Rustで動的計画法:Intervals
はじめに
動的計画法を実装してみて、Rustの勉強をやってみる。問題としてはEducational DP Contestという動的計画法の練習を目的としたコンテストのものを使用。
AからZまで問題が設定されているが、今回はWのIntervalsを解いてみる。区間ごとに点数が決められていて、最高得点を取得するための組み合わせを求める問題。点数が正の数だけであれば、オール1が答えになるが、負の数が入るのでそれを考慮する必要がある。
利用したライブラリ
標準入力からデータを読み取る部分はproconioを利用。
ベクタから重複を削除するためにitertoolsに入っているdedupを使う。
完成したコード
アルゴリズム
dp[k][j]とする。この時、dp[k-1][j]からどうやってdp[k][j]を求めるかであるが、簡単化のために、
kビット目が1の時は、k-1の最大値に
ベース実装
use proconio::input;
fn main() {
input! {
n : usize, m : usize,
mut ranges : [(usize, usize, i64); m]
}
ranges.sort_by(|(_, r1, _), (_, r2, _)| r1.cmp(r2));
let mut dp = vec![0_i64; n + 1];
let mut right_index = 0;
for (l, r, a) in ranges {
if right_index < r {
let max_value = dp[0..=right_index].iter().max().unwrap().clone();
for i in (right_index + 1)..=r {
dp[i] = max_value;
}
}
right_index = r;
for i in l..=r {
dp[i] += a;
}
}
let max_value = dp.iter().max().unwrap().clone();
println!("{}", max_value);
}
前述のアルゴリズムを素直に実装すると上記のようになる。dpは上書きする形で、rangesで回す。この数がmax()で求める時のコストやfor i in l..=rのループが
まず、
for i in (right_index + 1)..=r {
dp[i] = max_value;
}
個人的に、終点を含むrangeを表す時の=rの記法は分かりやすくで好き。
座標圧縮
use proconio::input;
use itertools::*;
use std::collections::HashMap;
fn main() {
input! {
n : usize, m : usize,
mut ranges : [(usize, usize, i64); m]
}
ranges.sort_by(|(_, r1, _), (_, r2, _)| r1.cmp(r2));
+ let mut values = Vec::with_capacity(m * 2 + 1);
+ values.push(0_usize);
+ for (l, r, _) in &ranges {
+ values.push(*l);
+ values.push(*r);
+ }
+ values.sort();
+ let compressed = values.into_iter().dedup().enumerate().map(|(enu, index)| (index, enu)).collect::<HashMap<_,_>>();
let mut dp = vec![0_i64; n + 1];
let mut right_index = 0;
for (l, r, a) in ranges {
+ let cl = compressed.get(&l).unwrap();
+ let cr = compressed.get(&r).unwrap();
+ if right_index < *cr {
let max_value = dp[0..=right_index].iter().max().unwrap().clone();
+ for i in (right_index + 1)..=*cr {
dp[i] = max_value;
}
}
+ right_index = *cr;
+ for i in *cl..=*cr {
dp[i] += a;
}
}
let max_value = dp.iter().max().unwrap().clone();
println!("{}", max_value);
}
つまり以下の2つの問題は答えは同じだけど、dpの長さは100と3になる。なので、不要な部分を削除してしまう。
100 2
1 100 10
1 50 -10
3 2
1 3 10
1 2 -10
values.sort();
let compressed = values.into_iter()
.dedup()
.enumerate()
.map(|(enu, index)| (index, enu))
.collect::<HashMap<_,_>>();
必要なのは、dedup)、番号をつけて(enumerate)、順番を入れ替えて(map)、ハッシュにする(collect). dedupの実装は中々面白いので興味があれば検索すると良いと思う。
collectでHashMapを作る時に上記の記述の方がハッシュ化している感があって好みではあるが、検索してみると以下の記述の方が多い気がした。変数の型が明確になるという理由からかも知れない。
let compressed: HashMap<_,_> = ...collect();
セグメント木
use proconio::input;
use std::collections::HashMap;
use itertools::*;
mod lazy_segment_tree;
fn main() {
input! {
+ _ : usize, m : usize,
mut ranges : [(usize, usize, i64); m]
}
ranges.sort_by(|(_, r1, _), (_, r2, _)| r1.cmp(r2));
let mut values = Vec::with_capacity(m * 2 + 1);
values.push(0_usize);
for (l, r, _) in &ranges {
values.push(*l);
values.push(*r);
}
values.sort();
let compressed = values.into_iter().dedup().enumerate().map(|(enu, index)| (index, enu)).collect::<HashMap<_,_>>();
let n = compressed.len() - 1;
+ let mut dp = lazy_segment_tree::LazySegmentTree::new(
+ n + 1,
+ 0,
+ |x, y| std::cmp::max(x, y),
+ || i64::MIN,
+ |l, v| match l { Some(value) => value + v, None => v },
+ |f, g| match (f, g) { (Some(fv), Some(gv)) => Some(fv + gv), (Some(_), None) => f, (None, _) => g });
let mut right_index = 1;
for (l, r, a) in ranges {
let cl = compressed.get(&l).unwrap();
let cr = compressed.get(&r).unwrap();
if right_index < *cr {
+ let max_value = dp.prod(0..=right_index);
+ dp.apply(Some(max_value), (right_index + 1)..=*cr);
}
right_index = *cr;
+ dp.apply(Some(a), *cl..=*cr);
}
+ let max_value = dp.prod(0..=n);
println!("{}", max_value);
}
この問題の場合、区間に対する操作が多いので遅延評価セグメント木を使ってみる。以前Flowers で使ったFenwick Tree (BIT) が0から始まる区間の操作を対象にしていたが、こちらは任意の区間にしたもの。遅延評価セグメント木は各操作を
遅延評価セグメント木と、普通のセグメント木とあるが、今回のように区間の値を一度に更新したい場合は遅延評価が必要。調べているとすでに実装があった。
測定結果
#!/user/bin/env python
import random
import sys
n = int(sys.argv[1])
m = int(sys.argv[2])
RANGE = 1000
random.seed()
print(str(n) + " " + str(m))
for i in range(m):
l = random.randrange(1, n + 1)
r = random.randrange(0, min(RANGE, n - l + 1)) + l
a = random.randrange(-1000000000, 1000000000)
print(str(l) + " " + str(r) + " " + str(a))
スクリプトで自動的に問題を作成して評価をしてみた。区間の長さは1000未満としているので、for i in l..=rのループは
Nに対する計算量
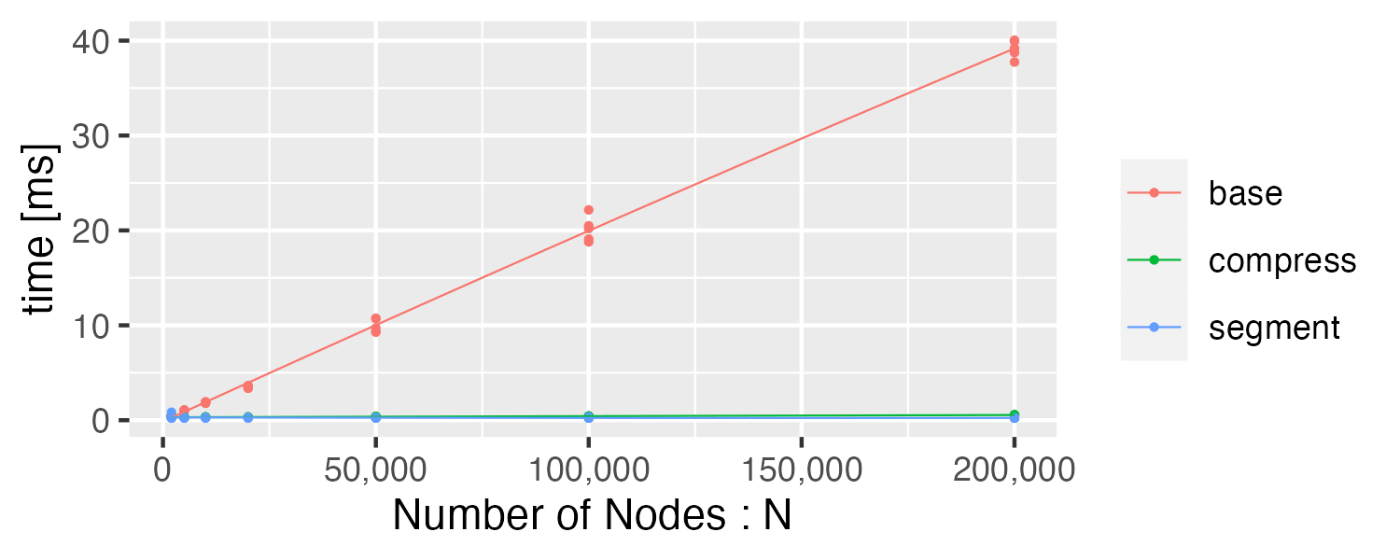
minのコストが意外とかかっているのが分かる。座標圧縮をすると、dpの長さが
Mに対する計算量

関連記事
Rustで動的計画法の実装:
🐸Frog | 🌴Vacation | 🎒Knapsack | 🐍LCS | 🚶♂️Longest Path | 🕸️Grid | 💰Coins | 🍣Sushi | 🪨Stones | 📐dequeue | 🍬Candies | 🫥Slimes | 💑Matching | 🌲Indipendent Set | 🌻Flowers | 👣Walk | 🖥️Digit Sum | 🎰Permutation | 🐰Grouping | 🌿Subtree | ⏱️Intervals | 🗼Tower | 🐸Frog3
Discussion