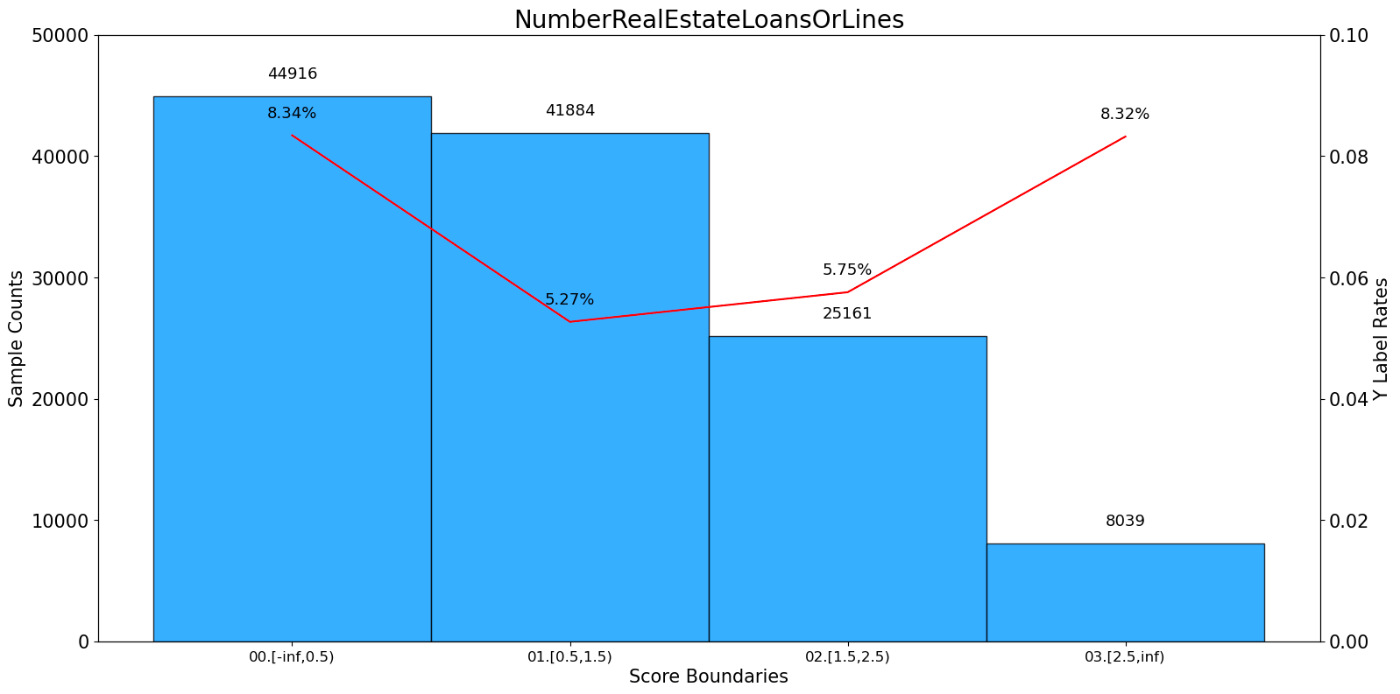
WOE value transformation
transfer = lapras.WOETransformer()
transfer.fit(c.transform(train_selected), train_selected[target], exclude=[target])
train_woe = transfer.transform(c.transform(train_selected))
val_woe = transfer.transform(c.transform(val_df))
test_woe = transfer.transform(c.transform(test_df))
transfer.export()
<lapras.transform.WOETransformer at 0x2746667ccd0>
{'RevolvingUtilizationOfUnsecuredLines': {0: -0.8545447193506434,
1: -1.435924251083907,
2: -0.6929855643979773,
3: -0.29136415096437573,
4: -0.06103342378641303,
5: 0.37996133825687756,
6: 0.9542941342803827,
7: 1.422282881666063},
'age': {0: 0.5690265657186839,
1: 0.3381626624268103,
2: 0.17127518361124283,
3: 0.01929671368468067,
4: -0.27227960227196496,
5: -0.4325717146160795,
6: -0.7629275544122108,
7: -1.135076460199848},
'DebtRatio': {0: -0.3191794579881027,
1: 0.05991215232361727,
2: -0.16555936062220464,
3: 0.06823001536904652,
4: 0.37938896793740196,
5: 0.6676282169900559,
6: -0.06859110802102461,
7: -0.328063830129681},
'MonthlyIncome': {0: -0.20995147767771272,
1: 0.4922698255982443,
2: 0.341157000215592,
3: 0.4333621138306611,
4: 0.22666561619976386,
5: 0.004400453785423839,
6: -0.21516837009619558,
7: -0.45433994810005246},
'NumberOfOpenCreditLinesAndLoans': {0: 0.7274245964408524,
1: 0.10811217698089041,
2: -0.045900527604813335,
3: -0.20171651274902666,
4: -0.34794087212098535,
5: -0.13111603896185353,
6: 0.08595130018741898,
7: 0.0032385444691370685},
'NumberOfTimes90DaysLate': {0: -0.39049652350955594, 1: 2.308637231090842},
'NumberRealEstateLoansOrLines': {0: 0.23299016747526333,
1: -0.25989576346995086,
2: -0.16611993338112926,
3: 0.23033126856416491}}
IF you want to ensure all the regression params are positive, you can select the features(WOE) once more.
# # Features filtering could be done once more after transformed into WOE value. This is optional.
# train_woe, dropped = lapras.select(train_woe,target = target, empty = 0.9, \
# iv = 0.02, corr = 0.9, vif = False, return_drop=True, exclude=[])
# print(dropped)
# print(train_woe.shape)
# train_woe.head(10)
Stepwise regression, to select best features, this is optional
# final_data = lapras.stepwise(train_woe,target = target, estimator='ols', direction = 'both', criterion = 'aic', exclude = [])
final_data = train_woe
Scorecard modeling
card = lapras.ScoreCard(
combiner = c,
transfer = transfer,
pdo = 40,
rate = 2,
base_odds = 1/60,
base_score = 600
)
col = list(final_data.drop([target],axis=1).columns)
card.fit(final_data[col], final_data[target])
ScoreCard(combiner=<lapras.transform.Combiner object at 0x7e03f8aa9fc0>,
transfer=<lapras.transform.WOETransformer object at 0x7e03effe75b0>)
card.get_params()['combiner']
card.get_params()['transfer']
print("card.intercept_:%s" % (card.intercept_))
print("card.coef_:%s" % (card.coef_))
card.export()
<lapras.transform.Combiner at 0x2745de778e0>
<lapras.transform.WOETransformer at 0x2746667ccd0>
card.intercept_:-2.620820761531965
card.coef_:[ 0.74975573 0.43247525 0.85266412 0.09651427 -0.30244651 0.72712492
0.40350345]
{'intercept': {'[-inf,inf)': 514.97},
'RevolvingUtilizationOfUnsecuredLines': {'[-inf,0.0001)': 36.97,
'[0.0001,0.1318)': 62.13,
'[0.1318,0.3009)': 29.98,
'[0.3009,0.3963)': 12.61,
'[0.3963,0.5003)': 2.64,
'[0.5003,0.6987)': -16.44,
'[0.6987,0.941)': -41.29,
'[0.941,inf)': -61.54},
'age': {'[-inf,35.5)': -14.2,
'[35.5,43.5)': -8.44,
'[43.5,52.5)': -4.27,
'[52.5,55.5)': -0.48,
'[55.5,59.5)': 6.8,
'[59.5,63.5)': 10.8,
'[63.5,67.5)': 19.04,
'[67.5,inf)': 28.33},
'DebtRatio': {'[-inf,0.0193)': 15.71,
'[0.0193,0.1368)': -2.95,
'[0.1368,0.4164)': 8.15,
'[0.4164,0.5055)': -3.36,
'[0.5055,0.7714)': -18.67,
'[0.7714,2.9942)': -32.85,
'[2.9942,995.5)': 3.38,
'[995.5,inf)': 16.14},
'MonthlyIncome': {'[-inf,930.0)': 1.17,
'[930.0,2000.5)': -2.74,
'[2000.5,2649.5)': -1.9,
'[2649.5,3456.5)': -2.41,
'[3456.5,4833.5)': -1.26,
'[4833.5,6596.5)': -0.02,
'[6596.5,9930.5)': 1.2,
'[9930.5,inf)': 2.53},
'NumberOfOpenCreditLinesAndLoans': {'[-inf,2.5)': 12.7,
'[2.5,3.5)': 1.89,
'[3.5,5.5)': -0.8,
'[5.5,7.5)': -3.52,
'[7.5,8.5)': -6.07,
'[8.5,13.5)': -2.29,
'[13.5,16.5)': 1.5,
'[16.5,inf)': 0.06},
'NumberOfTimes90DaysLate': {'[-inf,0.5)': 16.39, '[0.5,inf)': -96.87},
'NumberRealEstateLoansOrLines': {'[-inf,0.5)': -5.43,
'[0.5,1.5)': 6.05,
'[1.5,2.5)': 3.87,
'[2.5,inf)': -5.36}}
train_result = final_data[[target]].copy()
train_result['score'] = card.predict(final_data[col])
train_result['prob'] = card.predict_prob(final_data[col])
val_result = val_woe[[target]].copy()
val_result['score'] = card.predict(val_woe[col])
val_result['prob'] = card.predict_prob(val_woe[col])
test_result = df_testing
test_result['score'] = card.predict(test_woe[col])
test_result['prob'] = card.predict_prob(test_woe[col])
Model performance of validation dataset
lapras.perform(val_result['prob'],val_result[target])
KS: 0.5175
AUC: 0.8289
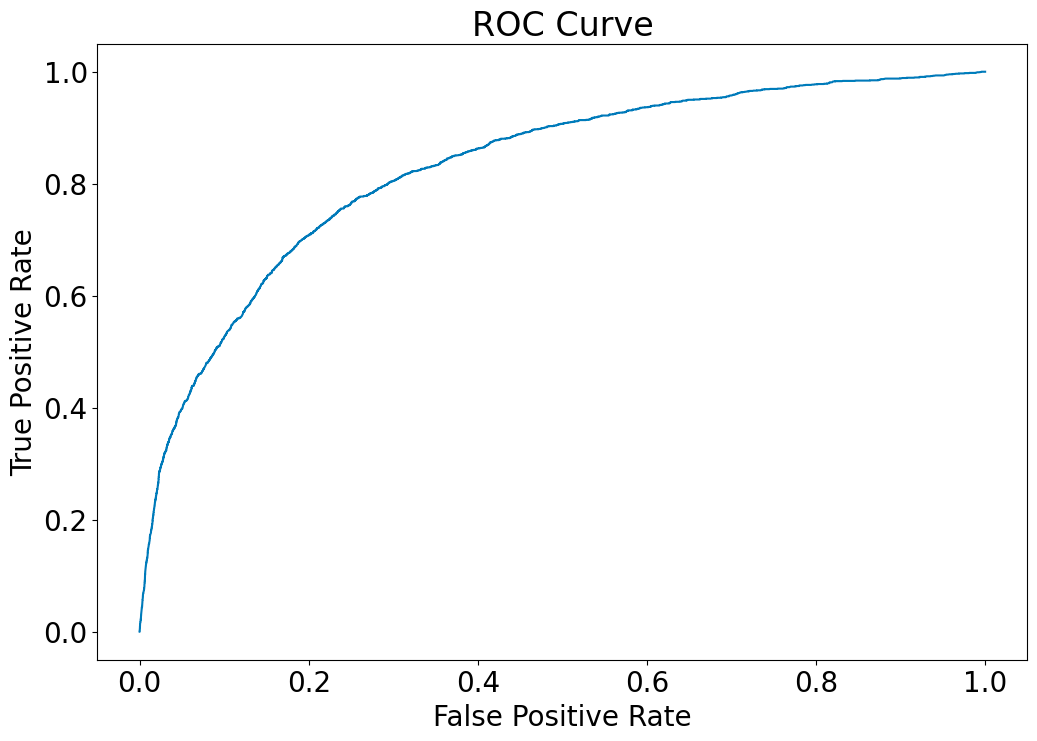
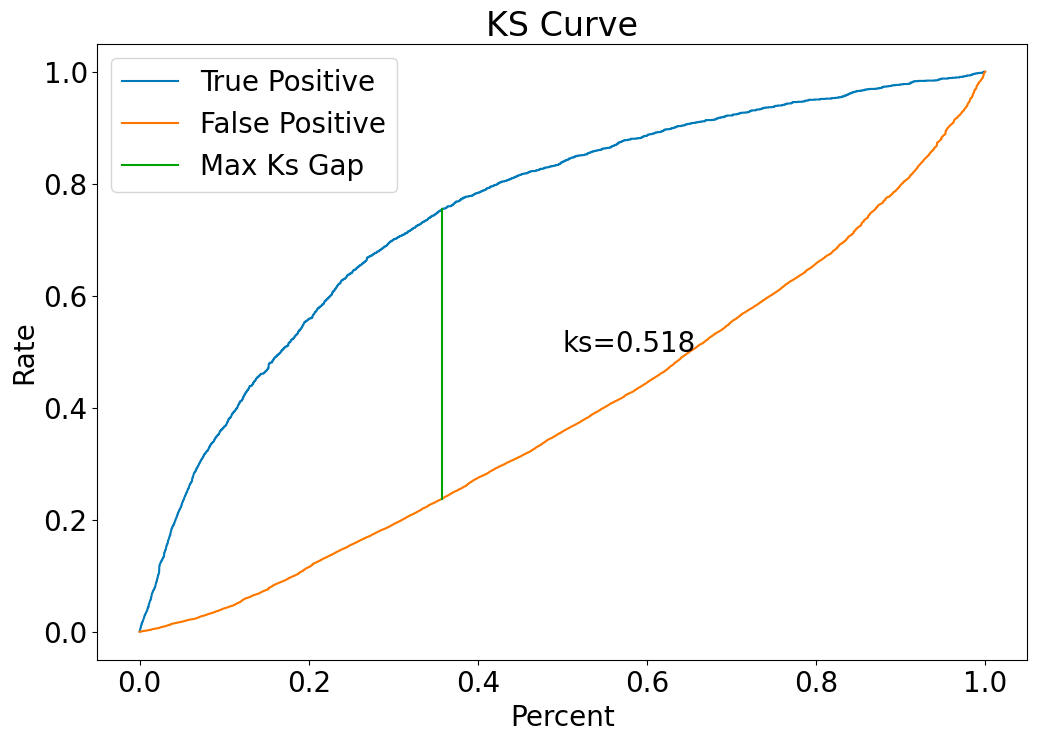

lapras.score_plot(val_result,score='score', target=target)

lapras.LIFT(val_result['prob'],val_result[target])
| recall | precision | improve |
|---|---|---|
| 0.1 | 0.525469 | 8.05934 |
| 0.2 | 0.475669 | 7.29554 |
| 0.3 | 0.445034 | 6.82568 |
| 0.4 | 0.354649 | 5.43939 |
| 0.5 | 0.282496 | 4.33276 |
| 0.6 | 0.234519 | 3.59691 |
| 0.7 | 0.202575 | 3.10697 |
| 0.8 | 0.159824 | 2.45129 |
| 0.9 | 0.115828 | 1.7765 |
| 1 | 0.0652 | 1 |
Prediction result for test dataset.
test_result[['score','prob']].head(10)
| score | prob |
|---|---|
| 483.52 | 0.111464 |
| 519.46 | 0.0630556 |
| 585.35 | 0.021033 |
| 517.98 | 0.0645845 |
| 445.18 | 0.196006 |
| 526.37 | 0.0563404 |
| 521.72 | 0.0607733 |
| 627.52 | 0.0102394 |
| 644.37 | 0.00766631 |
| 366.5 | 0.487975 |
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion